Elasticsearch 8.X 聚合查询下的精度问题及其解决方案
1、线上环境问题
咕泡同学提问:我在看runtime文档的时候做个测试, agg求avg的时候不管是double还是long,数据都不准确,这种在生产环境中如何解决啊?


2、问题归类及出现场景
上述问题可以归类为:Elasticsearch聚合查询下的精度问题。
在日常的数据处理工作中,我们经常会遇到使用Elasticsearch进行大数据查询、统计、聚合等操作。Elasticsearch在实践中表现出优秀的搜索性能,但在一些复杂的聚合操作,如求平均值(avg)时,可能会出现数据精度不准的问题。
接下来我们将详细介绍这个问题的出现场景、可能的原因以及解决方案。
在Elasticsearch中,数据精度问题主要出现在聚合(aggregation)操作中。比如我们在做一些大数运算时,如求和(sum)、求平均值(avg),可能会遇到数据类型(double或long)导致的精度问题。这是因为Elasticsearch在进行聚合操作时,为了提高性能和效率,会使用一种叫做“浮点数计算”的方式来做大数运算,而这种计算方式在处理大数时往往会丢失一些精度。
3、问题最小化复现
以一个简单的例子来说明这个问题。我们在Elasticsearch中存储了一些商品数据,现在我们想要计算所有商品的平均价格。
数据和查询的DSL如下(已在 Elasticsearch 8.X 环境下验证过):
数据:
POST /product/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "商品1", "price" : 1234.56 }
{ "index" : { "_id" : "2" } }
{ "name" : "商品2", "price" : 7890.12 }查询DSL:
GET /product/_search
{
"size": 0,
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
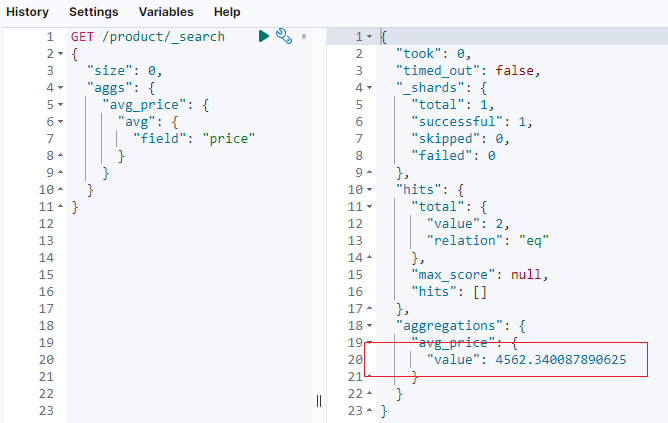
}虽然我们期望得到的平均价格是 (1234.56 + 7890.12) / 2 = 4562.34,但是由于浮点数计算的精度问题,返回的结果可能会略有偏差,如下图所示。
4、解决方案探讨与实现
如何解决上述聚合后精度问题呢?我们结合 Elasticsearch 基础知识和实战经验,给出如下三种解决方案。
方案一:借助 scaled_float 类型提升精度。
方案二:使用 scripted_metric 提升精度。
方案三:业务层面自己写代码实现。
接下来,我们逐一实战且解读上述三个方案。
4.1 借助 scaled_float 类型提升精度
4.1.1 什么是scaled_float?
scaled_float 是 Elasticsearch提供的一种特殊的数字数据类型,用于存储带小数的数字。
与 float 和 double 不同, scaled_float 实际上是一个 long 类型,只是它将实际的浮点数乘以一个给定的缩放因子进行存储。
在许多应用场景中,我们需要存储具有小数的数字,例如价格、评分等。float 和 double 是常用的数据类型,但它们有一些问题:例如,它们在存储和排序时可能会丢失精度,而且它们占用的存储空间比整数类型要多。而 scaled_float 实际上是将浮点数乘以一个 scaling factor,然后将结果存储为 long 。
例如,如果 scaling factor 是100,那么数字12.34将会被存储为1234。在查询和返回结果时,Elasticsearch将会除以 scaling factor ,返回原始的浮点数。
4.1.2 scaled_float的优势
精度更准确可控
与float和double相比,scaled_float在存储和排序时更准确,因为它实际上是存储的长整数,不存在浮点数的精度问题。
性能更好
由于scaled_float使用的是long类型,因此占用的存储空间更小,性能也更好。
灵活性更强
可以根据需要设置scaling factor,以平衡精度和性能。如果需要更高的精度,可以使用较大的scaling factor。如果项目需求关注性能和存储空间,可以使用较小的scaling factor。
4.1.3 在Elasticsearch中使用scaled_float
要在Elasticsearch中使用scaled_float,需要在映射中定义字段类型,并提供一个scaling factor。例如:
{
"properties": {
"price": {
"type": "scaled_float",
"scaling_factor": 100.0
}
}
}这个映射定义了一个名为price的scaled_float字段,它的scaling factor是100。这意味着所有的价格都将乘以100,然后作为long存储。
例如,价格12.34将会被存储为1234。
总的来说,scaled_float是一个非常有用的工具,可以在需要存储浮点数的情况下提供更好的精度和性能。
4.1.4 实战一把,解决开篇类似问题
在这个例子中,我们有两个产品,它们的价格是浮点数。
如果想要使用scaled_float,首先需要设置一个映射(mapping)。假设想要以精确到分的精度存储价格,那么可以设置scaling_factor为100.0。以下是如何定义映射的步骤:
首先,创建一个新的索引并定义映射:
PUT /product
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"price": {
"type": "scaled_float",
"scaling_factor": 100.0
}
}
}
}这个命令创建了一个新的索引 product,并定义了两个字段:name(类型为text)和price(类型为scaled_float,scaling_factor为100.0)。
然后,批量 bulk 插入数据如下:
POST /product/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "商品1", "price" : 1234.56 }
{ "index" : { "_id" : "2" } }
{ "name" : "商品2", "price" : 7890.12 }在这个过程中,price字段的值会自动乘以scaling_factor(在这里是100.0),然后存储为long类型。所以实际存储的值是123456和789012。
查询时,Elasticsearch会自动将价格除以scaling_factor,返回原始的浮点数。例如,如果执行以下查询:
GET /product/_doc/1返回的结果将会是:
{
"_index": "product",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"name": "商品1",
"price": 1234.56
}
}尽管price在存储时被乘以了100,但在查询时它又被除以了100,所以看到的价格仍然是1234.56。
这样,可以在保持较高精度的同时,使用更少的存储空间和更好的性能来存储和查询价格了。
最终咱们实现如下:
GET product/_search
{
"size": 0,
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
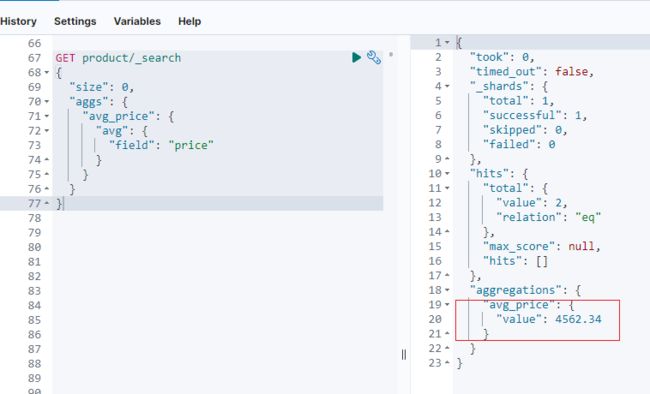
}如下所示,结果精度达到预期值。
4.2 使用scripted_metric提高精度
面对这种情况,我们可以使用Elasticsearch的另一个强大功能 —— 脚本计算(scripted_metric)来解决。
scripted_metric允许我们自定义复杂的聚合逻辑,比如下面的DSL:
####务必要删除索引
DELETE product
POST /product/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "商品1", "price" : 1234.56 }
{ "index" : { "_id" : "2" } }
{ "name" : "商品2", "price" : 7890.12 }
GET /product/_search
{
"size": 0,
"aggs": {
"avg_price": {
"scripted_metric": {
"init_script": "state.total = 0.0; state.count = 0",
"map_script": "state.total += params._source.price; state.count++",
"combine_script": "HashMap result = new HashMap(); result.put('total', state.total); result.put('count', state.count); return result",
"reduce_script": """
double total = 0.0; long count = 0;
for (state in states) {
total += state['total'];
count += state['count'];
}
double average = total / count;
DecimalFormat df = new DecimalFormat("#.00");
return df.format(average);
"""
}
}
}
}Elasticsearch是一个分布式搜索和分析引擎,意味着数据可以在多个分片上存储和处理。为了处理分布式数据,Elasticsearch使用了一种名为map-reduce的编程模型。这个模型分为两个步骤:映射(Map)和归约(Reduce)。init_script,map_script,combine_script和reduce_script都是这个模型的组成部分,用于实现更复杂的聚合。
在如上的脚本中,我们定义了四个步骤:
init_script:初始化脚本,在每个分片上为每个聚合创建一个新的状态。
map_script:映射脚本,用于处理输入文档,并将其状态转化为一个可以合并的格式。
combine_script:组合脚本,用于在节点级别合并每个分片的状态。
reduce_script:归约脚本,用于在全局范围内合并状态。
通过这种方式,我们可以得到一个更精确的平均值。
上述脚本的具体含义解释如下:
init_script:这个脚本在每个分片上执行一次,为每个分片创建一个新的状态。
在上述脚本中,它创建了一个状态对象,其中包含了一个总和(total)和一个计数器(count)。这个状态对象被初始化为{total: 0.0, count: 0}。
map_script:这个脚本在每个文档上执行一次。
在上述脚本中,它读取每个文档的price字段,并将这个值添加到total,同时增加count的值。这样,total会包含所有文档价格的总和,count会包含处理过的文档数量。
combine_script:这个脚本在每个分片上执行一次,对每个分片的状态进行组合。
在上述脚本中,它只是将total和count放入一个HashMap中返回。如果有很多状态需要合并,可能会在这个脚本中进行一些预处理。
reduce_script:这个脚本在结果合并时执行一次,将所有分片的状态进行归约,计算出最终结果。
在上述脚本中,它遍历所有分片的状态,计算总的total和count,然后计算平均价格。DecimalFormat用于将平均价格格式化为两位小数的字符串。
简单来说,这就是一个分步计算平均值的过程:首先初始化状态,然后为每个文档更新状态,接着在每个分片上合并状态,最后在全局范围内合并状态并计算结果。
最终结果如下图所示,达到预期精度。

4.3 业务层面自己写代码实现。
在应用层面进行精度控制:将原始数据获取到应用层,然后在应用层进行精确的计算。这种方法的优点是可以得到非常精确的结果,但缺点是可能需要处理大量的数据,增加了网络传输和计算的负担。
在应用层面处理数据的精度问题通常需要两个步骤:
首先,需要从 Elasticsearch 获取原始数据;
然后,在应用层进行精确的计算。
以下是一个使用Java处理数据精度的例子:
假设系统应用是用 Java 编写的,可以使用 Java 的 BigDecimal 类进行精确的浮点数计算。以下是一个简单的例子:
BigDecimal price1 = new BigDecimal("1234.56");
BigDecimal price2 = new BigDecimal("7890.12");
BigDecimal average = price1.add(price2).divide(new BigDecimal(2), 2, RoundingMode.HALF_UP);
System.out.println(average); // 输出:4562.34上述示例中,我们首先创建了两个 BigDecimal 对象,代表两个价格。然后我们调用add方法将它们加起来,然后调用 divide 方法计算平均值。最后,我们使用 RoundingMode.HALF_UP 参数来控制舍入模式。
请注意,这种方法需要在应用层处理所有的数据,如果数据量很大,那么这可能会导致性能问题。为了减少数据传输和计算的负担,可能需要在Elasticsearch中使用更精确的查询来只获取需要的数据,或者使用Elasticsearch的聚合功能来减少返回的数据量。
此外,可能还需要在应用层做一些优化,比如使用并行处理、缓存等技术来提高处理性能。具体的方法会根据应用的具体情况和需求来决定。
5、小结
总的来说,虽然Elasticsearch在进行聚合操作时可能会出现数据精度不准的问题,但是通过借助 scaled_float 类型提升精度、使用 scripted_metric 提升精度以及业务层面自己写代码实现三种方案得到较为精确的结果。
在遇到类似的问题时,我们需要根据实际情况选择最适合的解决方案。一方面要考虑精度的要求,另一方面也要考虑查询性能和资源消耗。我们应该根据业务的实际需求,适时地使用脚本计算来提高聚合操作的精度。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

大模型时代,抢先一步学习进阶干货!