Elasticsearch 基本使用(五)查询条件匹配方式(query & query_string)
查询条件匹配方式
-
- 概述
- query
-
- term
- terms
- range
- match_all
- match
-
- match 匹配精度问题
- match_phrase
- match_pharse_prefix
- match_bool_prefix
- multi_match
- query_string
-
- 简单查询一个字段
- 在多个字段上应用同一个条件 (类似multi_match)
- 在所有字段上应用同一个条件 (超越了multi_match)
- 对单个条件应用多个值
-
- 多个值之间可以是 AND 或者 OR 的关系
- query_string
-
- match 匹配
-
- 一个字段一个值
- 一个字段多个值
- 多个字段一个值
- 多个字段多个值
- 模糊匹配(比match更强大,在match后的词里面再进行模糊匹配)
- 范围匹配
- query_string 不同维度之间都是可以混用的(以上只是介绍了query_string基本用法,还有很多高级特性,具体可以参考官方文档)
概述
ES中常用的查询类型往大了分可以分为简单查询,复合查询,聚合查询等;
而复合查询及聚合查询都是基于简单查询的;简单查询里面对条件的匹配方式又分为不同类型。term[s],match,match_all,match_phrase 等等
query
term
单词查询,在字段的倒排索引(发生分词)或者直接在字段值(未发生分词)中查找条件值,只要找到这个条件值就算匹配上,得分为1。
terms
多个单词查询,效果为 多个 term 或者的逻辑。bool -> should -> term1,term2…
range
一般用于对数值类型进行范围查询
match_all
无条件查询,匹配所有数据
match
- 根据文档中实际存储的字段类型(是否为分词文本 text,keyword 不会进行分词),决定是否对条件值进行分词
- 如果未分词,直接以条件值执行 term 查询
- 如果分词,则对条件值进行,分词处理;
- 若得到一个词,也是执行term查询
- 若得到多个词,默认执行 terms 查询(多个单词 或者关系)
- 也可以手动指定为 且关系(如果为且,意思是,倒排索引后的词表中要包含 条件分词后的 所有单词),通过以下方式指定 match 单词之间的关系
以上查询 operator 默认为 or,分词 得到 张 和 四 两个词;GET /stu/_search { "query": { "match": { "name": { "query": "张 四", "operator": "and" } } } }
可以查到 张三 李四 张三四 三个人。
我们将 operator 指定为 and 后,只能查到 张三四 一个人了,必须包含条件分词后的所有单词。
match 匹配精度问题
对于match 分词后的查询;
and 是必须包含条件分词后所有的单词
or 是只需包含条件分词后任意一个单词。
and 下相对来说精度问题还好点,毕竟要包含所有条件分词单词。
如果是在or的情况,我们想要定义至少包含几个单词才当作匹配上,此时还需要另一个参数 minimum_should_match 。
虽然在and情况下,用得相对较少,但对and也有效
此值也可以设置为百分比,意思是条件分词后,达到比例的条件单词匹配上才算匹配,
比如,以下查询语句是查不出数据的
GET /stu/_search
{
"query": {
"match": {
"name": {
"query": "张 四",
"operator": "and",
"minimum_should_match": 3
}
}
}
}
因为你的条件分词,只有 2个词,即使分词也只得到2个词, 小于 minimum_should_match
match_phrase
以当前条件值,到文档**字段(而非分词后的列表)**里查询。
条件不做分词,到文档字段内 进行连续的 文本匹配
match_pharse_prefix
同样是以 条件不做分词到文档字段中查询,但是条件最后的 单词不是必须匹配字段内的完整单词
例如:
文档字段为 i love you
条件为 i love yo
match_phrase 下 无法匹配,因为 文档中 you 是一个完整的单词;只能匹配 i 或者 i love 或者 i love you
match_pharse_prefix 就可以匹配,就是说只要是一个前缀包含的连续文本就能匹配
match_bool_prefix
条件进行分词,执行 bool > should 查询
前面的词 做 term 查询,最后一个词做 perfix 查询
multi_match
在实际开发中,特别是模糊查询场景,可能需要将条件应用到多个文档字段上进行匹配。
当然我们可以使用 bool + should 的方式实现。
但ES已经给我们提供了一种更为便捷的方式。
同时匹配 品牌或名称 有苹果的数据
"query": {
"multi_match" : {
"query": "苹果",
"fields": [ "brand", "name" ]
}
}
等价于
"query": {
"bool": {
"should": [
{
"match": {
"brand": "苹果"
}
},
{
"match": {
"name": "苹果"
}
}
]
}
}
query_string
以下是引用自ES社区博客中的一段描述
该查询使用语法基于 OR,AND 或 NOT 等运算符来解析和拆分提供的查询字符串。 然后查询在返回匹配文档之前独立分析每个拆分文本。
你可以使用 query_string 查询创建一个复杂的搜索,其中包括通配符,跨多个字段的搜索等等。 尽管用途广泛,但查询是严格的,如果查询字符串包含任何无效语法,则返回错误。
简单总结:这是使用字符串通过 AND OR NOT 构建复杂查询的一种实现方式,但是语法较严格,容易出错,并不推荐在日常查询中使用
实际测试下来,单个条件执行的应该是match操作
简单查询一个字段
default_field:条件字段,只能一个。
GET /bank/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "School Lane"
}
}
}
返回结果为 School Lane 的match查询,凡是 address 包含 School 或者 Lane 的都匹配上
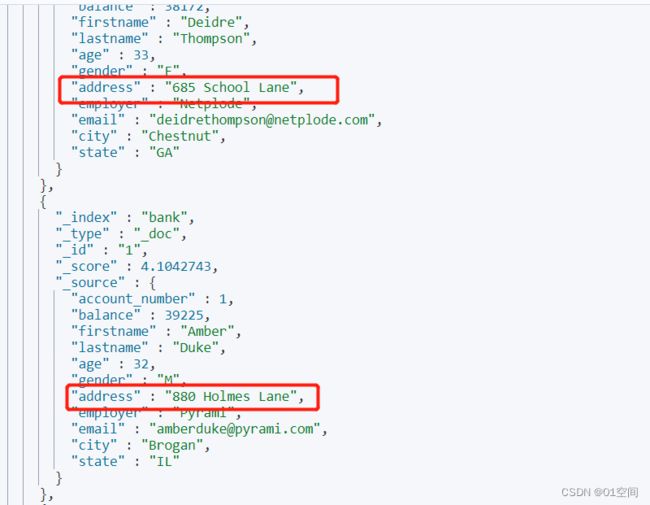
在多个字段上应用同一个条件 (类似multi_match)
上面的简单查询 通过 “default_field”: “字段名” 指定一个查询字段。
当要将条件应用到多个字段时,可以使用 “fields”: [“字段1”, “字段2”],
GET /bank/_search
{
"query": {
"query_string": {
"fields": ["age", "account_number"],
"query": "26"
}
}
}
查询 age match 26 或者 account_number match 26 的数据
在所有字段上应用同一个条件 (超越了multi_match)
在所有字段上执行match操作,只要任何一个字段匹配上就算匹配。
我们只需要去掉 fields 字段即可
GET /bank/_search
{
"query": {
"query_string": {
"query": "28"
}
},
"size": 2000
}
以上,在所有字段上应用 match 28。
在 bank 这个索引下,查到了 age = 28 和 id = 28 的数据
对单个条件应用多个值
多个值之间可以是 AND 或者 OR 的关系
- 在所有字段上match 28 或者 30
GET /bank/_search
{
"query": {
"query_string": {
"query": "28 OR 30"
}
},
"size": 2000
}
指定字段 fields 或默认字段 default_field都适用这个逻辑关系
NOT 关键字可以用在逻辑关系中任一项的前面,表示查询相反条件
query_string
上面指定字段要么使用 fields ,要么使用 default_field,其实还有另一种更为灵活的方式,我们可以直接将字段写到 query查询语句中,
使用 query:“字段名: 条件值” 的方式灵活定制查询条件
match 匹配
一个字段一个值
GET /bank/_search
{
"query": {
"query_string": {
"query": "age: 30"
}
},
"size": 100
}
一个字段多个值
GET /bank/_search
{
"query": {
"query_string": {
"query": "age: 30 OR 20"
}
},
"size": 100
}
多个字段一个值
GET /bank/_search
{
"query": {
"query_string": {
"query": "age: 30 OR account_number:1"
}
},
"size": 100
}
多个字段多个值
GET /bank/_search
{
"query": {
"query_string": {
"query": "age: (30 OR 20) OR account_number: 1"
}
},
"size": 100
}
模糊匹配(比match更强大,在match后的词里面再进行模糊匹配)
如下:
match Sedgwick
GET /bank/_search
{
"query": {
"match": {
"address": "Sedgwick"
}
}
}
match 只能在分词后的倒排索引中精确匹配
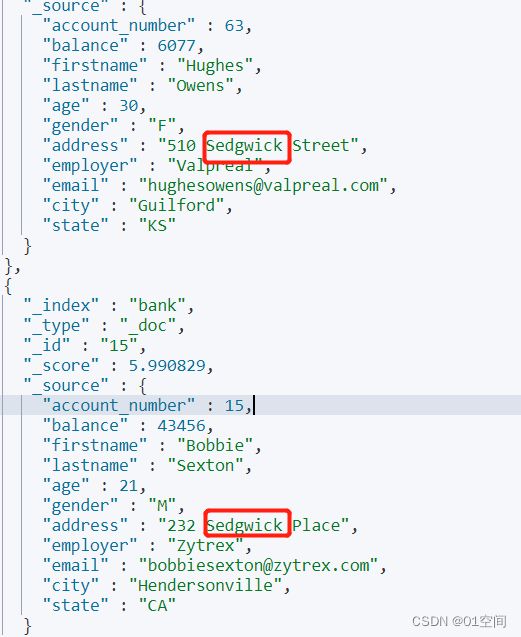
如果把条件值改成 Sedgwic,去掉最后一个 k,match就查不出来数据了。
但是使用 query_string 的模糊匹配依然有办法查出来这两条数据
query_string 的模糊匹配有两个通配符
- ?,统配一个字符,
- *,统配任意多个字符
使用以下语句都可以查出这两条数据 - ?匹配一个字符 k
GET /bank/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "Sedgwic?"
}
}
}
- *匹配一个字符 k
GET /bank/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "Sedgwic*"
}
}
}
- *匹配多个字符 ck
GET /bank/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "Sedgwi*"
}
}
}
- 前缀也能模糊
GET /bank/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "*dgwi*"
}
}
}
以上都能查出来那两条数据。
范围匹配
默认的匹配方式为 match,其本质就是 等值匹配,只是分不分词的区别,
对于 query 中的 range 查询,query_string 中也有对应实现。
并且 query_string 还支持两种写法
- 区间写法
[ 表示包含起始值
] 表示包含结束值
{ 不包含起始值
} 不包含结束值
*表示不限制这一边的值
以下例子- [1 TO 2] :1 <= x <= 2
- {1 TO 2} :1 < x < 2
- [* TO 2] : x <= 2
依然支持上面不同字段的写法,这里只是举个例子
GET /bank/_search
{
"query": {
"query_string": {
"default_field": "age",
"query": "{* TO 20]"
}
}
}
GET /bank/_search
{
"query": {
"query_string": {
"query": "age:{* TO 20]"
}
}
}
- 传统 > < 写法
- “>2” 大于2
- ">=2"大于等于2
- “>=2 AND <=5” 大于等于2且小于等于5
与上面那些多条件,多个值,模糊查询 不同维度之间 是可以混合使用的。
GET /bank/_search
{
"query": {
"query_string": {
"default_field": "age",
"query": ">=20"
}
}
}
GET /bank/_search
{
"query": {
"query_string": {
"default_field": "age",
"query": ">=20 AND <30"
}
}
}
GET /bank/_search
{
"query": {
"query_string": {
"query": "age:(>=20 AND <30)"
}
}
}