Mongodb学习笔记
注意:现阶段6版本可能会有问题,按装5版本即可
目录
一. 连接方式
shell连接:
图像化界面连接:
二. 数据库的创建和删除。常用命令
三. 集合的创建和删除
1. 集合的显示创建
四. 文档的 增,删,改,查
1. 插入数据find
(1). 向 comment 的集合(表)中插入一条数据:
(2). 向 comment 的集合(表)中批量插入数据:
2. 查询数据
3. 更新数据
4. 删除数据
五. 文档的分页查询
1. 统计查询:count()
2. 分页列表查询:limit() skip()
3. 排序查询:sort() 方法对数据进行排序
4. 正则的复杂条件查询:通过 js语法的正则 实现
5. 比较查询:通过“ <,<=,>,>=,!= 常用操作符”
6. 包含,不包含查询: $in $nin
7. 条件连接查询:与 ($and) 和 或 ($or)
8. 查询所有存在或不存在 某个 字段的数据
六、数据库数据的导出、导入、备份、恢复
1、导出。(mongoexport)
2、数据导入。(mongoexport)
3、数据备份。(mongodump)
4、数据恢复。(mongorestore)
七、常用命令小结。
MongoDB的简介
它是一个以JSON 为数据模型的文档数据库,由上市公司 MongoDB Inc 开发, 总部位于美国纽约。
特点:建模为可选 ,JSON数据模型比较适合开发者,横向扩展可以支持很大数据量和并发。
为什么叫文档数据库?
文档来自于 “ JSON Document” 并非我们一般理解的 POF, WORD文档
技术优势:
- JSON 结构和对象模型接近,开发代码量低
- JSON 的动态模型意味着更容易响应新的业务需求
- 复制集提供 99.999% 高可用
- 分片架构支持海量数据和无缝扩容
一. 连接方式
配置的快捷启动:net start MongoDB
shell连接:
1. mongo
2.mongo --host=网址 --port=端口号[27017]
图像化界面连接:
二. 数据库的创建和删除。常用命令
1. 创建数据库,若存在次数据库,则直接切换到这个数据库
use 数据库名
注意:创建的数据库存放在内存中, 但如果里面有集合(不为空)它会持久化到磁盘
2. 查看所有有权限查看的所有数据库
show dbs
或
show databases
注意:查看的是磁盘里的 。
- admin:从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
- local:这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config:当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
3. 查看当前使用的数据库
db
MongoDB中默认的数据库为 test ,如果你没有选择数据库,集合讲存放在 test数据库中
4. 删除数据库
db.dropDatabase()
三. 集合的创建和删除
1. 集合的显示创建
创建语法:
db.createCollection("集合名")
查看当前库中的集合(表):
show collections
或
show tables
集合的删除 :返回一个布尔值
db.collection.drop()
或
db.集合名.drop()
四. 文档的 增,删,改,查
1. 插入数据find
(1). 向 comment 的集合(表)中插入一条数据:
db.comment.insert({"myid":"123","username":"干得漂亮"})
注意:
- comment 集合如果不存在,则会隐式创建
- mongo中的数字,默认情况下是 double 类型,如果要存整型,必须使用函数 NumberInt(整型数字), 否则取出来就有问题。
- 插入当前日期使用 new Date()
- 插入的数据没有指定_id ,会自动生成主键值
- 如果某字段没值,可以赋值为 null ,或不写改字段
执行成功后,如下, 说明插入一个数据成功了。

(2). 向 comment 的集合(表)中批量插入数据:
语法:
db.comment.insertMany(
[
, ] , {
writeConcern:
, ordered:
}
)
参数:
| Parameter | Type | Description |
|---|---|---|
| document | document | 要插入到集合中的文档或文档数组。((json格式) |
| writeConcern | document | 可选。性能和可靠性的级别 |
| ordered | boolean | 可选。一个布尔值,指定Mongod实例应执行有序插入还是无序插入。默认为true。是否排序 |
执行成功后,如下, 说明插入一个数据成功了。

注意:批量插入数据,如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉,因此,我们可以使用 try catch 进行异常捕捉处理,测试的时候可以不处理
try {
db.comment.insertMany([
{"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我 他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08- 05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"},
{"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔 悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"},
{"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船 长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"},
{"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯 撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"},
{"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫 嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08- 06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"}
]);
} catch (e) {
print (e);
}2. 查询数据
语法格式:
db.collection.find(
, )
参数:
| Parameter | Type | Description |
|---|---|---|
| query | document | 可选。使用查询运算符指定选择筛选器,若要返回集合中的所有文档,请省略次参数或传递空文档({})。 |
| projection | document | 可选。指定要在查询筛选器匹配的文档中返回的字段,若要返回匹配文档中的所有字段,请省略此参数 |
只查看存在这个 字段和字段值 的所有数据:"add":"hhh"
db.comment.find( {add:"hhh"} )
只查看存在这个 字段和字段值 的第一条数据:"add":"hhh"
db.comment.findOne( {add:"hhh"} )
只查看这条数据的 部分字段:"add":"hhh" 默认显示 _id 去除 { _id:0}
db.comment.find( {add:"hhh"}, {aaa: 1} )
3. 更新数据
语法:
db.comment.update()
覆盖更新:这条数据中处理这个字段,其它的都没了
修改 _id为1 的数据,的点赞量为666:
db.comment.update( {_id:"1"} , {likenum: NumberInt(666)} )
局部更新: 使用修改器 $set:{} 来实现
修改 _id为2 的数据,的点赞量为28:
db.comment.update( {_id:"2" }, {$set:{likenum: NumberInt(20)}} )
批量更新: {multi:true}
更新用户名为 1003 的所有用户
//默认只修改第一条数据
db.comment.update({userid:"1003"},{$set:{nickname:"张三"}})
// 修改所有符合条件的数据db . comment . update ({ userid : "1003" },{ $set :{ nickname : "张三 " }},{ multi : true })
列值增长的修改:实现对某列值在原基础上进行增加或减少,可以使用 $inc 运算符 来实现 。
正负值
db.comment.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})
4. 删除数据
删除文档语法结构:
db.集合名.remove(条件)
删除全部的数据,慎用:
db.comment.remove({})
删除 _id = 1 的记录:
db.comment.remove({_id:"1"})
五. 文档的分页查询
1. 统计查询:count()
统计查询使用 count()方法,语法如下:
db.comment.count(
, )
参数:
统计 comment 集合的所有记录数:
db.comment.count()
按条件统计记录数:
db.comment.count({userid:"1003"})
2. 分页列表查询:limit() skip()
使用 limit() 方法来读取前面指定数量的数据,默认值20
db.comment.find().limit(2)
db.comment.find().skip(3)
跳过前面2条记录,返回3条记录
db.comment. find().limit(3).skip(2)
3. 排序查询:sort() 方法对数据进行排序
参数:1:升序 -1:降序
db.集合名称.find().sort(排序方式)
例如: 对userid降序排列,并对访问量进行升序排列
db.comment.find().sort({userid:-1,likenum:1})
注意:skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit(),和命令编写顺序无关。
4. 正则的复杂条件查询:通过 js语法的正则 实现
db.collection.find({field:/ 正则表达式 /})或db. 集合 .find({ 字段 :/ 正则表达式 /})例:查询包含 “”某某“” 的所有文档db.comment.find({content: / 某某 /})
5. 比较查询:通过“ <,<=,>,>=,!= 常用操作符”
db. 集合名称 .find({ "field" : { $gt: value }}) // 大于 : field > valuedb. 集合名称 .find({ "field" : { $lt: value }}) // 小于 : field < valuedb. 集合名称 .find({ "field" : { $gte: value }}) // 大于等于 : field >= valuedb. 集合名称 .find({ "field" : { $lte: value }}) // 小于等于 : field <= valuedb. 集合名称 .find({ "field" : { $ne: value }}) // 不等于 : field != value案例: 查询评论点赞数量大于 700 的记录db.comment.find({likenum:{$gt:NumberInt(700)}})
6. 包含,不包含查询: $in $nin
db.comment.find({userid:{ $in:["1003","1004"]}})
不包含使用 $nin 操作符。 示例:查询评论集合中userid字段不包含1003和1004的文档
db.comment.find({userid:{$nin:["1003","1004"]}})
7. 条件连接查询:与 ($and) 和 或 ($or)
语法格式:与
$and:[ { },{ },{ } ]
示例:查询评论集合中likenum大于等于700 并且小于2000的文档:
db.comment.find({$and:[{likenum:{$gte:NumberInt(700)}},{likenum:{$lt:NumberInt(2000)}}]})
语法格式:或
$or:[ { },{ },{ } ]
如果两个以上条件之间是或者的关系,我们使用 操作符进行关联,与前面 and的使用方式相同 格式为:
$or:[ { },{ },{ } ]
示例:查询评论集合中userid为1003,或者点赞数小于1000的文档记录
db.comment.find({$or:[ {userid:"1003"} ,{likenum:{$lt:1000} }]})
8. 查询所有存在或不存在 某个 字段的数据
查询所有存在 name 字段的记录
db.users.find({name: {$exists: true}});
查询所有不存在 name 字段的记录
db.users.find({name: {$exists: false}});
六、数据库数据的导出、导入、备份、恢复
1、导出。(mongoexport)
注意:只能导出数据库中的表,每次只能导出一个表
// 语法:
mongoexport
-h(或--host) IP地址
-u 用户名---(没有可省略)
-p 密码---(没有可省略)
-d 数据库名
-c 表名
--type 输出的格式或类型,默认json---(只有两种格式:json和csv)
-f 导出的字段---(省略表示所有字段。如果--type为csv类型,不能省略,-f "字段名")
-o 保存文件的目录,可自定义指定文件后缀名
-q 指定查询语法,相当于筛选输出---(可省略)
// 1.普通导出----导出每个字段:
mongoexport -h 127.0.0.1:27017 -d test -c user -o C:\Users\user.json
// 2.导出指定的字段:
mongoexport -h 127.0.0.1:27017 -d test -c user -f "send_uin,recv_uin,appid" -o C:\Users\user.json
// 3.指定过滤条件,time字段大于100的(-q) 注意:字段名需要用双引号括起来
mongoexport -h 127.0.0.1:27017 -d test -c user -q '{"time":{"$gt":1637396640000000}}' -o C:\Users\user.json
// 4.指定pretty 输出
mongoexport -h 127.0.0.1:27017 -d test -c user --pretty -o C:\Users\user.json
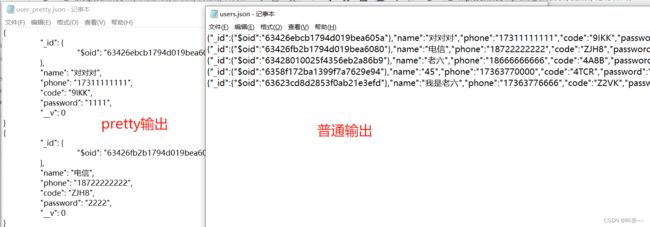
2、数据导入。(mongoexport)
// 语法:
mongoimport
-h(或--host) IP地址
-u 用户名---(没有可省略)
-p 密码---(没有可省略)
-d 数据库名
-c 表名
--type 输出的格式或类型(可省略),默认json---(只有两种格式:json和csv)
-f 导出的字段---(省略表示所有字段。如果--type为csv类型,不能省略,-f "字段名")
--headerline :如果导入的格式是csv,则使用第一行的标题作为导入的字段
--file :要导入的文件
// 1.普通导入:
mongoimport -h 127.0.0.1:27017 -d test -c user --type=json --file=C:\Users\user.json3、数据备份。(mongodump)
// 语法:
mongodump
-h:MongDB所在服务器地址,例如:127.0.0.1,当然也可以指定端口号:127.0.0.1:27017
-d:需要备份的数据库实例,例如:test
-o:备份的数据存放位置,例如:/home/mongodump/,当然该目录需要提前建立,这个目录里面存放该数据库实例的备份数据。
// 数据备份:讲本地数据数据库test 的数据全部保存到 C:\Users目录下
mongodump -h 127.0.0.1:27017 -d test -o C:\Users4、数据恢复。(mongorestore)
// 语法:
mongorestore
-h:MongDB所在服务器地址
-d:需要恢复的数据库实例。这个名称也可以和备份时候的不一样,比如test2
--dir:备份数据所在位置,例如:/home/ab/
--drop:恢复前,先删除当前数据,在恢复备份的数据。慎用!
// 数据恢复:讲本地数据数据库test 的数据全部保存到 C:\Users目录下
mongorestore -h 127.0.0.1:27017 -d test --drop --dir C:\Users七、常用命令小结。
选择切换数据库: use articledb插入数据: db.comment.insert({bson 数据 })查询所有数据: db.comment.find();条件查询数据: db.comment.find({ 条件 })查询符合条件的第一条记录: db.comment.findOne({ 条件 })查询符合条件的前几条记录: db.comment.find({ 条件 }).limit( 条数 )查询符合条件的跳过的记录: db.comment.find({ 条件 }).skip( 条数 )修改数据: db.comment.update({ 条件 },{ 修改后的数据 }) 或 db.comment.update({ 条件 },{$set:{ 要修改部分的字段 : 数据 })修改数据并自增某字段值: db.comment.update({ 条件 },{$inc:{ 自增的字段 : 步进值 }})删除数据: db.comment.remove({ 条件 })统计查询: db.comment.count({ 条件 })模糊查询: db.comment.find({ 字段名 :/ 正则表达式 /})条件比较运算: db.comment.find({ 字段名 :{$gt: 值 }})包含查询: db.comment.find({ 字段名 :{$in:[ 值 1 ,值 2]}}) 或 db.comment.find({ 字段名 :{$nin:[ 值 1 ,值 2]}})条件连接查询: db.comment.find({$and:[{ 条件 1},{ 条件 2}]}) 或 db.comment.find({$or:[{ 条件 1},{ 条件 2}]})