cocos的渲染原理代码彻底分析
最终我选择了研究一下cocos2dx的渲染管线的知识,一是因为这个引擎代码更为熟悉,二是相对来说会简单点。
首先做几个小实验:
实验1:
三个不同的图片顺序排序在场景里,这里说的顺序排序指的是文件目录,而不是场景里的位置。
结果:
drawcall = 3 (左下角GL calls),每次drawcall分别是三个图片节点。


实验2:
界面摆放位置和实验1一样,区别是把三张图片放入合图里。
结果:
drawcall = 1,三个图片节点合并到一个drawcall中去了

实验3:
前置条件和实验2一样,新建了两个文本,一个在图像1和2之间,一个在图像2子节点中
结果:
drawcall = 5,每个节点分别产生了一次drawcall。


试验结束
通过以上实验,我们隐约猜出三个结论:
- 合图可以减少drawcall;
- 文字内容好像会打断drawcall;
- 节点的遍历顺序是深度优先遍历的;
那么就让我们带着这三个猜测去看cocos2dx的渲染代码。
前面文章我们讲过游戏从开始到每帧刷新的步骤,这次我们直接从drawScene函数开始看。
 图1
图1
图1: 在CCDirector文件中有一个函数mainloop,其中包含了渲染场景的起点drawScene()
 图2
图2
图2:其中首先去render当前运行的场景。

 图3
图3
图3:最终调到了scene的render 函数里,这里我们看见了一个老熟人——camera,这里我们去看看,这个camera到底是哪里来的。
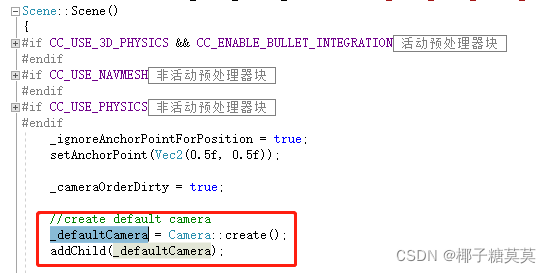 图4
图4
图4:原来是在Scene的构造函数里自动帮我们创建了一个camera,并加入到场景中。
上面的scene::render里还传递了一个函数,mat4,也就是4x4的matrix(矩阵),矩阵的效果是什么呢?在空间里变换,为了方便计算,会把模型空间坐标(也就是跟随着父节点的坐标位置)转化为世界空间坐标,再把世界空间坐标转化为视图空间坐标(也就是摄像机看到的世界,也可以说以摄像机为原点),最后再把视图空间坐标转化为投影空间坐标(正交和透视),这个过程会使用矩阵运算来完成,也就是MVP(model-view-projection),只需要把点或向量和变换矩阵相乘就可以得到新空间中的值。
这里也可以做一个小实验,我们把实验3中的第2张图片的缩放改为-100%,然后比较两个场景的文本文件:
可以看到只有图片2的数据里改变了 缩放属性,他的子节点text_2并没有缩放属性的修改,但是实际表现上他是跟随着父节点缩放了大小的,而实现原理就是通过父节点的矩阵运算得到最终效果。理解了这个原理,更详细的就不再这里展开了。

回到Scene::render中,我们接着玩下看:
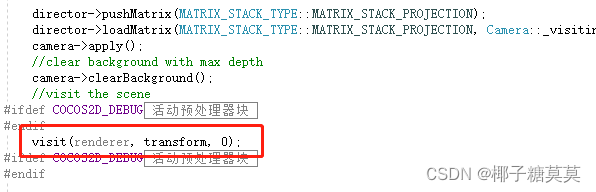 图5
图5
我们看到有一个visit函数,跳转进去
 图6
图6
这里就确认了我们的第三个猜测:节点的遍历顺序是深度优先遍历的;
但是有一点不同的是,除了顺序遍历这一个特点外,更为优先的是localzorder值。在第一个红框上面有一行sortAllChildren(),这个函数是把所有子节点按照localzorder由小到大排序。第一个红框里首先顺序遍历所有zorder小于0的值;第二个红框里再调用自己的draw方法;第三个红框里遍历顺序遍历剩下的节点。
而回到我们加载场景的的loadCSBWithLuaTable方法中,如果没有特殊指定zorder,那么就是按节点顺序进行遍历。
 图7
图7
而draw函数是由各个节点类自己重写的,我们就看看之前用到的Sprite和Label吧。
这里第一个红框里有一个比较有趣的函数,checkVisibility 判断本节点是否在屏幕中,也就是第一个红框。
图8
红框里的代码会先把节点中心点的模型坐标转化为世界坐标,然后再通过摄像机的projectGL方法,直接转化为投影坐标,再计算转化为屏幕坐标。然后把该节点的长宽加到屏幕的长宽上,通过判断该点是否在处理之后的屏幕长宽内来判断改节点是否在屏幕内。
回到(图7)Sprite::draw方法的第二个红框里。
这里有一个 _trianglesCommand.init 方法,那么这个东西是什么呢?
他是Sprite节点类包含的一个 TrianglesCommand 实例。
在cocos的renderer文件夹中除了TrianglesCommand类,还包含了CCQuadCommand、CCCustomCommand、CCBatchCommand、CCGroupCommand、CCMeshCommand和CCPrimitiveCommand。
其中GROUP_COMMAND是命令集合,QUAD_COMMAND是TRIANGLES_COMMAND的扩展类,真正的渲染命令只有5种:CUSTOM_COMMAND用于自定义绘制,BATCH_COMMAND批次渲染图集,MESH_COMMAND网格渲染,主要用于渲染3D模型(Sprite3D),PRIMITIVE_COMMAND用于点线等的绘制,TRIANGLES_COMMAND三角形绘制,主要绘制按钮,图片等矩形控件(sprite)。
Sprite::draw方法初始化了_trianglesCommand实例,并调用renderer的addCommand方法,把三角形命令加入到队列中。
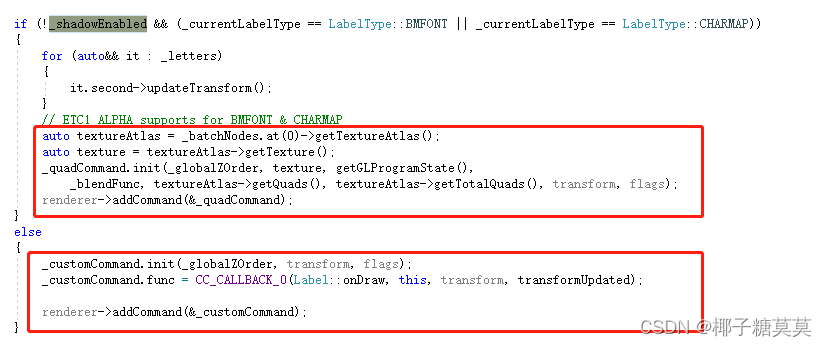 图10
图10
Label::draw方法则依据是否有阴影和是否是BMFONT或CHARMAP来使用quad和custom。
 图11
图11
addCommand最终加入到的是_renderGroups中。
_renderGroups实际上就是一个RenderQueue的队列。
 图13
图13
push_back是根据command不同的golbalOrder值来加入到不同队列的。golbalOrder值是在节点类中初始化command传递的,也通过 setGlobalZOrder 来设置不同的值。golbalOrder和loaclzorder一样也控制着渲染顺序,并且优先级更高于loaclzorder,值越小越先渲染。
当所有的渲染命令都加入到队列中后回到(图5)Scene::render函数中,前面已经调用visit完成了addCommand操作,接下来就来到
渲染器的render函数
 图15
图15
首先对渲染队列进行排序
 图16
图16
不同的队列使用不同的排序方法。
然后调用Render::render函数中的visitRenderQueue方法。
 图17
图17
顺序遍历不同的命令队列。
 图18
图18
我们挑zero命令队列来看,首先调用opengl的函数,开启深度测试,启用深度写入,打开混合,关闭背面剔除功能(其实这里按理说不用渲染背面,除非有翻转动作……)等。
然后调用依次调用processRenderCommand方法。
 图19
图19
processRenderCommand里也是依据不同的命令类型来做处理,红框里可以看到对于三角形命令做了合批的处理。
当当前三角形命令中的顶点数和索引数不超过一个阈值时就可以加入到三角形命令队列中。如果超过了就调用drawBatchedTriangles方法。
 图20
图20
还有一个触发点是如果processRenderCommand调用的不是三角形命令,如
 图21
图21
会先调用flush函数。
 图22
图22
flush函数中也调用了drawBatchedTriangles函数,做最终的三角形命令队列合批操作。这里我就明白了第二个猜想:为什么两个图片中间的文字会打断合批,这是因为文字的渲染命令不是三角形命令。
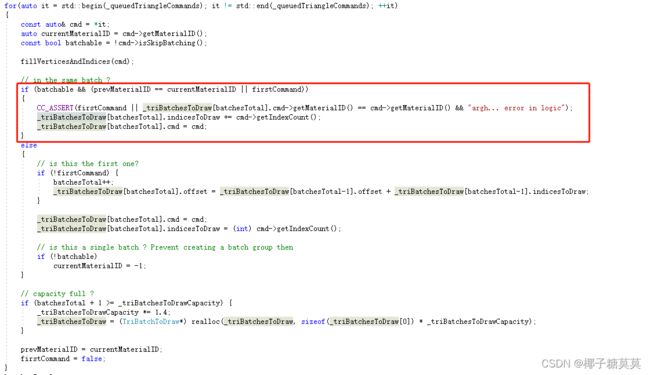 图23
图23
首先遍历所有三角形命令,如果_materialid是相等的就可以放到一个_triBatchesToDraw堆栈中。
 图24
图24
_materialid是包含纹理id的一个hash值,因此我们就了解到第一个猜想:合图让纹理id变为同一个,所以才可以实行合批策略。
 图25
图25
而TriBatchToDraw是一个 结构体,包含三角形命令,绘制索引和偏移量。
同一个合图中的图片资源,会把绘制索引加入到同一个_triBatchesToDraw的绘制索引上,偏移量就是之前计算过的所有的绘制索引的总值。
 图26
图26
全部三角形命令队列执行完毕后,调用gl方法将顶点/索引复制到GL对象,最后依次执行_triBatchesToDraw堆栈中的draw命令,最后清空所有队列。
至此整个渲染过程执行完毕。
引发的思考:是不是只有Sprite类型才能做合批处理呢?
我们常用的Image,Button,CheckBox,贴图Layout等他们实际上内核都是Sprite或者Scale9Sprite,而这两个都是三角形渲染命令的。比较特殊且有意思的是是fnt字体,他们其实用的也是纹理资源,底层渲染命令是QuadCommand,而QuadCommand其实也只是TrianglesCommand的扩展类,真正加入到渲染队列中的也是TrianglesCommand渲染命令。
合理猜想,大胆假设:如果我们把纹理资源也加到合图中,那么fnt字会不会也加入到合批处理中呢?
3,2,1公布答案!
——————————————————————————————————
答案是不能。
原因很简单,因为fnt字资源中的file文件是写死的,也就是单独的那一张图,即使你把他加入到了合图中,也只不过是合图中也有一张fnt字纹理资源而已,到底层合批处理那一步判断的textureid并不相同。
合理猜想,大胆假设:我们都知道fnt字也不过是根据索引在纹理中判断偏移量来展示纹理,如果我们改一下fnt字的底层,在创建fnt字纹理时优先去合图文件中取?
这个就留待你们去验证啦~
那么fnt字是不是无法合批呢?
在特定条件下还是可以的,如果两个fnt字用的时同一个纹理,并且加入渲染的顺序是连续的,就会被加到同一个批次中去。
了解了合批策略我们能做什么呢?
比如有一个界面背包:需要展示12个背景,背景上有12个不同的物品,还有12个数字展示数量,按我们正常的摆放界面的习惯,背景一层,上面套一个物品图片,再上面套一个text节点,然后再摆放下一个背景……这样就会有36次drawcall。但如果我们稍稍改变一下层级,所有背景放在一层,所有的物品放在一层,并且把不同的物品图片放到一张合图里(一般我们都会选择这么干,可能不会把背景放进来),使用的所有fnt字并且把他们也放在一层。这样最多只需要3次drawcall就能够完成界面渲染!是不是质的提升!
本篇文章先讲到这里,下一章我会带大家看一下神奇的(shader)着色器代码。
如果觉得有帮助请给我点赞并收藏哦~您的支持是我最大的鼓励~
