密码学总结杂七杂八的wp
快捷键
折叠(展开)所有代码这里是指按下快捷键后凡事.py文件里可折叠的都折叠。
折叠所有代码:Ctrl + Shift + - (减号)
展开所有代码:Ctrl + Shift + + (加号)
折叠(展开)某一层所有代码这里指的是比如if嵌套一个for两个都可折叠,那么光标在 if 按下此快捷键每一层都折叠。
折叠某一层所有代码:Ctrl + Alt + - (减号)
展开某一层所有代码:Ctrl + Alt + + (加号)
单层折叠(展开)这里指比如 if 嵌套一个 for 两个都可折叠,那么光标在 if 按下此快捷键只折叠光标对应的这层 if 里面的 for 是不折叠的。
折叠单层:Ctrl + -(减号)
展开单层:Ctrl + +(加号)
为什么要折叠代码?
当代码量多的时候折叠代码可以让我们更容易浏览想要的内容、更简洁。
这个跟为什么雨伞不用的时候要收起来?为什么衣服不穿的时候要折起来?的道理差不多。
————————————————
版权声明:本文为CSDN博主「无梦生7」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:简要说明三个 Pycharm 折叠代码快捷键_无梦生7的博客-CSDN博客这个错误消息表明您的代码中存在
包的冲突问题
与OpenSSL包的lib模块中的X509_V_FLAG_CB_ISSUER_CHECK属性相关的AttributeError。此错误可能是由不兼容的包版本或损坏的安装引起的。
- 检查包版本:确保您安装了最新版本的
scrapy和OpenSSL。您可以在Anaconda命令提示符中使用以下命令来更新包:
conda update scrapy
conda update opensslconda update scrapy
conda update openssl
- 重新安装
OpenSSL包:有时候,OpenSSL的安装可能会损坏。您可以尝试使用以下命令重新安装包:
conda install openssl --force-reinstallconda install openssl --force-reinstall
- 重新安装
scrapy:如果上述步骤无法解决问题,您可以尝试使用以下命令重新安装scrapy包:
conda install scrapy --force-reinstallconda install scrapy --force-reinstall
执行这些步骤后,尝试再次运行您的脚本,看看错误是否仍然存在。如果问题仍然存在,您可能需要提供关于您的环境(Python版本、包版本、操作系统)的更多详细信息,以便进一步调查该问题。
三线格子制作

ssl问题什么原因呢
AttributeError: module 'lib' has no attribute 'X509_V_FLAG_CB_ISSUER_CHECK'
C:\Users\韩东平>pip install pyOpenSSL --upgradeRequirement already satisfied: pyOpenSSL in d:\amaconda\lib\site-packages (19.1.0)Collecting pyOpenSSL Downloading pyOpenSSL-23.2.0-py3-none-any.whl (59 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 59.0/59.0 kB 519.1 kB/s eta 0:00:00Requirement already satisfied: cryptography!=40.0.0,!=40.0.1,<42,>=38.0.0 in d:\amaconda\lib\site-packages (from pyOpenSSL) (39.0.1)Requirement already satisfied: cffi>=1.12 in d:\amaconda\lib\site-packages (from cryptography!=40.0.0,!=40.0.1,<42,>=38.0.0->pyOpenSSL) (1.14.6)Requirement already satisfied: pycparser in d:\amaconda\lib\site-packages (from cffi>=1.12->cryptography!=40.0.0,!=40.0.1,<42,>=38.0.0->pyOpenSSL) (2.20)Installing collected packages: pyOpenSSL Attempting uninstall: pyOpenSSL Found existing installation: pyOpenSSL 19.1.0 Uninstalling pyOpenSSL-19.1.0: Successfully uninstalled pyOpenSSL-19.1.0Successfully installed pyOpenSSL-23.2.0
pyd文件加密解密
上次写了一个pyd逆向,在文章末尾讲了hook模块等方法。现在来完善一下。众所周知,python打包的exe,如果没加任何加密的话,源码是可以很容易被轻松逆向出来的。所以就会有人会将python代码打包成pyd文件。其实就是一种dll文件。来增加破解难度。
作者:人间失格
链接:https://www.zhihu.com/question/347425323/answer/2701116472
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
公钥体系中用公钥加密
rsa算法中
私钥体系中,验证签名,私钥掌握在自己手里
这段文本涉及到公钥加密和数字签名技术中的一些概念。
在公钥体系中,加密和解密使用不同的密钥。公钥用于加密数据,而私钥用于解密数据。这种体系的优点是可以确保数据传输的安全性,因为即使公钥被泄露,攻击者也无法解密数据。
RSA算法是一种常见的公钥加密算法,它基于大素数分解的难题。私钥体系中,数字签名用于验证消息的完整性和真实性。数字签名是使用私钥对消息进行加密,以便在接收方使用公钥进行解密,并验证消息是否被篡改或伪造。
因此,在RSA算法中,私钥用于验证签名,以确保消息的完整性和真实性。私钥通常由消息的发送方掌握,以确保只有授权的人可以对消息进行签名和验证。
https://www.cnblogs.com/yiyide266/p/9393169.html
实践
导入rsa模块,随机产生n,p,q,e和d,对明文“meet at the nature park at seven ”进行加密运算,求密文是多少?(编程题提交代码jupyter文件+运行结果的截图或照片)
在RSA加密算法中,n、p、q、e和d都是密钥的组成部分。
其中,n是公钥和私钥的一部分,是两个大质数p和q的乘积。p和q是两个大质数,它们应该足够大以保证安全性。只有知道p和q,才能计算出n。
e是公钥的一部分,是一个小于(p-1)×(q-1)的正整数,且与(p-1)×(q-1)互质。e和(p-1)×(q-1)的最大公约数为1。e的选择可以使用欧拉函数φ(n),φ(n)等于(p-1)×(q-1),然后选择一个与φ(n)互质的整数e。
d是私钥的一部分,是一个满足ed ≡ 1 (mod (p-1)×(q-1))的正整数。d的计算可以使用扩展欧几里得算法来实现。
在RSA加密算法中,公钥是(n,e),私钥是(n,d)。加密时使用公钥进行加密,解密时使用私钥进行解密。
import rsa # 生成RSA密钥对
(pubkey, privkey) = rsa.newkeys(512)
# 加密明文
message = b'meet at the nature park at seven '
ciphertext = rsa.encrypt(message, pubkey)
# 解密密文
plaintext = rsa.decrypt(ciphertext, privkey)
print(plaintext)import rsa # 生成RSA密钥对
(pubkey, privkey) = rsa.newkeys(512)
# 加密明文
message = b'meet at the nature park at seven '
ciphertext = rsa.encrypt(message, pubkey)
# 解密密文
plaintext = rsa.decrypt(ciphertext, privkey)
print(plaintext)
from cryptography.hazmat.primitives.asymmetric import rsa, padding
from cryptography.hazmat.primitives import serialization
from cryptography.hazmat.backends import default_backend
# 生成RSA密钥对
private_key = rsa.generate_private_key(
public_exponent=65537,
key_size=2048,
backend=default_backend()
)
public_key = private_key.public_key()
# 明文
message = b"meet at the nature park at seven"
# 使用公钥加密
ciphertext = public_key.encrypt(
message,
padding.OAEP(
mgf=padding.MGF1(algorithm=hashes.SHA256()),
algorithm=hashes.SHA256(),
label=None
)
)
# 打印密文
print("密文:", ciphertext)
from cryptography.hazmat.primitives.asymmetric import rsa, padding
from cryptography.hazmat.primitives import serialization
from cryptography.hazmat.backends import default_backend
# 生成RSA密钥对
private_key = rsa.generate_private_key(
public_exponent=65537,
key_size=2048,
backend=default_backend()
)
public_key = private_key.public_key()
# 明文
message = b"meet at the nature park at seven"
# 使用公钥加密
ciphertext = public_key.encrypt(
message,
padding.OAEP(
mgf=padding.MGF1(algorithm=hashes.SHA256()),
algorithm=hashes.SHA256(),
label=None
)
)
# 打印密文
print("密文:", ciphertext)
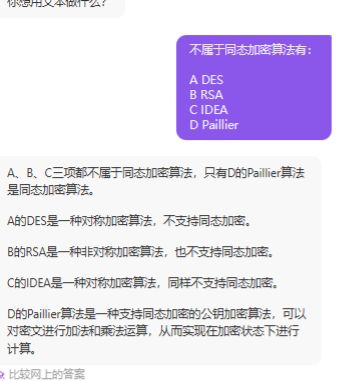
同态加密
无可信第三方的委托计算
用户可以使用同态加密将数据上传到云端,而无需暴露明文数据,云端可以对密文进行计算,然后返回计算结果给用户,从而保护了数据的隐私性。
同态加密有三种类型:完全同态加密、部分同态加密和近似同态加密。完全同态加密可以进行任何计算,包括加法和乘法,而部分同态加密只能进行一种计算,例如只能进行加法或乘法。近似同态加密允许进行多次计算,但是每次计算都会使得结果的误差逐渐增大
全同态
实践
同态加密验证。简单的同态加密包含加法同态和乘法同态,加法同态算法最经典的是Paillier算法,乘法同态算法最经典的是RSA算法。以下是RSA算法同态验证说明:
设: a*b=c (基础等式)
其中:加密函数e(),解密函数d() [enctrypt:加密;decrypt:解密]
乘法同态特为:e(a)*e(b)=e(c)
c=d(e(c))=d(e(a)*e(b))
验证c 是否等于a*b,即可得到乘法同态的正确性。
(编程题提交代码jupyter文件+运行结果的截图或照片)
# 同态加密验证。简单的同态加密包含加法同态和乘法同态,加法同态算法最经典的是Paillier算法,乘法同态算法最经典的是RSA算法。以下是RSA算法同态验证说明:
# 设: a*b=c (基础等式)
# 其中:加密函数e(),解密函数d() [enctrypt:加密;decrypt:解密]
# 乘法同态特为:e(a)*e(b)=e(c)
# c=d(e(c))=d(e(a)*e(b))
# 验证c 是否等于a*b,即可得到乘法同态的正确性。
# (编程题提交代码jupyter文件+运行结果的截图或照片)# 同态加密验证。简单的同态加密包含加法同态和乘法同态,加法同态算法最经典的是Paillier算法,乘法同态算法最经典的是RSA算法。以下是RSA算法同态验证说明:
# 设: a*b=c (基础等式)
# 其中:加密函数e(),解密函数d() [enctrypt:加密;decrypt:解密]
# 乘法同态特为:e(a)*e(b)=e(c)
# c=d(e(c))=d(e(a)*e(b))
# 验证c 是否等于a*b,即可得到乘法同态的正确性。
# (编程题提交代码jupyter文件+运行结果的截图或照片)
安全多方计算和安全计算不是同一个概念。
安全多方计算(Secure Multi-Party Computation,简称SMPC)是一种协议,允许多个参与方在不暴露私有输入的情况下进行计算,并获得计算结果。SMPC协议可以保证在任何情况下,参与方的私有输入都不会被泄露,同时也不会泄露计算结果。
安全计算(Secure Computation)是一种通用的概念,用于描述在计算过程中保护数据隐私和计算结果的技术。安全计算包括多种技术,如同态加密、差分隐私、加密多方计算等,这些技术都旨在保护数据隐私,防止恶意攻击者获取敏感信息。
因此,可以说安全多方计算是安全计算的一种具体实现方式,但并不等同于安全计算。
数据脱敏
不可逆脱敏(Irreversible De-identification)是一种数据脱敏技术,它将敏感数据进行加密或哈希等转换,使得原始数据无法恢复,从而保护数据隐私。
与可逆脱敏技术不同,不可逆脱敏技术无法将脱敏后的数据转换回原始数据。这种技术通常应用于需要保护数据隐私的场景,例如金融、医疗等领域。
不可逆脱敏技术的优点是可以有效地保护数据隐私,同时减少数据泄露的风险。但是,由于无法将脱敏后的数据转换回原始数据,因此在一些场景下可能会影响数据分析和挖掘的效果。因此,在选择脱敏技术时,需要根据具体场景和需求来选择适合的脱敏方案。
可恢复 (各类加密解密)
不可恢复(替换算法、生成算法)
数据脱敏规则一般分类为两类。
A.可变形与不可变形
B.可加密与不可加密
列
| 姓名 |
电话号码 |
邮寄内容 |
邮寄地址 |
| 王旭彤 |
15821897278 |
文件 |
中国人民警察大学智慧警务七队 |
| 李培源 |
15121898307 |
化妆品 |
中国人民警察大学智慧警务七队 |
| 曹晓言 |
13121898462 |
鞋 |
中国人民警察大学智慧警务七队 |
| 赵文浦 |
19121892537 |
拉杆箱 |
中国人民警察大学智慧警务七队 |
| 王艺霖 |
13721891477 |
口红 |
中国人民警察大学智慧警务七队 |
| 孙诚睿 |
15566897278 |
衣服 |
中国人民警察大学智慧警务七队 |
| 王泽升 |
15121898307 |
去油贴 |
中国人民警察大学智慧警务七队 |
| 杜英慧 |
15321898462 |
usb数据线 |
中国人民警察大学智慧警务七队 |
| 牛易航 |
18921892537 |
袜子 |
中国人民警察大学智慧警务七队 |
| 李育骏 |
13721891477 |
裤子 |
中国人民警察大学智慧警务七队 |
| 黄棋 |
15821897278 |
体恤衫 |
中国人民警察大学智慧警务七队 |
| 陈泽 |
15121898307 |
刮胡刀 |
中国人民警察大学智慧警务七队 |
| 罗日坤 |
15321898462 |
鲜花 |
中国人民警察大学智慧警务七队 |
| 付彦斌 |
19121892537 |
新鲜水果 |
中国人民警察大学智慧警务七队 |
| 郑莹 |
13721891477 |
方便面 |
中国人民警察大学智慧警务七队 |
| 林景玮 |
15821897333 |
文件 |
中国人民警察大学智慧警务七队 |
快递单加密 防隐私泄露!
“面单上消费者的名字和电话号码中间4个数字,都被*字符代替。“我们暂时保留了一些地址信息,主要用于帮助快递员核对包裹。”周磊表示,未来会不断加强信息脱敏力度。“现在是隐去了消费者的手机号码,以后包裹上的消费者相关信息会越来越少”。”
现有“kuaidiuser.xlsx”文件一个,请用Python编程,将“kuaidiuser.xlsx”文件,消费者名字只保留姓,电话中间4位用“*”代替(158****7278),邮寄物品只保留第一个字,隐去队别信息。
提交要求:
1,需提交jupyter代码文件,并将运行结果截图或拍照上传。
k匿名
显示标识符,饮食标识符,敏感信息(需要保护,不想告诉别人)
【k-匿名(k-Anonymity)代码实现】差分隐私代码实现系列(三)_k匿名实现_粥粥粥少女的拧发条鸟的博客-CSDN博客
处理方法
https://www.cnblogs.com/jiangshaoyin/p/10190540.html
抑制
泛化
| name |
date_of_birth |
sex |
zip |
illness |
| Thomas |
19780808 |
male |
72021 |
Cancer |
| Kim |
19780909 |
male |
72000 |
Cancer |
| Herbert |
19780710 |
male |
72059 |
Cancer |
| Peter |
19780809 |
male |
72062 |
Poisoning |
| Frederica |
19980102 |
female |
63331 |
Strain |
| Anika |
19980216 |
female |
63321 |
Flue |
| Tamara |
19980329 |
female |
63309 |
Dementia |
| Michaela |
19980101 |
female |
63392 |
Hairloss |
| Louis |
19870520 |
male |
89721 |
Caries |
| Simon |
19870602 |
male |
89777 |
Acne |
| Karl |
19870525 |
male |
89733 |
Caries |
| Florian |
19870429 |
male |
89777 |
Acne |
| Holger |
19900426 |
male |
77462 |
Poisoning |
| Leopold |
19900427 |
male |
77409 |
Dementia |
| Sebastian |
19900502 |
male |
77431 |
Strain |
| Christian |
19900418 |
male |
77421 |
Flue |
| Katharina |
19911017 |
female |
76192 |
Hairloss |
| Anna |
19911520 |
female |
76189 |
Flue |
| Charlotte |
19912002 |
female |
76133 |
Caries |
| Kathy |
19911012 |
female |
76133 |
Flue |
数据集data.csv,有以下字段,如图所示(文件见附件),请用K匿名算法实现隐私保护。
提交要求
qid少出现重复几次就是,就是k匿名
k是可选的
差分隐私
差分隐私技术的核心在于其 **随机算法** 的设计。差分隐私是一种保护个人隐私的技术,它通过向数据添加噪声来保护个人身份信息。在差分隐私中,随机算法是一种常用的技术,它可以在保护数据隐私的同时,尽可能地保持数据的准确性和有用性。
这个文本提到的是数据的抑制,它是指对 **显式标识符** 做不发布处理。在数据处理中,为了保护个人隐私,有时需要对数据进行抑制处理。抑制是一种数据保护技术,它通过删除或替换敏感信息来保护个人隐私。在这里,显式标识符是指可以直接或间接地识别个人身份的信息,如姓名、地址、电话号码等。对显式标识符进行抑制处理可以有效地保护个人隐私。
数据匿名话
这个文本提到了匿名化的反面,其中包括 **再识别或反匿名化**。在数据处理中,匿名化是一种常用的数据保护技术,它通过删除或替换个人身份信息来保护个人隐私。匿名化的目的是实现数据共享和发布,同时保护个人隐私。匿名化的反面是再识别或反匿名化,它指的是通过技术手段将匿名化后的数据还原成原始数据,从而揭示出数据主体的身份信息。再识别或反匿名化技术可以对匿名化数据进行分析和处理,从而揭示出数据主体的身份信息。其他选项中,数据查找、数据再现和隐私识别都不是匿名化的反面。数据查找是指在数据库中查找特定的数据;数据再现是指将数据从一个格式转换为另一个格式;隐私识别是指使用数据分析技术识别出个人身份信息。
B 个人数据。简单的匿名化处理通常只是将个人数据中的识别信息删除或替换成不可识别的字符,以达到保护隐私的目的。这里的个人数据指的是可以用来唯一识别个体身份的信息,如姓名、身份证号等。关键字符和敏感字符都是指代个人数据中具有敏感性质的信息,无法简单过滤掉;而显式标识符则是指表示个体身份的特定符号或代码,类似于个人数据中的识别信息,也需要进行更复杂的处理才能得到有效的匿名化效果。
数据泛化
这个文本提到了数据泛化的定义,其中包括 **将数据集中与任务相关的数据以较低的概念层次抽象到较高的概念层次的过程**。在数据处理中,数据泛化是一种常用的数据保护技术,它通过将数据集中与任务相关的数据以较低的概念层次抽象到较高的概念层次的过程来保护数据隐私。数据泛化的目的是实现数据共享和发布,同时保护数据隐私。在数据泛化过程中,数据管理员会对数据进行抽象、概括或者模糊化处理,以保护数据隐私。其他选项中,数据抑制是删除或完全省略部分数据以保护数据主体的身份;数据失真是改变数据的值以保护数据隐私;数据识别是将匿名化后的数据还原成原始数据以揭示出数据主体的身份信息。
苹果---水果
表示符号
这个文本是一个单选题,其中提到了一个术语:**标识符**。标识符是指用于唯一标识一个人或实体的信息或属性。在数据隐私保护中,标识符是一种敏感信息,需要得到妥善的保护。在本题中,问题是联合起来能唯一标识一个人的多个属性的标识符是什么?答案是 **准标识符**。准标识符是指由多个非敏感属性组合而成的标识符,它可以用来唯一标识一个人或实体,但本身并不包含敏感信息。准标识符可用于数据匿名化等隐私保护技术中,以避免敏感信息被泄露。其他选项中,显式标识符是指明确表示某个人或实体的标识符;敏感标识符是指包含敏感信息的标识符;数据标识符是指用于标识数据集中某个数据记录的标识符。
The size of the network (639)exceeds the limit of this version (500).
Reduce the size,e.g. ,reduce the number of years,or lower the k value for g-index,and then try again.
T-相近隐私保护模型需上任一群组中敏感值的分布接近于整体表中的属性分布
B QID。相近隐私保护模型(也称差分隐私模型)是一种隐私保护算法,常被用于对结构化数据进行去识别化处理,以实现数据共享的目的。其中QID(Quasi-Identifiers)是指在某个数据集中能够唯一或几乎唯一标识一个个体身份的组合属性变量,并且它与敏感信息可以组合成敏感值。相近隐私保护模型会为QID 加入噪声,在数据发布前通过加噪器、扰动器等方式注入一定程度的噪声,从而保证对敏感信息的保护。该模型的基本思想是:对任意相邻的数据集,都具有较高概率生成相近的输出结果。这意味着,在一个数据表中,任意一组数据的敏感值分布接近于整体数据表中的数据属性分布,从而达到了保护隐私不损失数据质量的目的。AIC、BBC 和 AED 不是隐私保护相关的术语。
去标识化
D 去标识化建立在个体基础之上,保留了个体颗粒度,采用哈希函数等技术手段代替对个人信息的标识。
去标识化是一种数据处理方式,通过去除个人身份信息中的标识符(例如姓名、身份证号码等),将其变为匿名或伪匿名信息。与个人信息的初始状态相比,去标识化后得到的数据得以避免用户信息泄露的风险,但仍然能够被研究者利用以进行二次分析。因此,去标识化并不能完全规避“ 能够单独或者与其他信息结合识别自然人个人身份”这个问题。另外,不同于匿名化,去标识化在保护个人隐私的同时可以保留个体颗粒度,也即可以保留部分特征信息以使得研究者可以利用这些匿名化的数据进行二次分析。
Hadoop平台提供安全管理和授权功能的组件包括以下几种:
A. Sentry:是Apache Hadoop中的一个重要子项目,主要用于对Hadoop的访问控制进行细粒度的管理,可以通过Sentry来定义哪些用户或群组有权访问特定数据库、表、列族等对象,从而实现数据的细粒度权限控制。
B. Knox:是Apache Hadoop生态系统中的网关应用程序,可以为整个Hadoop集群提供安全的访问入口,同时能够处理不同协议、不同版本之间的差异,并且具备开箱即用的WebUI界面和REST API接口。
C. Ranger:是一个开源的Hadoop安全管理解决方案,可以提供整个Hadoop生态系统的安全管理和授权服务,其主要功能包括审计、访问控制、数据掩码、加密等。
D. Impala:是一个高效的SQL查询引擎,可以在Hadoop生态系统的内存和磁盘上执行SQL语句。Impala通过Kerberos网络认证和集成到Apache Sentry等授权框架来提供安全性。
DOCKER
下列关于docker虚拟化技术描述错误的是:B. Docker就是虚拟机:Docker并不是虚拟机,而是一种轻量级的容器化技术。与虚拟机不同,Docker不需要模拟硬件环境,而是共享宿主机的操作系统内核,因此启动速度更快,资源占用更少,且更加灵活。其他选项描述如下:A. Docker是一个开源的应用容器引擎:正确。Docker是一个开源的应用容器引擎,可以帮助开发人员快速构建、打包、部署和运行应用程序。C. Docker是重量级虚拟化技术:错误。Docker是一种轻量级的容器化技术,与传统的重量级虚拟化技术相比,Docker更加轻便、快速、灵活。D. Docker是半虚拟化技术:错误。Docker使用的是操作系统层面的虚拟化技术,也称为容器化技术,而不是半虚拟化技术。
ctf
美亚,长安,盘古石做了四年的misc
rev和pwn
链接库
数据库链接
Traceback (most recent call last): File "C:\Users\韩东平\机器学习\obe\数据库管理软件obe\lyx\李宇轩_mysql.py", line 69, inconnection = mysql.connector.connect( File "D:\Amaconda\lib\site-packages\mysql\connector\pooling.py", line 293, in connect return CMySQLConnection(*args, **kwargs) File "D:\Amaconda\lib\site-packages\mysql\connector\connection_cext.py", line 120, in __init__ self.connect(**kwargs) File "D:\Amaconda\lib\site-packages\mysql\connector\abstracts.py", line 1181, in connect self._open_connection() File "D:\Amaconda\lib\site-packages\mysql\connector\connection_cext.py", line 291, in _open_connection self._cmysql.connect(**cnx_kwargs) RuntimeError: Failed raising error. 进程已结束,退出代码1 Traceback (most recent call last): File "C:\Users\韩东平\机器学习\obe\数据库管理软件obe\lyx\李宇轩_mysql.py", line 69, inconnection = mysql.connector.connect( File "D:\Amaconda\lib\site-packages\mysql\connector\pooling.py", line 293, in connect return CMySQLConnection(*args, **kwargs) File "D:\Amaconda\lib\site-packages\mysql\connector\connection_cext.py", line 120, in __init__ self.connect(**kwargs) File "D:\Amaconda\lib\site-packages\mysql\connector\abstracts.py", line 1181, in connect self._open_connection() File "D:\Amaconda\lib\site-packages\mysql\connector\connection_cext.py", line 291, in _open_connection self._cmysql.connect(**cnx_kwargs) RuntimeError: Failed raising error. 进程已结束,退出代码1
这个错误是在连接到MySQL数据库时发生的问题。根据错误信息,它似乎是由于无法建立数据库连接而引起的。
可能的原因和解决方案如下:
- 检查数据库连接参数:确保在连接MySQL时提供了正确的主机名、用户名、密码和数据库名。请检查您的代码中的连接参数部分,并确保它们与您的MySQL服务器配置相匹配。
- 确保MySQL服务器正在运行:请确保您的MySQL服务器正在运行并且已启动。您可以尝试通过命令行或其他工具连接到MySQL服务器,以验证服务器是否正常工作。
- 检查防火墙设置:如果您的MySQL服务器位于另一台计算机上,确保防火墙允许从您的计算机连接到MySQL服务器的流量。如果防火墙阻止了数据库连接请求,您将无法建立连接。请检查您的防火墙设置,并确保允许与MySQL服务器的通信。
- 确保MySQL Python驱动程序已正确安装:请确保您的Python环境中安装了正确的MySQL连接驱动程序。根据您的代码中使用的驱动程序,可能需要安装
mysql-connector-python或pymysql等库。您可以使用pip命令来安装所需的库。
这些是常见的解决连接到MySQL数据库时遇到问题的方法。根据您的具体情况,您可能需要进一步检查和调试来确定导致连接问题的确切原因。
import mysql.connector
connection = mysql.connector.connect(
host="localhost",
user="root",
password="",
database="公交线路统计"
)
cursor = connection.cursor()
# 创建游标对象
cursor = connection.cursor()
# 执行SQL查询和操作
# 例如:
cursor.execute("SELECT * FROM 表名")
result = cursor.fetchall()
# 处理查询结果
for row in result:
print(row)
# 关闭游标和数据库连接
cursor.close()
connection.close()connection = mysql.connector.connect(
host="localhost",
user="root",
password="",
database="公交线路统计"
)
cursor = connection.cursor()
# 创建游标对象
cursor = connection.cursor()
# 执行SQL查询和操作
# 例如:
cursor.execute("SELECT * FROM 表名")
result = cursor.fetchall()
# 处理查询结果
for row in result:
print(row)
# 关闭游标和数据库连接
cursor.close()
connection.close()
表的构建
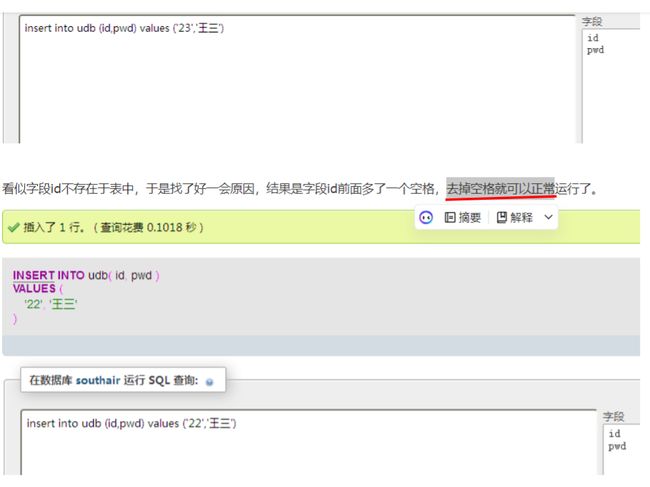
mysql.connector.errors.ProgrammingError: 1146 (42S02): Table 'db_sc.xx' doesn't existmysql.connector.errors.ProgrammingError: 1146 (42S02): Table 'db_sc.xx' doesn't exist
增加信息函数,但要提前创建好表格
def add_data_xl():
number = entry_number_xl.get()
responsible_person = entry_responsible_person.get()
line_name = entry_line_name_xl.get()
mileage = entry_mileage.get()
type = entry_type.get()
sql = f"INSERT INTO xl (编号, 负责人, 线路名称, 计算里程, 类型) VALUES ('{number}', '{responsible_person}', '{line_name}', '{mileage}', '{type}')"
cursor.execute(sql)
connection.commit()
entry_number_xl.delete(0, tk.END)
entry_responsible_person.delete(0, tk.END)
entry_line_name_xl.delete(0, tk.END)
entry_mileage.delete(0, tk.END)
entry_type.delete(0, tk.END)
show_xl_data()def add_data_xl():
number = entry_number_xl.get()
responsible_person = entry_responsible_person.get()
line_name = entry_line_name_xl.get()
mileage = entry_mileage.get()
type = entry_type.get()
sql = f"INSERT INTO xl (编号, 负责人, 线路名称, 计算里程, 类型) VALUES ('{number}', '{responsible_person}', '{line_name}', '{mileage}', '{type}')"
cursor.execute(sql)
connection.commit()
entry_number_xl.delete(0, tk.END)
entry_responsible_person.delete(0, tk.END)
entry_line_name_xl.delete(0, tk.END)
entry_mileage.delete(0, tk.END)
entry_type.delete(0, tk.END)
show_xl_data()

主要的函数

列明找不到--防止转义--创建表的问题
Traceback (most recent call last):
File "D:\Amaconda\lib\tkinter\__init__.py", line 1892, in __call__
return self.func(*args)
File "C:\Users\韩东平\机器学习\obe\数据库管理软件obe\lyx\李宇轩_mysql.py", line 189, in add_data_xl
cursor.execute(sql)
File "D:\Amaconda\lib\site-packages\mysql\connector\cursor_cext.py", line 330, in execute
result = self._cnx.cmd_query(
File "D:\Amaconda\lib\site-packages\mysql\connector\connection_cext.py", line 619, in cmd_query
raise get_mysql_exception(
mysql.connector.errors.ProgrammingError: 1054 (42S22): Unknown column '负责人' in 'field list'Traceback (most recent call last):
File "D:\Amaconda\lib\tkinter\__init__.py", line 1892, in __call__
return self.func(*args)
File "C:\Users\韩东平\机器学习\obe\数据库管理软件obe\lyx\李宇轩_mysql.py", line 189, in add_data_xl
cursor.execute(sql)
File "D:\Amaconda\lib\site-packages\mysql\connector\cursor_cext.py", line 330, in execute
result = self._cnx.cmd_query(
File "D:\Amaconda\lib\site-packages\mysql\connector\connection_cext.py", line 619, in cmd_query
raise get_mysql_exception(
mysql.connector.errors.ProgrammingError: 1054 (42S22): Unknown column '负责人' in 'field list'
根据错误消息,您的代码在执行SQL查询时遇到了问题。错误消息指出在字段列表中存在一个未知的列名 '负责人'。
要解决此问题,请注意以下几点:
- 检查列名的拼写和大小写:请确保列名 '负责人' 的拼写和大小写与数据库表中的列名一致。MySQL是区分大小写的,因此列名的拼写和大小写必须准确匹配。
- 检查列是否存在:确保 '负责人' 列确实存在于您指定的表中。您可以使用MySQL客户端工具(如MySQL Workbench)连接到数据库,并查看表结构以验证列是否存在。
- 使用反引号转义列名:如果列名包含特殊字符或保留字,您可以使用反引号将列名转义。例如,如果 '负责人' 是一个包含特殊字符或保留字的列名,您可以这样使用:`负责人`。
以下是一个示例,演示如何在查询中使用反引号转义列名:
sql = "SELECT `负责人` FROM 表名"
cursor.execute(sql)
sql = "SELECT `负责人` FROM 表名"
cursor.execute(sql)
请根据您的具体情况和数据库表结构,适当调整列名和查询语句。
总结:根据错误消息,您的代码中使用了一个未知的列名 '负责人'。请检查列名的拼写和大小写,并确保列存在于数据库表中。如果需要,可以使用反引号转义列名。
SELECT负责人FROM xl
1054-Unknown column'负责人'in'field list'
但是我的表的结构里有
编号
负责人
线路名称
计算里程
类型


机械学习
半监督模型
打一半标签
迁移学习
训练好的直接迁移
高斯模型连续的
伯努利:01,离散的
警情文本处理
import pandas as pd
import numpy as np
data_test=pd.read_excel(r"C:\Users\韩东平\机器学习\obe\警情文本分析源代码obe\警情数据集\警情数据集\X_test.xlsx")
data_test.head()
data_t=data_test['报警内容']
#将报警内容转换为列表
data_t=list(data_t)import pandas as pd
import numpy as np
data_test=pd.read_excel(r"C:\Users\韩东平\机器学习\obe\警情文本分析源代码obe\警情数据集\警情数据集\X_test.xlsx")
data_test.head()
data_t=data_test['报警内容']
#将报警内容转换为列表
data_t=list(data_t)
new_y_test=[]
for i in range(len(y_test)):
if(y_test[i]=='求助'):
new_y_test.append(0)
if(y_test[i]=='治安案件'):
new_y_test.append(1)
if(y_test[i]=='纠纷'):
new_y_test.append(2)
if(y_test[i]=='举报'):
new_y_test.append(3)
if(y_test[i]=='其它报警'):
new_y_test.append(4)
if(y_test[i]=='刑事案件'):
new_y_test.append(5)new_y_test=[]
for i in range(len(y_test)):
if(y_test[i]=='求助'):
new_y_test.append(0)
if(y_test[i]=='治安案件'):
new_y_test.append(1)
if(y_test[i]=='纠纷'):
new_y_test.append(2)
if(y_test[i]=='举报'):
new_y_test.append(3)
if(y_test[i]=='其它报警'):
new_y_test.append(4)
if(y_test[i]=='刑事案件'):
new_y_test.append(5)
磁盘坏道
硬盘提示需要格式化才可使用 此卷不包含可识别的文件系统 拯救RAW格式磁盘内文件教程_哔哩哔哩_bilibili
deni