AIGC时代:未来已来
摘要:人工智能的快速发展使得我们进入了AIGC时代。AIGC时代的到来,将会带来巨大的机遇和挑战。
人工智能的快速发展使得我们进入了AIGC时代,即人工智能与图形计算相结合的时代。在这个时代,人们可以利用云计算、大数据分析等技术来处理和呈现多模态信息。例如,AI系统可以通过语音和图像识别技术对多媒体文件进行分析,从而实现智能的分类、检索和推荐。此外,随着5G和物联网技术的不断发展,多模态信息的处理和应用将会越来越普及。AIGC时代的到来,将会带来巨大的机遇和挑战。
01 AIGC时代:万物皆可AI生成
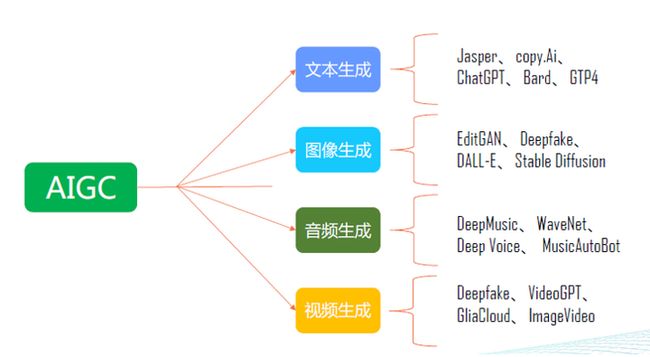
AIGC是一种可以广泛应用于文本、图像、音频和视频生成的人工智能技术。在文本生成方面,它可以运用多种算法进行创作,例如Jasper、copy.Ai、ChatGPT、Bard和GTP4等。在图像生成领域,它可以使用技术如EditGAN、Deepfake、DALL-E和Stable Diffusion等,创造出各种令人惊叹的图片。对于音频生成,AIGC也拥有许多强大的工具,如DeepMusic、WaveNet、Deep Voice和MusicAutoBot等,可以生成高质量的音乐和声音效果。最后,对于视频生成,AIGC同样可以提供很多资源,比如Deepfake、VideoGPT、GliaCloud和ImageVideo等,能够制作出专业级别的视觉效果和动画。总之,AIGC在多个领域都有着广泛的应用前景,并且将会继续不断地发展和完善。体验地址:详情获取
(以上图来自网络)
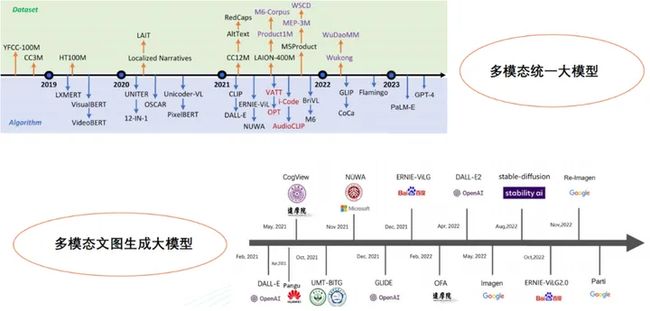
02 多模态大模型的分类与发展脉络
在单模态模型阶段(2012年前),深度学习技术没有普及,研究人员主要关注单一类型的数据处理,例如图像分类模型AlexNet等。
紧接着进入单模态模型融合阶段(2012-2018年),随着深度学习技术的不断发展和应用场景的多样化,研究人员开始尝试将多个单模态模型进行融合,实现不同数据类型之间的交叉学习和融合,例如HT100M、LXMERT、VisualBERT、videoBERT等模型。
目前已经处于多模态统一大模型阶段(2018年至今),研究人员开始提出采用单个模型处理多个数据类型的方法,这类模型通常包含多种输入和输出方式,需要大量的计算资源和数据支持,已经取得良好的效果。例如UNITER模型,它是一个基于Transformer结构的多模态统一大模型,能够同时处理文本、图片和视频等数据类型。它在内部使用了跨模态交叉注意力机制来实现不同数据类型之间的交互,从而使得整个模型能够更好地理解多种数据的语义信息,并取得了领先的性能。
(以上图来自网络)
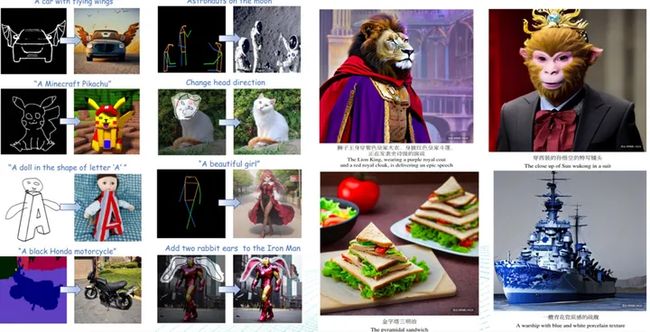
03 文图生成AIGC-变得精致,可控
近年来,随着人工智能技术的不断发展,文图生成技术也得到了显著的进步。今天的文图生成模型不仅能够生成逼真高清的图像,还能够实现更精致的效果,并具备可控性。 在实现更精致的效果上,研究人员针对传统GAN模型存在的缺陷,提出了许多改进方法,如Pix2PixHD、SPADE等。这些模型能够增强模型输出的细节表现力,生成更加真实、精细的图像。 在提高模型的可控性上,研究人员引入了条件图像生成的思想。通过给定不同的条件信息,包括语义标签、风格向量等,可以使模型生成更多样化、个性化的图像。例如,BigGAN、StyleGAN2等模型就能够根据不同的条件生成各种风格迥异的图像。除此之外,研究人员还提出了interpolated GAN和controllable GAN等模型,使得用户可以通过插值等方式来精细控制生成图像的各个细节。 总之,文图生成技术在逼真高清的图像生成上取得了巨大的成功,在精细度和可控性方面也有了很大提高,这些技术的不断进步将为我们带来更加优秀、多样化的文图生成应用。
(以上图来自网络)
然而,文图生成AIGC的出现使得画风变得更加逼真高清,更有风格和意境。文图生成是利用人工智能技术根据输入的文本生成图像。在文图生成的研究中,逼真高清、融合多种风格和意境的图像生成是重要的研究方向。其中,高清作画模型如Google Imagen,能够实现高分辨率、逼真的图像生成;而意境绘画模型如StableDiffusion,则注重于将多种风格和意境进行融合,生成更加个性化、有深度的图像。这些模型的应用场景非常广泛,如艺术创作、平面设计等领域。

(以上图来自网络)
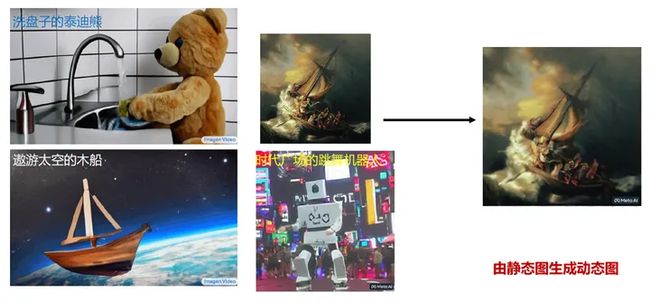
04 视频生成AIGC – 自然流畅、栩栩如生
视频生成AIGC(Artificial Intelligence Generated Content)技术正越来越成熟,能够使得生成的视频像真实一样自然流畅、栩栩如生。 视频生成AIGC技术所用的算法和模型也得到了不断的优化和改进。新型的神经网络算法、光学与物理学建模等技术被引入到视频生成AIGC中,使得生成的视频更加逼真。 视频生成AIGC的研究重点在于如何捕捉到影片的场景、运动和情绪,以此生成自然流畅的视频。为此,研究人员将深度学习算法应用于视频生成,使得机器可以从大量的视频数据中学习各种动作和情感,从而产生栩栩如生的视频。此外,生成的视频不仅要接近真实,还要做到自然流畅。研究人员还提出了许多技术手段,比如光流分析、双向循环生成模型等,能够在不同场景下实现平滑过渡,从而使得视频更加自然流畅。 视频生成AIGC技术的发展使得我们可以生成更加逼真、自然流畅的视频,应用场景非常广泛,如影视制作、游戏开发等领域。未来,视频生成AIGC将会进一步推进技术的发展和创新,给我们带来更多的惊喜和新体验。
(以上图来自网络)
05 多模态AIGC大模型驱动的具身智能
多模态AIGC大模型驱动的具身智能是一种人工智能技术,它可以将传感器信号和文本输入结合起来,建立语言和感知的链接,从而操控机器人完成任务规划和物品操作。谷歌推出的5620亿参数PaLM-E就是其中的代表。 这种技术的应用场景也很广泛,如智能家居、无人驾驶和工业自动化等领域。通过大模型驱动的具身智能,机器人可以更加智能地感知周围环境,并根据文本输入来规划相应的行动,实现人机协同。
PaLM-E模型采用了先进的多模态AIGC技术,它可以结合图像、声音、触觉等多个传感器信号来进行深度学习,并从中提取出关键特征。同时,PaLM-E还能够将文本输入转换为语义表示,与感知信息相结合进行综合判断和决策。这种技术的发展使得机器人可以更加智能地感知和理解周围环境,进而实现精准的任务执行和物品操作。 PaLM-E进一步验证了“智慧涌现”在多模感知和具身智能上的效果。
06 GPT-4 的发布,标志着 AIGC 迈入了多模态融合的新纪元
GPT-4的模型取得了重大突破,它拥有强大的图像识别能力,处理长达 2.5 万字的文本输入,让回答准确性大幅提升,以及能够生成歌词、富有创意的文本,可以实现风格的多样化。
GPT-4 作为一个强大的多模态模型,能够接受图像和文本输入,并输出准确的文本回答。实验证明,GPT-4 在各种专业测试和学术基准上的表现堪比人类水平。举个例子,在模拟律师考试中,GPT-4 能够取得前 10% 的成绩,而 GPT-3.5 则稍显逊色,只能排在倒数 10%。GPT-4 的新功能允许用户指定视觉或语言任务,并以纯文本设置并行处理文本和图像形式的 prompt。具体而言,当输入包含文本和图像时,GPT-4 能生成相应的文本输出,如自然语言、代码等。在许多领域,包括带有文本和照片的文档、图表或屏幕截图等,GPT-4 都展现出了与纯文本输入类似的功能。此外,它还可以利用为纯文本语言模型开发的测试时间技术进行增强,如少样本和思维链 prompt。GPT-4是世界第一款强有力的AI系统,会掀起一场新的工业革命,带来新的社会分工,创造新的应用场景,全面提升人类的智能化水平。
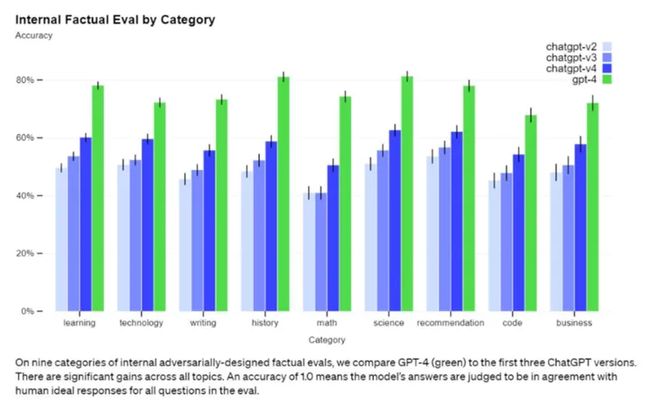
(以上图来自网络)
07 Is the AI GAME OVER?
在Rich Sutton著名文章《苦涩的教训》中,他提出了一个引人深思的观点,即唯一导致AI进步的是更多的数据、更有效的计算。这一观点得到了DeepMind研究主任Nando de Freitas的支持,他甚至宣称AI现在完全取决于规模,AI领域更难的挑战已经解决了,大模型已经(暂时)战胜了精心设计的知识工程。这一观点也得到了实际应用的证明,大量的数据和更强大的计算能力确实对AI技术的发展起着关键作用。 然而,我们也不能因此认为AI的发展已经结束了。如今,虽然大模型已经建立了基础,但真正的挑战仍然在于如何将其应用到实际场景中。例如,在自动驾驶领域,需要考虑不同的天气条件、不同的交通状况等复杂情况,这些都需要AI技术在实际应用中不断实现迭代和优化。 此外,AI在推理、判断和创造等方面仍面临许多挑战,实现真正的智能仍然需要突破。因此,虽然大模型已经取得了重大进展,但AI的发展之路仍然任重而道远。
GPT-4发布,AIGC时代的多模态还能走多远?我将发布四个系列,还会探讨AIGC的阿克琉斯之踵, 多模态认知智能和AIGC for MMKG,敬请期待!
文章转载自:华为云开发者联盟
原文链接:https://www.cnblogs.com/huaweiyun/p/17275588.html