《数据同步-NIFI系列》Nifi详细教程入门-03处理器
Nifi处理器
1 文件传输实现
在没有详细的介绍之前,可以先通过一个小的Demo,让自己有一个初步的了解,或许这样对你来说会比较有意思。
1.1 添加和配置GetFile处理器
添加
添加Processor的流程就是这样,这里使用动图演示一下,后续这样操作即可。

配置
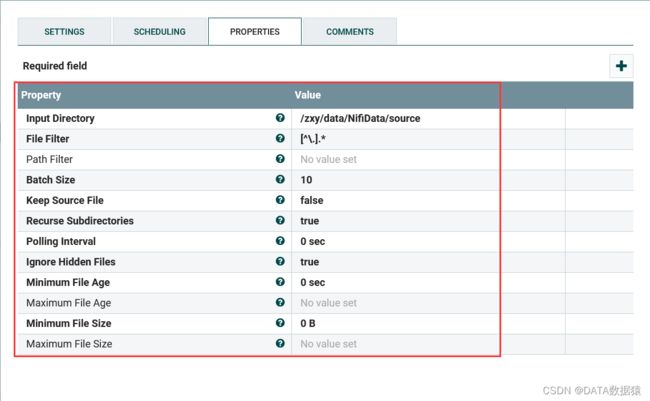
在input Directory一栏中添加路径,需要注意的是这个路径是安装nifi的服务器上的路径。其他配置暂时不做太多介绍,后续可以自行了解。这里主要是入门操作,看的多了反而觉得杂乱。

1.2 添加和配置PutFile处理器
添加

配置
在Directory一栏填写路径,即文件传输的目的地。

1.3 连接处理器

1.4 Processor自连接
putfile作为流程中的最后一个组件,已经没有下游。所以当他success或者failure的时候自己消化就可以。当然也可以根据自己需要当成功的时候自己消化,当失败的时候记录日志。

1.5 启动
启动组件方式已经介绍过,通过选中组件后,点击操作栏的启动按钮,或者单机鼠标右键都可以实现启动效果。

1.5 测试
# 模拟往source目录下生成文件
[root@zxy_slave1 target]# echo "hello world" > /zxy/data/NifiData/source/test1.txt
# 查看target目录,已经由Nifi同步到
[root@zxy_slave1 target]# ls
test1.txt
# 查看文件内容
[root@zxy_slave1 target]# cat test1.txt
hello world
2 Nifi处理器介绍
2.1 查看处理器
Nifi提供了293个处理器,但是可以通过nifi/lib目录下添加nar包增加新的处理器。

2.2 处理器选项配置说明
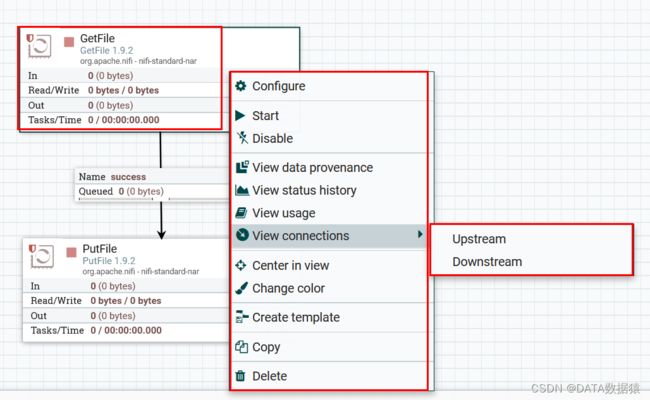
选项说明:
- 0. Configure(配置):此选项允许用户建立或更改处理器的配置。
- 1. Start(启动或停止):启动处理器,当处理器在启动状态的时候查看,可以停止处理器。
- 2. Disable(启用或禁用):启用处理器,当处理器在启用状态的时候,可以禁用处理器。
- 3. View data provenance(查看数据来源):此选项显示NiFi数据来源表,其中包含有关通过该处理器路由FlowFiles的数据来源事件的信息。
- 4. View status history(查看状态历史记录):此选项打开处理器统计信息随时间的图形表示。
- 5. View usage(查看用法):此选项将用户带到处理器的使用文档。
- 6. View connection → Upstream(查看连接→上游):此选项允许用户查看和“跳转”入处理器的上游连接。当处理器连接进出其他进程组时,这尤其有用。
- 7. View connection → Downstream(查看连接→下游):此选项允许用户查看和“跳转”到处理器外的下游连接。当处理器连接进出其他进程组时,这尤其有用。
- 8. Centere in view(视图中心):将当前选用的处理器,置于面板中心位置。
- 9. Change color(更改颜色):此选项允许用户更改处理器的颜色,这可以使大流量的可视化管理更容易。
- 10. Group (添加到组):把当前处理器添加到组。
- 11. Create template(创建模板):此选项允许用户从所选处理器创建模板。
- 12. Copy(复制):此选项将所选处理器的副本放在剪贴板上,以便可以通过右键单击工作区并选择“粘贴”将其粘贴到工作区上的其他位置。复制粘贴操作也可以使用按键Ctrl-C和Ctrl-V完成。
- 13. Delete(删除):此选项允许从画布中删除处理器。
2.3 处理器应用配置说明

2.3.1 设置

第一个是处理器名称,可根据业务自定义
第二个是否启用,与2.3 处理器选项配置说明中的distable功能一样。
第三个是终止关系,处理器定义的每个关系必须有下游处理器或者自动终止。
第四个是可能发生的事件,在稍等多久处理。
第五个是某种情况下,阻止处理器运行事件。
第六个是日志级别,默认为WARN,显示所有警告和错误。
2.3.2 调度

第一个调度策略,有时间驱动和cron定时驱动。
第二个是大哥前任务数,根据需求配置。
第三个是运行计划,根据不同调度策略选择对应的值。
第四个执行器,在集群模式下,可以选择是所有节点都执行还是主节点执行。
2.3.3 属性
不同处理器的属性都不一样,可以通过view usage查看对应文档。
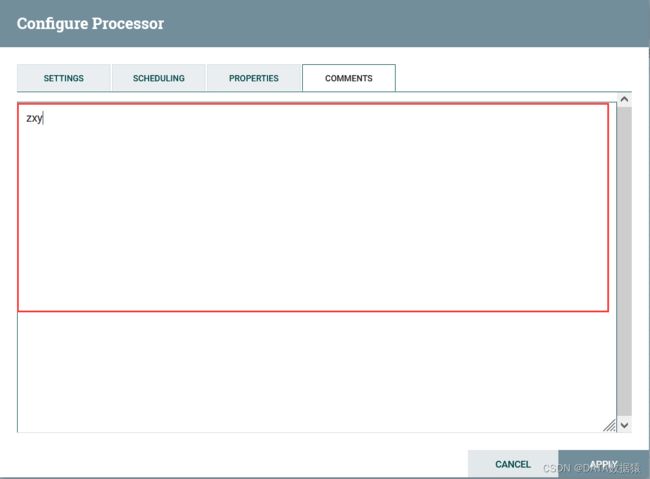
2.3.4 注释
在空白处添加注释即可
2.3.5 保存
在配置好所有属性后,一定要APPLY保存修改。
3 常用处理器
不同业务场景,使用的处理器都会大有差别,这里简单罗列几个。
ExecuteScript : 执行脚本的处理器,可以支持如下脚本: clojure, ecmascript, groovy, lua, python, ruby
QueryDatabaseTable : 数据库查询处理器
ConvertAvroToJSON : 将数据格式由Avro转为Json
SplitJson : 将JSON文件拆分为多个单独的FlowFiles, 用于由JsonPath表达式指定的数组元素。
EvaluateJsonPath : 根据FlowFile的内容评估一个或多个JsonPath表达式。这些表达式的结果将分配给FlowFile属性,或者写入FlowFile本身的内容,具体取决于处理器的配置。
ReplaceText : 文本组装与替换, 支持正则表达式
PutHDFS : 将FlowFile数据写入Hadoop分布式文件系统(HDFS)
PutHiveQL : 执行hive ddl/dml命令, 如: insert, update
PublishKafka_2_0 : 根据配置将消息发送到kafka topic
SelectHiveQL : 执行hive select 语句并获取结果
PutSQL : 执行SQL的insert或update命令
GetFile : 从目录中的文件创建FlowFiles。
PutFile : 将FlowFile数据写入文件
GetHDFS : 从Hadoop分布式文件系统获取文件
CaptureChangeMySQL : 从MySQL数据库中检索更改数据捕获(CDC)事件。CDC事件包括INSERT,UPDATE,DELETE操作。事件作为单个流文件输出,这些文件按操作发生的时间排序。
ExecuteStreamCommand : 一般用于执行sh脚本
4 处理器类别
为了更好的处理数据,用户必须对数据处理类型有了解。因为Nifi有很多处理器实现提取数据、路由、转换、处理、拆分、聚合以及分发等功能。只有了解后,才能快速的找到适合你需求的处理器,以达到最优的效果。
数据转换
- CompressContent:压缩或解压
- EncryptContent:加密或解密
- ConvertCharacterSet:编码内容的字符集转换
- ConvertAvroToJSON:将Avro数据类型转为json类型
- ReplaceText:使用正则表达式修改文本内容
- TransformXml:应用XSLT转换XML内容
- JoltTransformJSON:应用JOLT规范来转换JSON内容
路由和调解
- ControlRate:控制流程中流经某部分的速率
- DetectDuplicate:根据用户定义标准发现重复的FlowFiles。通常与HashContent一起使用
- DistributeLoad:根据用户选择的规则实现负载平衡或数据抽样
- MonitorActivity:健康数据流状态,(可选)在数据流恢复时发送通知。
- RouteOnAttribute:根据FlowFile包含的属性路由FlowFile,可自定义属性,分发路由。
- ScanAttribute: 扫描 FlowFiles 的指定属性,检查它们的任何值是否存在于指定的术语字典中。
- ScanContent: 扫描 FlowFiles 的内容以查找在用户提供的字典中找到的术语。
- RouteOnContent:根据FlowFile的内容是否与用户自定义的正则表达式匹配。如果匹配,则FlowFile将路由到已配置的关系。
- ValidateXml:以XML模式验证XML内容; 根据用户定义的XML Schema,判断FlowFile的内容是否有效,进而来路由FlowFile。
数据库访问
- ConvertJSONToSQL:将JSON文档转换为SQL INSERT或UPDATE命令,然后可以将其传递给PutSQL Processor
- ExecuteSQL:执行用户定义的SQL SELECT命令,结果为Avro格式的FlowFile
- ExecuteSQLRecord: 执行提供的 SQL 选择查询。查询结果将转换为 Record Writer 指定的格式。
- PutSQL:通过执行FlowFile内容定义的SQL DDM语句来更新数据库
- PutDatabaseRecord:使用指定的 RecordReader 从传入流文件中输入(可能是多个)记录
- SelectHiveQL:对Apache Hive数据库执行用户定义的HiveQL SELECT命令,结果为Avro或CSV格式的FlowFile
- PutHiveQL:通过执行FlowFile内容定义的HiveQL DDM语句来更新Hive数据库
属性提取
- EvaluateJsonPath:用户提供的Json表达式,添加属性,用结果值替换FlowFile内容或将结果值提取到用户自己命名的Attribute中。
- EvaluateXPath:用户提供XPath表达式,然后根据XML内容评估这些表达式,用结果值替换FlowFile内容或将结果值提取到用户自己命名的Attribute中。
- EvaluateXQuery:用户提供XQuery查询,然后根据XML内容评估此查询,用结果值替换FlowFile内容或将结果值提取到用户自己命名的Attribute中。
- ExtractText:用户提供一个或多个正则表达式,然后根据FlowFile的文本内容对其进行评估,然后将结果值提取到用户自己命名的Attribute中。
- HashAttribute:对用户定义的现有属性列表的串联进行hash。
- HashContent:对FlowFile的内容进行hash,并将得到的hash值添加到Attribute中。
- IdentifyMimeType:评估FlowFile的内容,以确定FlowFile封装的文件类型。此处理器能够检测许多不同的MIME类型,例如图像,文字处理器文档,文本和压缩格式,仅举几例。
- UpdateAttribute:向FlowFile添加或更新任意数量的用户定义的属性。这对于添加静态的属性值以及使用表达式语言动态计算出来的属性值非常有用。该处理器还提供"高级用户界面(Advanced User Interface)",允许用户根据用户提供的规则有条件地去更新属性。
系统交互
- ExecuteProcess:运行用户自定义的操作系统命令。进程的StdOut被重定向,以便StdOut的内容输出为FlowFile的内容。此处理器是源处理器(不接受数据流输入,没有上游组件) - 其输出预计会生成新的FlowFile,并且系统调用不会接收任何输入。如果要为进程提供输入,请使用ExecuteStreamCommand Processor。
- ExecuteStreamCommand:运行用户定义的操作系统命令。FlowFile的内容可选地流式传输到进程的StdIn。StdOut的内容输出为FlowFile的内容。此处理器不能用作源处理器 - 必须传入FlowFiles才能执行。
数据提取
- GetFile:将文件内容从本地磁盘(或网络连接的磁盘)流式传输到NiFi,然后删除原始文件。此处理器应将文件从一个位置移动到另一个位置,而不是用于复制数据。
- GetFTP:通过FTP将远程文件的内容下载到NiFi中,然后删除原始文件。此处理器应将文件从一个位置移动到另一个位置,而不是用于复制数据。
- GetSFTP:通过SFTP将远程文件的内容下载到NiFi中,然后删除原始文件。此处理器应将文件从一个位置移动到另一个位置,而不是用于复制数据。
- GetJMSQueue:从JMS队列下载消息,并根据JMS消息的内容创建FlowFile。可选地,JMS属性也可以作为属性复制。
- GetJMSTopic:从JMS主题下载消息,并根据JMS消息的内容创建FlowFile。可选地,JMS属性也可以作为属性复制。此处理器支持持久订阅和非持久订阅。
- GetHTTP:将基于HTTP或HTTPS的远程URL的请求内容下载到NiFi中。处理器将记住ETag和Last-Modified Date,以确保不会持续摄取数据。
- ListenHTTP:启动HTTP(或HTTPS)服务器并侦听传入连接。对于任何传入的POST请求,请求的内容将作为FlowFile写出,并返回200响应。
- ListenUDP:侦听传入的UDP数据包,并为每个数据包或每个数据包创建一个FlowFile(取决于配置),并将FlowFile发送到"success"。
- GetHDFS:监视HDFS中用户指定的目录。每当新文件进入HDFS时,它将被复制到NiFi并从HDFS中删除。此处理器应将文件从一个位置移动到另一个位置,而不是用于复制数据。如果在集群中运行,此处理器需仅在主节点上运行。要从HDFS复制数据并使其保持原状,或者从群集中的多个节点流式传输数据,请参阅ListHDFS处理器。
- ListHDFS / FetchHDFS:ListHDFS监视HDFS中用户指定的目录,并发出一个FlowFile,其中包含它遇到的每个文件的文件名。然后,它通过分布式缓存在整个NiFi集群中保持此状态。然后可以在集群中,将其发送到FetchHDFS处理器,后者获取这些文件的实际内容并发出包含从HDFS获取的内容的FlowFiles。
- GetKafka:从Apache Kafka获取消息,特别是0.8.x版本。消息可以作为每个消息的FlowFile发出,也可以使用用户指定的分隔符一起进行批处理。
- GetMongo:对MongoDB执行用户指定的查询,并将内容写入新的FlowFile。
数据出口/发送数据
- PutEmail:向配置的收件人发送电子邮件。FlowFile的内容可选择作为附件发送。
- PutFile:将FlowFile的内容写入本地(或网络连接)文件系统上的目录。
- PutFTP:将FlowFile的内容复制到远程FTP服务器。
- PutSFTP:将FlowFile的内容复制到远程SFTP服务器。
- PutJMS:将FlowFile的内容作为JMS消息发送到JMS代理,可选择将Attributes添加JMS属性。
- PutSQL:将FlowFile的内容作为SQL DDL语句(INSERT,UPDATE或DELETE)执行。FlowFile的内容必须是有效的SQL语句。属性可以用作参数,FlowFile的内容可以是参数化的SQL语句,以避免SQL注入攻击。
- PutKafka:将FlowFile的内容作为消息发送到Apache Kafka,特别是0.8.x版本。FlowFile可以作为单个消息或分隔符发送,例如可以指定换行符,以便为单个FlowFile发送许多消息。
- PutMongo:将FlowFile的内容作为INSERT或UPDATE发送到Mongo。
分裂和聚合
- SplitText:SplitText接收单个FlowFile,其内容为文本,并根据配置的行数将其拆分为1个或多个FlowFiles。例如,可以将处理器配置为将FlowFile拆分为多个FlowFile,每个FlowFile只有一行。
- SplitJson:允许用户将包含数组或许多子对象的JSON对象拆分为每个JSON元素的FlowFile。
- SplitXml:允许用户将XML消息拆分为多个FlowFiles,每个FlowFiles包含原始段。这通常在多个XML元素与"wrapper"元素连接在一起时使用。然后,此处理器允许将这些元素拆分为单独的XML元素。
- UnpackContent:解压缩不同类型的存档格式,例如ZIP和TAR。然后,归档中的每个文件都作为单个FlowFile传输。
- SegmentContent:根据某些已配置的数据大小将FlowFile划分为可能的许多较小的FlowFile。不对任何类型的分界符执行拆分,而是仅基于字节偏移执行拆分。这是在传输FlowFiles之前使用的,以便通过并行发送许多不同的部分来提供更低的延迟。而另一方面,MergeContent处理器可以使用碎片整理模式重新组装这些FlowFiles。
- MergeContent:此处理器负责将许多FlowFiles合并到一个FlowFile中。可以通过将其内容与可选的页眉,页脚和分界符连接在一起,或者通过指定存档格式(如ZIP或TAR)来合并FlowFiles。FlowFiles可以根据公共属性进行分箱(binned),或者如果这些流是被其他组件拆分的,则可以进行"碎片整理(defragmented)"。根据元素的数量或FlowFiles内容的总大小(每个bin的最小和最大大小是用户指定的)并且还可以配置可选的Timeout属性,即FlowFiles等待其bin变为配置的上限值最大时间。
- SplitContent:将单个FlowFile拆分为可能的许多FlowFile,类似于SegmentContent。但是,对于SplitContent,不会在任意字节边界上执行拆分,而是指定要拆分内容的字节序列。
HTTP
- GetHTTP:将基于HTTP或HTTPS的远程URL的内容下载到NiFi中。处理器将记住ETag和Last-Modified Date,以确保不会持续摄取数据。
- ListenHTTP:启动HTTP(或HTTPS)服务器并侦听传入连接。对于任何传入的POST请求,请求的内容将作为FlowFile写出,并返回200响应。
- InvokeHTTP:执行用户配置的HTTP请求,
可用于接收API接口数据。此处理器比GetHTTP和PostHTTP更通用,但需要更多配置。此处理器不能用作源处理器,并且需要具有传入的FlowFiles才能被触发以执行其任务。 - PostHTTP:执行HTTP POST请求,将FlowFile的内容作为消息正文发送。这通常与ListenHTTP结合使用,以便在无法使用s2s的情况下在两个不同的NiFi实例之间传输数据(例如,节点无法直接访问并且能够通过HTTP进行通信时代理)。 注意:除了现有的RAW套接字传输之外,HTTP还可用作s2s传输协议。它还支持HTTP代理。建议使用HTTP s2s,因为它更具可扩展性,并且可以使用具有更好用户身份验证和授权的输入/输出端口的方式来提供双向数据传输。
- HandleHttpRequest / HandleHttpResponse:HandleHttpRequest Processor是一个源处理器,与ListenHTTP类似,启动嵌入式HTTP(S)服务器。但是,它不会向客户端发送响应(比如200响应)。相反,流文件是以HTTP请求的主体作为其内容发送的,所有典型servlet参数、头文件等的属性作为属性。然后,HandleHttpResponse能够在FlowFile完成处理后将响应发送回客户端。这些处理器总是彼此结合使用,并允许用户在NiFi中可视化地创建Web服务。这对于将前端添加到非基于Web的协议或围绕已经由NiFi执行的某些功能(例如数据格式转换)添加简单的Web服务特别有用。