【MySQL】如何优化SQL查询的总体框架(详细版,关于如何优化数据库服务器从大到小详细说明了步骤)
文章目录
- 1 数据库服务器的优化步骤
- 2 观察
-
- 2.1 观察系统总体运行情况
- 2.2 定位执行慢的 SQL:慢查询日志
- 2.3 查看 SQL 执行成本:SHOW PROFILE
- 2.4 分析查询语句:EXPLAIN(重点掌握)
-
- 2.4.1 EXPLAIN各列作用
- 2.4.2 EXPLAIN 的 type 列
- 1.4.3 EXPLAIN 的 Extra 列
- 1.4.4 一个优化案例
- 2 参考资料
1 数据库服务器的优化步骤
当我们遇到数据库调优问题的时候,该如何思考呢?这里把思考的流程整理成下面这张图。整个流程划分成了 观察(Show status) 和 行动(Action) 两个部分。字母 S 的部分代表观察(会使用相应的分析工具),字母 A 代表的部分是行动(对应分析可以采取的行动)。

小结:

2 观察
2.1 观察系统总体运行情况
在 MySQL中,可以使用 SHOW STATUS 语句查询一些数据库服务器的运行情况,如:性能参数 、 执行频率等。
备注:
1、show status 是由数据库自行维护的,作用是记录系统的运行情况,用户不可修改。
2、与 show status 类似的有一个 show variables 描述的是系统的一些系统变量,这些用户是可以控制的,用来调整系统的一些情况
SHOW STATUS语句语法如下:
SHOW [GLOBAL|SESSION] STATUS LIKE '参数';
一些常用的性能参数如下:
- Connections:连接MySQL服务器的次数。
- Uptime:MySQL服务器的上线时间。
- Slow_queries:慢查询的次数
- Innodb_rows_read:Select查询返回的行数
- Innodb_rows_inserted:执行INSERT操作插入的行数
- Innodb_rows_updated:执行UPDATE操作更新的行数
- Innodb_rows_deleted:执行DELETE操作删除的行数
- Com_select:查询操作的次数
- Com_insert:插入操作的次数。对于批量插入的 INSERT 操作,只累加一次
- Com_update:更新操作的次数。
- Com_delete:删除操作的次数。
举例:
show status like 'Uptime';
2.2 定位执行慢的 SQL:慢查询日志
关于慢日志,作者写了另外的文章,这里不做过多介绍,《5.4.5 The Slow Query Log(慢日志实验).md》
2.3 查看 SQL 执行成本:SHOW PROFILE
show profile 的作用是查看sql消耗的资源,也就是通常所说的成本。
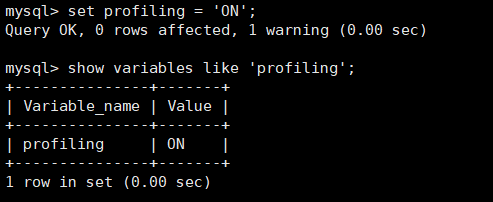
show variables like 'profiling';

通过设置 profiling='ON' 来开启 show profile:
set profiling = 'ON';
然后执行相关的查询语句。接着看下当前会话都有哪些 profiles,使用下面这条命令:
show profiles;
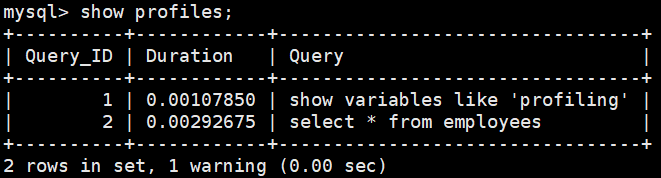
你能看到当前会话一共有 2 个查询。查看某一次查询的资源使用情况使用:
show profile cpu,block io for query 2;

show profile在新的版本中标注过期了,官方建议大家使用性能库,即performance_schema
2.4 分析查询语句:EXPLAIN(重点掌握)
使用语法:
EXPLAIN SELECT select_options
如果我们想看看某个查询的执行计划的话,可以在具体的查询语句前边加一个 EXPLAIN ,就像这样:
EXPLAIN SELECT 1;
EXPLAIN 语句输出的各个列的作用如下:
| 列名 | 描述 |
|---|---|
id |
在一个大的查询语句中每个SELECT关键字都对应一个 唯一的id |
select_type |
SELECT关键字对应的那个查询的类型 |
table |
表名 |
partitions |
匹配的分区信息 |
type |
针对单表的访问方法 |
possible_keys |
可能用到的索引 |
key |
实际上使用的索引 |
key_len |
实际使用到的索引长度 |
ref |
当使用索引列等值查询时,与索引列进行等值匹配的对象信息 |
rows |
预估的需要读取的记录条数 |
filtered |
某个表经过搜索条件过滤后剩余记录条数的百分比 |
Extra |
一些额外的信息 |
2.4.1 EXPLAIN各列作用
为了让大家有比较好的体验,我们调整了下 EXPLAIN 输出列的顺序。
1. table:
不论我们的查询语句有多复杂,里边儿 包含了多少个表 ,到最后也是需要对每个表进行 单表访问 的,所以MySQL规定EXPLAIN语句输出的每条记录都对应着某个单表的访问方法,该条记录的table列代表着该表的表名(有时不是真实的表名字,可能是简称)。
2. id:
我们写的查询语句一般都以 SELECT 关键字开头,比较简单的查询语句里只有一个 SELECT 关键字,id就可以理解为一个select语句。
- id如果相同,可以认为是一组,从上往下顺序执行
- 在所有组中,id值越大,优先级越高,越先执行
- 关注点:id号每个号码,表示一趟独立的查询, 一个sql的查询趟数越少越好
3. select_type:
查询类型。有如下表:
| 名称 | 描述 |
|---|---|
| SIMPLE | Simple SELECT (not using UNION or subqueries)(只要不是union和子查询) |
| PRIMARY | Outermost SELECT(最外面的查询) |
| UNION | Second or later SELECT statement in a UNION(union) |
| DEPENDENT UNION | Second or later SELECT statement in a UNION, dependent on outer query(union且依赖外部查询) |
| UNION RESULT | Result of a UNION.( union之后的结果) |
| SUBQUERY | First SELECT in subquery(子查询) |
| DEPENDENT SUBQUERY | First SELECT in subquery, dependent on outer query(子查询且依赖外部查询) |
| DERIVED | Derived table(派生表) |
| DEPENDENT DERIVED | Derived table dependent on another table(派生表且依赖其他表) |
| MATERIALIZED | Materialized subquery(物化子查询) |
| UNCACHEABLE SUBQUERY | A subquery for which the result cannot be cached and must be re-evaluated for each row of the outer query |
具体分析如下:
-
SIMPLE除了子查询和UNION都是simple
EXPLAIN SELECT * FROM s1;
当然,连接查询也算是 SIMPLE 类型,比如:
EXPLAIN SELECT * FROM s1 INNER JOIN s2;
-
PRIMARYEXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;
-
UNION -
UNION RESULT -
SUBQUERYEXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2) OR key3 = 'a';
-
DEPENDENT SUBQUERYEXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2 WHERE s1.key2 = s2.key2) OR key3 = 'a';
-
DEPENDENT UNIONEXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2 WHERE key1 = 'a' UNION SELECT key1 FROM s1 WHERE key1 = 'b');
-
DERIVEDEXPLAIN SELECT * FROM (SELECT key1, count(*) as c FROM s1 GROUP BY key1) AS derived_s1 where c > 1;
-
MATERIALIZEDEXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2);
-
UNCACHEABLE SUBQUERY -
UNCACHEABLE UNION
2.4.2 EXPLAIN 的 type 列
针对上文提到的type类型,这里重点说明。
EXPLAIN输出的type列描述了如何联接表。以下列表描述了连接类型,按从最佳类型到最差类型的顺序排列:
-
system只有一行数据的表,是const的一种特殊情况
CREATE TABLE t(i int) Engine=MyISAM; INSERT INTO t VALUES(1); EXPLAIN SELECT * FROM t; -
const常量级别,表中最多只匹配一行且在查询开始的时候就被读取到了。这种情况就是
PRIMARY KEY或UNIQUE。举例:SELECT * FROM tbl_name WHERE primary_key=1; -- 右边是常量,左边是主键 SELECT * FROM tbl_name WHERE primary_key_part1=1 AND primary_key_part2=2; -
eq_ref等值引用。从当前的表读取一行与先前的表匹配。这是除了system、const以外最快的方式,如在
PRIMARY KYE或UNIQUE NOT NULL会使用。举例如下:SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1; -
ref引用,跟 eq_ref 不同的是ref可能会匹配多行而eq_ref匹配一行。对于前一个表中的每一个行组合,都会从此表中读取具有匹配索引值的所有行。当键不是PRIMARY key或UNIQUE索引(换句话说,如果联接不能根据键值选择一行),则使用ref。举例:
-- 不是 primary key 或者 unique SELECT * FROM ref_table WHERE key_column=expr; SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column; SELECT * FROM ref_table,other_table WHERE ref_table.key_column_part1=other_table.column AND ref_table.key_column_part2=1; -
fulltext -
ref_or_null这个join type类型跟ref类似,但是可能会包括null。举例:
SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL; -
index_merge此联接类型表示使用了索引合并优化。在查询的列都来自索引时可能会发生。
-
unique_subquery用来在子查询中代替 eq_ref。举例:
-- primary_key 是唯一索引 value IN (SELECT primary_key FROM single_table WHERE some_expr) -
index_subquery跟 unique_subquery类似。它代替 IN 子查询,但是它和非唯一索引一起工作。举例:
-- key_column 是非唯一索引 value IN (SELECT key_column FROM single_table WHERE some_expr) -
range范围。使用索引选择给定范围的行的类型就是range。通常在这些情况发生:=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN、LIKE、IN()。举例:
SELECT * FROM tbl_name WHERE key_column = 10; SELECT * FROM tbl_name WHERE key_column BETWEEN 10 and 20; SELECT * FROM tbl_name WHERE key_column IN (10,20,30); SELECT * FROM tbl_name WHERE key_part1 = 10 AND key_part2 IN (10,20,30); -
index当覆盖索引时一般使用index,该类型跟all差不多效率除了特殊情况外。
-
all全表扫描
1.4.3 EXPLAIN 的 Extra 列
EXPLAIN输出的Extra列包含有关MySQL如何解析查询的附加信息。以下列表说明了可以在此列中显示的值。以下列举几个常见的
-
Backward index scan
反向索引扫描
-
const row not found
-
Distinct
-
Full scan on NULL key
-
Impossible HAVING
不可能的having条件
-
Impossible WHERE
不可能的where条件
-
No tables used
-
unique row not found
-
Using filesort
-
Using index
只使用索引树中的信息从表中检索列信息,而不必进行额外的查找来读取实际行。当查询仅使用作为单个索引一部分的列时,可以使用此策略。
-
Using temporary
为了解决查询,MySQL需要创建一个临时表来保存结果。通常发生在GROUP BY和ORDER BY子句
-
Using where
1.4.4 一个优化案例
有如下的sql语句
EXPLAIN SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate,
tt.ActualShipDate, tt.ClientID,
tt.ServiceCodes, tt.RepetitiveID,
tt.CurrentProcess, tt.CurrentDPPerson,
tt.RecordVolume, tt.DPPrinted, et.COUNTRY,
et_1.COUNTRY, do.CUSTNAME
FROM tt, et, et AS et_1, do
WHERE tt.SubmitTime IS NULL
AND tt.ActualPC = et.EMPLOYID
AND tt.AssignedPC = et_1.EMPLOYID
AND tt.ClientID = do.CUSTNMBR;
被比较的列如下:
| Table | Column | Data Type |
|---|---|---|
tt |
ActualPC |
CHAR(10) |
tt |
AssignedPC |
CHAR(10) |
tt |
ClientID |
CHAR(10) |
et |
EMPLOYID |
CHAR(15) |
do |
CUSTNMBR |
CHAR(15) |
表的索引如下:
| Table | Column | Data Type |
|---|---|---|
tt |
ActualPC |
CHAR(10) |
tt |
AssignedPC |
CHAR(10) |
tt |
ClientID |
CHAR(10) |
et |
EMPLOYID |
CHAR(15) |
do |
CUSTNMBR |
CHAR(15) |
现在用explain分析出来的结果如下:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
do ALL PRIMARY NULL NULL NULL 2135
et_1 ALL PRIMARY NULL NULL NULL 74
tt ALL AssignedPC, NULL NULL NULL 3872
ClientID,
ActualPC
Range checked for each record (index map: 0x23)
现在应该如何优化?
分析:
1、从执行计划的输出可以看到所有的链接类型都是ALL,这是全表扫描非常地效;从rows列的乘积 74 * 2135 * 74 * 3872 的结果可以看出需要扫描的行的数量将非常多(即使结果只有很少一部分);但是可以看到对表却是建立了索引,那为啥索引没有被使用到?
2、仔细观察发现是因为字段的类型长度不一样,有 char(10) 和 char(15),很明显只能扩长度不能缩小长度。执行如下操作重新观察执行计划
ALTER TABLE tt MODIFY ActualPC VARCHAR(15);
ALTER TABLE tt MODIFY AssignedPC VARCHAR(15),MODIFY ClientID VARCHAR(15);
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
tt ref AssignedPC, ActualPC 15 et.EMPLOYID 52 Using
ClientID, where
ActualPC
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
达到这一步基本已经很完美了,索引基本上都使用到了,而且是eq_ref和ref效率都还可以。
3、但是仔细分析发现
-
在 Extra 列使用过滤条件的列(即第二列)并没有作为驱动表,驱动表是et表(第一行是驱动表)。
-
优化器预估tt扫描52行,et扫描74行,既然tt表扫描的行少,那应该让tt表作为驱动表
4、执行以下语句让MySQL分析关键字的分布情况(在Oracle中也叫做收集统计信息)
ANALYZE TABLE tt;
5、重新查看执行计划,如下:
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC NULL NULL NULL 3872 Using
ClientID, where
ActualPC
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1
do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
2 参考资料
官网:https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
show status:参考我的文章:《13.7.7.37 SHOW STATUS Statement.md》
理解执行计划:参考我的文章:《8.8.2 EXPLAIN Output Format(explain 输出执行计划的格式).md》
书籍:《InnoDB 存储引擎》,该书电子版书籍作者无套路免费下载
传送门: 保姆式Spring5源码解析
欢迎与作者一起交流技术和工作生活
联系作者
传送门: 保姆式Spring5源码解析
欢迎与作者一起交流技术和工作生活
联系作者