论文阅读--ssFPN: Scale Sequence (S2 ) Feature Based Feature Pyramid Network for Object Detection
论文地址:ssFPN: Scale Sequence (S2 ) Feature Based Feature Pyramid Network for Object Detection
1、文章解决的核心问题
目标检测任务中,FPN是一个解决多尺度问题的核心结构,但即使使用了FPN或者其变体结构,最终检测结果的AP值在小目标上依然较差,如下图所示,APs的的检测结果无论在一阶段的YOLO或者两阶段的Cascade R-CNN中表现军远低于APm以及APl,究其原因,作者认为是CNN提取深层特征时会丢失较多语义信息,因此提出Scale-Sequence FPN来加强小目标的信息。

2、网络结构
本文提出的主要结构如下所示:
backbone(Resnet/CspDarknet)提取图像的特征,利用FPN、PAN进行特征融合,以FPN为例,获取P3、P4、P5三个特征融合层,因需要增强小目标的特征层(一般高分辨率的特征层检测小目标),因此以P3作为基准,首先将所有的特征层resize到P3的大小,接着使用unsqueeze函数在每一层增加一个level维度,并在此维度上将所有resize后的特征层concat起来,构成一个general view模块;此时general view模块就类似于视频的连续祯一样,使用3D卷积+3D batch normalization+ Leaky ReLU来提取其特征,为了简化只是用一次上述操作,然后特征送入AvgPool3D中在level维度进行池化,最后获取一个与P3大小相同的feature map, 将P3与该特征层concat,利用1*1的卷积调整通道后送入后续检测任务。

3、实验效果
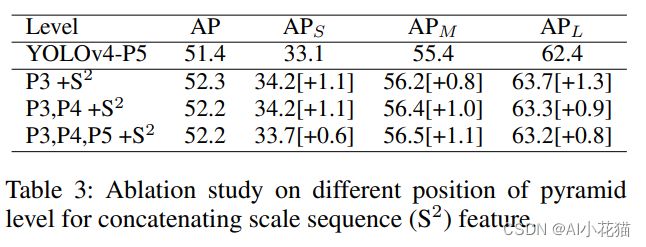
- 在不同位置添加SS模块
放在不同的位置均有AP值的提升
- 在FPN/PAN中使用模块

- 添加SS模块后的推理时间
添加SS模块后,基于YOLOV4的对比实验可知:在增加1-3M参数的情况下,AP平均提升1个点左右,推理时间延迟2S

4、代码
本文未提供官方代码,按照作者的意图,结合mmdetection的框架进行了复现,代码如下:
import torch.nn as nn
import torch
import torch.nn.functional as F
from mmcv.cnn import xavier_init
import math
from mmdet.core import auto_fp16
from ..registry import NECKS
from ..utils import ConvModule
@NECKS.register_module
class ss_FPN(nn.Module):
def __init__(self,
in_channels,
out_channels,
num_outs,
start_level=0,
end_level=-1,
add_extra_convs=False,
extra_convs_on_inputs=True,
relu_before_extra_convs=False,
no_norm_on_lateral=False,
conv_cfg=None,
norm_cfg=None,
activation=None):
super(ss_FPN, self).__init__()
assert isinstance(in_channels, list)
self.in_channels = in_channels
self.out_channels = out_channels
self.num_ins = len(in_channels)
self.num_outs = num_outs
self.activation = activation
self.relu_before_extra_convs = relu_before_extra_convs
self.no_norm_on_lateral = no_norm_on_lateral
self.fp16_enabled = False
if end_level == -1:
self.backbone_end_level = self.num_ins
assert num_outs >= self.num_ins - start_level
else:
# if end_level < inputs, no extra level is allowed
self.backbone_end_level = end_level
assert end_level <= len(in_channels)
assert num_outs == end_level - start_level
self.start_level = start_level
self.end_level = end_level
self.add_extra_convs = add_extra_convs
self.extra_convs_on_inputs = extra_convs_on_inputs
self.lateral_convs = nn.ModuleList()
self.fpn_convs = nn.ModuleList()
for i in range(self.start_level, self.backbone_end_level):
l_conv = ConvModule(
in_channels[i],
out_channels,
1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg if not self.no_norm_on_lateral else None,
activation=self.activation,
inplace=False)
fpn_conv = ConvModule(
out_channels,
out_channels,
3,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
activation=self.activation,
inplace=False)
self.lateral_convs.append(l_conv)
self.fpn_convs.append(fpn_conv)
# add extra conv layers (e.g., RetinaNet)
extra_levels = num_outs - self.backbone_end_level + self.start_level
if add_extra_convs and extra_levels >= 1:
for i in range(extra_levels):
if i == 0 and self.extra_convs_on_inputs:
in_channels = self.in_channels[self.backbone_end_level - 1]
else:
in_channels = out_channels
extra_fpn_conv = ConvModule(
in_channels,
out_channels,
3,
stride=2,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
activation=self.activation,
inplace=False)
self.fpn_convs.append(extra_fpn_conv)
# add scale sequence
self.conv3D_bn_act = nn.Sequential(
nn.Conv3d(self.out_channels, self.out_channels, kernel_size=(3, 3, 3), stride=1, padding=(1, 1, 1)),
nn.BatchNorm3d(self.out_channels),
nn.LeakyReLU(0.01, inplace=True)
)
self.avgpool = nn.AvgPool3d(kernel_size=(num_outs, 1, 1), stride=(num_outs, 1, 1), padding=(0, 0, 0))
self.conv_1_1 = nn.Conv2d(self.out_channels * 2, self.out_channels, 1, 1)
# default init_weights for conv(msra) and norm in ConvModule
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
xavier_init(m, distribution='uniform')
@auto_fp16()
def forward(self, inputs):
assert len(inputs) == len(self.in_channels)
# build laterals
# size [1,256,56,56], [1,512,28,28], [1,1024,14,14],[1,2048,7,7]
laterals = [
lateral_conv(inputs[i + self.start_level])
for i, lateral_conv in enumerate(self.lateral_convs)
]
# build top-down path
# size [1,256,56,56], [1,256,28,28], [1,256,14,14],[1,256,7,7]
used_backbone_levels = len(laterals)
for i in range(used_backbone_levels - 1, 0, -1):
laterals[i - 1] += F.interpolate(
laterals[i], scale_factor=2, mode='nearest')
# build outputs
# part 1: from original levels
outs = [
self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
]
# part 2: add extra levels
if self.num_outs > len(outs):
# use max pool to get more levels on top of outputs
# (e.g., Faster R-CNN, Mask R-CNN)
if not self.add_extra_convs:
for i in range(self.num_outs - used_backbone_levels):
outs.append(F.max_pool2d(outs[-1], 1, stride=2))
# add conv layers on top of original feature maps (RetinaNet)
else:
if self.extra_convs_on_inputs:
orig = inputs[self.backbone_end_level - 1]
outs.append(self.fpn_convs[used_backbone_levels](orig))
else:
outs.append(self.fpn_convs[used_backbone_levels](outs[-1]))
for i in range(used_backbone_levels + 1, self.num_outs):
if self.relu_before_extra_convs:
outs.append(self.fpn_convs[i](F.relu(outs[-1])))
else:
outs.append(self.fpn_convs[i](outs[-1]))
# add scale sequence in FPN
last_p = outs[0]
size = outs[0].size()[-2:]
add_level_scale = [torch.unsqueeze(F.interpolate(out, size=size, mode='nearest'), dim=2) for out in
outs]
Pssf = torch.cat(add_level_scale, dim=2)
Pssf = self.conv3D_bn_act(Pssf)
Pssf = self.avgpool(Pssf)
Pssf = torch.squeeze(Pssf, dim=2)
Pssf = torch.cat([Pssf, last_p], dim=1)
ps3 = self.conv_1_1(Pssf)
outs[0] = ps3
return tuple(outs)
实际在自己的数据集测试,AP都掉1个点,可能实现有些问题,如果有大佬知道,麻烦告知
–END–