大数据最佳实践-Kylin高级篇
文章目录
- 优化cube
-
- 5.1 找到问题Cube
-
- 5.1.1 检查Cuboid数量
- 5.1.2 检查Cube大小
- 优化构建
-
- 5.2.1 使用聚合组
- 5.2.2 并发粒度优化
- 1.Cube执行情况
- 2.Cube大小
- 3.聚合组
- 4.资源参数优化
- 配置Kylin的精确去重指标跨Segment上卷
- 留存分析
- 漏斗分析
- Cue 迁移
-
- I. 在同一个Hadoop集群下的Cube迁移
- II. 跨Hadoop集群下的Cube迁移
- 混合模型
- 其他
优化cube
从之前章节的介绍可以知道,在没有采取任何优化措施的情况下,Kylin会对每一种维度的组合进行预计算,每种维度的组合的预计算结果被称为Cuboid。假设有4个维度,我们最终会有24 =16个Cuboid需要计算。
但在现实情况中,用户的维度数量一般远远大于4个。假设用户有10 个维度,那么没有经过任何优化的Cube就会存在210 =1024个Cuboid;而如果用户有20个维度,那么Cube中总共会存在220 =1048576个Cuboid。虽然每个Cuboid的大小存在很大的差异,但是单单想到Cuboid的数量就足以让人想象到这样的Cube对构建引擎、存储引擎来说压力有多么巨大。因此,在构建维度数量较多的Cube时,尤其要注意Cube的剪枝优化(即减少Cuboid的生成)。
5.1 找到问题Cube
5.1.1 检查Cuboid数量
Apache Kylin提供了一个简单的工具,供用户检查Cube中哪些Cuboid 最终被预计算了,我们称其为被物化(Materialized)的Cuboid。同时,这种方法还能给出每个Cuboid所占空间的估计值。由于该工具需要在对数据进行一定阶段的处理之后才能估算Cuboid的大小,因此一般来说只能在Cube构建完毕之后再使用该工具。目前关于这一点也是该工具的一大不足,由于同一个Cube的不同Segment之间仅是输入数据不同,模型信息和优化策略都是共享的,所以不同Segment中哪些Cuboid被物化哪些没有被物化都是一样的。因此只要Cube中至少有一个Segment,那么就能使用如下的命令行工具去检查这个Cube中的Cuboid状态:
bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader CUBE_NAME
CUBE_NAME:想要查看的Cube的名字
例如:
[atguigu@hadoop102 kylin]$ bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader FirstCube
… …
… …
Statistics of FirstCube[FULL_BUILD]
Cube statistics hll precision: 14
Total cuboids: 7
Total estimated rows: 51
Total estimated size(MB): 3.027915954589844E-4
Sampling percentage: 100
Mapper overlap ratio: 1.0
Mapper number: 1
Length of dimension DEFAULT.EMP.JOB is 1
Length of dimension DEFAULT.EMP.MGR is 1
Length of dimension DEFAULT.EMP.DEPTNO is 1
|---- Cuboid 111, est row: 10, est MB: 0
|---- Cuboid 011, est row: 9, est MB: 0, shrink: 90%
|---- Cuboid 001, est row: 3, est MB: 0, shrink: 33.33%
|---- Cuboid 010, est row: 7, est MB: 0, shrink: 77.78%
|---- Cuboid 101, est row: 9, est MB: 0, shrink: 90%
|---- Cuboid 100, est row: 5, est MB: 0, shrink: 55.56%
|---- Cuboid 110, est row: 8, est MB: 0, shrink: 80%
从分析结果的下半部分可以看到,所有的Cuboid及它的分析结果都以树状的形式打印了出来。在这棵树中,每个节点代表一个Cuboid,每个Cuboid都由一连串1或0的数字组成,如果数字为0,则代表这个Cuboid中不存在相应的维度;如果数字为1,则代表这个Cuboid中存在相应的维度。除了最顶端的Cuboid之外,每个Cuboid都有一个父亲Cuboid,且都比父亲Cuboid少了一个“1”。其意义是这个Cuboid就是由它的父亲节点减少一个维度聚合而来的(上卷)。最顶端的Cuboid称为Base Cuboid,它直接由源数据计算而来。
每行Cuboid的输出中除了0和1的数字串以外,后面还有每个Cuboid 的的行数与父亲节点的对比(Shrink值)。所有Cuboid行数的估计值之和应该等于Segment的行数估计值,每个Cuboid都是在它的父亲节点的基础上进一步聚合而成的,因此从理论上说每个Cuboid无论是行数还是大小都应该小于它的父亲。在这棵树中,我们可以观察每个节点的Shrink值,如果该值接近100%,则说明这个Cuboid虽然比它的父亲Cuboid少了一个维度,但是并没有比它的父亲Cuboid少很多行数据。换而言之,即使没有这个Cuboid, 我们在查询时使用它的父亲Cuboid,也不会有太大的代价。那么我们就可以对这个Cuboid进行剪枝操作。
5.1.2 检查Cube大小
还有一种更为简单的方法可以帮助我们判断Cube是否已经足够优化。在Web GUI的Model页面选择一个READY状态的Cube,当我们把光标移到该Cube的Cube Size列时,Web GUI会提示Cube的源数据大小,以及当前Cube的大小除以源数据大小的比例,称为膨胀率(Expansion Rate),如图所示。

一般来说,Cube的膨胀率应该在0%~1000%之间,如果一个Cube的膨胀率超过1000%,那么Cube管理员应当开始挖掘其中的原因。通常,膨胀率高有以下几个方面的原因。
1)Cube中的维度数量较多,且没有进行很好的Cuboid剪枝优化,导致Cuboid数量极多;
2)Cube中存在较高基数的维度,导致包含这类维度的每一个Cuboid占用的空间都很大,这些Cuboid累积造成整体Cube体积变大;
因此,对于Cube膨胀率居高不下的情况,管理员需要结合实际数据进行分析,可灵活地运用接下来介绍的优化方法对Cube进行优化。
优化构建
5.2.1 使用聚合组
聚合组(Aggregation Group)是一种强大的剪枝工具。聚合组假设一个Cube的所有维度均可以根据业务需求划分成若干组(当然也可以是一个组),由于同一个组内的维度更可能同时被同一个查询用到,因此会表现出更加紧密的内在关联。每个分组的维度集合均是Cube所有维度的一个子集,不同的分组各自拥有一套维度集合,它们可能与其他分组有相同的维度,也可能没有相同的维度。每个分组各自独立地根据自身的规则贡献出一批需要被物化的Cuboid,所有分组贡献的Cuboid的并集就成为了当前Cube中所有需要物化的Cuboid的集合。不同的分组有可能会贡献出相同的Cuboid,构建引擎会察觉到这点,并且保证每一个Cuboid无论在多少个分组中出现,它都只会被物化一次。
对于每个分组内部的维度,用户可以使用如下三种可选的方式定义,它们之间的关系,具体如下。
1)强制维度(Mandatory),如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个Cuboid都会包含该维度。每个分组中都可以有0个、1个或多个强制维度。如果根据这个分组的业务逻辑,则相关的查询一定会在过滤条件或分组条件中,因此可以在该分组中把该维度设置为强制维度。
2)层级维度(Hierarchy),每个层级包含两个或更多个维度。假设一个层级中包含D1,D2…Dn这n个维度,那么在该分组产生的任何Cuboid中, 这n个维度只会以(),(D1),(D1,D2)…(D1,D2…Dn)这n+1种形式中的一种出现。每个分组中可以有0个、1个或多个层级,不同的层级之间不应当有共享的维度。如果根据这个分组的业务逻辑,则多个维度直接存在层级关系,因此可以在该分组中把这些维度设置为层级维度。
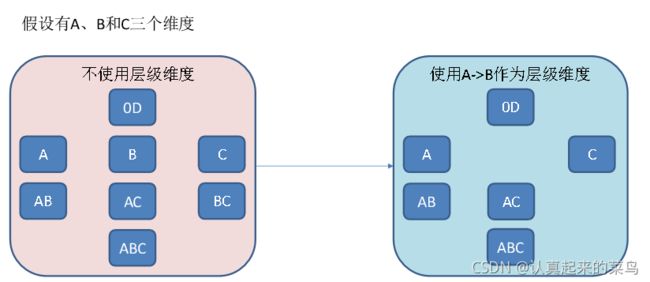
3)联合维度(Joint),每个联合中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现。每个分组中可以有0个或多个联合,但是不同的联合之间不应当有共享的维度(否则它们可以合并成一个联合)。如果根据这个分组的业务逻辑,多个维度在查询中总是同时出现,则可以在该分组中把这些维度设置为联合维度。

这些操作可以在Cube Designer的Advanced Setting中的Aggregation Groups区域完成,如下图所示。

聚合组的设计非常灵活,甚至可以用来描述一些极端的设计。假设我们的业务需求非常单一,只需要某些特定的Cuboid,那么可以创建多个聚合组,每个聚合组代表一个Cuboid。具体的方法是在聚合组中先包含某个Cuboid所需的所有维度,然后把这些维度都设置为强制维度。这样当前的聚合组就只能产生我们想要的那一个Cuboid了。
再比如,有的时候我们的Cube中有一些基数非常大的维度,如果不做特殊处理,它就会和其他的维度进行各种组合,从而产生一大堆包含它的Cuboid。包含高基数维度的Cuboid在行数和体积上往往非常庞大,这会导致整个Cube的膨胀率变大。如果根据业务需求知道这个高基数的维度只会与若干个维度(而不是所有维度)同时被查询到,那么就可以通过聚合组对这个高基数维度做一定的“隔离”。我们把这个高基数的维度放入一个单独的聚合组,再把所有可能会与这个高基数维度一起被查询到的其他维度也放进来。这样,这个高基数的维度就被“隔离”在一个聚合组中了,所有不会与它一起被查询到的维度都没有和它一起出现在任何一个分组中,因此也就不会有多余的Cuboid产生。这点也大大减少了包含该高基数维度的Cuboid的数量,可以有效地控制Cube的膨胀率。
5.2.2 并发粒度优化
当Segment中某一个Cuboid的大小超出一定的阈值时,系统会将该Cuboid的数据分片到多个分区中,以实现Cuboid数据读取的并行化,从而优化Cube的查询速度。具体的实现方式如下:
构建引擎根据Segment估计的大小,以及参数“kylin.hbase.region.cut”的设置决定Segment在存储引擎中总共需要几个分区来存储,如果存储引擎是HBase,那么分区的数量就对应于HBase中的Region数量。kylin.hbase.region.cut的默认值是5.0,单位是GB,也就是说对于一个大小估计是50GB的Segment,构建引擎会给它分配10个分区。用户还可以通过设置kylin.hbase.region.count.min(默认为1)和kylin.hbase.region.count.max(默认为500)两个配置来决定每个Segment最少或最多被划分成多少个分区。

由于每个Cube的并发粒度控制不尽相同,因此建议在Cube Designer 的Configuration Overwrites(上图所示)中为每个Cube量身定制控制并发粒度的参数。
假设将把当前Cube的kylin.hbase.region.count.min设置为2,kylin.hbase.region.count.max设置为100。这样无论Segment的大小如何变化,它的分区数量最小都不会低于2,最大都不会超过100。相应地,这个Segment背后的存储引擎(HBase)为了存储这个Segment,也不会使用小于两个或超过100个的分区。我们还调整了默认的kylin.hbase.region.cut,这样50GB的Segment基本上会被分配到50个分区,相比默认设置,我们的Cuboid可能最多会获得5倍的并发量。
1.Cube执行情况
通过cube名称查询cube具体执行情况
./bin/kylin.sh org.apache.kylin.engine.mr.common.CubeStatsReader xxx_cube


从分析结果的下半部分可以看到,所有的Cuboid及它的分析结果都以树状的形式打印了出来。在这棵树中,每个节点代表一个Cuboid,每个Cuboid都由一连串1或0的数字组成,如果数字为0,则代表这个Cuboid中不存在相应的维度;如果数字为1,则代表这个Cuboid中存在相应的维度。除了最顶端的Cuboid之外,每个Cuboid都有一个父亲Cuboid,且都比父亲Cuboid少了一个“1”。其意义是这个Cuboid就是由它的父亲节点减少一个维度聚合而来的(上卷)。最顶端的Cuboid称为Base Cuboid,它直接由源数据计算而来。
每行Cuboid的输出中除了0和1的数字串以外,后面还有每个Cuboid 的的行数与父亲节点的对比(Shrink值)。所有Cuboid行数的估计值之和应该等于Segment的行数估计值,每个Cuboid都是在它的父亲节点的基础上进一步聚合而成的,因此从理论上说每个Cuboid无论是行数还是大小都应该小于它的父亲。在这棵树中,我们可以观察每个节点的Shrink值,如果该值接近100%,则说明这个Cuboid虽然比它的父亲Cuboid少了一个维度,但是并没有比它的父亲Cuboid少很多行数据。换而言之,即使没有这个Cuboid, 我们在查询时使用它的父亲Cuboid,也不会有太大的代价。那么我们就可以对这个Cuboid进行剪枝操作。
2.Cube大小
在这里插入图片描述
一般来说,Cube的膨胀率应该在0%~1000%之间,如果一个Cube的膨胀率超过1000%,那么Cube管理员应当开始挖掘其中的原因。通常,膨胀率高有以下几个方面的原因。
1)Cube中的维度数量较多,且没有进行很好的Cuboid剪枝优化,导致Cuboid数量极多;
2)Cube中存在较高基数的维度,导致包含这类维度的每一个Cuboid占用的空间都很大,这些Cuboid累积造成整体Cube体积变大;
3)存在比较占用空间的度量,例如Count Distinct,因此需要在Cuboid的每一行中都为其保存一个较大的寄存器,最坏的情况将会导致Cuboid中每一行都有数十KB,从而造成整个Cube的体积变大;
3.聚合组
聚合组(Aggregation Group)是一种强大的剪枝工具。聚合组假设一个Cube的所有维度均可以根据业务需求划分成若干组(当然也可以是一个组),由于同一个组内的维度更可能同时被同一个查询用到,因此会表现出更加紧密的内在关联。每个分组的维度集合均是Cube所有维度的一个子集,不同的分组各自拥有一套维度集合,它们可能与其他分组有相同的维度,也可能没有相同的维度。每个分组各自独立地根据自身的规则贡献出一批需要被物化的Cuboid,所有分组贡献的Cuboid的并集就成为了当前Cube中所有需要物化的Cuboid的集合。不同的分组有可能会贡献出相同的Cuboid,构建引擎会察觉到这点,并且保证每一个Cuboid无论在多少个分组中出现,它都只会被物化一次。
对于每个分组内部的维度,用户可以使用如下三种可选的方式定义,它们之间的关系,具体如下。
1)强制维度(Mandatory),如果一个维度被定义为强制维度,那么这个分组产生的所有Cuboid中每一个Cuboid都会包含该维度。每个分组中都可以有0个、1个或多个强制维度。如果根据这个分组的业务逻辑,则相关的查询一定会在过滤条件或分组条件中,因此可以在该分组中把该维度设置为强制维度。

2)层级维度(Hierarchy),每个层级包含两个或更多个维度。假设一个层级中包含D1,D2…Dn这n个维度,那么在该分组产生的任何Cuboid中, 这n个维度只会以(),(D1),(D1,D2)…(D1,D2…Dn)这n+1种形式中的一种出现。每个分组中可以有0个、1个或多个层级,不同的层级之间不应当有共享的维度。如果根据这个分组的业务逻辑,则多个维度直接存在层级关系,因此可以在该分组中把这些维度设置为层级维度。
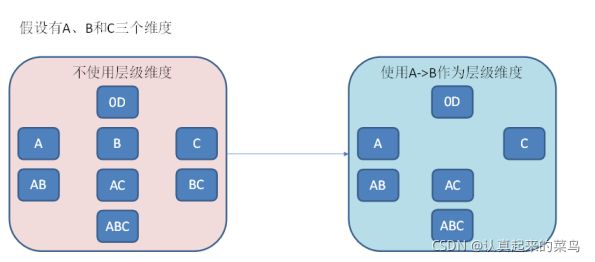
3)联合维度(Joint),每个联合中包含两个或更多个维度,如果某些列形成一个联合,那么在该分组产生的任何Cuboid中,这些联合维度要么一起出现,要么都不出现。每个分组中可以有0个或多个联合,但是不同的联合之间不应当有共享的维度(否则它们可以合并成一个联合)。如果根据这个分组的业务逻辑,多个维度在查询中总是同时出现,则可以在该分组中把这些维度设置为联合维度。


4.资源参数优化


配置Kylin的精确去重指标跨Segment上卷


Kylin 中编辑 measure 的时候,可以选择 Count Distinct,且Return Type 选为 Precisely,点保存就可以了。但是事情没有那么简单,刚才上文在讲 Bitmap 时,一直都有一个前提,放入的值都是数值类型,但是如果不是数值类型的值,它们不能够直接放入 Bitmap,这时需要构建一个全区字典,做一个值到数值的映射,然后再放入 Bitmap 中。
BitMap结构:Bitmap 也称之为 Bitset,它本质上是定义了一个很大的 bit 数组,每个元素对应到 bit 数组的其中一位。
解决跨segment的数据字段去重问题
任意时间段去重
留存分析
kylin解决用户留存数据
用法
要在Apache Kylin中使用保留计算,必须满足以下要求:
*只能是一维
*要计算的度量已定义为精确计数不同的度量
下面介绍了intersect_count的用法:
intersect_count(columnToCount, columnToFilter, filterValueList)
columnToCount the columnt to cacluate and distinct count
columnToFilter the variety dimension
filterValueList the values of variety dimension, should be array
这里有一些例子:
intersect_count(uuid, dt, array[‘20161014’, ‘20161015’])
The precisely distinct count of uuids shows up both in 20161014 and 20161015
intersect_count(uuid, dt, array[‘20161014’, ‘20161015’, ‘20161016’])
The precisely distinct count of uuids shows up all in 20161014, 20161015 and 20161016
intersect_count(uuid, dt, array[‘20161014’])
The precisely distinct count of uuids shows up in 20161014, equivalent to count(distinct uuid)
完整的sql语句示例:
select city, version,
intersect_count(uuid, dt, array[‘20161014’]) as first_day,
intersect_count(uuid, dt, array[‘20161015’]) as second_day,
intersect_count(uuid, dt, array[‘20161016’]) as third_day,
intersect_count(uuid, dt, array[‘20161014’, ‘20161015’]) as retention_oneday,
intersect_count(uuid, dt, array[‘20161014’, ‘20161015’, ‘20161016’]) as retention_twoday
from visit_log
where dt in (‘2016104’, ‘20161015’, ‘20161016’)
group by city, version
结论
基于位图和UDAF intersect_count,我们可以在Apache Kylin上进行快速便捷的保留分析。与传统方式相比,Apache Kylin中的SQL可以更加简单,清晰和高效。
漏斗分析
1.简单维度漏斗分析
漏斗分析,又叫转化漏斗,就是将一个特定过程的多个步骤间的转化情况,以漏斗的形式展示出来,通过图形直观地发现流失最严重的环节,从而有针对性地去进行优化。
△ 表1:漏斗分析
可以看出,漏斗分析中也要用到交集运算,例如:有多少访问了首页的用户,进入到了产品详细页?看了产品详情页的,有多少用户将它加入到了购物车?产品运营人员非常关心这些指标,因为它代表了用户在使用中每一步的转化关系;如果某一个路径上的转化率较低,意味着潜在的问题和风险,需要及时介入。
以前面的示例数据为例,如果我们将 Page 作为一个维度,User ID 做 count distinct 度量,构建成 Cube 后得到这样的用户访问统计(示例):
Page User IDs (Bitmap)
index.html [100,101,102,103,104]
search.html [100,102,103]
detail.html [101,103]
△ 表4:样例 Cube 2
这样通过切换 Page 的值来做交集,我们就可以很容易地计算出它们之间的漏斗转化率,如:
select
intersect_count(user_id, page, array[‘index.html’]) as first_step_uv,
intersect_count(user_id, page, array[‘search.html’]) as second_step_uv,
intersect_count(user_id, page, array[‘detail.html’]) as third_step_uv,
intersect_count(user_id, page, array[‘index.html’, ‘search.html’]) as retention_one_two,
intersect_count(user_id, page, array[‘search.html’,‘detail.html’]) as retention_two_three
from access_log
where dt in (‘2016104’, ‘20161015’, ‘20161016’)
结果:
5, 3, 2, 3, 2
如此行为漏斗的转化率也就很容易得到了:
Page 关联用户数(转化率)
index.html 4(100%)
index.html -> search.html 3 (3/4=75%)
search.html -> detail.html 2 (2/3=66%)
△ 表 5:样例行为漏斗结果
当然这是一个很简单的例子,实际会复杂很多;这里的 Page(页面)可以换成埋点值或其它维度,从而更加细致地分析各种行为之间的关联关系。
2. 进阶版
先或再与操作
有时候业务人员在分析问题的时候,会动态调整分析的组合,把一些条件先进行或(or)操作,然后再跟其它条件做与(and)运算。例如,访问了“搜索页”和“详情页”中任何一个的用户,有多少访问了“付款页”?前两者是一个或的关系,它们的结果需要跟第三个进行与操作。
为了支持这种特殊的计算,我们可以扩展 intersect_count 函数,让它可以理解或运算符。下面是一个示例(这里默认使用了“|”作为或条件的分隔符,如果维度值中可能包含“|”,需通过配置修改成其它符号):
select
intersect_count(user_id, page, array['search.html|detail.html’, ‘payment.html’])
from access_log
Cue 迁移
Cube 迁移
Cube迁移功能主要用于把QA环境下的Cube迁移到PROD环境下,Kylin v3.1.0对这个功能进行了加强,加强的功能列表如下:
在迁移前,Kylin会使用内部定义的一些规则对Cube的质量及兼容性做校验,之前的版本则需要人工去校验;
通过邮件的方式发送迁移请求及迁移结果通知,取代之前的人工沟通;
支持跨Hadoop集群的迁移功能;
I. 在同一个Hadoop集群下的Cube迁移
提供如下两种方式来迁移同一个Hadoop集群下的Cube:
使用Kylin portal;
使用工具类’CubeMigrationCLI.java’;
- 迁移的前置条件
Cube迁移的操作按钮只有Cube的管理员才可见。
在迁移前,必须对要迁移的Cube进行构建,确认查询性能,Cube的状态必须是READY。
配置项’kylin.cube.migration.enabled‘必须是true。
确保Cube要迁移的目标项目(PROD环境下)必须存在。
QA环境和PROD环境必须在同一个Hadoop集群下, 即具有相同的 HDFS, HBase and HIVE等。 - 通过Web界面进行Cube迁移的步骤
首先,要确保有操作Cube的权限。
步骤 1
在QA环境里的 ‘Model’ 页面,点击’Actions’列中的’Action’下拉列表,选择’Migrate’操作:
步骤 2
在点击’Migrate’按钮后, 将会出现一个弹出框:
步骤 3
在弹出框中输入PROD环境的目标项目名称,使用QA环境的项目名称作为默认值。
步骤 4
在弹出框中点击’Validate’按钮,将会在后端对迁移的Cube做一些验证,待验证完毕,会出现验证结果的弹出框。
验证异常及解决方法
The target project XXX does not exist on PROD-KYLIN-INSTANCE:7070: 输入的PROD环境的目标项目名称必须存在。
Cube email notification list is not set or empty: 要迁移的Cube的邮件通知列表不能为空。
建议性提示
Auto merge time range for cube XXXX is not set: 建议设置Cube的配置项:’Auto Merge Threshold’。
ExpansionRateRule: failed on expansion rate check with exceeding 5: Cube的膨胀率超过配置项’kylin.cube.migration.expansion-rate’配置的值,可以设置为一个合理的值。
Failed on query latency check with average cost 5617 exceeding 2000ms: 如果设置配置项’kylin.cube.migration.rule-query-latency-enabled’为true, 在验证阶段后端会自动生成一些SQL来测试Cube的查询性能,可以合理设置配置项’kylin.cube.migration.query-latency-seconds’的值。
步骤 5
待验证通过,点击’Submit’按钮发起Cube迁移请求给Cube的管理员。后端会自动发送请求邮件给Cube管理员:
步骤 6
Cube管理员在接收到Cube迁移请求邮件后,可以通过’Model’页面里’Admins’列的’Action’下拉列表,选择’Approve Migration’操作还是’Reject Migration’操作,同时后端会自动发送请求结果邮件给请求者:
步骤 7
如果Cube管理员选择’Approve Migration’,将会出现如下弹出框:
在弹出框输入正确的目标项目名称,点击’Approve’按钮,后端开始迁移Cube。
步骤 8
迁移Cube成功后,将会出现如下弹出框,显示迁移成功:
步骤 9
最后, 在PROD环境下的’Model’页面,迁移的Cube会出现在列表中,且状态是DISABLED。
- 使用’CubeMigrationCLI.java’工具类进行迁移
作用
CubeMigrationCLI.java 用于迁移 cubes。例如:将 cube 从测试环境迁移到生产环境。请注意,不同的环境是共享相同的 Hadoop 集群,包括 HDFS,HBase 和 HIVE。此 CLI 不支持跨 Hadoop 集群的数据迁移。
如何使用
前八个参数必须有且次序不能改变。
./bin/kylin.sh org.apache.kylin.tool.CubeMigrationCLI
例如:
./bin/kylin.sh org.apache.kylin.tool.CubeMigrationCLI ADMIN:KYLIN@kylin-qa:7070 ADMIN:KYLIN@kylin-prod:7070 kylin_sales_cube learn_kylin true false false true false
命令执行成功后,请 reload metadata,您想要迁移的 cube 将会存在于迁移后的 project 中。
下面会列出所有支持的参数:
- 如果您使用 cubeName 这个参数,但想要迁移的 cube 所对应的 model 在要迁移的环境中不存在,model 的数据也会迁移过去。
- 如果您将 overwriteIfExists 设置为 false,且该 cube 已存在于要迁移的环境中,当您运行命令,cube 存在的提示信息将会出现。
- 如果您将 migrateSegmentOrNot 设置为 true,请保证 Kylin metadata 的 HDFS 目录存在且 Cube 的状态为 READY。
Parameter Description
srcKylinConfigUri The URL of the source environment’s Kylin configuration. It can be username:password@host:7070, or an absolute file path to the kylin.properties. If you use the URL method, you need to change the ADMIN user name and password to username:password@hostname:port format is placed in the URL, because there is a API needs to be called with admin permission during the migration process.
dstKylinConfigUri The URL of the target environment’s Kylin configuration.
cubeName the name of Cube to be migrated.(Make sure it exist)
projectName The target project in the target environment.(Make sure it exist)
copyAclOrNot true or false: whether copy Cube ACL to target environment.
purgeOrNot true or false: whether purge the Cube from src server after the migration.
overwriteIfExists true or false: overwrite cube if it already exists in the target environment.
realExecute true or false: if false, just print the operations to take, if true, do the real migration.
migrateSegmentOrNot (Optional) true or false: whether copy segment data to target environment. Default true.
II. 跨Hadoop集群下的Cube迁移
注意:
当前只支持使用工具类’CubeMigrationCrossClusterCLI.java’来进行跨Hadoop集群下的Cube迁移。
跨Hadoop集群的Cube迁移,支持同时把Cube数据从QA环境迁移到PROD环境。
- 迁移的前置条件
在迁移前,必须对要迁移的Cube进行构建Segment,确认查询性能,Cube的状态必须是READY。
PROD环境下的目标项目名称必须和QA环境下的项目名称一致。 - 如何使用工具类’CubeMigrationCrossClusterCLI.java’来迁移Cube
./bin/kylin.sh org.apache.kylin.tool.migration.CubeMigrationCrossClusterCLI
例如:
./bin/kylin.sh org.apache.kylin.tool.migration.CubeMigrationCrossClusterCLI -kylinUriSrc ADMIN:[email protected]:17070 -kylinUriDst ADMIN:[email protected]:17777 -cube kylin_sales_cube -updateMappingPath $KYLIN_HOME/updateTableMapping.json -execute true -schemaOnly false -overwrite true
命令执行成功后,在PROD环境下的’Model’页面,迁移的Cube会出现在列表中,且状态是READY。
下面会列出所有支持的参数:
Parameter Description
kylinUriSrc (Required) The source kylin uri with format user:pwd@host:port.
kylinUriDst (Required) The target kylin uri with format user:pwd@host:port.
updateMappingPath (Optional) The path for the update Hive table mapping file, the format is json.
cube The cubes which you want to migrate, separated by ‘,’.
hybrid The hybrids which you want to migrate, separated by ‘,’.
project The projects which you want to migrate, separated by ‘,’.
all Migrate all projects. Note: You must add only one of above four parameters: ‘cube’, ‘hybrid’, ‘project’ or ‘all’.
dstHiveCheck (Optional) Whether to check target hive tables, the default value is true.
overwrite (Optional) Whether to overwrite existing cubes, the default value is false.
schemaOnly (Optional) Whether only migrate cube related schema, the default value is true. Note: If set to false, it will migrate cube data too.
execute (Optional) Whether it’s to execute the migration, the default value is false.
coprocessorPath (Optional) The path of coprocessor to be deployed, the default value is get from KylinConfigBase.getCoprocessorLocalJar().
codeOfFSHAEnabled (Optional) Whether to enable the namenode ha of clusters.
distCpJobQueue (Optional) The mapreduce.job.queuename for DistCp job.
distCpJobMemory (Optional) The mapreduce.map.memory.mb for DistCp job.
nThread (Optional) The number of threads for migrating cube data in parallel.
混合模型
Apache Kylin v1.0 引入了新的实现“混合模型”(也称为“动态模型”);这篇文章介绍了概念以及如何创建混合实例。
问题
对于传入的 SQL 查询,Kylin 选择一种(并且只有一种)实现来服务于查询;在“混合”之前,只有一种对用户开放的实现:Cube。也就是说,只会选择 1 个 Cube 来回答查询;
现在让我们从一个示例案例开始;假设用户有一个名为“Cube_V1”的Cube,它已经构建了几个月;现在用户想要添加新的维度或指标来满足他们的业务需求;于是他创建了一个名为“Cube_V2”的新Cube;
由于某种原因,用户希望保留“Cube_V1”,并希望从“Cube_V1”的结束日期开始构建“Cube_V2”;可能的原因包括:
历史源数据已从 Hadoop 中删除,无法从一开始就构建“Cube_V2”;
立方体很大,重建需要很长时间;
新维度/指标仅在某天可用或应用;
当查询使用新的维度/指标时,用户感觉过去的结果是空的。
对于针对常见维度/指标的查询,用户期望扫描“Cube_V1”和“Cube_V2”以获得完整的结果集;在这样的背景下,“混合模式”被引入来解决这个问题。
混合模型
混合模型是一种新的实现,它是一个或多个其他实现(多维数据集)的组合;见下图。
Hybrid 没有真正的存储;它就像是表上的虚拟数据库视图;混合实例充当委托人,将请求转发给其子实现,然后在从它们返回时合并结果。
如何添加混合实例
到目前为止,还没有用于创建/编辑混合的 UI;如果有需要,您需要手动编辑 Kylin 元数据;
第一步:备份kylin元数据存储
export KYLIN_HOME=“/path/to/kylin”
$KYLIN_HOME/bin/metastore.sh backup
将创建一个备份文件夹,假设它是 $KYLIN_HOME/metadata_backup/2015-09-25/
第二步:创建子文件夹“hybrid”
mkdir -p $KYLIN_HOME/metadata_backup/2015-09-25/hybrid
第 3 步:创建混合实例 json 文件:
vi $KYLIN_HOME/metadata_backup/2015-09-25/hybrid/my_hybrid.json
输入内容如下,“name”和“uuid”需要唯一:
{
“uuid”: “9iiu8590-64b6-4367-8fb5-7500eb95fd9c”,
“name”: “my_hybrid”,
“realizations”: [
{
“type”: “CUBE”,
“realization”: “Cube_V1”
},
{
“type”: “CUBE”,
“realization”: “Cube_V2”
}
]
}
这里“Cube_V1”和“Cube_V2”是你想要组合的立方体。
第 4 步:将混合实例添加到项目
使用文本编辑器打开项目 json 文件(例如项目“default”):
vi $KYLIN_HOME/metadata_backup/2015-09-25/project/default.json
在“realizations”数组中,添加如下条目,类型必须为“HYBRID”,“realization”是混合实例的名称:
{
"name": "my_hybrid",
"type": "HYBRID",
"realization": "my_hybrid"
}
第 5 步:上传元数据:
$KYLIN_HOME/bin/metastore.sh restore $KYLIN_HOME/metadata_backup/2015-09-25/
请注意,“restore”操作会将元数据从本地上传到远程 hbase 存储,这可能会覆盖远程的更改;因此,请在此期间 Kylin 服务器没有元数据更改时执行此操作(没有构建作业,没有立方体创建/更新等),或者在运行“恢复”之前仅将更改的文件拾取到一个空的本地文件夹;
第 6 步:重新加载元数据
重启 Kylin 服务器,或者在 Kylin Web UI 的“管理”选项卡中单击“重新加载元数据”以加载更改;理想情况下,混合动力车将开始工作;您可以通过编写一些 SQL 来进行一些验证。
常问问题:
问题 1:什么时候会选择混合来回答 SQL 查询?
如果其底层多维数据集之一可以回答查询,则将选择混合体;
问题 2:如何混合回答查询?
Hybrid 会将查询委托给它的每个子实现;如果子多维数据集能够进行此查询(匹配所有维度/指标),则将结果返回给混合,否则将被跳过;最后查询引擎会在返回给用户之前聚合来自混合的数据;
问题 3:混合会检查日期/时间重复吗?
不; 这取决于用户确保混合中的多维数据集没有日期/时间范围重复;例如,“Cube_V1”结束于2015-9-20(不含),“Cube_V2”应从2015-9-20(含)开始;
问题 4:混合是否会限制具有相同数据模型的子多维数据集?
不; 为了提供尽可能多的灵活性,混合不检查子多维数据集的事实/查找表和连接条件是否相同;但是用户应该了解他们在做什么以避免意外行为。
问题 5 : 混合动力车可以有另一个混合动力车吗?
不; 我们看不到需要;到目前为止,它假设所有的孩子都是立方体;
问题 6:我可以使用混合来连接多个立方体吗?
不; 混合的目的是合并历史立方体和新立方体,类似于“联合”,而不是“加入”;
问题 7:如果禁用了子立方体,是否会通过混合进行扫描?
不; 混合实例将在向其发送查询之前检查子实现的状态;所以如果立方体被禁用,它不会被扫描。
具体操作
Hybrid 模型
本教材将会指导您创建一个 Hybrid 模型。 关于 Hybrid 的概念,请参考这篇博客。
I. 创建 Hybrid 模型
一个 Hybrid 模型可以包含多个 cube。
点击顶部的 Model,然后点击 Models 标签。点击 +New 按钮,在下拉框中选择 New Hybrid。
输入 Hybrid 的名字,然后选择包含您想要查询的 cubes 的模型,然后勾选 cube 名称前的单选框,点击 > 按钮来将 cube(s) 添加到 Hybrid。
注意:如果您想要选择另一个 model,您应该移除所有已选择的 cubes。
点击 Submit 然后选择 Yes 来保存 Hybrid 模型。创建完成后,Hybrid 模型就会出现在左边的 Hybrids 列表中。
II. 更新 Hybrid 模型
点击 Hybrid 名称,然后点击 Edit 按钮。然后您就可以通过添加或删除 cube(s) 的方式来更新 Hybrid。
点击 Submit 然后选择 Yes 来保存 Hybrid 模型。
现在您只能通过点击 Edit 按钮来查看 Hybrid 详情。
III. 删除 Hybrid 模型
将鼠标放在 Hybrid 名称上,然后点击 Action 按钮,在下拉框中选择 Drop。然后确认删除窗口将会弹出。
点击 Yes 将 Hybrid 模型删除。
IV. 运行查询
Hybrid 模型创建成功后,您可以直接进行查询。 因为 hybrid 比 cube 有更高优先级,因此可以命中 cube 的查询会优先被 hybrid 执行,然后再转交给 cube。
点击顶部的 Insight,然后输入您的 SQL 语句。
*请注意, Hybrid model 不适合 “bitmap” 类型的 count distinct 跨 cube 的二次合并,请务必在查询中带上日期维度. *
其他
第一个问题:
在Tableau中显示的度量值如果是SUM计算,那么在Hive中最好使用的字段类型为decimal(20,0),避免使用int以及bigint。
第二个问题:
高基数维度的Cube在构建过程中报错
GC limite exceeded 以及 java.lang.OutOfMemoryError: Java heap space
解决办法:在${KYLIN_HOME}/conf/kylin_job_conf.xml中添加配置项如下:
mapreduce.map.java.opts.max.heap 983 mapreduce.reduce.java.opts.max.heap 983 mapreduce.map.java.opts -Xmx8000m -XX:OnOutOfMemoryError='kill -9 %p' mapreduce.reduce.java.opts -Xmx8000m -XX:OnOutOfMemoryError='kill -9 %p' mapred.child.java.opt -Xmx8000m -XX:OnOutOfMemoryError='kill -9 %p'第三个问题,高基数维度组优化:
在cube的acvanced setting中优化方式
1> 高技术维度可以单独做一个维度组,并且设置为mandatory dimensions。
例如:有维度a b c d,其中d为高基数维度,a为日期维度。为了在任何情况下查询都较为快速,可以做两个Aggregation Groups,第一组 a b c为一组,a为必要维度;第二组 a b c d为一组,a d为必要维度。
2>rowkeys设置中,尽量把高技术维度位置放在前面,并且shard by设置为true(这样能有效避免数据倾斜)。
第四个问题,关于count distinct优化:
Advanced ColumnFamily 中,把count distinct列单独放入一个ColumnFamily
第五个问题:
当想让一个字段既做维度也做度量,可以先将其设置为维度,然后在添加度量时勾选 Also Show Dimensions。