保障AI时代的图像安全:揭示解决虚假图片危机的三种策略

-
- 写在前面
- 从 P 图到假图批量生成,AI 图像安全成可信 AI 重点关注方向
- 三大技术:提前布局,合合信息 AI 图像安全技术助力行业健康发展
-
- ✔ AI 图像篡改检测技术
- ✔ 生成式图像鉴别技术
- ✔ OCR 对抗攻击技术
- 一项标准:与中国信通院等权威机构一道,助力科技向善
写在前面
2023 年世界人工智能大会(WAIC 2023)于 2023 年 7 月 6 日至 7 月 8 日在上海举办,本届大会以“智联世界 生成未来”为主题,聚焦通用人工智能发展,鼓励拥抱智能新时代,共话产业新未来。共同探讨了人工智能领域的前沿技术,包括深度学习、机器学习、自然语言处理、计算机视觉等多个领域,同时还展示了多项人工智能技术在实体经济领域的应用成果和案例。
大会包含了一系列主题论坛和研讨会,探讨人工智能领域的前沿技术和应用场景。在中国信通院举办的《“聚焦·大模型时代 AIGC 新浪潮”》主题论坛中,合合信息向我们展示了“三大技术 一项标准”,助力探索 AI 在图像内容安全领域可信化发展的多重可能:
从 P 图到假图批量生成,AI 图像安全成可信 AI 重点关注方向
近年随着人工智能(AI)技术的迅速发展,AI 在图像领域的应用也日益广泛。但同时也出现了一些与图像安全相关的问题,例如图像篡改、虚假图像生成、图像隐写等,大量基于虚假图片产生的诈骗案件、网络暴力事件在全球范围内造成了恶劣的影响。

通过使用深度学习模型和大规模数据集,可轻松地生成各种具有高度真实感的虚假图像,例如虚假的新闻报道、虚假的科学研究和虚假的广告等。这些虚假图像往往会对人们的思想和行为以及社会都产生负面影响,虚假广告和不实的商业宣传可能会让消费者受到欺骗,导致经济损失;虚假新闻可能会误导公众对于某些事件的认知,引发社会不稳定因素;虚假的社交媒体身份或者虚假的品牌形象等都可能导致消费者对品牌或者社交媒体平台的信任降低等不可预测的后果。当下 图像内容的安全 与 可信性 成为了公众关注的焦点,AI 图像的安全问题亟需解决。

合合信息长期聚焦于 “AI+DATA” 在文档智能领域中的前沿技术探索,以及"细粒度"视觉差异伪造图像鉴别、证件文档图片信息加密、生成式图像判别、文档图像完整性保护等行业焦点议题,在服务帮助个人及企业保护图像内容安全方面均有着突出优势。
三大技术:提前布局,合合信息 AI 图像安全技术助力行业健康发展
合合信息 AI 图像安全技术方案主要包括三项重点技术:AI 图像篡改检测、生成式图像鉴别、OCR 对抗攻击技术,以此应对日益高发的恶意 P 图、生成式造假和个人信息非法提取等现象。
✔ AI 图像篡改检测技术
所谓图像篡改检测就是给定一张图片,输入到篡改检测模型中,由模型判断这张图片是否被篡改,并且定位出篡改图像的篡改区域。合合信息 AI 图像篡改检测技术是基于深度学习的图像篡改检测技术。该技术通过学习图像被篡改后统计特征的变化,智能捕捉图像在篡改过程中留下的细微痕迹,并以热力图的形式展示图像区域篡改地点。
AI 图像篡改检测主要使用了两种深度学习模型:卷积神经网络(CNN)和循环神经网络(RNN)。其中 CNN 用于提取图像的特征,而 RNN 则用于分析序列数据,如文本或图像中的时间序列信息。在图像篡改检测过程中,首先将输入的图像进行预处理,包括图像大小的调整、特征提取和数据增强等;然后使用 CNN 对图像进行特征提取,得到图像的局部特征,如纹理、结构;接着使用 RNN 对提取的局部特征进行序列分析,捕捉图像的时间序列信息。在模型训练阶段,合合信息使用监督学习的方法,将已知的图像篡改样本输入到模型中,让模型通过不断地调整权重和偏置,使得模型的输出结果与真实标签(篡改或未篡改)尽可能地接近。整体上截图篡改检测分为四个类型:
- 复制移动。某一个图像中的某个区域复制到另外一个区域;
- 拼接。两个毫不相干的图像拼接成一个新的图像;
- 擦除。主要是擦除文档中的一些关键信息;
- 重打印。在擦除的基础上重新编辑新的文档。
该技术可以检测多种类型的图像,无论是转账记录、交易记录,还是聊天记录等多种截图,图像篡改检测技术均可“慧眼”识假,对于保障信息的真实性和完整性、防止欺诈方面有着显著作用。
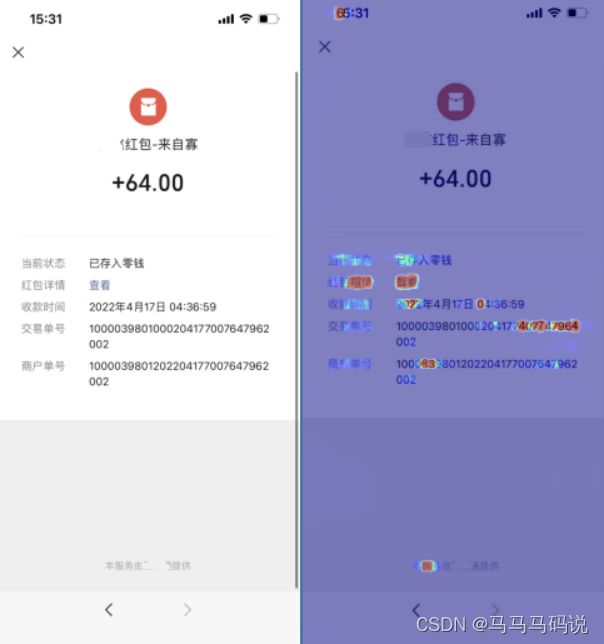
“重打印”篡改图片检测的具体操作是这样的,给定一张图片,输入到合合信息篡改检测模型中,随后便能够判别这张图像是否被篡改,并且定位出篡改图像的篡改区域。
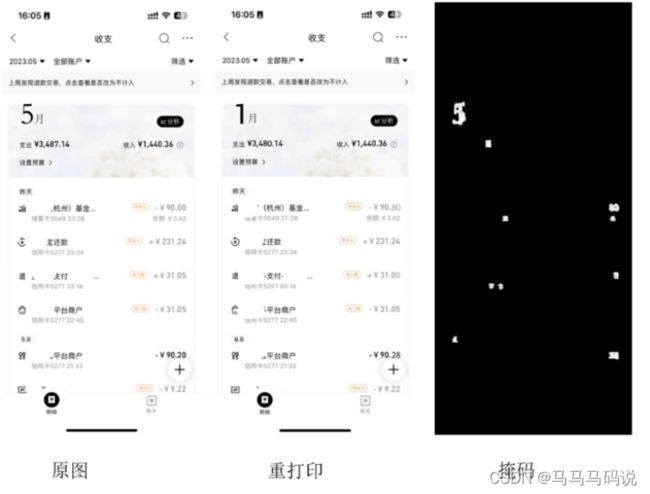
当下篡改检测的主要难点在于能否从没有明显差异的图片中找出被篡改的截图,找出的图片中是误检率是否可控;其实与证照篡改检测相比,截图检测难度更大。现有的视觉模型通常难以充分发掘原始图像和篡改图像的细粒度差异特征,所以很难实现令人满意的准确率。而合合信息提出的基于 HRNet 的编码器-解码器结构的图像真实性鉴别模型,结合图像本身的信息包括但不限于噪声、频谱等, 从而捕捉到细粒度的视觉差异实现高精度鉴别,完美的解决了这些难题。
✔ 生成式图像鉴别技术
人工智能爆火的当下,有不法分子也开始利用人工智能,使用生成的图片规避版权、身份验证,非法获取利益。由 AI 生成的图片可能会造成信息混乱和误导,影响人们对于真实事件和事实的判断和认知等。
合合信息生成式图像鉴别技术是一种利用多维度特征来分辨真实图片和生成式图片的技术。在实践中,生成式图像鉴别技术面临的主要挑战是 AI 生成的图像场景繁多,机器难以判别等。合合信息针对这一难点开发了独特的解决方案 —— 基于空域与频域关系建模来识别 AI 生成的图像。
该技术通过分析图像的特征和规律,利用神经网络对图像进行分类和识别,以鉴别图像是否是由 AI 生成的。它可以鉴别多种类型的图像,包括但不限于自然风景、人物画像、图标等。通过对图像的细节和结构进行分析,识别出图像中由 AI 生成的成分,并给出相应的警告或提示。以下是生成式图像鉴别模型结构:
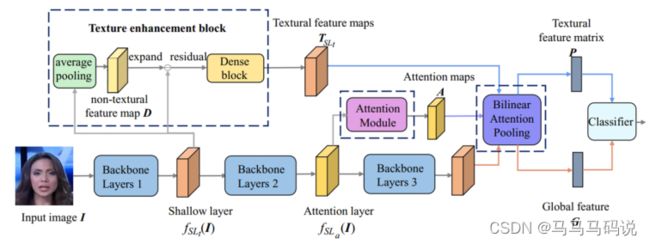
基于空域与频域关系建模,以实现在不用穷举图片的情况下,利用多维度特征来分辨真实图片和生成式图片的细微差异。输入图片后,模型通过多个空间注意力头来关注空间特征,并使用纹理增强模块放大浅层特征中的细微伪影,增强模型对真实人脸和伪造人脸的感知与判断准确度。生成式图像鉴别技术可完美应用于这些行业:
- 身份验证和访问控制:防止使用伪造人脸进行身份验证,应用于安全通行系统、电子门禁系统等;
- 金融反欺诈:在银行和金融领域防止使用伪造人脸进行信用卡诈骗、账户盗窃和身份冒用等欺诈行为;
- 移动设备的安全检测:可用于手机等移动设备的人脸解锁功能,以防止伪造人脸入侵用户的个人信息和设备;
- 数字图像取证:鉴定图像和视频中是否存在伪造的人脸,用于法医学和犯罪调查等;
- 视频会议远程认证:确保参与者使用真实人脸进行身份验证和认证。
✔ OCR 对抗攻击技术
在日常生活中,人们经常会拍摄自己的相关证件、文件并发送给第三方,但是这些图片上承载的个人信息很有可能被不法分子使用 OCR 技术识别提取并泄露,所以就需要一项技术来对文档图片进行“加密”。
OCR(Optical Character Recognition,光学字符识别)是一种将印刷或手写文本转换为计算机可编辑和存储格式的技术,通过利用图像处理和模式识别算法,将图像中的文本字符提取出来,并将其转换为计算机可识别的数字形式。OCR 对抗攻击则是给定一张测试的文本图片并指定目标文本,输入到系统中进行对抗攻击并输出结果图片,使得结果图片中先前指定的目标文本无法被 OCR 系统识别而不影响人眼对目标文本的识别。该对抗攻击分为白盒攻击和黑盒攻击两种形式,通常黑盒攻击最为常用。

作为一种基于深度学习的图像伪造检测技术,该技术利用神经网络和深度学习的方法,对图像进行分类和识别,以鉴别图像的真实性和可信度。其主要原理是通过向神经网络中注入一些精心设计的伪造特征,这些特征在人类视觉系统中难以察觉,但可以影响神经网络的分类结果。通过向真实图像中添加这些伪造特征,可以使得原本真实的图像被神经网络误判为伪造图像,从而达到欺骗的目的。在不影响肉眼观看的情况下可阻止机器自动爬取,通过 OCR 对抗攻击技术的应用,当我们在网上传输包含个人信息的图片时,可以对图像中的个人信息(如地址、银行卡号等)进行 OCR 对抗攻击从而防止包含个人信息的图片在网络传播过程中被第三方平台截获,以达到保护个人隐私的安全。其次在图像中包含大量文本数据时,可以对图像中的数据进行 OCR 对抗攻击,防止第三方通过 OCR 系统读取并保存图像中所有的文字内容,从而降低数据泄露的风险,起到数据加密的效果。
一项标准:与中国信通院等权威机构一道,助力科技向善
中国信通院已牵头启动了《文档图像篡改检测标准》制定工作,由合合信息、中国图象图形学学会、中国科学技术大学等科技创新企业及知名学术机构联合编制。旨在围绕伪造图像鉴别等焦点议题,凝聚行业共识,为行业提供有效指引;汇总图像内容安全领域需求,挖掘文档图像篡改检测技术趋势,助力图像产业健康成长。
《文档图像篡改检测标准》的制定,或将为中国 “可信 AI” 在机器视觉、图像处理领域的体系建设提供有力支持。随着人工智能技术的不断发展和应用,未来我们可以期待更多的创新和突破,为行业发展注入更多的安全感和稳定性。