【Python爬虫实战02】
在本次实战中,记录了如何使用Python爬虫来获取有声小说的播放量。使用requests库发送HTTP请求,并借助BeautifulSoup库来解析网页内容。
⚙️ 准备工作
在开始之前,确保已经安装了Python以及requests和BeautifulSoup库。可以使用以下命令来安装它们:
pip install requests
pip install BeautifulSoup
爬取目标
需要得到的数据:专辑名、演播、播放量
页面分析
在爬取之前,需要对目标网页进行分析,以确定要提取的数据所在的位置。
打开目标网页,并使用浏览器的开发者工具(通常是按
F12键)查看网页的HTML结构。
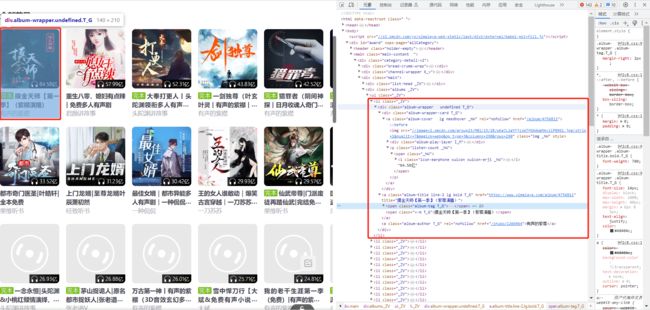
使用检查功能,可找到目标数据在网页中所在位置,接下来就是通过request.get()方法获取数据。
编写爬虫代码
首先,需要导入所需的库:
import requests
from bs4 import BeautifulSoup
接下来,将发送GET请求并获取网页内容:
url = 'https://www.xxxxx.com/category/a3/mostplays/'
# 使用了常见的浏览器User-Agent来模拟浏览器请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
html = response.text
print(html.text)
运行结果:

这样不太好看,使用prettify()方法格式化输出解析后的文档,更容易找出目标:
soup = BeautifulSoup(response.text, "html.parser")
print(soup.prettify())
运行结果:
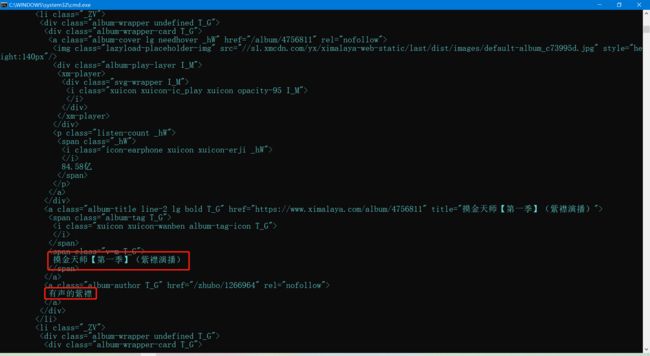
接下来,将使用BeautifulSoup库来解析HTML页面,并提取需要的信息。
分析界面可以得到书籍信息都在class_="_ZV"的标签中。
使用find_all方法获取所有书籍信息片段。
# 使用BeautifulSoup库来解析HTML页面
soup = BeautifulSoup(html, 'html.parser')
# 提取书籍列表
books = soup.find_all("li", class_="_ZV")
使用for循环提取每一本书的信息:书名、
for book in books:
# 提取书名
title = book.find("span", class_="v-m T_G").text
# 提取播放量
playcount = book.find("span", class_="_hW").text
# 提取作者
ablumuser = book.find("a", class_="album-author T_G").text
结果展示
现在,可以将提取的信息进行处理和展示。例如,可以打印播放榜单中的前十项:
print(f'书名:{title}-作者:{playcount}-播放量:{playcount}')
完整代码
下面是完整的Python爬虫代码:
import requests
from bs4 import BeautifulSoup
# 网址需要修改
url = "https://www.xxxxx.com/category/a3/mostplays/"
# 使用了常见的浏览器User-Agent来模拟浏览器请求
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
}
response = requests.get(url, headers=headers)
# print(response.text)
soup = BeautifulSoup(response.text, "html.parser")
# print(soup.prettify())
books = soup.find_all("li", class_="_ZV")
print(books)
# data = []
for book in books:
title = book.find("span", class_="v-m T_G").text # 书名
playcount = book.find("span", class_="_hW").text # 播放量
ablumuser = book.find("a", class_="album-author T_G").text
# data.append([title, playcount, ablumuser])
print(f'书名:{title}-作者:{playcount}-播放量:{playcount}')
总结
通过本次实战,学习了如何使用requests和BeautifulSoup库来爬取播放量。使用requests发送HTTP请求获取网页内容,然后使用BeautifulSoup库来解析HTML页面,并提取需要的信息。
现在,可以根据实际需求对提取的信息进行进一步处理,如数据存储、分析或可视化。
参考:
网络爬虫——BeautifulSoup详讲与实战——以山河作礼。