Python爬虫:Scrapy框架
Python爬虫:Scrapy框架
-
-
- ️ Scrapy介绍
- Scrapy框架
- Scrapy项目
- 创建爬虫过程
- ️ 页面分析
- 提取信息
- 完整代码
- 结语
-
在本篇博文中,我们将介绍Scrapy框架,并演示如何使用Scrapy进行网页爬取。Scrapy是一个强大且灵活的Python爬虫框架,它可以帮助我们快速开发和管理爬虫项目。
️ Scrapy介绍
Scrapy是一个基于Python的开源爬虫框架,它提供了一整套用于爬取网站的工具和组件。Scrapy使用了异步IO和事件驱动的架构,具有高效、可扩展和可配置的特点。
Scrapy框架
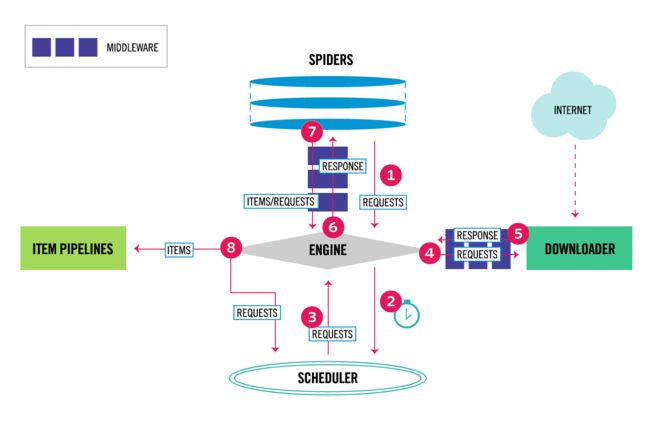
Scrapy是一个强大的Python爬虫框架,用于快速和高效地抓取网页数据。它提供了一组组件,每个组件都有特定的功能和用途。以下是Scrapy框架的主要组成部分的描述:
| 组件 | 描述 | 是否需要手写代码? |
|---|---|---|
| Spiders | 定义如何抓取特定网站的规则和逻辑 | 是 |
| Items | 定义要提取和保存的数据结构 | 是 |
| Pipelines | 处理从爬虫提取的数据,如数据清洗、验证和存储等 | 部分情况下需要手写代码 |
| Middleware | 修改请求和响应的处理过程,如添加代理、设置User-Agent等 | 部分情况下需要手写代码 |
| Downloader | 下载器,用于发起HTTP请求和处理响应 | 通常不需要手写代码 |
| Scheduler | 调度器,用于管理爬取的请求队列和去重 | 通常不需要手写代码 |
| Settings | 配置文件,用于配置Scrapy框架和爬虫的参数 | 部分情况下需要手写代码 |
| CrawlSpider | 一个高级的Spider,通过规则自动生成请求和处理逻辑 | 是 |
| SpiderMiddleware | 修改Spider处理过程的中间件,如添加代理、设置User-Agent等 | 部分情况下需要手写代码 |
需要注意的是,Scrapy框架的核心组件(如Spiders、Items、CrawlSpider)需要开发者手动编写代码来定义和配置。而其他组件(如Downloader、Scheduler、Settings)则由框架自动处理,不需要手写特定代码。
一个完整的爬虫,开发者需要参与Spiders、Pipeline、Middleware部分的开发。甚至最简单的爬虫,只需要开发Spiders部分即可。
Scrapy项目
在使用Scrapy之前,我们需要创建一个Scrapy项目。在命令行中执行以下命令来创建一个新的Scrapy项目:
scrapy startproject myproject
这将创建一个名为myproject的文件夹,其中包含Scrapy项目的基本结构和配置文件。
创建爬虫过程
接下来,我们将创建一个爬虫来定义如何爬取网站的规则和逻辑。在命令行中执行以下命令来创建一个新的爬虫:
cd myproject
scrapy genspider myspider example.com
这将在spiders目录下创建一个名为myspider的Python文件,其中包含了一个简单的爬虫模板。
️ 页面分析
在这一步中,我们需要分析目标网站的页面结构和数据,以确定如何提取所需信息。使用浏览器的开发者工具,检查网页元素和网络请求,并找到我们
感兴趣的数据。
提取信息
现在,我们将使用Scrapy提供的选择器和规则来提取我们需要的数据。在爬虫文件中,我们可以定义如何提取和处理页面中的特定元素。
以下是一个简单的示例,展示了如何使用Scrapy提取页面中的标题和链接:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://www.example.com']
def parse(self, response):
titles = response.css('h1::text').extract()
links = response.css('a::attr(href)').extract()
for title, link in zip(titles, links):
yield {
'title': title,
'link': link,
}
完整代码
以下是完整的Scrapy爬虫代码示例:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://www.example.com']
def parse(self, response):
titles = response.css('h1::text').extract()
links = response.css('a::attr(href)').extract()
for title, link in zip(titles, links):
yield {
'title': title,
'link': link,
}
结语
恭喜!您已经学会了使用Scrapy框架进行网页爬取。通过了解Scrapy的基本组成部分,创建项目并编写爬虫,您可以开始爬取目标网站并提取所需的数据。
希望本篇博文对您有所帮助,并通过使用emoji表情增加了一些趣味。Scrapy框架提供了更多高级功能和配置选项,可以进一步扩展和优化您的爬虫项目。
(待修改。。。)