MVC和MTV模式
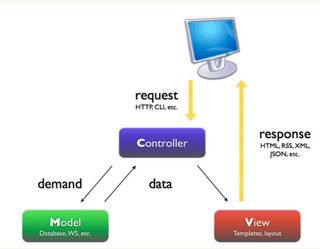
著名的MVC模式:所谓MVC就是把web应用分为模型(M),控制器(C),视图(V)三层;他们之间以一种插件似的,松耦合的方式连接在一起。
模型负责业务对象与数据库的对象(ORM),视图负责与用户的交互(页面),控制器(C)接受用户的输入调用模型和视图完成用户的请求。
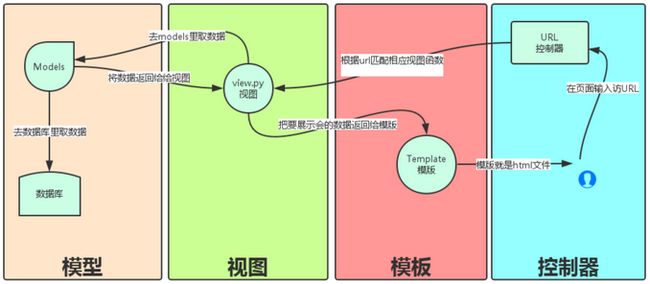
Django的MTV模式本质上与MVC模式没有什么差别,也是各组件之间为了保持松耦合关系,只是定义上有些许不同,Django的MTV分别代表:
Model(模型):负责业务对象与数据库的对象(ORM)
Template(模版):负责如何把页面展示给用户
View(视图):负责业务逻辑,并在适当的时候调用Model和Template
此外,Django还有一个url分发器,它的作用是将一个个URL的页面请求分发给不同的view处理,view再调用相应的Model和Template
django的流程和命令行工具
1、django实现流程
django #安装: pip3 install django# 创建project django-admin startproject mysite(项目名) ---mysite ---settings.py ---url.py ---wsgi.py ---- manage.py(启动文件) # 创建APP python mannage.py startapp app01 # settings配置 TEMPLATES STATICFILES_DIRS=( os.path.join(BASE_DIR,"statics"), ) STATIC_URL = '/static/' # 我们只能用 STATIC_URL,但STATIC_URL会按着你的STATICFILES_DIRS去找# 使用模版 render(req,"index.html") # 启动项目 python manage.py runserver 127.0.0.1:8090 # 连接数据库,操作数据 model.py
2、django的命令行工具
django-admin.py 是Django的一个用于管理任务的命令行工具,manage.py是对django-admin.py的简单包装,每一个Django Project里都会有一个mannage.py。
<1> 创建一个django工程 : django-admin.py startproject mysite
当前目录下会生成mysite的工程,目录结构如下:

- manage.py ----- Django项目里面的工具,通过它可以调用django shell和数据库等。
- settings.py ---- 包含了项目的默认设置,包括数据库信息,调试标志以及其他一些工作的变量。
- urls.py ----- 负责把URL模式映射到应用程序。
<2>在mysite目录下创建blog应用: python manage.py startapp blog
<3>启动django项目:python manage.py runserver 8080
setting配置
静态文件(主要指的是如css,js,images这样文件,在settings里面可以配置STATIC_ROOT和STATIC_URL)
1、为了后端的更改不会影响前端的引入,避免造成前端大量修改
STATIC_URL = '/static/' #引用名
STATICFILES_DIRS = (
os.path.join(BASE_DIR,"statics") #实际名 ,即实际文件夹的名字
)
django对引用名和实际名进行映射,引用时,只能按照引用名来,不能按实际名去找
------error-----不能直接用,必须用STATIC_URL = '/static/':
2、(statics文件夹写在不同的app下,静态文件的调用):
STATIC_URL = '/static/'
STATICFILES_DIRS=(
('hello',os.path.join(BASE_DIR,"app01","statics")) ,
)
#
Django URL (路由系统)
URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL模式以及要为该URL模式调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于这个URL调用这段代码,对于那个URL调用那段代码。
urlpatterns = [
url(正则表达式, views视图函数,参数,别名),
]
参数说明:
- 一个正则表达式字符串
- 一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
- 可选的要传递给视图函数的默认参数(字典形式)
- 一个可选的name参数
Django2.0以上正则表达式的匹配要导入 re_path
1 # re_path 2 #re_path是用正则匹配 3 from django.contrib import admin 4 from django.urls import path,re_path 5 from app01 import views 6 7 urlpatterns = [ 8 path('admin/', admin.site.urls), 9 path('login/',views.login.as_view()), 10 #表示之匹配 index/test 开头,并且index/test结尾的路径 11 re_path(r'^index/test$',views.test), 12 #匹配index/(四位数字年份)如果在正则里面加了括号,那么会在调用函数的时候自动将括号里匹配成功的内容传给试图函数,要在创建函数的时候接收,否则会报错 13 re_path(r'^inde/([0-9]{4})/$',views.year),
如果要中URL中捕获一个值,就需要在表达式用添加括号
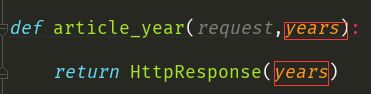
re_path('article/([0-9]{4}$)', views.article_year), #无名分组
re_path('article/(?P[0-9]{4})/(?P[0-9]{2})', views.article_year_month), #有名分组,指定了别名,接收参数时不能更改别名

路由分流
可以将不同的应用文件夹下都创建单独的urls文件,需要先导入include
![]()

相应应用下再添加相应的路由即可。输入地址时,需要先加上项目名,由全局的urls文件中分流到相应的应用中的urls文件中再进一步分流
url的反向解析
反向解析就是动态获取url的一种方式,可以在视图和模板中使用
如何使用?
在App目录urls中配置 加上 name属性 name ='xxx'
怎么视图中怎么使用呢?
引入 from django.urls import reverse
一、无参数
项目urls.py:![]()
app的urls.py: ![]()
在视图中:
在模板中:![]()
二、有参数
(1)不指定参数名
项目urls.py:![]()
app的urls.py:![]()
视图中:
def table_obj_list(request, app_name, model_name): print(reverse('table_obj_list',args=(app_name,model_name))) # /zadmin/crm/customerinfo/
(2)指定参数名
![]()
视图中:
def table_obj_list(request, app_name, model_name): print(reverse('table_obj_list',kwargs={'app_name':app_name,'model_name':model_name})) # /zadmin/crm/customerinfo/
Django Views(视图函数)
http请求中产生两个核心对象:
http请求:HttpRequest对象
http响应:HttpResponse对象
所在位置:django.http
之前我们用到的参数request就是HttpRequest 检测方法:isinstance(request,HttpRequest)
1 HttpRequest对象的属性和方法:
path: 请求页面的全路径,不包括域名 method: 请求中使用的HTTP方法的字符串表示。全大写表示。例如 if req.method=="GET": do_something() elseif req.method=="POST": do_something_else() GET: 包含所有HTTP GET参数的类字典对象 POST: 包含所有HTTP POST参数的类字典对象 服务器收到空的POST请求的情况也是可能发生的,也就是说,表单form通过 HTTP POST方法提交请求,但是表单中可能没有数据,因此不能使用 if req.POST来判断是否使用了HTTP POST 方法;应该使用 if req.method=="POST" COOKIES: 包含所有cookies的标准Python字典对象;keys和values都是字符串。 FILES: 包含所有上传文件的类字典对象;FILES中的每一个Key都是"file" name="" />标签中name属性的值,FILES中的每一个value同时也是一个标准的python字典对象,包含下面三个Keys: filename: 上传文件名,用字符串表示 content_type: 上传文件的Content Type content: 上传文件的原始内容 user: 是一个django.contrib.auth.models.User对象,代表当前登陆的用户。如果访问用户当前没有登陆,user将被初始化为 django.contrib.auth.models.AnonymousUser的实例。你可以通过user的is_authenticated()方法来辨别用户是否登陆: if req.user.is_authenticated();只有激活Django中AuthenticationMiddleware 时该属性才可用 session: 唯一可读写的属性,代表当前会话的字典对象;自己有激活Django中的session支持时该属性才可用。 #方法 get_full_path(),比如:http://127.0.0.1:8000/index33/?name=123 ,req.get_full_path()得到的结果就是/index33/?name=123 req.path:/index33
2 HttpResponse对象:
对于HttpRequest对象来说,是由django自动创建的,但是,HttpResponse对象就必须我们自己创建。每个view请求处理方法必须返回一个HttpResponse对象。
HttpResponse类在django.http.HttpResponse
在HttpResponse对象上扩展的常用方法:
页面渲染: render()(推荐) 页面跳转: redirect("路径") locals(): 可以直接将函数中所有的变量传给模板
-----------------------------------url.py urlpatterns = [ path('register/', views.register,name="reg"), path('login/', views.login), ] -----------------------------------views.py def register(request): if request.method=="POST": print(request.POST.get("user")) print(request.POST.get("age")) user=request.POST.get("user") if user=="zhang": #页面跳转 return redirect("/login/") return HttpResponse("success!") return render(request,"register.html") def login(request): name="zhang" return render(request,"login.html",locals()) -----------------------------------register.html-----------------------------------login.html
hello {{ name }}
总结: render和redirect的区别: render的url没有跳转到/login/,而是还在/register/,刷新一下就没了。 render只是直接返回一个页面。redirect会跳转到指定页面,并且url也随之变化Template基础
---------模板语法---------
一模版的组成
组成:HTML代码+逻辑控制代码
二 逻辑控制代码的组成
1 变量(使用双大括号来引用变量):
语法格式: {{var_name}}
------Template和Context对象
>>> python manange.py shell (进入该django项目的环境) >>> from django.template import Context, Template >>> t = Template('My name is {{ name }}.') >>> c = Context({'name': 'Stephane'}) >>> t.render(c) 'My name is Stephane.' # 同一模板,多个上下文,一旦有了模板对象,你就可以通过它渲染多个context,无论何时我们都可以 # 像这样使用同一模板源渲染多个context,只进行 一次模板创建然后多次调用render()方法渲染会 # 更为高效:
def current_time(req): now=datetime.datetime.now() return render(req, 'current_datetime.html', {'current_date':now}) #最后一个参数可以用locals()代替,表示创建的变量名可以直接在相应的html文件中用相
#应变量名代替,把变量渲染到页面上,而不需再用字典来表示
------深度变量的查找
在到目前为止的例子中,我们通过 context 传递的简单参数值主要是字符串,然而,模板系统能够非常简洁地处理更加复杂的数据结构,例如list、dictionary和自定义的对象。
在 Django 模板中遍历复杂数据结构的关键是句点字符 (.)。
---------------------url.py urlpatterns = [ path('query/', views.query), ] ---------------------views.py def query(request): l=["AA","BB","CC"] d={"name":"听雨轩","age":23} return render(request,"index.html",locals()) ------------------------index.htmlhello {{ l.0 }}
#显示 AAhello {{ d.name }}
#显示 听雨轩hello {{ d.age }}
#显示 23
------变量的过滤器(filter)的使用
语法格式: {{obj|filter:param}}


# add : 给变量加上相应的值 # # 2 addslashes : 给变量中的引号前加上斜线 # # 3 capfirst : 首字母大写 # # 4 cut : 从字符串中移除指定的字符 # # 5 date : 格式化日期字符串 # # 6 default : 如果值是False,就替换成设置的默认值,否则就是用本来的值 # # 7 default_if_none: 如果值是None,就替换成设置的默认值,否则就使用本来的值
---------------------url.py urlpatterns = [ path('query/', views.query), ] ---------------------views.py def query(request): d={"name":"听雨轩","age":23} test="hello world"
test2="he ll o w or ld"
t=datetime.datetime.now()
e=[]
a="click" return render(request,"index.html",locals()) ------------------------index.html
<h1>{{ d.age|add:12 }}h1> #显示 35
<h1>{{ test|capfirst }}h1> #显示 Hello world
<h1>{{ t|date:'Y-m-d' }}h1> #显示 2019-02-06
<h1>{{ e|default:'空' }}h1> #显示 空
#让变量a按标签来显示
<h1>{{ a|safe }}h1> #显示a标签,如果不加safe,则是一段html字符串
{% autoescape off %} #直接显示a标签,把加入的安全机制关掉,让a正常显示
<h1>{{ a }}h1>
{% endautoescape %}
2 标签(tag)的使用(使用大括号和百分比的组合来表示使用tag)
{% tags %}
------{% if %} 的使用
{% if %}标签计算一个变量值,如果是“true”,即它存在、不为空并且不是false的boolean值,系统则会显示{% if %}和{% endif %}间的所有内容
% if d.age > 20 %}hello {{ d.name }}
{% elif d.age < 20 %}hello {{ d.name }}的年龄小于20
{% endif %}
{% if %} 标签接受and,or或者not来测试多个变量值或者否定一个给定的变量
{% if %} 标签不允许同一标签里同时出现and和or,否则逻辑容易产生歧义
------{% for %}的使用
{% for %}标签允许你按顺序遍历一个序列中的各个元素,每次循环模板系统都会渲染{% for %}和{% endfor %}之间的所有内容
-
{% for obj in list %}
- {{ obj }} {% endfor %}
--------------------views.py def query(request): l=["AA","BB","CC"] return render(request,"index.html",locals()) --------------------index.html {% for name in l %} #显示 AA
{% for %}标签内置了一个forloop模板变量
forloop.counter表示循环的次数,它从1开始计数,第一次循环设为1
{% for name in l %}
<li>{{ forloop.counter }}:{{ name }}li>
{% endfor %}
显示 1:AA
2:BB
3:CC
-----------------------------------------------------
forloop.counter0 类似于forloop.counter,但它是从0开始计数,第一次循环设为0
forloop.revcounter 反过来计数
forloop.revcounter0 反过来计数,末尾为0
------------------------------------------------------
{% empty %} 判断是否为空
{% for i in li %}
{{ forloop.counter0 }}----{{ i }}
{% empty %} this is empty! {% endfor %}
------{%csrf_token%}:csrf_token标签
Django中post方式第一次提交时不让提交,csrf_token则相当于一把钥匙,让其第一次也可以提交
------{% url %}: 引用路由配置的地址
路由分发中启用别名

![]()
------{% with %}:用更简单的变量名替代复杂的变量名
{% with total=fhjsaldfhjsdfhlasdfhljsdal %}
{{ total }}
{% endwith %}
------{% verbatim %}: 禁止render(直接显示不做渲染)
{% verbatim %}
{{ hello }}
{% endverbatim %} # 页面直接显示 {{ hello }}
------{% load %}: 加载标签库
自定义过滤器和标签
------a、在app中创建templatetags模块(必须的)
------b、创建任意 .py 文件,如:my_tags.py
from django import template from django.utils.safestring import mark_safe register = template.Library() #register的名字是固定的,不可改变 # 自定义过滤器 @register.filter def multi(x,y): #参数x是默认的,对应于过滤器|左边的参数 return x*y # 自定义标签 @register.simple_tag def simple_tag(x,y,z): #可传任意多个参数 return x*y*z
------c、在使用自定义simple_tag和filter的html文件中导入之前创建的 my_tags.py :{% load my_tags %}
------d、使用simple_tag和filter(如何调用)
-------------------------------.html {% load xxx %} #首行 # num=12 参数只能传一个 {{ num|filter_multi:2 }} #24 {% simple_tag_multi 2 5 3 %} 参数不限,不能用在控制语句上,控制语句只能用filter
filter可以用在if等语句后,simple_tag不可以
{% if num|filter_multi:30 > 100 %}
{{ num|filter_multi:30 }}
{% endif %}
extend模板继承
------extend(继承)模板标签
到目前为止,我们的模板范例都只是些零星的 HTML 片段,但在实际应用中,你将用 Django 模板系统来创建整个 HTML 页面。 这就带来一个常见的 Web 开发问题: 在整个网站中,如何减少共用页面区域(比如站点导航)所引起的重复和冗余代码?
用 Django 解决此类问题的首选方法是使用更加优雅的策略—— 模板继承 。
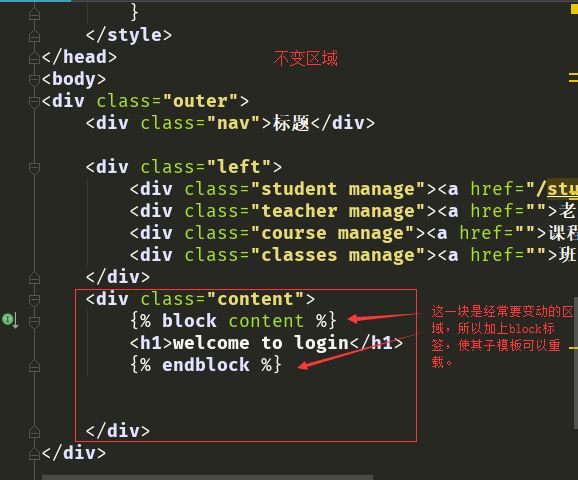
本质上来说,模板继承就是先构造一个基础框架模板,而后在其子模板中对它所包含站点公用部分和定义块进行重载。
我们使用模板标签: {% block %} 。 所有的 {% block %} 标签告诉模板引擎,子模板可以重载这些部分。 每个{% block %}标签所要做的是告诉模板引擎,该模板下的这一块内容将有可能被子模板覆盖。
基础模板
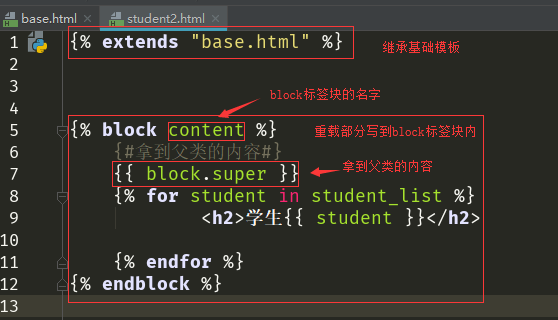
子模板
提醒:
继承并不会影响到模板的上下文。 换句话说,任何处在继承树上的模板都可以访问到你传到模板中的每一个模板变量。你可以根据需要使用任意多的继承次数。
以下是使用模板继承的一些诀窍:
<1>如果在模板中使用 {% extends %} ,必须保证其为模板中的第一个模板标记(要在第一行)。 否则,模板继承将不起作用。
<2>一般来说,基础模板中的 {% block %} 标签越多越好。 记住,子模板不必定义父模板中所有的代码块,因此
你可以用合理的缺省值对一些代码块进行填充,然后只对子模板所需的代码块进行(重)定义。 俗话说,钩子越
多越好。
<3>如果发觉自己在多个模板之间拷贝代码,你应该考虑将该代码段放置到父模板的某个 {% block %} 中。
如果你需要访问父模板中的块的内容,使用 {{ block.super }}这个标签,这个变量将会表现出父模
板中的内容。 如果只想在上级代码块基础上添加内容,而不是全部重载,该变量就显得非常有用了。
<4>不允许在同一个模板中定义多个同名的 {% block %} 。 存在这样的限制是因为block 标签的工作方式是双向的。
也就是说,block 标签不仅挖了一个要填的坑,也定义了在父模板中这个坑所填充的内容。如果模板中出现了两个
相同名称的 {% block %} 标签,父模板将无从得知要使用哪个块的内容。
include 加载模板
可以包含另外一个模块过来
{ %include "foo/bar.html" % }
Models
数据库的配置
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)
3 在django的项目中会默认使用sqlite数据库,在settings里有如下设置:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } }
如果想要更改mysql数据库,需要修改如下:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': ' ', #你的数据库名称 'USER': 'root', #你的数据库用户名 'PASSWORD': '', #你的数据库密码 'HOST': '', #你的数据库主机,留空默认为localhost 'PORT': '3306', #你的数据库端口 } }

在models.py文件中写好表结构后(下面会讲怎么写表结构),在启动Django项目前先创建表。
在pycharm的Terminal处切换到项目文件下输入 python manage.py makemigrations 会在项目的app01下的migrations文件夹里创建一个表文件,。
再次输入 python manage.py migrate 则会创建数据库表
注意:
NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。 设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。 然后,启动项目,会报错:no module named MySQLdb 这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb对于py3有很大问题,所以我们需要的驱动是PyMySQL 所以,我们只需要找到项目名文件下的__init__,在里面写入: import pymysql pymysql.install_as_MySQLdb()
ORM(对象关系映射)
用于实现面向对象编程语言里不同类型系统的数据之间的转换,换言之,就是用面向对象的方式去操作数据库的创建表以及增删改查等操作。
优点: 1 ORM使得我们的通用数据库交互变得简单易行,而且完全不用考虑SQL语句。
缺点:1 性能有所牺牲,不过现在的各种ORM框架都在尝试各种方法,比如缓存,延迟加载登来减轻这个问题。效果很显著。
2 对于个别复杂查询,ORM仍然力不从心,为了解决这个问题,ORM一般也支持写raw sql。
下面讲Django ORM语法,为了更好的理解,我们来做一个基本的 书籍/作者/出版商 数据库结构。
from django.db import models # Create your models here. class Book(models.Model): #所有字段默认都为空 name=models.CharField(max_length=20) #字符类型字段 price=models.FloatField() #浮点类型字段 pub_date=models.DateField() #时间类型字段 publish=models.ForeignKey("Publish",on_delete=models.CASCADE) #建立外键 #on_delete=models.CASCADE.Django2.0后需要加上,此值设置,是级联删除。老版本这个参数是默认的 class Author(models.Model): name=models.CharField(max_length=20) class Publish(models.Model): name=models.CharField(max_length=32) city=models.CharField(max_length=32)
注意1:记得在settings里的INSTALLED_APPS中加入'app01',然后再同步数据库。
分析代码:
<1> 每个数据模型都是django.db.models.Model的子类,它的父类Model包含了所有必要的和数据库交互的方法。并提供了一个简介漂亮的定义数据库字段的语法。
<2> 每个模型(类)相当于单个数据库表(多对多关系例外,会多生成一张关系表),每个属性也是这个表中的字段。属性名就是字段名,它的类型(例如CharField)相当于数据库的字段类型(例如varchar)。每一个实例对象也就是表中查询出来的一条记录或者记录集合
<3> 模型之间的三种关系:一对一,一对多,多对多。
一对一:实质就是在主外键(author_id就是foreign key)的关系基础上,给外键加了一个UNIQUE=True的属性;
一对多:就是主外键关系;(foreign key)
多对多:(ManyToManyField) 自动创建第三张表(当然我们也可以自己创建第三张表:两个foreign key)
常用字段类型
Field重要参数
<1> null : 数据库中字段是否可以为空 <2> blank: django的 Admin 中添加数据时是否可允许空值 <3> default:设定缺省值 <4> editable:如果为假,admin模式下将不能改写。缺省为真 <5> primary_key:设置主键,如果没有设置django创建表时会自动加上 <6> unique:数据唯一 <7> verbose_name Admin中字段的显示名称 <8> validator_list:有效性检查。非有效产生 django.core.validators.ValidationError 错误 <9>choices:一个用来选择值的2维元组。第一个值是实际存储的值,第二个用来方便进行选择。 如SEX_CHOICES= (( ‘F’,'Female’),(‘M’,'Male’),) gender = models.CharField(max_length=2,choices = SEX_CHOICES)
表的操作(增删改查):
-------------------------------------增(create , save) -------------------------------
from app01.models import * #create方式一: Book.objects.create(name=zZ') #create方式二: Book.objects.create(**{"name":"zZ"}) #save方式一: b=Book(name="zZ") b.save() #save方式二: b=Book() b.name="zZ" b.save()
一对多方式怎么写呢
方式一:
由于绑定一对多的字段,比如publish,存到数据库中的字段名叫publish_id,所以我们可以直接给这个字段设定对应值: Book.objects.create(name="linux运维",price=77, pub_date="2019-2-3",publish_id=1) publish_id的值必须要在publish表中存在,因为它是外键 方式二 #先获取要绑定的Publish对象: public_obj=Publish.objects.filter(name="人民出版社")[0] #将 publisher_id=1 改为 publish=pub_obj Book.objects.create(name="GO", price=66, pub_date="2019-1-3", publish=public_obj)
-----------------------------------------删(delete) ---------------------------------------------
Book.objects.filter(author="zZ").delete()
删除是级联删除的
-----------------------------------------改(update和save) ----------------------------------------
#方式一 #先查询再修改 (推荐这种) update是QuerySet对象的一个方法 Book.objects.filter(author="zZ").update(price=999) #方式二 b=Book.objects.get(author="zq") #get返回的是一个model对象,它没有update方法 b.price=120 b.save() #这种保存方式每个字段都会重新保存,费时间
update方法直接设定对应属性
save方法会将所有属性重新设定一遍,效率低
加入这段代码到settings.py配置文件中就可以看到每个操作对应的sql代码
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
---------------------------------------查(filter,value等) -------------------------------------
---------->查询API:
# <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 # <2>all(): 查询所有结果 # <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 #-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()-------- # <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 # <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 # <6>order_by(*field): 对查询结果排序 # <7>reverse(): 对查询结果反向排序 # <8>distinct(): 从返回结果中剔除重复纪录 # <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 # <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。 # <11>first(): 返回第一条记录 # <12>last(): 返回最后一条记录 # <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False。
book_list=Book.objects.all() #取得一个QuerySet对象集合 #取某条记录中的某部分 book_list=Book.objects.filter(author="zq").values("name") #查询除了查询条件之外的记录 book_list=Book.objects.exclude(author="zq").values("name","price") #去重 book_list=Book.objects.all().values("name").distinct() #求查询到的记录条数 book_count=Book.objects.all().values("name").distinct().count() # 模糊查询,价格大于50的书名和价格查询出来 book_list=Book.objects.filter(price__gt=50).values("name","price") # 查询名字带有p的记录,不区分大小写
book_list=Book.objects.filter(name__icontains="p").values("name","price")
---------->惰性机制:
所谓惰性机制:Publish.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它并不会马上执行sql,而是当调用QuerySet的时候才执行。
QuerySet特点:
<1> 可迭代的
<2> 可切片
注意事项:
(1) 下面的代码会得到数据库中id=2的人:person = Person.objects.filter(id=2) 上面的代码并没有运行任何的数据库查询。它加上一些过滤条件,或者将它传给某个函数,这些操作都不会发送给数据库。因为数据库查询是显著影响web应用性能的因素之一。 (2) 要真正从数据库获得数据,可以遍历queryset或者使用if queryset,总之用到数据时就会执行sql. (3) queryset是具有cache的.当你遍历queryset时,所有匹配的记录会从数据库获取,然后转换成Django的model。这被称为执行(evaluation).这些model会保存在queryset内置的cache中,这样如果再次遍历这个queryset,不需要重复运行通用的查询。 (4) 简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,但有时并不需要这些数据!为了避免这个,可以用exists()方法来检查是否有数据 if obj.exists(): (5) 当queryset非常巨大时,cache会成为问题.可以使用iterator()方法来获取数据,处理完数据就将其丢弃。 objs = Book.objects.all().iterator() # iterator()可以一次只从数据库获取少量数据,这样可以节省内存 for obj in objs: print(obj.name) #如果再次遍历则没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,没得遍历了。当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行查询。
条件关联查询、多对多查询
表结构:
Book 表:![]()
Author表:![]()
Publish表:![]()
Book_Author表:![]()
-----------------双下划线查询--------------------- # 出人民出版社出过的书的名字与价格 ret=Book.objects.filter(publish__name="人民出版社").values("name","price") # 拿到这本书相应出版社的名字 ret2=Publish.objects.filter(book__name="python").values("name") 另一种写法: ret3=Book.objects.filter(name="python").values("publish__name") # 找到北京的出版社出过的书 ret4=Book.objects.filter(publish__city="北京").values("name") ----------------------多对多查询--------------------- # 查询作者名为zq的作者出过的书的名称及价格 ret=Book.objects.filter(book_author__author__name="zq").values("name","price")
---------->聚合查询和分组查询
<1> aggregate(*args,**kwargs):
通过对QuerySet进行计算,返回一个聚合值的字典。
from django.db.models import Avg,Min,Sum,Max,Count # 求所有书价格的平均值 ret = Book.objects.all().aggregate(Avg("price")) # 求所有书的总价格 ret = Book.objects.all().aggregate(Sum("price")) # 求作者id为1的作者出过的书的总价格 ret=Book.objects.filter(book_author__author_id=1).aggregate(Sum("price")) # aggregate(name=Sum("price")) 可以自己起名字,结果就为自己起的名字
<2> annotate(*args,**kwargs):
可以通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
# 查各个作者出过的书的总价格 ret = Book.objects.values("book_author__author__name").annotate(Sum("price")) # 先对作者名字这一项分组再求和 # 求各个出版社出过的最便宜的书的价格 ret = Publish.objects.values("name").annotate(Min("book__price"))
---------->F查询和Q查询
from django.db.models import F.Q F 使用查询条件的值,专门取对象中某列值的操作 # 给每本书的价格加10 Book.objects.all().update(price=F("price")+10) Q 构建搜索条件 ret = Book.objects.filter(Q(price=87)|Q(name="GO")) # 或查询 ret = Book.objects.filter(~Q(name="GO")) # 非查询 ret = Book.objects.filter(Q(name__contains="G")) Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。
admin的配置
admin是django强大功能之一,它能够从数据库中读取数据,呈现在页面中,进行管理。默认情况下,它的功能已经非常强大,如果不需要复杂的功能,它已经够用,但是有时候,一些特殊的功能还需要定制,比如搜索功能等。。。
如果觉得英文界面不好用,可以在setting.py 文件中修改以下选项
LANGUAGE_CODE = 'en-us' #LANGUAGE_CODE = 'zh-hans'
浏览器输入http://127.0.0.1:8080/admin/ 访问。需要账户密码
可以通过命令 python manage.py createsuperuser 来创建超级用户
# python manage.py createsuperuser Username (leave blank to use 'root'): Email address: Password: Password (again): Superuser created successfully.
为了让 admin 界面管理某个数据模型,我们需要先注册该数据模型到 admin。在admin.py文件中修改
一 认识ModelAdmin
管理界面的定制类,如需扩展特定的model界面需从该类继承。
二 注册medel类到admin的两种方式:
<1> 使用register的方法
admin.site.register(models.Book,BookAdmin) # 加上BookAdmin这个参数(类名)就可以自定制
# 只有注册了在管理界面才会显示相应的表,才能操作
![]()
<2> 使用register的装饰器
@admin.register(Book)
三 掌握一些常用的设置技巧
list_display: 指定要显示的字段
list_filter: 指定列表过滤器
search_fields: 指定搜索的字段
ordering: 指定排序字段
list_per_page:指定分页
list_editable:指定哪些字段上的数据能否在网页直接修改
filter_horizontal : 选择器,如果某个字段的值很多,可以检索
from django.contrib import admin from app01 import models # Register your models here. class BookAdmin(admin.ModelAdmin): list_display = ('id','name','price','pub_date') # 显示字段名 list_editable = ('name','price') # 使数据能在网页上直接修改 # filter_horizontal = () # 选择器,如果某个字段的值很多,可以检索 list_per_page = 3 # 分页,每页显示3条 search_fields = ('id','name','price') # 设置搜索 list_filter = ('pub_date',) # 设置过滤,日期过滤 # 注册 admin.site.register(models.Author) admin.site.register(models.Book,BookAdmin) # 加上这个参数(类名)就可以自定制 admin.site.register(models.Publish)