归并排序与计数排序
目录
1.什么是归并排序
2.归并排序的实现
3.归并排序的非递归实现
4.计数排序
1.什么是归并排序
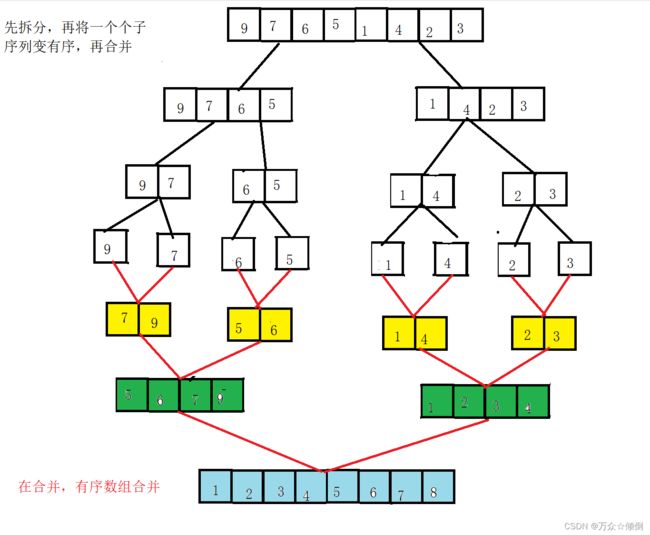
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的 分治(divide-and-conquer)策略 (分治法将问题分成一些小的问题然后递归求解,而治的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之),归并排序是将已有序的子序列归并得到完全有序的序列,即先使子序列有序,再使子序列段间有序。将两个有序表合并为一个有序表,称为二路归并。
动图演示:
模型展示:
2.归并排序的实现
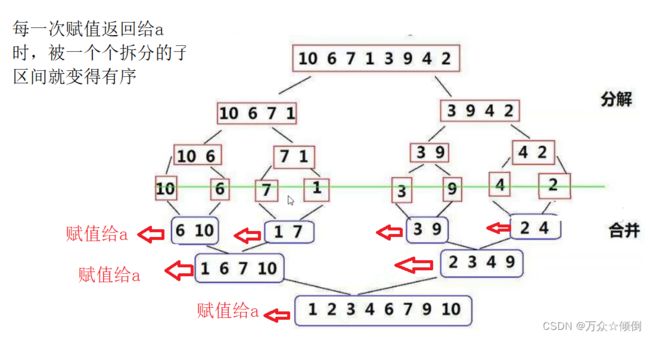
先将区间分割,在递归分割为一个个区间,每一个子区间递归返回之后,该递归的上一层递归的子区间就是原来的区间,递归完成后,最后返回传入的整个区间,且排序完成。
那么如何排序呢:
传入区间后,进入递归,开始分割区间,最后分割为一个数的这样的区间时,不在递归,进入后面的程序,然后开始比较,每一次将最小的一次放入tmp数组中,完成子排序,在之后在copy给a,返回上一层递归,此时该层子排序,因为下一层递归的完成使得部分序列有序
故在该层继续实现子排序,使得整体已有序,在赋值给a,在返回上一层递归。。。。。,递归完成即完成排序。
void mergesort(int* a, int begin, int end, int* tmp)
{
if (begin == end)
return;
int mid = (begin + end) / 2;
// [begin, mid] [mid+1, end]
mergesort(a, begin, mid, tmp);
mergesort(a, mid + 1, end, tmp);
// 归并两个区间
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
void Mergesort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
mergesort(a, 0, n - 1, tmp);
free(tmp);
}
int main()
{
int a[] = { 1,5,3,6,87,10 };
Mergesort(a, 6);
for (int i = 0; i < 6; i++)
{
printf("%d ", a[i]);
}
return 0;
}时间复杂度:O(NlogN)
空间复杂度:O(N)
3.归并排序的非递归实现
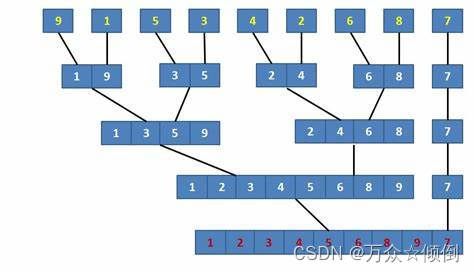
归并排序的非递归实现直接利用循环,将分割的区间进行排序再赋值给原数组,利用gap将区间分割出来,之后修正边界,防止越界。
归并排序非递归实现的思路是使用一个增量gap来控制每一次归并的区间的元素个数,这样同样能够达到递归分解区间的效果。
归并排序要求首先把整个数组分成最小的块,每个块是有序的,然后再逐层往上排序。非递归的归并排序主要在于子序列区间的划分,可以从子序列长度为1开始进行归并,即一个数据为一个子序列,从而得到区间长度为2的子序列,并对其进行归并,又会得到区间长度为4的有序子序列4,依次往后直至整个数组排序完成。实现非递归的归并排序的思路是先用一个参数记录子序列的下标,排序子序列后,参数跳到下一个子序列的下标,排序子序列,直到排序整体。
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
// 1 2 4 ....
int gap = 1;
while (gap < n)
{
int j = 0;
for (int i = 0; i < n; i += 2 * gap)
{
// 每组的合并数据
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
printf("[%d,%d][%d,%d]\n", begin1, end1, begin2, end2);
if (end1 >= n || begin2 >= n)
{
break;
}
// 修正
if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
// 归并一组,拷贝一组
memcpy(a+i, tmp+i, sizeof(int)*(end2-i+1));
}
printf("\n");
//memcpy(a, tmp, sizeof(int) * n);
gap *= 2;
}
free(tmp);
}4.计数排序
作为一种非常规的排序算法,计数排序(Counting sort)是一种稳定的线性时间排序算法。该算法于1954年由 Harold H. Seward 提出。计数排序使用一个额外的数组,其中第i个元素是待排序数组中值等于i的元素的个数。
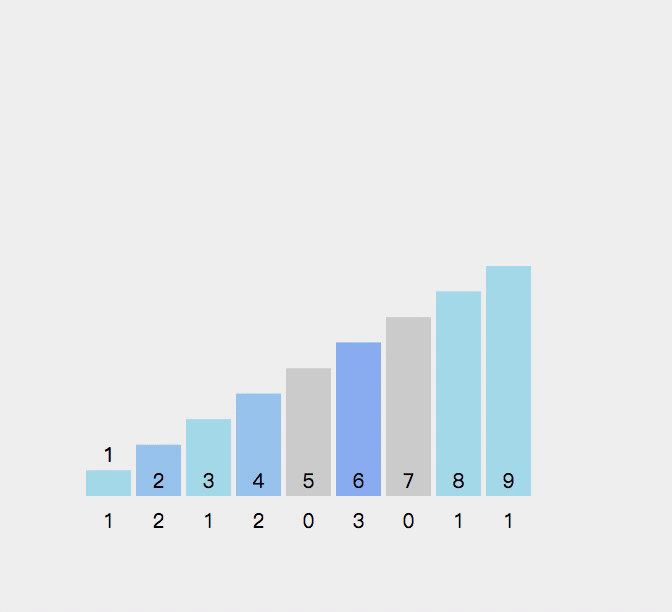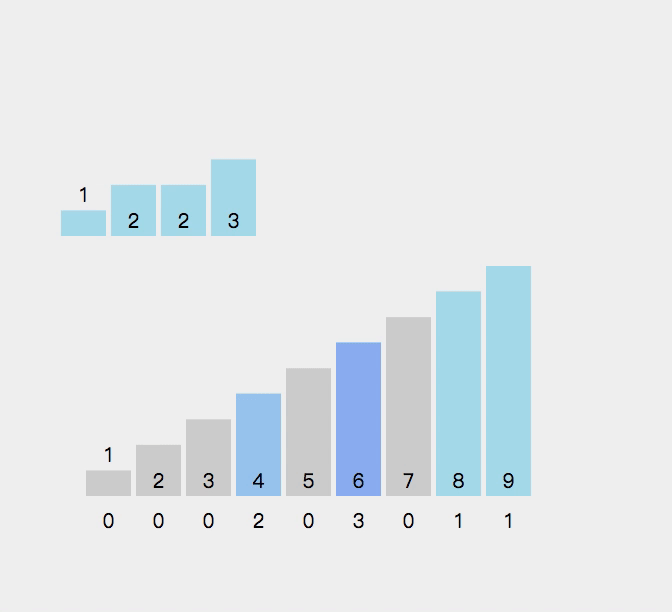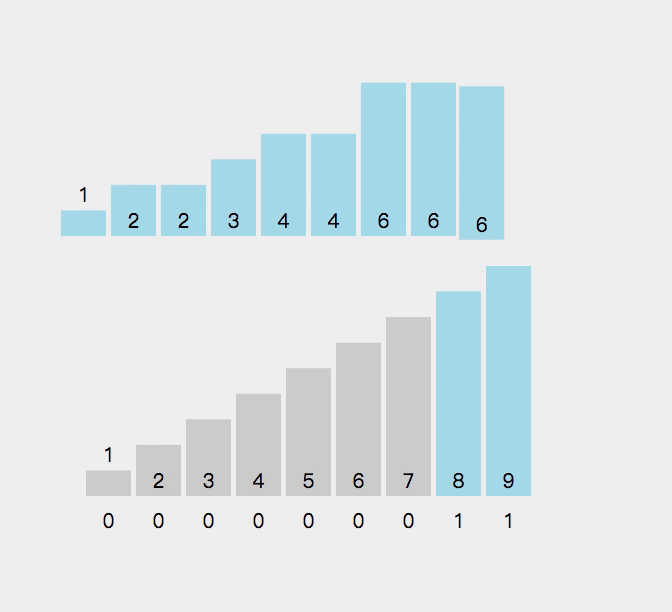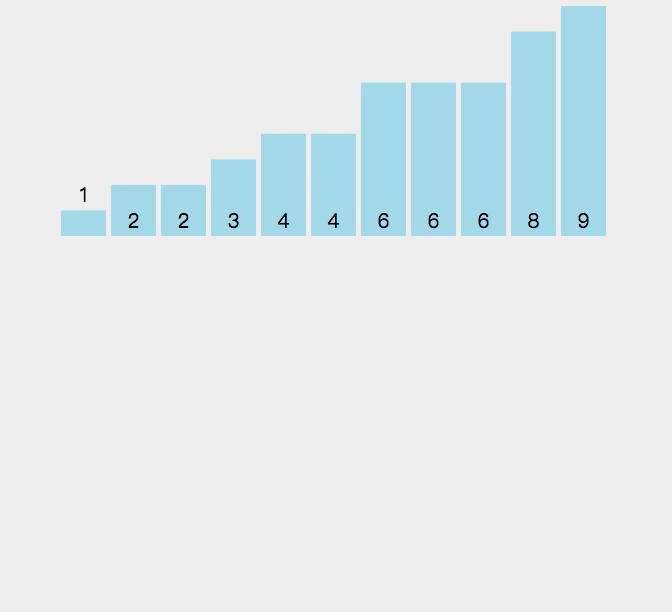
//计数排序
void countsort(int* a, int n)
{
int min = a[0], max = a[0];
for (int i = 0; i < n; i++)
{
if (min > a[i])
{
min = a[i];
}
if (max < a[i])
{
max = a[i];
}
}
int range = max - min + 1;
int* arr = (int*)malloc(sizeof(int) * range);
memset(arr, 0, sizeof(int) * range);
//统计
for(int i=0;i时间复杂度:O(N+range)
空间复杂度:O(N)
计数排序对于数据差距不是很大的时候,其效率甚至优于快速排序,希尔排序等,相当于时间复杂度就是o(n),但时基数排序也有他的缺点:
1.数据差距较大就不适合用计数排序,其时间和空间复杂度都会很高。
2.只能排整形数据