对Linux系统对Spark开发环境配置
单机版本
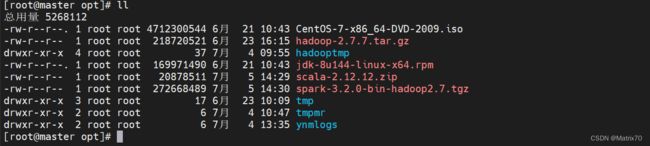
上传scala,spark对应安装包至/opt下
解压scala
此处我暂时/opt下进行的解压,后期将此文件移到/usr下;
也可以解压到/usr/local下,与下面的spark位置一致
#解压scala
unzip scala-2.12.12.zip 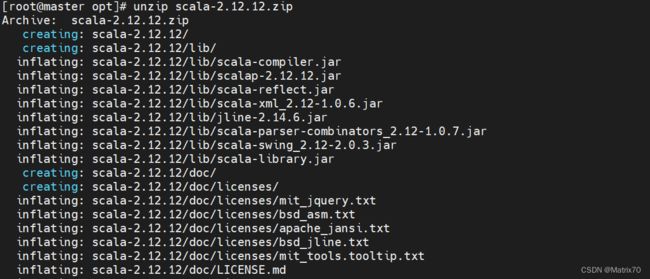
移动scala至/usr目录下
#移动/opt下的 scala-2.12.12解压包 至/usr/scala下
mv /opt/scala-2.12.12 /usr/scala
#eg:可以对scala-2.12.12进行重命名,我在这里没有进行此操作
mv /usr/scala/scala-2.12.12 /usr/scala/scala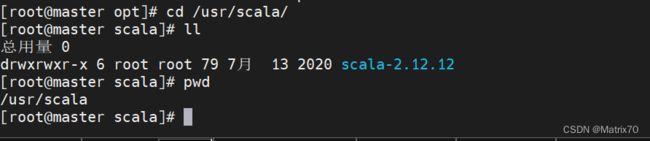
解压spark
解压spark至指定目录/usr/local下
#在/opt目录下执行,将opt下的spark包解压至指定目录/usr/local目录下
tar -xzf /opt/spark-3.2.0-bin-hadoop2.7.tgz -C /usr/local/下图比较久远,未及时更新,就按照上面的就行
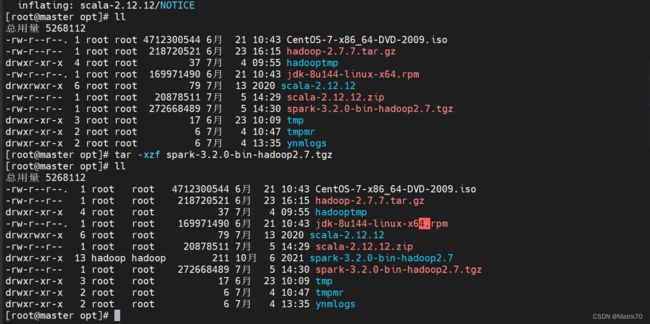
重命名为spark
#重命名spark-3.2.0-bin-hadoop2.7包为spark
mv /usr/local/spark-3.2.0-bin-hadoop2.7 spark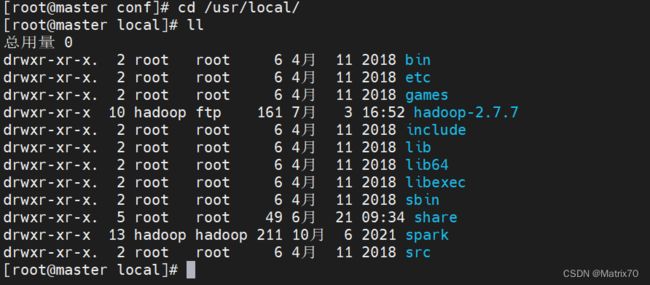
配置环境变量
配置scala环境变量
#编辑配置文件
vi /etc/profile
#配置SCALA_HOME环境变量
export SCALA_HOME=/usr/scala/scala-2.12.12
export PATH=$PATH:$SCALA_HOME/bin保存退出,并source使其生效
source完毕后输入scala并回车,验证scala配置是否成功,出现如下内容说明配置成功。
source /etc/profile 
配置Spark环境变量
#编辑配置文件
vi /etc/profile
#配置SPARK_HOME环境变量
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
保存退出source使其生效
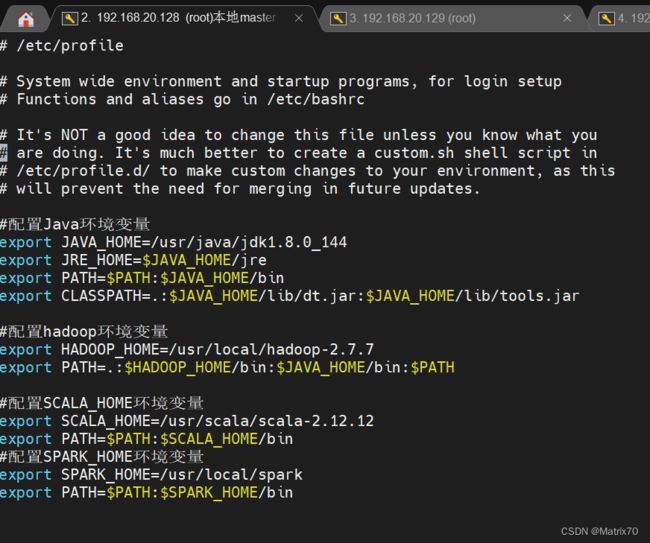
source /etc/profile
完毕后输入spark-shell并回车,验证spark配置是否成功,出现如下内容说明配置成功。
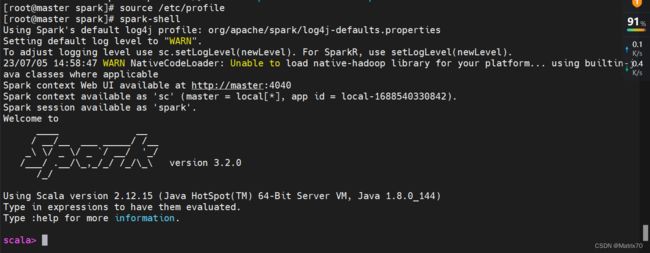
当启动spark完毕,我们可以在主机界面看到单机版版本Spark-UI界面
http://192.168.20.128:4040/jobs/
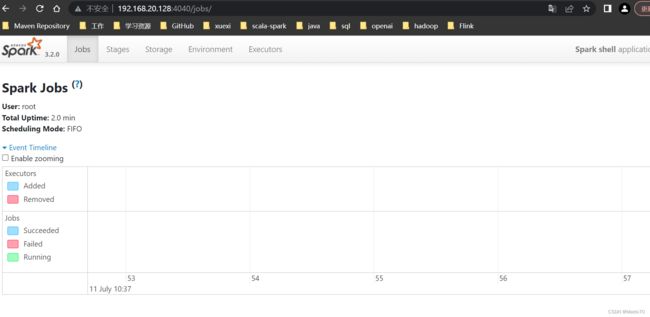
Spark集群版本
首先修改对应配置文件workers.tmplate,加入主机名
在主节点
进入到/usr/spark/spark-3.2.0-bin-hadoop2.7/conf,操作如下
#修改名称
cp workers.template workers
#编辑内容
vi workers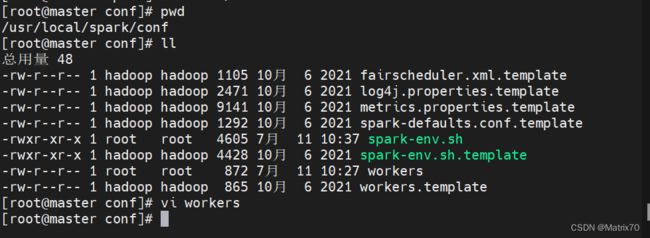
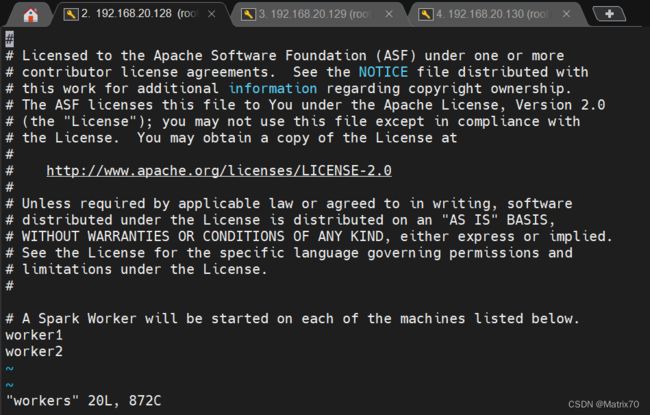
添加如下机器从节点主机名
(注:低版本的spark是slaves.template)
修改对应配置文件spark-env.sh.template为spark-env.sh
#改名字
cp spark-env.sh.template spark-env.sh
#修改文件内容,添加如下
vi spark-env.sh
#配置环境变量
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-2.7.7/bin classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.7/bin
export SPARK_MASTER_IP=192.168.20.128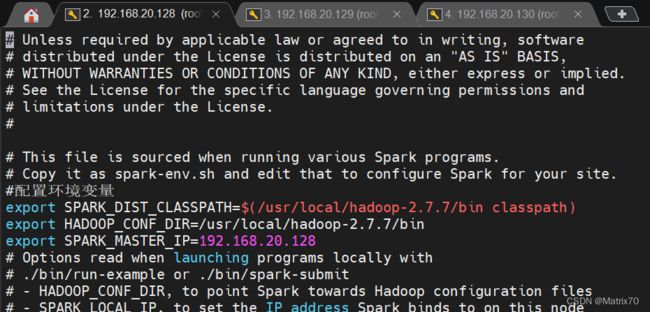
启动hadoop
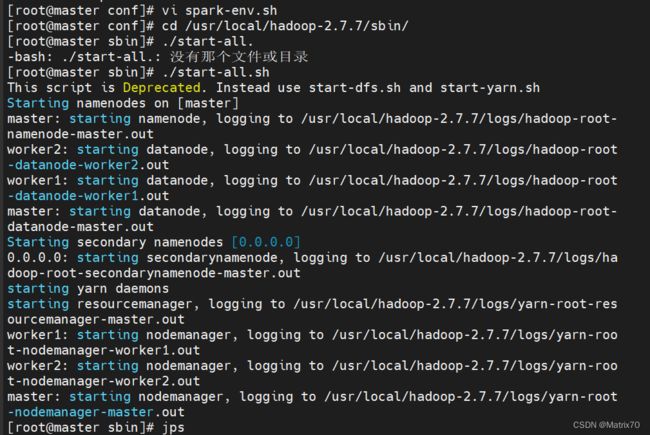
[root@master conf]# vi spark-env.sh
[root@master conf]# cd /usr/local/hadoop-2.7.7/sbin/
[root@master sbin]# ./start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /usr/local/hadoop-2.7.7/logs/hadoop-root- namenode-master.out
worker2: starting datanode, logging to /usr/local/hadoop-2.7.7/logs/hadoop-root -datanode-worker2.out
worker1: starting datanode, logging to /usr/local/hadoop-2.7.7/logs/hadoop-root -datanode-worker1.out
master: starting datanode, logging to /usr/local/hadoop-2.7.7/logs/hadoop-root- datanode-master.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.7.7/logs/ha doop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop-2.7.7/logs/yarn-root-res ourcemanager-master.out
worker1: starting nodemanager, logging to /usr/local/hadoop-2.7.7/logs/yarn-roo t-nodemanager-worker1.out
worker2: starting nodemanager, logging to /usr/local/hadoop-2.7.7/logs/yarn-roo t-nodemanager-worker2.out
master: starting nodemanager, logging to /usr/local/hadoop-2.7.7/logs/yarn-root -nodemanager-master.out
[root@master sbin]# jps
14611 DataNode
15097 ResourceManager
15226 NodeManager
14462 NameNode
14879 SecondaryNameNode
15663 Jps
如下图:
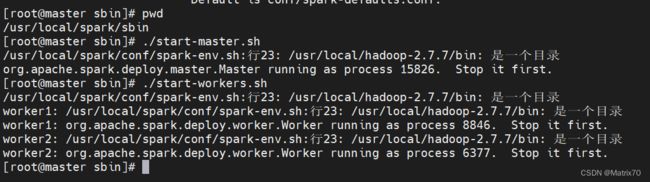
启动Spark
[root@master sbin]# pwd
/usr/local/spark/sbin
./start-master.sh
./start-workers.sh
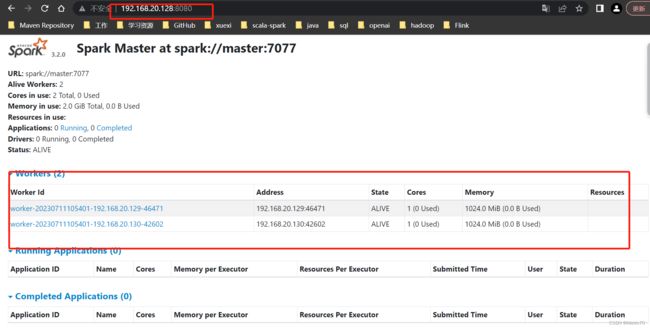
启动完毕查看8080端口
http://192.168.20.128:8080/
关闭spark集群
#关闭spark集群
cd /usr/local/spark/sbin
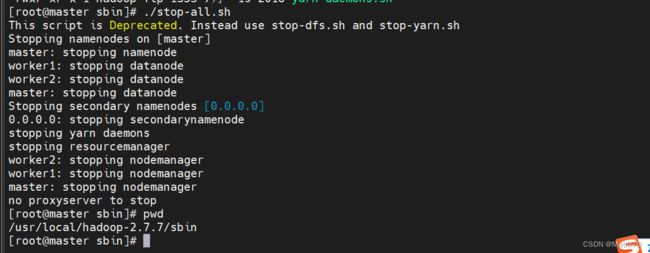
./stop-all.sh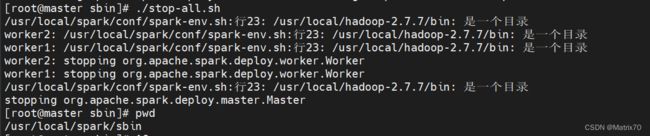
关闭hadoop集群
#关闭hadoop集群
cd /usr/local/hadoop-2.7.7/sbin
./stop-all.sh