神经网络初谈
文章目录
- 简介
- 神经网络的发展历程
-
- 神经网络的初生
- 神经网络的第一次折戟
- 神经网络的新生,Hinton携BP算法登上历史舞台
- 命途多舛,神经网络的第二次寒冬
- 神经网络的重生,黄袍加身,一步封神
- 神经网络的未来,众说纷纭
- 其他时间点
- 神经网络简介
-
- 激活函数的作用
- 偏置项的作用
- 输出层
- RNN
- CNN
- TensorFlow游乐场
- 子问题拓展
-
- 什么是感知机
- 单层感知机为什么无法处理异或问题
- 早期的单层感知机是怎么训练的,为什么这种训练的方式无法迁移到多层感知机上?
- 八卦新闻之人工神经网络与支持向量机之争
- LeCun大神简述
- 参考文献
简介
深度学习、神经网络,近些年来人工智能领域最炙手可热的话题。保持垄断,直到强化学习被提出。
深度学习的应用领域广泛,文本、图像、音视频,只要能数据化的,没有NN处理不了的。(被戏称为万能逼近定理,炼丹工程师)
人脸识别,机器翻译,自动驾驶,AI换脸,你能听到的、能想到的黑科技,背后都有神经网络的支撑。
深度学习,这一概念正式提出于2006年,是Hinton(辛顿,神经网络之父)老爷子给出的定义:“多层神经网络及其相关学习方法”。

LeCun任职Facebook AI实验室时就说,如果把神经网络从Facebook中去掉,那Facebook将啥也不是。
在人工智能研究领域,Yann LeCun(法国绅士杨立昆)、Geoffrey Hinton (辛顿)和 Yoshua Bengio(本吉奥)一直被公认为深度学习三巨头(男子偶像天团,黑暗中最后的光)。

神经网络的发展历程
突然感觉花边新闻还不少。
目前公认的,神经网络的发展历程可以分为三个阶段:
- 20世纪40年代~60年代,初生
- 20世纪80年代~90年代,新生
- 2006年至今,黄袍加身

神经网络的初生
[1]我们用的神经网络实际上全称应该是人工神经网络,它并不是近年出现的新产品,而是一个名副其实的老古董。人工神经网络第一次出现是在20世纪50年代左右,准确的说是1943年,
1943年,神经科学家和控制论专家Warren McCulloch和逻辑学家Walter Pitts基于数学和阈值逻辑算法创造了一种神经网络计算模型。这个线性模型通过测试f(x,w)的值是正还是负,来识别两种类别的输入。从此之后,学界针对神经网络的研究正式分成了两部分,一是对大脑中生物过程的研究,二是将神经网络应用于人工智能的研究,即人工神经网络,(所谓的深度学习,依赖的框架,就是这个人工神经网络)[1]。
为叙述简便,以下将人工神经网络用神经网络代指
当时应该是叫做感知机,其实就是单层的人工神经网络
之后的几年里,到1969年之前,学界对这种新生的计算模型还是蛮有热情的,大家觉得这个东西很有发展潜力,陆陆续续有很多人围绕这个模型做了些研究,对人工神经网络的机制、计算思想等做了一些程度上的丰满。比如说

比较突出的贡献是,1957年,心理学家Frank Rosenblatt创造了模式识别算法感知机。
学界呈现一片父慈子孝欣欣向荣的景象。
直到1969年。
神经网络的第一次折戟
1969年,Marvin Minsky(马文,人工智能之父)和Seymour Papert(西蒙)发现了神经网络的两个重大缺陷:
第一个问题是,单层感知机无法处理异或问题(XOR问题)。感知机本质上是线性函数,所有的线性分类模型都无法处理异或问题,详情见后续“子问题拓展”小节,想要搞非线性分类(解决线性不可分问题)的话,必须要发展多层感知机。
那么第二个问题来了,当时世界的人,受限于多种原因,没有办法将多层感知机训练的足够好。比较突出的原因有两个,一是当时学界并没有发现一种能够应用于多层感知机上的有效算法。那么早期的单层感知机是怎么训练的?,二就是硬件限制了,当时的计算机的计算能力并不足以支撑复杂的神经网络。

自此,学术界的很多权威开始质疑神经网络,绝大部分研究人员都放弃了对神经网络的研究,神经网络的研究进入了寒冬。
神经网络的新生,Hinton携BP算法登上历史舞台
Hinton携BP算法登上历史舞台。
直到1986年,Rumelhart、Hinton和 Williams合著 Learning representations by backpropagating errors,正式提出使用反向传播(BP)算法来训练多层神经网络,再次唤起了学界对人工神经网络的研究热情。
这里需要提一句的是,作为破冰关键的BP算法,实际上在1974年就已经出现了。
1974年,Paul Werbos在自己的博士毕业论文中深刻分析了将反向传播算法运用于神经网络方面的可能性,但是遗憾的是,他并没有发表将BP算法应用于神经网络这方面的论文,大概是因为当时学界里的人已经失去了对这方面的兴趣,或者说信心。但好在不是所有人都这样,受此启发, LeCun Yann(他给自己取了个中文名杨立昆,深度学习三巨头之一)在Hinton实验室做博后期间,提出了BP应用于神经网络的雏形,并最终在1986年正式出现在世人眼前。
神经网络的发展迅速迎来第二春。
命途多舛,神经网络的第二次寒冬
然而好景不长。
20世纪90年代中期,由Vapnik(万普尼克, 战斗民族的骄傲,统计学习理论的创始人之一)等人发明的支持向量机诞生,它同样解决了线性不可分问题,在很多方面都强势碾压了刚复活没多久的多层神经网络,比如说,训练速度快、不需要大量调参、没有梯度消失等问题,泛化性能强、过拟合风险更小等,使得支持向量机一诞生,就迅速打败了自己的老前辈多层神经网络成为了学界的主流。后来甚至一度发展到,只要你的论文中包含了神经网络,那就非常容易被拒稿,学术界当时对神经网络的态度,已经不能拿嫌弃来形容了。神经网络的研究再次进入了寒冬。选择继续研究神经网络的学者寥寥无几,其中就包括了上面提到的Hinton老爷子。
长江后浪推前浪,浮事新人换旧人。
学界那帮男人的喜新厌旧,远超你的想象。
但好在我们有Hinton。
神经网络的重生,黄袍加身,一步封神
十年磨一剑,Hinton老爷子王者归来。
2006年,Hinton老爷子提出了“深度置信网络”,通过“预训练”+“微调”的优化方法,提高了神经网络的性能,且大大减少了训练时间。
但这都不是最重要的。
以后人的眼光来看,当时最重要的是,他为多层神经网络及相关学习方法赋予了一个新的名词:深度学习。
2012年,Hinton老爷子用LeCun赖以成名的卷积神经网络,和自己的深度置信调优技术,以极大的优势(超出第二名11%,第二名和第三名只差1%)赢下了当年的ImageNet竞赛,狠狠的碾压了其他一众机器学习算法。
至此,深度学习引爆了人们的研究热情,并一步一步成了人工智能的代名词,发展垄断至今。Hinton、LeCun等人被直接送上神坛,跟神经网络有关的一切东西都开始被追捧,最初那段时间,甚至演变成,跟深度学习不沾边的论文很难发表了。直到前几年,强化学习的兴起,这股风气才有所收敛。
不过学界还是有比较清醒的学者的,对于做了几十年冷板凳的神经网络,突然被捧上巅峰,也有很多相对理智学者对神经网络的未来表示了担忧,比如说LeCun,他一直都在呼吁学界对深度学习保持冷静。
神经网络的未来,众说纷纭
神经网络已经神化了,就像前几年的“互联网+”一样,无人不知无人不晓。
就像年轻那会儿出去做项目,我跟他说我改进了预处理的手段,我修改了优化器的细节,我降低了错误率多少多少,他是不在意的,但是你跟他讲我用了深度学习,他会对你肃然起敬。
但幸好学界还是有比较清醒的学者的,对于做了几十年冷板凳的神经网络,突然被捧上巅峰,也有很多理智学者对神经网络的未来表示了担忧,比如说LeCun,他一直都在呼吁学界对深度学习保持冷静。
不过LeCun这位法国绅士说话很直,他呼吁的方式简单来说就是泼凉水。
2018年的时候,LeCun在推特上说应该放弃深度学习,惊爆了世人的眼球。我不知道国外的媒体是怎么报道的,反正那段时间微信公众号给我推送的都是这种标题:
震惊,深度学习巨头竟直言放弃深度学习,是人性的扭曲还是道德的沦丧?
但实际上他的意思是换一个名词来解释深度学习的工作,即“可微分编程”,Lecun想告诉大家的是,人们对深度学习的期望太高了,终结者?天网?都不是,DL只是“将各种参数化的函数模块网络组装起来,做成新软件,同时以某种基于梯度的优化再将其训练出来”
这跟普通的编程工作没有区别。
其他时间点
其他一些同样比较重要的时间点,记录一下:


神经网络简介
跟所有的分类一样,神经网络可以将输入映射到输出,自动学习拟合x和y之间的函数关系f(x)=y。它会自己找到它觉得最好的一个映射f。需要提一句的是,这个f的具体形式你是不知道的,这也是神经网络不可解释性的一方面。它就是个黑盒。

一个简单的神经网络,输入层、隐藏层和输出层。
隐层可以有多个。
每一层的输出同时也是下一层的输入。每层由一个个神经元组成,每层中每个神经元是独立的。
神经元之间的连线,在生物学中叫做突触,而在数学模型中,这样的突触有一个加权数据,叫做权重。
以下是单个神经元的示意图:

每个神经元,或者说节点,将输入数据x与一组权重结合,通过(权重)来放大或者抑制输入,来指定其在模型中的重要性。
(w0又称偏置,以下用b(bias)表示)
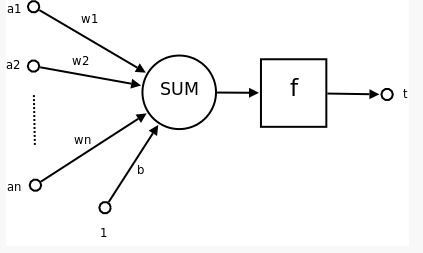
输入数据和权重的乘积之和将会进入神经元的激活函数,来判断信号是否继续向下传播,或者说来决定多少信号会继续向下传播,
- a 1 , a 2 , … , a n a_1,a_2, \dots, a_n a1,a2,…,an为输入向量的各个分量;
- w 1 , w 2 , … , w n w_1,w_2, \dots, w_n w1,w2,…,wn为神经元各个突触的权重值;
- b b b是偏置;
- f f f是神经元的激活函数(activation function), 通常是非线性函数;
- t t t是神经元的输出;
所以一个神经元的数学表示为: t = f ( W T ∗ A + b ) t=f(W^T*A+b) t=f(WT∗A+b)
- W W W为权值向量, W T W^T WT是它的转置;
- A A A是输入向量
- b b b是偏置
- f f f是activation function
可见, 一个神经元的作用是, 求得输入向量和权重向量的内积之后, 将其输入到激活函数, 得到一个标量结果作为神经元的输出;
激活函数的作用
激活函数在数学上的作用是,将(−∞,+∞)之间的数映射到指定区间之间,如(0,1)或者(-1, 1),前者如sigmoid、relu,后者如tanh。
为什么要使用激活函数?
这个说法其实并不严谨,严谨的说法应该是问,为什么要使用非线性激活函数?
答案是为了给神经网络引入非线性。
假设有一个神经网络,激活函数是恒等激活函数,即g(z)=z,那么

可以看到,不管是a1还是a2,都只是x的线性组合,所以不管多少层,效果都跟一层一样。所以我们需要非线性激活函数,来为神经网络的拟合引入无限可能。
以下是一些激活函数的曲线图

sigmoid,


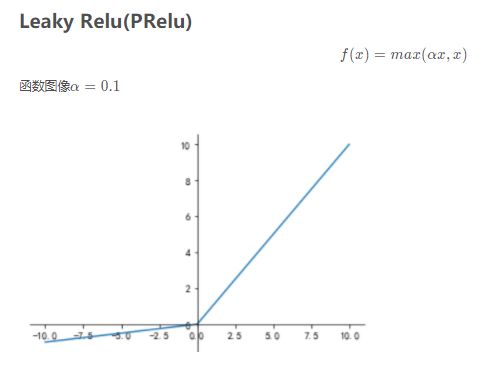
relu解决了梯度消失的问题,因为它导数是1.。。因为是分段函数,所以也算是非线性。但有的神经元可能永远不会被激活,因为左侧全是0.
针对这种情况,学界又提出两种PRelu和ELU,特别对左侧做了处理:


softmax,

可以看出来,softmax跟其他激活函数不一样,其他激活函数是神经元之间各自激活各自,而softmax是把所有神经元搞到一起做了个归一化,所以softmax往往被用于在最后的输出层,用来计算概率(加起来等于1)。
参考文献:
- 各种激活函数, 图像, 导数及其特点
偏置项的作用
很简单,为决策平面添加水平方向的偏移量,如果不加偏置的话,我们所有的分割线或者说决策平面都是经过原点的,但是现实问题并不会是经过原点线性可分的。


参考文献:神经网络中w,b参数的作用(为何需要偏置b的解释)
输出层
在分类问题中,输出层输出的是概率,比如说我有五个类别,那输出层就对应5个神经元,每个神经元表示一个概率,即输入样本是本类的概率。
输出层除了生成概率外,还有一个比较重要的作用是计算损失值。
损失函数的存在,有两个重要的目的,一是为了给神经网络一个优化的目标,就是损失函数最小化,最理想的情况就是,一个属于类别2的样本,其输出层第二个神经元输出的概率是1,其他神经元全是0.
第二个作用是为参数的更新提供参考,神经网络每次训练都会调整每个权重参数的值,那怎么调?每个参数调多少?都是由损失函数决定的,损失函数提供一个初始的梯度值,然后逆向回传梯度,每个参数的更新法则是:
w n e w = w o l d − l r ∗ 该参数对应的梯度 w_{new} = w_{old} - lr * 该参数对应的梯度 wnew=wold−lr∗该参数对应的梯度
RNN
RNN很适合用来做自然语言处理。


这块能说很久,有时间之后再补充。
在自然语言处理领域,之前是无法处理语序问题的,只能利用词频。而RNN的诞生使得利用语序成为可能。
为什么要关注语序呢,直观点讲,“你是我爹”和“我是你爹”所表示的语义是不一样的。
CNN
参考文献:一文简单介绍卷积神经网络(CNN)
垄断图像领域的卷积神经网络CNN,其中最重要的就是卷积层。
在CNN中的第一层卷积层,先选择一个局部区域(filter)去扫描整张图片,局部区域所圈起来的所有节点会和filter做乘法累加操作,再连接到下一层的一个节点上。假设要扫描的图片是一张灰度图片(也就是只有一个颜色通道),所有的filter也是个二维的矩阵,那个该卷积过程可以用如下动图表示。

那假如卷积层要扫描的图片是张彩色图片(也就是该图片有RGB三个通道),那么图片的像素可以表示成三维结构,所选用的filter也是个三维结构,如图所示:

那卷积过程就如图:

比较有意思的是,在这个过程中,你可以把生成的三维矩阵重新图片化,可以看到一个原图的一个边缘细节。之前有论文是这么展示的,用来形象展示CNN的每一层都在做什么,可惜我没存。
突然有点好奇,文本这样做会出来什么?比较难,毕竟语言模型的向量空间实际上是离散的。
TensorFlow游乐场
可视化游乐场 这个比较有意思
子问题拓展
神经网络的作用极大,LeCun任职Facebook ai实验室时就说,如果把神经网络从Facebook中去掉,那Facebook将啥也不是。
而且,真实的神经网络比上面介绍的麻烦的多,日常使用的时候,我们需要选择好权重初始化器,优化器,乱七八糟一堆。batch size的大小、学习率、dropout、标准化。每个稍不注意,都会对最终的结果产生很严重的影响。
什么是感知机
以下基于参考文献2
感知机(perceptron)是一种二元分类的线性分类模型,输入样本的特征向量,输出样本的类别。
感知机只有一个输出值,通过与阈值的对比来决定最终输出+1还是-1。
感知机引入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,进行训练,这个训练,实际上就是最优化求解的问题啦。
感知器的数学定义,直接贴图了:

用通俗的语言描述感知机的学习(训练)过程:
- 对感知机的权重w进行随机赋值;
- 对于训练集中一个样本的输入值x,计算其在感知机里的输出值f(x);
- 如果根据输出值得到的分类不对,则计算损失函数值,用损失函数来调整权重;
- 继续输入下一个样本,重复步骤2,3
- 重复步骤4,一直到感知机不再出错。
单层感知机为什么无法处理异或问题
单层感知机实际上就是一种线性模型,线性模型都无法处理异或问题,
那什么是异或问题?

右图坐标系红色表示一类,蓝色表示一类,我们需要知道找到一个超平面把这两个类别分开,明显可见的是,我们没法找到一条直线能完成这个工作。
以上参考文献:感知机不能表示“异或”
关于逻辑回归是线性还是非线性,似乎是个好问题,逻辑回归本身的f(x)是线性的,加上g(x)的sigmoid之后是非线性的。
判断一个模型是线性还是非线性,这个似乎是个众说纷纭的故事,
有文献提过,区分是否为线性模型,主要是看一个乘法式子中自变量x前的系数w,如果自变量只被一个参数影响,那么此模型为线性模型。机器学习中线性模型和非线性的区别
当然最直观的还是看决策平面是否直线。
还有一种说法,源于,机器学习中的线性和非线性判断 ,
上面讲线性的定义是:F(ax+y) = aF(x) + F(y),其中x和y是变量而a是常数。卷积满足这个定义,所以是线性操作,而非线性的操作有:
- x n x^n xn,n不为1
- ∣ x ∣ |x| ∣x∣,即变量在绝对值中
- sgn(x),指出x的正负号,x大于0则返回1,小于0则返回-1,等于0返回0;
早期的单层感知机是怎么训练的,为什么这种训练的方式无法迁移到多层感知机上?
神经元的学习机制是基于将错误最小化的微积分
八卦新闻之人工神经网络与支持向量机之争
参考文献3
1989年,LeCun提出了卷积神经网络,在图像领域取得了不错的效果,上世纪90年代末期已经处理了美国10%-20%支票数字识别。但是因为神经网络本身的不可解释性,CNN也受到了不少的质疑。比如说支持向量机之父,数学家Vladinmir Vapnik,之后神经网络进入二次寒冬,就是他干的。
1995年3月的一个下午,Vapnik和Larry Jackel(把LeCun招进贝尔实验室的人)打了一个赌。Jackel认为到2000年,我们能够明确了解人工神经网络能够发挥多大作用。Vapnik不同意这个观点,他认为就算到2005年,也没有人能够理解如何使用神经网络,与1995年的状况相差无几。他们的赌注是一顿奢华的晚餐,双方在证人面前签字画押,而LeCun则是第三方签名人,Bottou是非官方见证人。
现在来看,Vapnik(之后称为阿V)赢了一半,因为直到现在,研究人员也没有完整的搞明白神经网络内部的工作原理,虽然时不时就有几篇相关论文发表,但是似乎并没有什么明显的反响。个人感觉这方面的研究最突出的贡献就是给这种现象总结了个术语,就是神经网络的不可解释性。但是Larry也赢了一半,因为神经网络到目前仍然活跃在人工智能的一线上。
据说,2000年,两人在享用完一顿奢侈晚餐后,平分了账单。
这就是著名的贝尔实验室学术豪赌
LeCun大神简述
参考文献4
1988年,年仅27岁的法国绅士LeCun走进了贝尔实验室,接触到了大量数据集和运行飞快的电脑,一个拥有5000个训练样本的USPS数据集——在当时算是数一数二的庞大数据集了。
Yann LeCun,CNN之父,纽约大学终身教授,与Geoffrey Hinton、Yoshua Bengio并成为“深度学习三巨头”
参考文献5
LeCun比较真性情,说话很直,18年推特上说应该放弃深度学习,被媒体过度解读,实际上他的意思是换一个名词来解释深度学习的工作,即“可微分编程”,Lecun想告诉大家的是,人们对深度学习的期望太高了,终结者?天网?都不是,DL只是“将各种参数化的函数模块网络组装起来,做成新软件,同时以某种基于梯度的优化再将其训练出来”
他跟普通的编程工作并没有区别。
18年有个比较火的全球第一个机器人公民,号称人类末日的苏菲娅,LeCun直接在推特上开骂“招摇撞骗,脑子里全是屎”
参考文献
- 神经网络的历史?
- 什么是感知机? 对原理讲的特别好,深浅适中且清晰
- 研究人工智能三十年,Facebook AI 负责人Yann LeCun到底有多牛?
- 【AI大咖】再认识Yann LeCun,一个可能是拥有最多中文名的男人
- 怼完Sophia怼深度学习!细数完大神Yann LeCun 这些年怼过的N件事,原来顶级高手是这样怼人的…