opencv 基于haar特征的级联分类器实现图象识别原理
暑假的时候做了一个智能机械臂,用到了opencv里的级联分类器,这里写一下我的理解
级联分类器上手简单,同时Haar特征支持一些特殊图形的检测,例如人脸,我训练的是一个纯色模型,效果并不好,不建议用该种方法识别一些颜色梯度变化不明显的物体
(1)haar特征

图片展示了最基本的几类haar特征,每种其实都有相应的变式,图中黑:白等于1:1,

这种也是一种haar特征。
每个haar特征都对应一个特征值,相当于对图像以某点展开一个矩形对图像进行卷积操作(haar特征中的黑只是表达与白相反体现的是一种色差变化)
对于一个haar特征 j 求其特征值的操作为
f(j)= 白色像素和 *白色像素权重 - 黑色像素和 * 黑色像素权重
因为一个haar 特征里黑色像素与白色像素数量不一定相等所以要成一个权重
,再次说明一下黑色像素在原图中不一定为黑,而在这个点上的特征值让他表现为黑色一方而已
求特征值的操作类似与一个卷积操作。
特征值产生的数据非常巨大,opencv里介绍了一种一种归一化操作

这里是我引用资料上的不多叙述,是为了让数据小一些
(2)积分图

如图对于一个图片其haar特征数量是巨大的,仅左上角一个点都可以产生大量haar特征计算矩阵(可放缩)
满足(s, t)条件的矩形称为条件矩形:
(1) x 方向边长必须能被自然数 s 整除(能均等分成 s 段)
(2) y 方向边长必须能被自然数 t 整除(能均等分成 t 段)
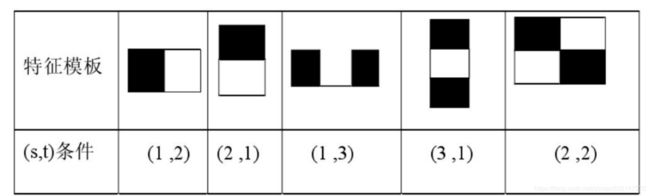

这个很好理解将左边的【m/s】.....依次乘右边的引子相当于不同的haar特征表示
一个24*24图像仅最简单的特征模板,特征值数量为 (24+23+22+...+1)*(12+11+...+1)=43200
如果每次都一个一个的取像素进行计算,计算量非常巨大,
积分图是一种将这种计算简化的方法
积分图的定义为:将一个点左上角的像素相加取代该像素
f(x,y)=i(x,y)+ f(x-1,y)+f(x,y-1)-f(x-1,y-1)

i 为原图
因为 f(x-1,y)+f(x,y-1)对左上角所有像素累加了两遍,所以要减一个f(x-1,y-1)
积分图是如何简化计算的呢
比如一个haar特征
其特征值等于矩阵右侧所有像素减左侧像素

那么一个特征矩阵内的像素信息 可有矩阵端点积分图获得,对于一个图片计算一次积分图可以避免大量重复运算
以上是级联分类器的识别基础,下面是级联分类器是如何构建的
opencv采用了AdaBoost学习算法 ,整个级联分类器是一个决策树结构
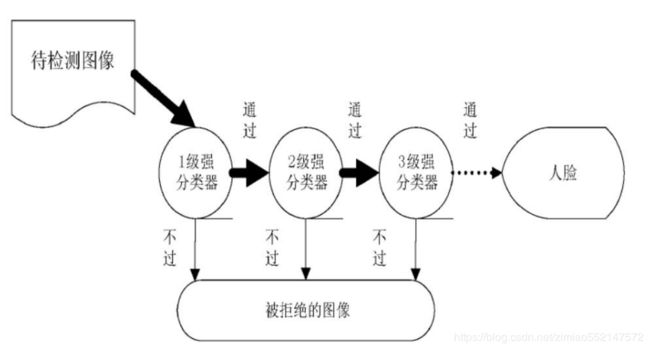
对于强分类器,我找到了两种说法
(1)强分类器是若干个弱分类器的线性组合
(2)强分类器有多个并联的弱分类器组成
这两种说法本质一样
(3.1)弱分类器
h(x,f,p,q)={1 ( p *f(x) < p *q) ,0(otherwise)}
这是一个弱分类器的组成
x为待检测图像,f为一特定haar特征,p 让不等号方向保持一致 ,q为阈值
这里说一下我的理解,有的特征是大于阈值判断为是检测物体,有的则要小于,p分两种情况取正负一
阈值的获取:
对于一特定haar特征,将所有样本的特征值按大小排列
设某特征值 f(j) ,
其前面的特征值中 正样本的比例记为S +
其前面的特征值中 负样本的比例记为S -
所有训练样本中正样本的比例记为T+
负样本的比例记为T-
分类误差r=min{(S+) +(T- )-(S-) ,(S-)+(T+)-(S+)}
遍历所有特征值找到当前haar特征下分类误差最小的特征值作为阈值p
一个图片的haar特征非常多,而一个弱分类器的训练就是找的一个haar特征,他的分类误差小,用这个特征能够区分出人脸or非人脸,在为多个haar特征找阈值的同时,选择分类误差最小的haar特征作为弱分类器
(4.1--对应3.1弱分类器的强分类器)


就是在循环过程中改变不同弱分类器权重,让多个弱分类器投票表决,最终形成一个强分类器
(3.2弱分类器其二)
h(x,f,p,q)={1 ( p *f(x) < p *q) ,0(otherwise)}
这个定义是一样的和3.1,不一样的是多了 leftvalue 和rightvalue,阈值的选取方法也不同

训练完一个弱分类器后更新权重

对numPos+numNeg个权重按照如下公式更新权重(注意更新后需要对权重进行归一化)

(4.2--对应3.2的强分类器)
一个强分类器的结构如图
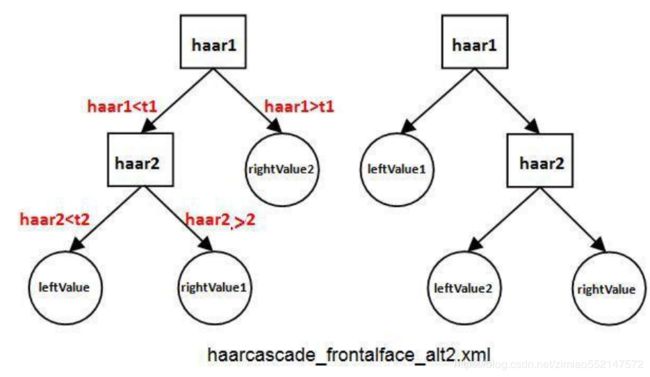
以左图为例,第一个弱分类器判断阈值,小于则向下进行,大于输出该级的rightvalue
在检测目标时, 每个弱分类器独立运行并输出cascadeLeaves[leafOfs - idx]值,然后把当前强分类器中每一个弱
分类器的输出值相加 ,即:
sum += cascadeLeaves[leafOfs - idx]
之后与本级强分类器的stageThreshold阈值对 比, 当且仅当结果sum>stageThreshold时,认
为当前检测窗口通过了该级强分类器 。当前检测 窗口通过所有强分类器时,才被认为是一个检测
目标。 可以看出, 强分类器与弱分类器结构不同,是一 种类似于“并联”的结构,称其为“并联组成的 强分类器”。
强分类器阈值计算
与4.1一样是一个循环过程
1,使用当前的stage中已经训练好的弱分类器去检测样本中的每一正样本,计算弱分类器输出值之和保存在eval中。
2,对eval升序排序
3,以eval[thresholdIdx]作为stage阈值stageThreshold,显然正样本越多估计的stageThreshold越准确。
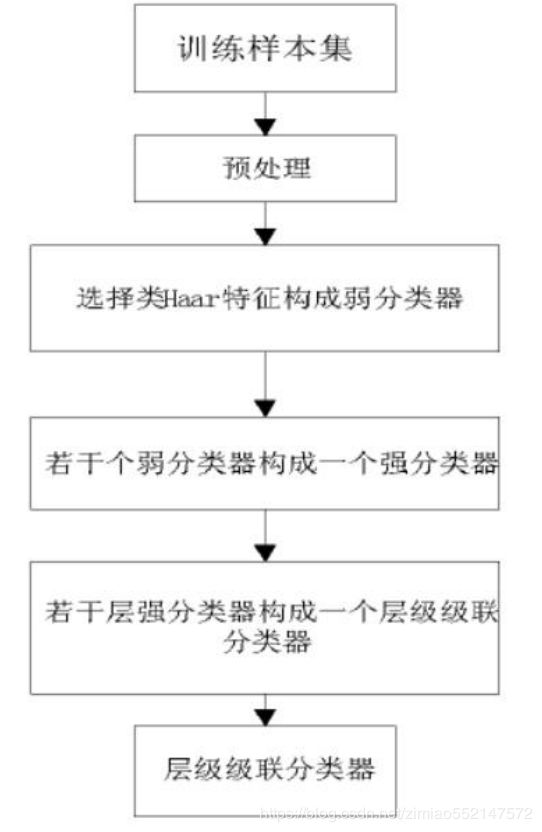
整个过程:
1,寻找正负样本作为训练样本
2,计算每个Haar特征在当前权重下的阈值+leftvalue+rightvalue,组成了一个个弱分类器
3,通过WSE寻找最优的弱分类器(看不懂就是找错误率最小的若分类器)
4,更新权重(在下一个若分类器训练过程加重对上一个弱分类器判断错误的权重)
5,按照minHitRate估计stageThreshold
(-minhitrate每个阶段分类器需要的最小的命中率,总的命中率为min_hit_rate的number_of_stages次方)
6,重复上述1-5步骤,直到falseAlarmRate到达要求,或弱分类器数量足够。 停止循环,输出stage。
7,进入下一个stage训练
虽然是整理的,希望对你有帮助
原文1:(7条消息) Adaboost 人脸检测:Haar特征及积分图、分类器的级联_あずにゃん的博客-CSDN博客_adaboost图像分类 原文2:第九节、人脸检测之Haar分类器 - 大奥特曼打小怪兽 - 博客园 (cnblogs.com)