【数据挖掘】时间序列教程【九】
第5章 状态空间模型和卡尔曼滤波
状态空间模型通常试图描述具有两个特征的现象
-
有一个底层系统具有时变的动态关系,因此系统在时间上的“状态”t 与系统在时间的状态t−1有关 .如果我们知道系统在时间上的状态t−1 ,那么我们就有了我们需要知道的一切,以便对当时的状态进行推断或预测t .
-
我们无法观察到系统的真实底层状态,而是观察它的嘈杂版本。
这两个特征导致我们指定状态方程,它描述了系统如何从一个时间点演变到下一个时间点,以及观察方程,它描述了底层状态如何转换(添加噪声)为我们直接测量的东西。
假设有一个初始状态![]() .为t=1,2,... 我们希望能够估计后续状态
.为t=1,2,... 我们希望能够估计后续状态![]() 在每个时间点,我们都会观察到一些数据
在每个时间点,我们都会观察到一些数据 我们希望将这些数据纳入我们的估计中
我们希望将这些数据纳入我们的估计中 .
.
在最简单的情况下,我们可以提出一个观察方程
![]()
这里![]() 和状态方程
和状态方程
![]()
这里![]() .参数θ τ 和σ 假设是已知的(您可以将它们视为调整参数),并且我们希望生成一个估计值 对于所有人t 感兴趣。回想一下,我们唯一观察到的是序列
.参数θ τ 和σ 假设是已知的(您可以将它们视为调整参数),并且我们希望生成一个估计值 对于所有人t 感兴趣。回想一下,我们唯一观察到的是序列![]()
状态空间模型可能最有意义的设置是动态设置,在该设置中,我们尝试估计状态值在“实时”中,不知道未来会发生什么。例如,在航天器的制导和导航应用中,我们想知道航天器在太空中行驶时的位置和速度,同时考虑到牛顿运动定律。根据我们对航天器位置和速度的估计,我们需要决定下一步该做什么。这种情况要求我们整合所有可用的信息,以产生最佳的估计。
5.1 示例:一个简单的航天器
假设我们乘坐宇宙飞船前往月球,我们刚刚点燃完引擎,让我们继续前进。当我们在太空中“航行”时,我们想知道我们离地球有多远,我们会定期看到恒星以估计我们的位置。
我们的“状态” 是我们的航天器与地球的径向距离。除非有任何加速度,如果航天器在时间![]() 的位置是
的位置是![]() ,其速度是
,其速度是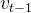 ,那么牛顿定律告诉我们它在时间 t 的位置是
,那么牛顿定律告诉我们它在时间 t 的位置是
![]()
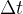 是时间点之间经过的时间间隙,
是时间点之间经过的时间间隙,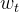 表示一些噪声或轻微扰动(例如
表示一些噪声或轻微扰动(例如![]() 。在某些情况下,我们可能会假设
。在某些情况下,我们可能会假设![]() 。因此,这里的状态方程体现了“运动中的物体保持运动”的想法。
。因此,这里的状态方程体现了“运动中的物体保持运动”的想法。
我们可以写这个方程,稍微不同,使用向量和矩阵作为
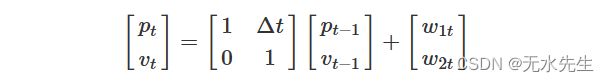
如果实际上没有加速度,我们知道速度不会随时间\(t-1\)到时间\(t\)而变化(也许除了一些轻微的扰动)。如果我们让
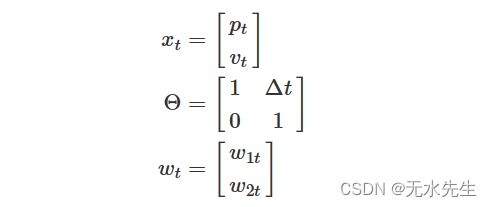
那么我们的状态方程就是
![]()
在这一点上,我们还没有讨论数据,但是如果没有对系统的任何观察,我们将不得不假设系统根据状态方程演变。因此,如果我们知道初始状态 ,我们对后续状态的最佳猜测将是
,我们对后续状态的最佳猜测将是
![]()
等等。这些与其说是“估计”(因为没有数据),不如说是基于我们对系统潜在动态的了解,对下一个状态应该是什么的预测。
那么问题是,如果我们在时间\ 观察数据 ,我们应该怎么做?我们期望在时间 t 观察到什么?第二个问题可能是我们需要多久进行一次测量才能很好地估计我们的状态?
观察数据 ,我们应该怎么做?我们期望在时间 t 观察到什么?第二个问题可能是我们需要多久进行一次测量才能很好地估计我们的状态?
现在假设我们偶尔通过在航天器上进行的测量来观察我们的位置,并且在时间 我们观察到我们的位置 ,即
![]()
所以 是我们真实位置的噪声测量(i.e ![]() )。我们同样可以使用我们的状态向量将其完整形式编写为
)。我们同样可以使用我们的状态向量将其完整形式编写为
![y_ t = [ 1 \; \; \; 0 ] x_ t + v _t](http://img.e-com-net.com/image/info8/018aeb37c3254ef896a1fcfa0ada5b0c.png)
如果我们让
![]()
然后我们有 ,我们的观察方程。一旦我们观察\ ,我们对 的知识会如何变化?答案由卡尔曼滤波器给出。
,我们的观察方程。一旦我们观察\ ,我们对 的知识会如何变化?答案由卡尔曼滤波器给出。
5.2 卡尔曼滤波
有趣的事实:卡尔曼滤波器是由鲁道夫·卡尔曼在马里兰州巴尔的摩高等研究所工作时开发的。
为了介绍卡尔曼滤波器,让我们采用一个简单的模型,有时称为“局部水平”模型,其状态方程为
![]()
和观察方程
![]()
其中我们假设![]() 和
和 ![]() 。基本的一维卡尔曼滤波算法如下。我们从初始状态
。基本的一维卡尔曼滤波算法如下。我们从初始状态 和初始方差
和初始方差 开始。从这里我们计算
开始。从这里我们计算
![]()
作为我们对 和
和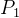 的最佳猜测,给定我们当前状态。鉴于我们的新观察结果
的最佳猜测,给定我们当前状态。鉴于我们的新观察结果![]() ,我们可以根据这个新信息更新我们的猜测,得到
,我们可以根据这个新信息更新我们的猜测,得到
![]()
这里:![]()
对于一般情况,我们希望生成一个新的估计值 ,并且我们有当前状态![]() 和方差
和方差![]() 。
。
![]()
鉴于新的信息 ,然后我们可以更新我们的估计以获
![]()
这里:
![]()
是卡尔曼增益系数。 如果我们看一下卡尔曼增益的公式,很明显,如果测量噪声很高,那么 σ 2 很大,那么卡尔曼增益会更接近 0 ,以及新数据点的影响 y t 会很小。如果 σ 2 很小,那么过滤后的值 ![]() 将会朝着以下方向进行更多调整 。在针对特定应用调整卡尔曼滤波算法时,记住这一点很重要。总体思路是
将会朝着以下方向进行更多调整 。在针对特定应用调整卡尔曼滤波算法时,记住这一点很重要。总体思路是

5.3 推导一维情况
有多种方法可以驱动卡尔曼滤波方程,但对于统计学家来说,最简单的方法可能是用正态分布来考虑一切。请记住,我们通常不会相信数据是按正态分布的,但我们可以将正态分布视为一种工作模型。我们将继续使用上面描述的局部模型
![]()
这里: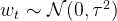 和
和![]()
让我们从 t = 1 我们将观察的地方![]() 。假设我们有初始状态
。假设我们有初始状态 ![]() 。首先,我们想要得到边际分布
。首先,我们想要得到边际分布 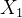 , IE。
, IE。 ![]() 。因为没有
。因为没有![]() 我们还不能以任何观察到的信息为条件。我们可以计算
我们还不能以任何观察到的信息为条件。我们可以计算 ![]() 作为
作为
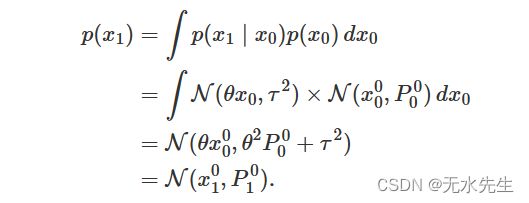
请注意,我们已经定义了 ![]() ;
; ![]() 。我们可以想到
。我们可以想到 ![]() 这是我们根据我们对系统的了解而不是任何数据可以做出的最佳预测。 鉴于新的观察
这是我们根据我们对系统的了解而不是任何数据可以做出的最佳预测。 鉴于新的观察![]() 我们想用这些信息来估计 。为此我们需要条件分布
我们想用这些信息来估计 。为此我们需要条件分布 ![]() ,称为过滤密度。我们可以用贝叶斯法则来解决这个问题:
,称为过滤密度。我们可以用贝叶斯法则来解决这个问题:
![]()
从观测方程我们知道 ![]() 我们刚刚计算了
我们刚刚计算了![]() 在上面。因此,利用正态分布的基本属性,我们有
在上面。因此,利用正态分布的基本属性,我们有

这里:
![]()
是卡尔曼增益系数。那么对于 t = 1 我们有了新的估计
![]()
和
![]()
所以过滤密度为![]()
现在让我们迭代一下这个过程 t = 2 我们现在将有一个新的观察结果 ![]() 。我们想要计算新的过滤器密度
。我们想要计算新的过滤器密度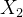
![]()
上面的陈述隐含的是 ![]() 不依赖于
不依赖于 ![]() 以价值为条件 。新的过滤密度
以价值为条件 。新的过滤密度![]() 是观测数据历史的函数,是观测密度的乘积
是观测数据历史的函数,是观测密度的乘积 ![]() 和预测密度
和预测密度![]() 。 在这种情况下,观测密度就是
。 在这种情况下,观测密度就是![]() 。预测密度可以通过增加
。预测密度可以通过增加 ![]() 与之前的状态值
与之前的状态值
![]()
在积分内部,我们有状态方程密度和滤波器密度的乘积![]() ,我们刚刚计算出
,我们刚刚计算出 ![]() 。状态方程密度为
。状态方程密度为 ![]() 过滤密度为
过滤密度为![]() 。将这些积分出来,我们得到
。将这些积分出来,我们得到
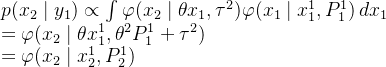
将我们刚刚计算的预测密度与观测密度相结合,我们得到
![]()
这里:
![]()
是新的卡尔曼增益系数。如果我们定义![]() 和
和 ![]() 那么我们就有了
那么我们就有了![]() 。 我们怎么办
。 我们怎么办![]() 只是为了好玩?给出一个新的观察结果
只是为了好玩?给出一个新的观察结果![]() ,我们想要新的过滤器密度
,我们想要新的过滤器密度
![]()
使用与之前相同的想法,我们知道观察密度![]() 预测密度为
预测密度为
现在新的过滤器密度是

此处:![]()
总结一下,对于每个 t = 1 , 2 , 3 , …… 的估计 X t 是过滤密度的平均值 ![]() 过滤密度是观测密度和预测密度的乘积,即
过滤密度是观测密度和预测密度的乘积,即
![]()
卡尔曼滤波算法的好处是我们递归地计算每个估计,因此不需要“保存”先前迭代的信息。每次迭代都内置了先前迭代的所有信息。