机器学习——KNN算法实战—手写数字识别
原理简述:KNN算法是机器学习中的一种基础的分类回归算法,选择距离自己最近的几条数据,依据最邻近的数据性质来估测自身的性质。
下面我们开始实战,制作手写数字识别模型:
一、cv2创建模型
1、导入相关的库,这里我们用numpy和cv2两个库
import numpy as np
import cv2
2、导入数据,并转化灰度图像
img = cv2.imread('digits.png')
gray =cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #转换为灰度图3、将图像划分,通过循环遍历,形成一个多维的矩阵
#将原始图像划分为独立数字,每个图像数字为20*20,共计5000个
cells=[np.hsplit(row,100) for row in np.vsplit(gray,50)] #遍历按行划分为50行,每行划分100列
#装进array,形状(50,100,20,20),50行,100列,每个图像20*20大小
x=np.array(cells)4、划分一半的数字为训练集,另一半为测试集
train = x[ : , :50] #划分训练集和测试集
test = x[:,50:100]5、更改数字输入尺寸,让其符合KNN算法的输入方式
#将数据构造为符合KNN的输入,将每个数字的尺寸由20*20调整为1*400(一行400个像素)
train_new=train.reshape(-1,400).astype(np.float32) #size=(2500,400)
test_new=test.reshape(-1,400).astype(np.float32) #size=(2500,400)6、给训练集和数据集分配标签
#分配标签:分别为训练数据、测试数据分配标签(图像对应实际值)
k=np.arange(10)
labels=np.repeat(k,250) #重复数组中的元素,每个元素重复250次
train_labels=labels[:,np.newaxis] #np.newaxis用于在数组中增加一个新维度
test_labels=np.repeat(k,250)[:,np.newaxis]7、构建模型并训练
#模型的构建与训练,sklearn knn ,opencv里也有knn
knn=cv2.ml.KNearest_create() #通过cv2创建一个knn模型
knn.train(train_new,cv2.ml.ROW_SAMPLE,train_labels) #cv2.ml.ROW_SAMPLE表示横向获取一条数据
ret,result,neighbours,dist=knn.findNearest(test_new,k=4)
#ret: 表示查找操作是否成功
#result:浮点数数组,表示测试样本的预测标签
#neighbours:整数数组,表示测试样本最近的k个邻居的索引
#dist:浮点数数组,表示测试样本与每个最近的邻居之间的距离
8、以测试集检验正确率
#通过测试集校验准确率
matches=result==test_labels
correct=np.count_nonzero((matches))
accuracy=correct*100.0/result.size
print(f'当前使用KNN识别手写数字的准确率为{accuracy}%')运行结果如下:
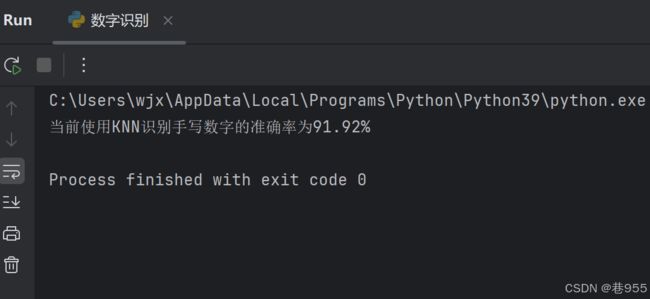
完整代码如下:
import numpy as np
import cv2
img = cv2.imread('digits.png')
gray =cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #转换为灰度图
#将原始图像划分为独立数字,每个图像数字为20*20,共计5000个
cells=[np.hsplit(row,100) for row in np.vsplit(gray,50)] #遍历按行划分为50行,每行划分100列
#装进array,形状(50,100,20,20),50行,100列,每个图像20*20大小
x=np.array(cells)
train = x[ : , :50] #划分训练集和测试集
test = x[:,50:100]
#将数据构造为符合KNN的输入,将每个数字的尺寸由20*20调整为1*400(一行400个像素)
train_new=train.reshape(-1,400).astype(np.float32) #size=(2500,400)
test_new=test.reshape(-1,400).astype(np.float32) #size=(2500,400)
#分配标签:分别为训练数据、测试数据分配标签(图像对应实际值)
k=np.arange(10)
labels=np.repeat(k,250) #重复数组中的元素,每个元素重复250次
train_labels=labels[:,np.newaxis] #np.newaxis用于在数组中增加一个新维度
test_labels=np.repeat(k,250)[:,np.newaxis]
#模型的构建与训练,sklearn knn ,opencv里也有knn
knn=cv2.ml.KNearest_create() #通过cv2创建一个knn模型
knn.train(train_new,cv2.ml.ROW_SAMPLE,train_labels) #cv2.ml.ROW_SAMPLE表示横向获取一条数据
ret,result,neighbours,dist=knn.findNearest(test_new,k=4)
#ret: 表示查找操作是否成功
#result:浮点数数组,表示测试样本的预测标签
#neighbours:整数数组,表示测试样本最近的k个邻居的索引
#dist:浮点数数组,表示测试样本与每个最近的邻居之间的距离
#通过测试集校验准确率
matches=result==test_labels
correct=np.count_nonzero((matches))
accuracy=correct*100.0/result.size
print(f'当前使用KNN识别手写数字的准确率为{accuracy}%')以上代码基于cv2自带的sklearn 函数,下面我们用sklearn库实现
二、sklearn 库创建模型
1、首先依旧是导入相关的库,在sklearn.neighbors中声明KNeighborsClassifier类
import numpy as np
import cv2
from sklearn.neighbors import KNeighborsClassifier
2、数据转化部分的代码大体相同,如下:
考虑到KNeighborsClassifier模型接收一维数据,所以不用将标签升维
img = cv2.imread('digits.png')
gray =cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cells=[np.hsplit(row,100) for row in np.vsplit(gray,50)]
x=np.array(cells)
train = x[ : , :50]
test = x[:,50:100]
train_new=train.reshape(-1,400).astype(np.float32)
test_new=test.reshape(-1,400).astype(np.float32)
k=np.arange(10)
labels=np.repeat(k,250)3、创建x,y两个坐标轴,建立模型并测试
x=train_new
y=labels
neigh=KNeighborsClassifier(n_neighbors=6) # 创建模型对象
neigh.fit(x,y) # fit训练模型4、加入测试集的数据,并检验精确度
predict_data =test_new
# print(neigh.predict(predict_data))
result=neigh.predict(predict_data)
correct=np.count_nonzero((result))
accuracy=correct*100.0/result.size
print(f'当前使用KNN识别手写数字的准确率为{accuracy}%')运行结果如下:
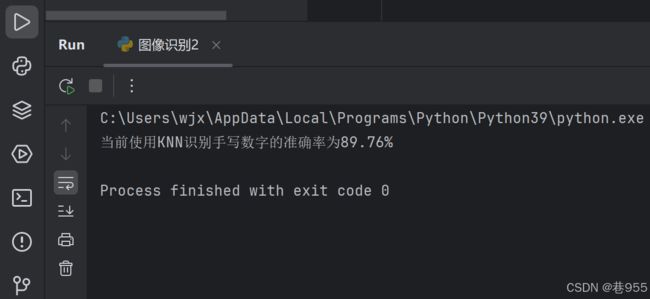
完整代码如下:
import numpy as np
import cv2
from sklearn.neighbors import KNeighborsClassifier
img = cv2.imread('digits.png')
gray =cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
cells=[np.hsplit(row,100) for row in np.vsplit(gray,50)]
x=np.array(cells)
train = x[ : , :50]
test = x[:,50:100]
train_new=train.reshape(-1,400).astype(np.float32)
test_new=test.reshape(-1,400).astype(np.float32)
k=np.arange(10)
labels=np.repeat(k,250)
x=train_new
y=labels
neigh=KNeighborsClassifier(n_neighbors=6) # 创建模型对象
neigh.fit(x,y) # fit训练模型
predict_data =test_new
# print(neigh.predict(predict_data))
result=neigh.predict(predict_data)
correct=np.count_nonzero((result))
accuracy=correct*100.0/result.size
print(f'当前使用KNN识别手写数字的准确率为{accuracy}%')注:以上内容仅代表个人观点,若有错误,欢迎指正