Python 正则表达式
本文章为视频 Python编程:正则表达式_哔哩哔哩_bilibili 的笔记
正则表达式多用于文本处理与提取信息,相对于python内置字符串的处理,正则的代码量更少,python做正则的库是re,我们大多数情况这样写就行了,比如我们想提取下面这个文字中的所有数字

- 加入r的原因是,不对字符串进行其他的加工,比如转义字符,是斜杠就是斜杠,不对其进行加工
其他的都好理解,关键在于re.compile中的内容,我们成r' '中的内容为正则表达式
正则表达式测试网站 regex101: build, test, and debug regex
使用方式就按下面这样使用就可以了
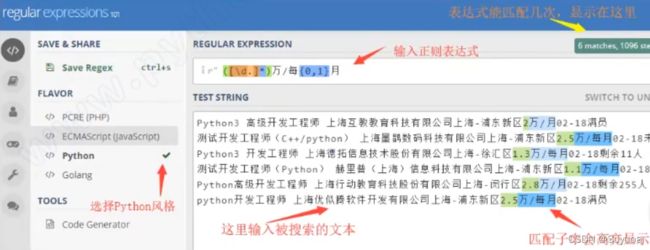
正则表达式本质上也是一种字符串,下面我们看一下正则表达式的常见使用方式
在不同语言中正则表达式会有区别,但符号与用法基本相似
目录
1 普通字符
2 元字符
2.1 点 .
2.2 星号 *
2.3 加号 +
2.4 问号 ?
2.4.1 匹配字符用
2.4.2 贪婪模式与非贪婪模式
2.5 尖号 ^
2.5.1 取反
2.5.2 当作起始位置
2.6 美元号 $
3 括号
3.1 花括号 {}
3.2 方括号 []
3.3 小括号 ()
4 反斜杠 \
4.1 元字符的转译
4.2 数字字符 \d
4.3 非数字字符 \D
4.4 空白字符 \s
4.5 非空白字符 \S
4.6 文字字符 \w
4.7 非文字字符 \W
5 其余方法
5.1 re.split()
5.2 re.sub()
5.3 re.compile的第二个参数
5.3.1 re.ASCII与re.A
5.3.2 re.DOTALL与re.S
5.3.3 re.IGNORECASE与re.I
5.3.4 re.MULTLINE与re.M
5.3.5 re.VERBOSE与re.X
1 普通字符
在正则表达式中直接输入指定的普通字符,比如

2 元字符
2.1 点 .
点 表示匹配除了换行符之外任何的单个字符
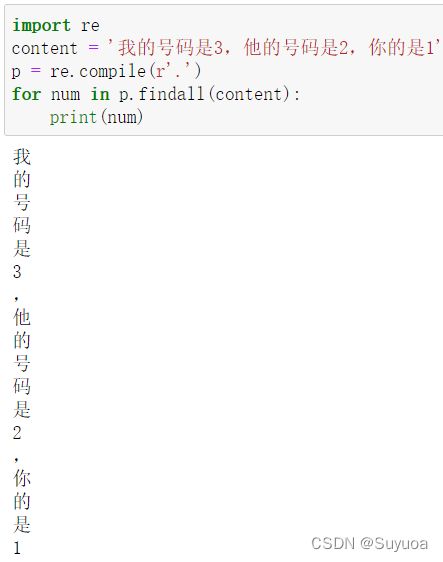
那么我们就可以结合普通提取出来这三句话中 '的' 前面的字符(含字符'的')

2.2 星号 *
星号 表示匹配前面表达式任意次(包括0次)
比如我现在想获取 第一个 '的' 后面的全部内容

这里的星号是对点的形容,点是任意字符,星号是任意次数,也就是说在这里把'的'后面的所有任意字符找出来
我们再看下面这个例子
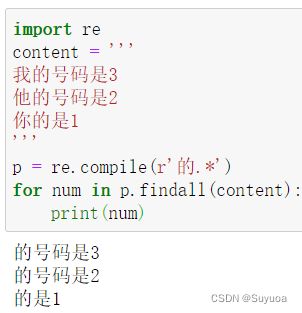
当我的字符并不只有一行的时候,他会多行进行寻找,与上面例子的区别是有无换行(符)
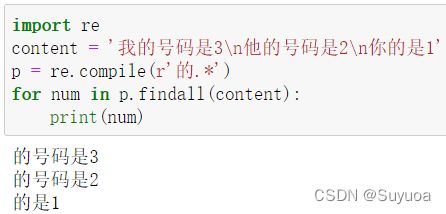
星号也可以当作0次来使用

如果没有星号,最后一行就没有了
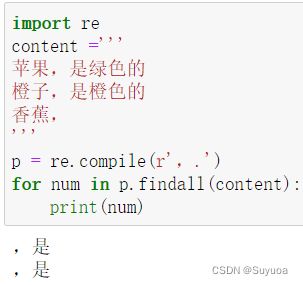
星号也可以搭配别的字符

2.3 加号 +
加号匹配前面字符一次或多次,不包括0次,跟星号的区别就是不包括0次

2.4 问号 ?
2.4.1 匹配字符用
问号匹配前面字符0次或1次
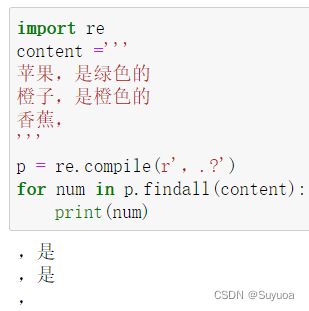
2.4.2 贪婪模式与非贪婪模式
贪婪模式会得到尽可能多的字符,非贪婪模式会得到尽可能少的字符
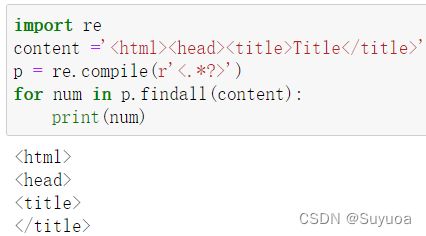
贪婪模式这样写

非贪婪模式这样写,在星号,加号,问号后面加一个问号
2.5 尖号 ^
他的中文名字可能是这个,在这里我形象的称其为尖号
第一次看可以看完括号的讲解再看这个
2.5.1 取反
在方括号内加一个^表示对方括号内的所有条件取反

2.5.2 当作起始位置
如果不加尖号,我们发现有两个匹配项

现在我们加上尖号,尖号表示起始位置

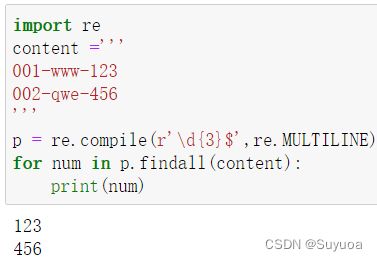
在单行字符中起始位置有多个,在多行字符中起始位置有多个,启用多行模式我们需要加入re.M或re.MULTILINE

2.6 美元号 $
美元号可以表示文本的结束位置,美元号也有单行与多行的区分
3 括号
3.1 花括号 {}
花括号匹配指定次数,比如我想提取出 出现 '色' 的次数至少3次,至多5次的文字

如果要看是什么颜色的话就前面加个点

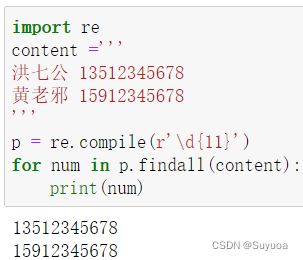
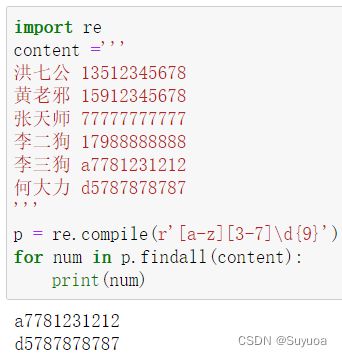
我们可以配合最开始提到的数字字符,提取出手机号码这一类的信息
- 手机号码一共11位
3.2 方括号 []
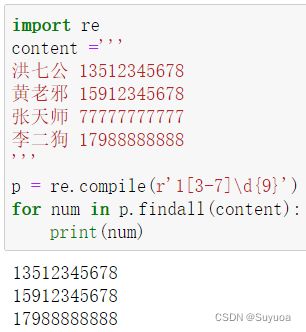
方括号代表选择,比如我们现在拿到了多个手机号,我只想要13和15开头的,我应该这样写

[35]表示1后面只要跟3或者跟5的,其余不要
中括号内也可以写范围,比如我定义范围在3到7之间
除了选择数字也可以选择字母或者其他字符
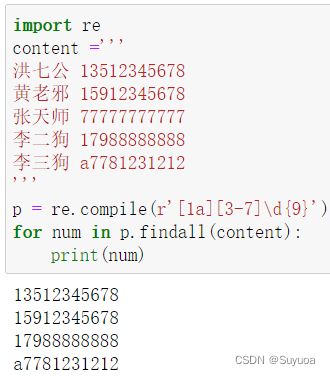
字母也可以设置范围
- 元字符在方括号中会失去特殊用法
- 下面要讲的反斜杠内容都可以放到方括号中
3.3 小括号 ()
我现在想要逗号前的内容(不包含逗号),那么我们就应该这样写

小括号被成为组选择器,如果我们感兴趣的内容有多组,我们可以设置多个小括号,比如我下面就想提取颜色部分

4 反斜杠 \
4.1 元字符的转译
我们现在想提取点之前的内容
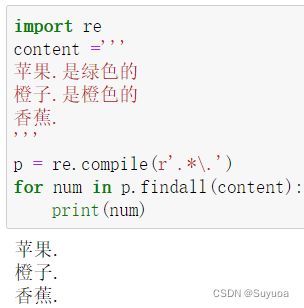
如果不加斜杠的话是不可以的
4.2 数字字符 \d
使用 \d 可以提取出文字内的数字字符

相当于[0-9]

当位数多的时候就可以像上面电话号码那样操作
4.3 非数字字符 \D

相当于[^0-9]

4.4 空白字符 \s
提取字符的空白部分,包括空格,tab,换行符等

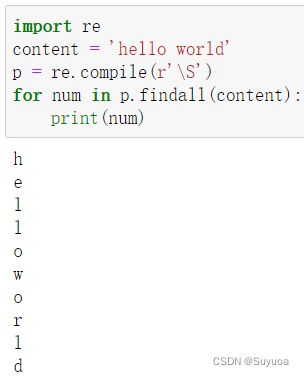
4.5 非空白字符 \S
4.6 文字字符 \w
包括大小写字母,数字,下划线,以及unicode字符
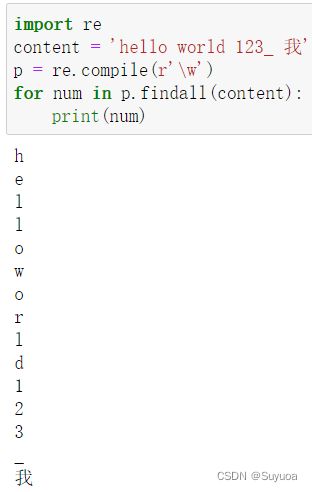
与[a-zA-Z0-9_]是有区别的

如果我们不想要汉字也可以这样写
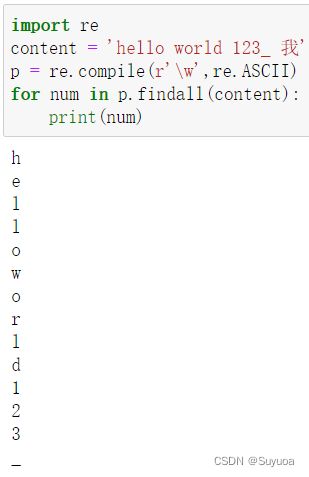
或者

4.7 非文字字符 \W

- 上面的结果是两行空格
5 其余方法
5.1 re.split()
比如当我们想提取用逗号,分号或空格后的信息,我们就可以这样写

5.2 re.sub()
将不太规则的字符,换成固定字符

我现在想让号码都加上6,那么我们不能替换成固定字符,而是要使用函数

上面那个例子中
- sth.group(0) 是字符串的全部内容
- sth.group(1) 是字符串的第一组的内容,如果把数字换成2,就是第二组的内容
5.3 re.compile的第二个参数
这里的re.A这种东西,我们称为Flag
5.3.1 re.ASCII与re.A
如果加上了,就只匹配ASCII字符

5.3.2 re.DOTALL与re.S
当你要隔行寻找的时候,加入re.S就是全体找,不加就是一行一找

5.3.3 re.IGNORECASE与re.I
加上不区分大小写,不加上就区分
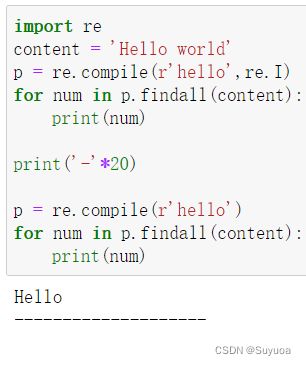
5.3.4 re.MULTLINE与re.M
加上了就是多行模式,没加就不是多行模式,只针对^和$这两个符号

- 没加多行模式没找到的原因是开头就换行了,所以没有
5.3.5 re.VERBOSE与re.X
加上后排除空格井号等对正则表达式的影响,一般不使用这个
