1 监督学习与非监督学习简介--机器学习基础理论入门
1 监督学习与非监督学习简介–机器学习基础理论入门
1.1 机器学习基本概念
什么是机器学习
机器学习:
机器学习(machine learning,ML)是一门多领域交叉学科,设计概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
输入
训练集(training set):用于建立模型
验证集(validation set):用来检验最终选择最优的模型的性能如何
测试集(test set):用来检验最终选择最优的模型的性能如何,要和样本集分布一致。

输出
给定输入的特征向量X=(x_1,x_2,…,x_m),特定的算法经过计算,输出对应的预测标签y ̂
机器学习的目标与评价
目标
遇到新数据时能够准确的对该数据进行分析(泛化)
评价
任务不同,评价方式不同
用量化的方式来评价算法的效果
输出正确的数量越多效果越好
e.g 回归任务通常使用均方误差来衡量算法的效果

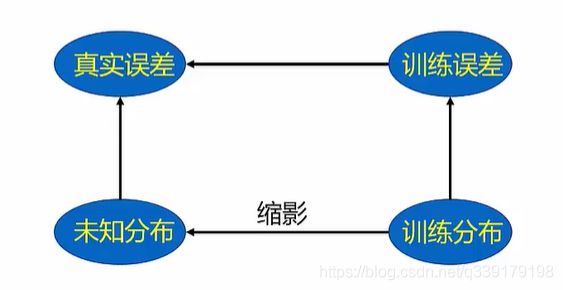
指导原则—经验风险最小化
定义:最小化在训练集上的误差
一直复习电磁学的内容,如果考电磁学,那效果会比较好,如果考试天体物理,那就效果比较差。
经验风险最小化如果不加限制的使用会有过拟合和欠拟合的问题。
过拟合与欠拟合
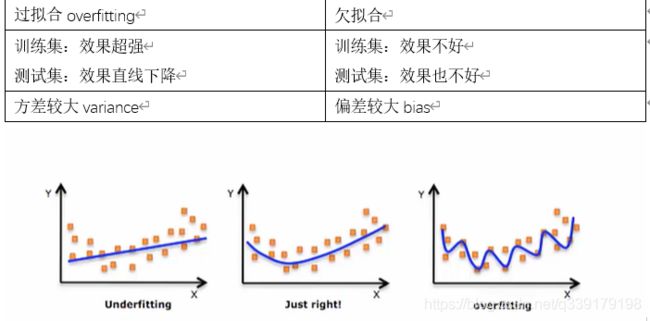
过拟合一定会发生的原因:数据量太小,不能反映真实的数据分布;模型复杂度的问题,比如神经网络,参数太多,可解释性差;缺乏归纳偏置
归纳偏置
事先对机器学习算法的一种假设,一种偏好,从概率论的角度来看,归纳偏置就是加入的模型中的先验信息。
作用:减少搜索空间;减缓过拟合
如何假设出问题,那很难得出正确答案。
独立同分布条件(I.i.d条件)
定义:训练集和测试集是从统一个数据分布中抽取,并且抽取的过程是独立的(independent and identically distributed)
满足独立同分布条件,前面提到的经验风险最小化才是成立的。
推论:
(1) 数据集越大,越能反应数据的真实分布(题海战术)
(2) 数据集的质量很重要(做不同类型的题目,才能提高泛化能力)
1.2 监督学习简介
什么是监督学习
利用一组已知类别的样本调整算法的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。
买课本的时候,如果后面又习题答案就是监督学习,若没有答案就是非监督学习。
特征工程
特征比算法更重要。进入算法的是垃圾,结果也肯定是垃圾。
特征的质量比数量更重要。
特征过多的缺陷
(1) 增加了算法的复杂度和运行时间
(2) 简单的模型更具有鲁棒性(奥卡姆剃刀原理)
(3) 有用的维度数量少的时候可解释性更强
两种方法
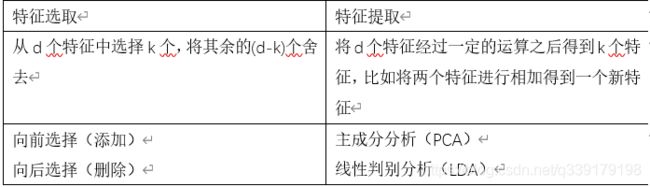
在实践中,特征工程是一个具有艺术气息的工作,很多时候需要一些专业知识,很多时候靠不断的尝试。
实例


对数值型连续随机变量进行预测和建模的监督学习算法(即最后输出的特征向量的标签是连续值)
1.3 非监督学习简介
什么是非监督学习
在未加标签的数据中,试图找到隐藏的结构
实例
聚类
聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集,这样让同一个子集的成员对象都有相似的一些属性。

1.4 常见算法简介
回归算法
对数值型连续随机变量进行预测和建模的监督学习算法(即最后输出的特征向量的标签是连续值)
函数的拟合问题(最小二乘法)
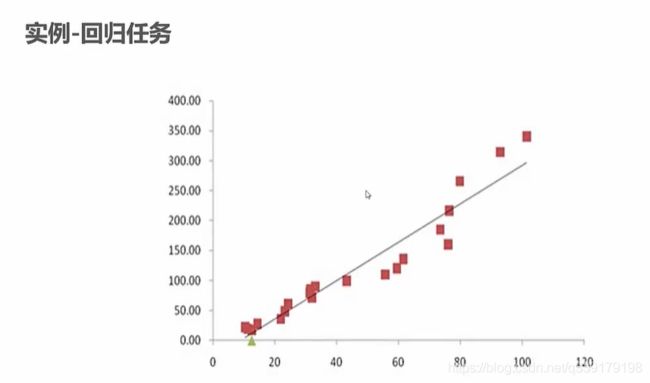
一维回归任务
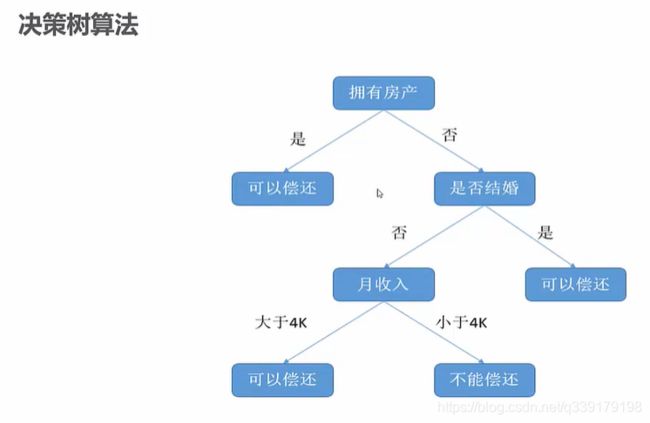
决策树算法
神经网络算法
一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间互相连接的关系,从而达到处理信息的目的。
典型的全连接神经网络
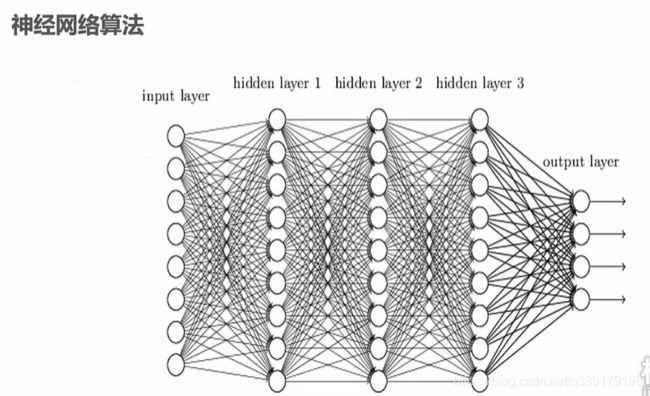
只要分布是线性可分的,那感知机模型一定收敛。感知机模型只有输入和输出。增加了隐藏层后就是神经网络,理论上复杂很多,计算能力要求高很多,卷积神经网络在图像识别领域大放异彩,但是也不是万能的,很多时候因为数据的可用性。
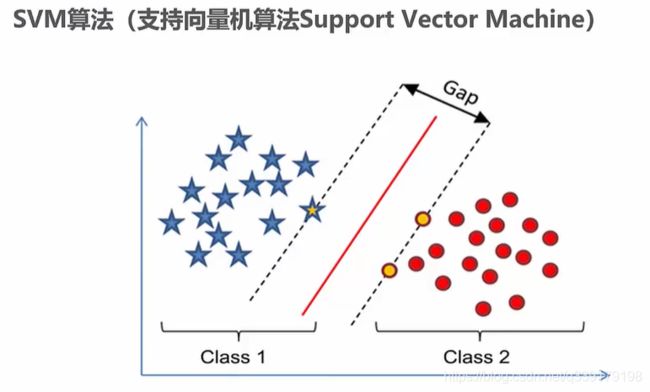
SVM算法(支持向量机)
Vapnik等人在多年研究统计学习理论基础上对线性分类器提出了另一种设计最佳准则。其原理也从线性可分说起,然后扩展到线性不可分的情况。甚至扩展到使用非线性函数中去,这种分类器被称为支持向量机。
SVM一般用于二分类任务,经过变换也可胜任多分类任务(one-against-one方法是在每两个类之间都构造一个binary SVM;对于每一个类,将其作为+1类,而其余 [公式] 个类的所有样本作为-1类,构造一个binary SVM,一类对余类,one-against-all,one-against-the-rest)
SVM就是寻找一个超平面,把数据集分开,同时使支持向量到超平面的距离最小化。处于虚线的点就是支持向量。有时候,可能涉及特征的非线性变换。
K-Means算法
算法接受参数k(簇);然后将事先输入的n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较低。
KNN算法
如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。

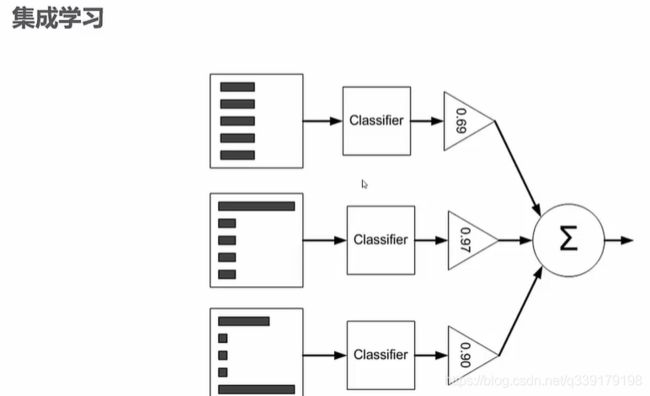
集成学习算法
集成学习是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。
分为bagging和boosting