【PDF】html/dom生成pdf
1、简要描述
上一篇博客主要讲的是pdf文件转换成canvas,然后进行相关的操作。本篇博客主要讲html中dom如何生成pdf文件(前端生成pdf),后端生成pdf当然也可以,原理也是将html网页通过后端服务导出成pdf,不深入讲,这里着重讲前端生成pdf。
2、相关插件及知识
还是使用的老朋友html2canvas和jspdf插件
1、jspdf
"jspdf": "^2.5.1"使用方法:
import JsPDF from 'jspdf';
const PDF = new jsPDF({
unit: "mm", // 单位,本示例为mm
format: "a4", // 页面大小
orientation: "portrait", // 页面方向,portrait: 纵向,landscape: 横向
putOnlyUsedFonts: true, // 只包含使用的字体
compress: true, // 压缩文档
precision: 16, // 浮点数的精度
});
// 或者
const PDF = new JsPDF('p', 'mm', [210, 297]);
// 添加图片
PDF.addImage(
imageData, // 此值可以为下面这些类型 string | HTMLImageElement | HTMLCanvasElement | Uint8Array | RGBAData
'JPEG', // 转换后的格式
x, // 被切割的imageData的横坐标
y, // 被切割的imageData的纵坐标
w, // 当前图片的宽度
h, // 当前图片的高度
);
// 添加新的一页
PDF.addPage();
// 输出格式
PDF.output(type: "arraybuffer"): ArrayBuffer;
PDF.output(type: "blob"): Blob;
PDF.output(type: "bloburi" | "bloburl"): URL;
// 本地保存为pdf文件
PDF.save('lindadayo.pdf')2、html2canvas
"html2canvas": "^1.4.1"// 实例方法
html2canvas(dom, config).then(function(canvas) {}) config相关配置参考下图: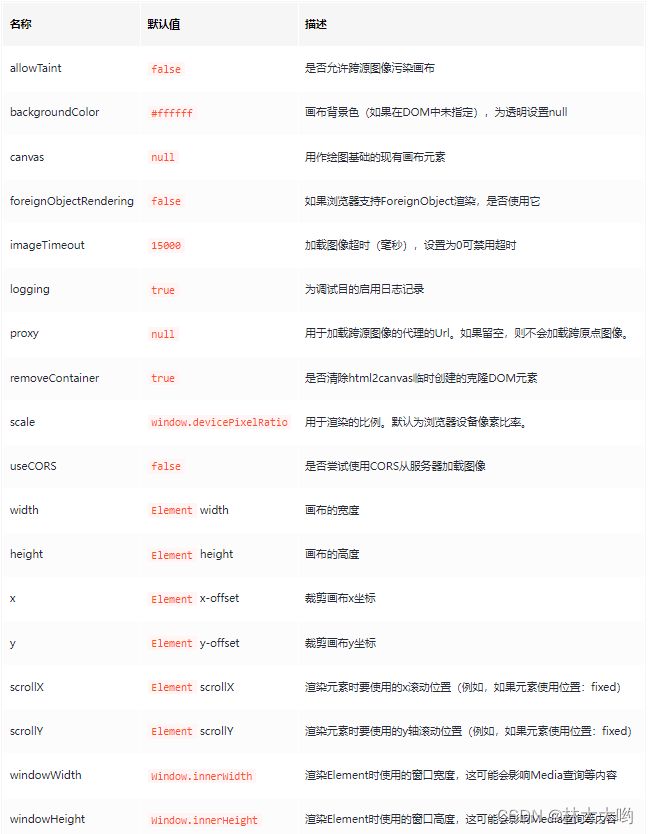
3、源码
1、dom结构

2、核心逻辑
这里为什么要将dom进行分区处理呢?请看第四点疑难解答
/**
* 生成pdf
* @param CommonPage 需要转换的dom节点
* @param i 分区索引
* @returns
*/
async generatePdf(CommonPage?: Element, childLen?: number) {
PDF = new JsPDF('p', 'mm', [210, 297]); // pdf实例
for (let i = 0; i < childLen; i++) {
await asyncSingleAreaControl(CommonPage, i)
}
generateUploadPdf();
},
/**
* 上传pdf文件
*/
async generateUploadPdf() {
// 文件重命名
const pdfName = pdfNameHandle()
const uri = PDF.output('blob')
const file = await blobUriToFile(uri, pdfName)
// 此时的file是File类对象,你可以选择上传到服务器噢~当然你也可以选择直接导出到前端
// PDF.output('lindadayo.pdf');
},
/**
* 单个分区生成pdf操作
* @param CommonPage 父节点dom
* @param i 分区索引
* @returns
*/
async asyncSingleAreaControl(CommonPage, i) {
const canvas = await singleHandle(CommonPage, i)
await areaPage(canvas, i)
},
/**
* 分区pdf处理
* @param canvas 各个分区dom转换后的canvas
* @param areaNo 分区索引
*/
areaPage(canvas, areaNo) {
// 是否是第一个分区(作用于是否开始就addPage)
const isFirstArea = areaNo === 0
return new Promise((resolve, _reject) => {
// a4纸宽高
const A4Origin = {
width: PDF.internal.pageSize.getWidth(),
height: PDF.internal.pageSize.getHeight()
}
const contentWidth = canvas.width;
/**
* html2canvas放大3.125倍时精度丢失导致多了2像素
* 3368: 高度285mm纸张html2canvas放大300dpi后像素
* 3366:正常实际高度
*/
const contentHeight = canvas.height <= 3368 ? 3366 : canvas.height;
const pageHeight = Math.round(contentWidth / A4Origin.width * A4Origin.height);
let leftHeight = contentHeight;
let position = 0;
const imgWidth = A4Origin.width;
const imgHeight = Math.ceil(A4Origin.width / contentWidth * contentHeight);
const pageData = canvas.toDataURL('image/jpeg', 1);
// 非首个分区,得先addPage,因为不然会少一页 && 大于某个范围才新增一页,避免因为浮点数计算精度造成多增一页
if (!isFirstArea && leftHeight > 0) {
PDF.addPage()
}
while (leftHeight > 0) {
PDF.addImage(pageData, 'JPEG', 0, position, imgWidth + (isBrower() ? 0.62 : 0), imgHeight + (isBrower() ? 0.32 : 0));
position -= A4Origin.height;
leftHeight -= pageHeight
// 大于某个范围才新增一页,避免因为浮点数计算精度造成多增一页
if (leftHeight > 0) {
PDF.addPage()
}
}
resolve(true)
})
},
/**
* 单页pdf处理
// * @param root 总节点
* @param index 分区索引
*/
async singleHandle(CommonPage, index) {
// 报错Unable to find element in cloned iframe解决方法
// getDiv在外部声明, 内部赋值
try {
getDiv = CommonPage.querySelector(`#CommonPageItemArea-${index}`)
const res = await html2canvas(getDiv, {
useCORS: true,
allowTaint: true,
scale: 3.125
}).then(function(canvas) {
return canvas
})
return res
} catch (e) {
console.log(e)
}
}4、疑难解答
1、为什么要对dom进行分区操作?
其实如果你不使用html2canvas的参数scale,就没必要进行分区,但是在很多时候,你不放大canvas的话,会导致pdf中的图片很模糊,还有锯齿,所以要对canvas进行方法,但是放大后,会导致一些问题:生成pdf后,超过15000px以后的dom会有样式丢失,所以得对dom进行分区操作,让每个分区的dom高度 * 放大倍数不超过15000px。我们一般都会导出a4纸大小,a4纸宽高是210mm*297mm,换算成像素是793.29px * 1122.52px,如果你选择放大两倍,那么,单页高度就是2245px,结论为一个分区能够放六个a4纸高度的dom,所以你在开发页面时,就要做好这种页面结构噢~
2、html2canvas仍然报图片出错/跨域的问题,即使后端oss已经解决跨域了
这个涉及知识点:img标签获取属于非跨域操作,Image类实例化属于跨域操作,所以得再html2canvas依赖中打补丁
/dist/html2canvas.js
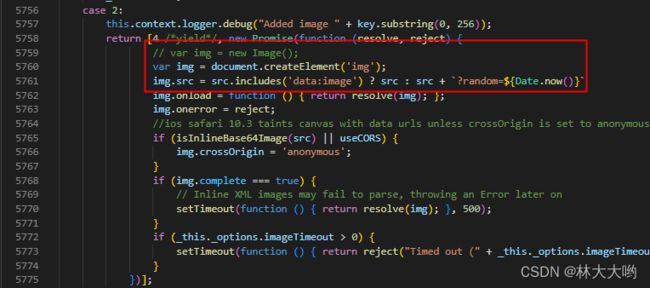
3、报错Unable to find element in cloned iframe解决方法
在分区中循环处理dom生成canvas时会报出这种错误,原因是html2canvas第一参数的变量应该设置为全局变量而不应该是局部变量
try {
getDiv = CommonPage.querySelector(`#CommonPageItemArea-${index}`)
const res = await html2canvas(getDiv, {
useCORS: true,
allowTaint: true,
scale: 3.125
}).then(function(canvas) {
return canvas
})
return res
} catch (e) {
console.log(e)
}--- 有问题可以随时评论噢~ ---