手把手教学分布式事务Seata的AT模式
使用AT模式的前提:
--需要支持ACID事务的关系型数据库
AT特色:
--AT对业务代码完全无侵入,在使用的过程中只要关注自己的业务SQL,其它的交给Seata来分析提交的SQL语句(开启全局事务,全局锁,记录到undoLog,提交or回滚等)
AT的2个阶段操作:
--一阶段,在本地事务中,一并提交业务数据的更新和将对应的操作记录到undoLog
--二阶段,成功结束,自动异步删除记录到undoLog的日志。失败则生成补偿操作,完成数据的回滚
AT 如何使用
模拟需求:以下订单为例,在分布式的电商场景中,订单服务和库存服务可能是两个数据库
我们先来看看AT模式下的代码是什么样的,这里忽略了Seata的相关配置,只看业务部分
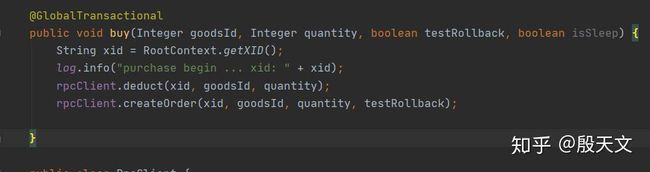
在需要开启分布式事务的方法上标记@GlobalTransactional,然后执行分别执行扣减库存和扣减库存操作的,事务的参与者可以是本地的数据源,或者RPC的远程调用(远程调用的话需要携带全局事务ID,也就是上图的xid)
AT 一阶段
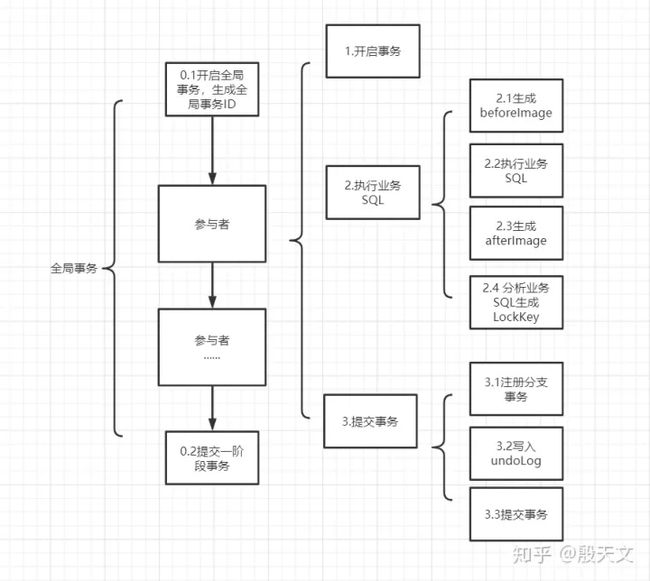
之前说过AT模式分为两个阶段,第一阶段包括提交业务数据和回滚日志(undoLog),第一阶段具体流程如下图
GlobalTransactional 切面
标记@GlobalTransactional的方法通过AOP实现了,开启全局事务和提交全局事务两个操作,与Spring 事务机制类似,当 GlobalTransactionalInterceptor 在事务执行过程中捕获到Throwable时,会发起全局事务回滚
0.1 步骤中会生成一个全局事务ID
0.2 所有事务参与者执行结束后,一阶段事务提交
undoLog
我们先来看看 Seata undoLog 的结构
// 省略了相关方法
public class SQLUndoLog {
// insert, update ...
private SQLType sqlType;
private String tableName;
private TableRecords beforeImage;
private TableRecords afterImage;
}Seata 在执行业务SQL前后,会生成beforeImage和afterImage,在需要回滚时,根据SQLType,决定具体的回滚策略,例如SQLType=update时,将数据回滚到beforeImage的状态,如果SQLType=insert,则根据afterImage删除数据
如2.4所示,每条业务SQL,执行成功后,会为这条SQL生成LockKey,格式为tableName:PrimaryKey
注册分支事务
在3.1步骤注册分支事务时,client会把所有的LockKey 拼到一起作为全局锁发送给Seata-server。如果注册成功,写入undoLog,并提交本地事务,一阶段结束,等待二阶段反馈
如果当前有其他分支事务已经持有了相同的锁(即其他事务也在处理相同表的同一行),则client 注册事务分支失败。client会根据客户端定义的重发时间和重发次数进行不断的尝试,如果重试结束仍然没有获得锁,则一阶段失败,本地事务回滚。如果该全局事务存在已经注册成功分支事务,Seata-server 进行二阶段回滚
全局锁会在分支事务二阶段结束后释放
Seata 全局锁的设计是为了什么? 以扣减库存场景为例,TX1 完成库存扣减的一阶段,库存从100扣减为99,正在等待二阶段的通知。TX2也要扣减同一商品的库存,如果没有全局锁的限制,TX2库存从99扣减为98,这时如果TX1接收到回滚通知,进行回滚把库存从98回滚到100。因为没有全局锁,造成了 脏写
AT 二阶段
二阶段是完全异步化的并且完全由Seata控制,Seata根据所有事务参与者的提交情况决定二阶段如何处理
如果所有事务提交成功,则二阶段的任务就是删除一阶段生成 的undoLog,并释放全局锁
如果部分事务参与者提交失败,则需要根据undoLog对已经注册的事务分支进行回滚,并释放全局锁
对Seata提出的疑问
至此我们已经初步了解了Seata的AT模式是如何实现的了
如果你也和我一样,仔细思考了上述过程,可能会提出一些问题,这边我列举一下我在学习Seata时,遇到的问题,以及我得出的结论
问题1. Seata如何做到无侵入的分析业务SQL生成undoLog,注册事务分支等操作?
Seata 代理了DataSource,我们可以通过在代码注入一个DataSource来验证我的说法,目前的DataSource 是 io.seata.rm.datasource.DataSourceProxy
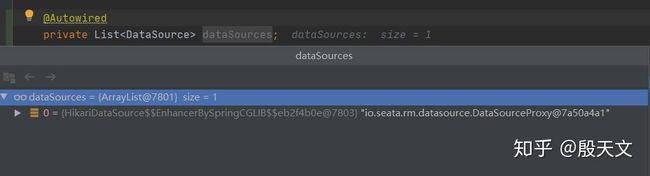
所有的Java持久化框架,最终在操作数据库时都会通过DataSource接口获取Connection,通过Connection 实现对数据库的增删改查,事务控制。
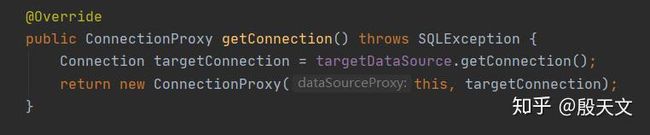
Seata 通过代理Connection的方式,做到了无侵入的生成undoLog,注册事务分支,具体源码可以查看io.seata.rm.datasource.ConnectionProxy
问题2. ConnectionProxy 如何判断当前事务是全局事务,还是本地事务?
通过当前线程是否绑定了全局事务id,在进行全局事务之前,需要调用RootContext.bind(xid);
问题3. 全局事务并发更新
还是以下订单扣减库存的场景为例,如果TX1和TX2同时扣减product_id为1的库存,这时Seata会不会生成相同的beforeImage?
举个例子,TX1读库存为100,TX1扣减库存1,此时BeforeImage为100 紧接着 如果TX2读库存也为100,那么就有问题了,不管TX2扣减多少库存,如果TX1回滚那么相当于覆盖了TX2扣减的库存,出现了脏写
Seata是如何解决这个问题的?
源码位置:io.seata.rm.datasource.exec.AbstractDMLBaseExecutor::executeAutoCommitFalse

可以看到这里的逻辑和我上面画的图一致,证明我没有瞎说
我们来看一下beforeImage(),这是一个抽象方法,看一下他的子类UpdateExecutor是如何实现的

通过Debug,可以看出Seata这边也是确实考虑了这个问题,直接简单而有效的解决了这个问题
回到我们的例子,由于SELECT FOR UPDATE的存在,TX2如果也想读同一条数据的话,只能等到TX1 提交事务后,才能读到。所以问题解决
问题4. 全局事务外的更新
我们现在可以确认在Seata的保证下,全局事务,不会造成数据的脏写,但是全局事务外会!
什么意思呢?
还以库存为例
用户正在抢购,用户A完成了1阶段的库存扣减,这个时候库存为99。
此时库存管理员上线了,他查了一下库存为99。嗯...太少了,我加100个,库存管理员把库存更新为200。
而此时seata给用户A生成beforeImage为100,如果此时用户A的全局事务失败了,发生了回滚,再次将库存更新为100... 再次出现脏写
Seata 针对这个问题,提供了@GlobalLock注解,标记该注解时,会像全局事务一样进行SQL分析,竞争全局锁,就不会出现上述问题了
关于这个问题可以参考Seata的FAQ文档 http://seata.io/zh-cn/docs/overview/faq.html
问题5. @GlobalTransactional 和 @Transactional 同时使用会怎么样
我们上文中已经说过了 @GlobalTransactional 的作用了,他是负责开启全局事务/提交事务1阶段,说白了@GlobalTransactional 只和Seata-server 交互,而 @Transactional 管理的是本地数据库的事务,所以二者不发生冲突。
但是需要注意 @GlobalTransactional AOP 覆盖范围一定要大于 @Transactional
问题6. 如果其中某一个事务分支超时未提交,会发生什么
这个我并没有看源码,而是通过跑demo,验证的
例如现在有A,B两个事务分支
A 正常提交,并向Seata注册分支成功
B 2分钟后提交事务,并向Seata发起注册
Seata的全局事务超时时间,默认是1分钟,Seata-server 在检测到有超时的全局事务时,会向所有已提交的分支,发起回滚。而超时提交的事务,向Seata-server发起分支注册时,响应结果为事务已超时,或者事务不存在,也会回滚本地事务
问题7. Seata-client 如何接收Seata-server发起的通知
Seata-client 包含了Netty服务,在启动时Netty会监听端口,并向Seata-server 发起注册。server中存储了client 的调用地址。
总结
我们学习了Seata的AT模式是如何工作的,可以看出Seata模式在开发上是非常简单的,但是Seata的背后为了维持分布式事务的数据一致性,做了大量的工作,AT模式非常适合现有的业务模型直接迁移。
但是他的缺点也很明显,性能并不是那么的优秀。例如我们刚刚看到的全局锁的问题,为了数据不会发生脏写,Seata牺牲了业务的并发能力。在非常要求性能的场景,可能还是需要考虑TCC,SAGA,可靠消息等方案
在使用Seata开发前,建议大家先去阅读一下FAQ文档,避免踩坑 https://seata.io/zh-cn/docs/ove