windows下配置pytorch + yolov8+vscode,并自定义数据进行训练、摄像头实时预测
最近由于工程需要,研究学习了一下windows下如何配置pytorch和yolov8,并自己搜集数据进行训练和预测,预测使用usb摄像头进行实时预测。在此记录一下全过程
一、软件安装和配置
1. vscode安装
windows平台开发python,我采用vscode作为基础开发平台,点击 https://code.visualstudio.com/进入vscode官网,下载对应的稳定版本即可。
下载安装完成后,在插件界面搜索 python,找到第一个即可安装好python开发环境。
python我安装的是3.10版本
2. miniconda3安装
miniconda3可以用于配置pytorch的开发环境,https://docs.conda.io/en/latest/miniconda.html在官网下载对应版本即可,我的是python3.10,windows64,所以下载的是如图所示的安装包
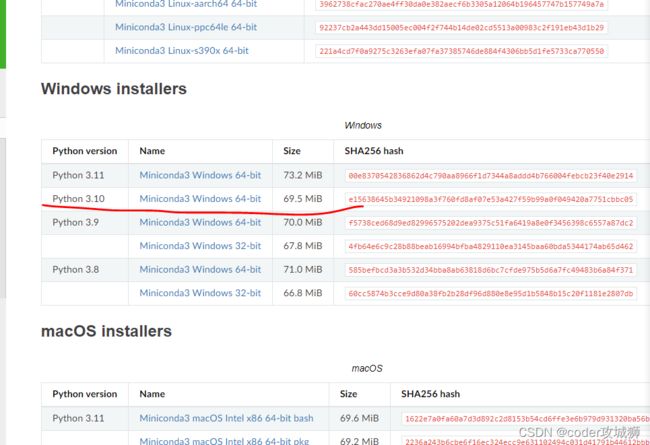
配置path变量:找到miniconda3安装路径,参照下图设置环境变量

设置完成后,在开始菜单中找到Anaconda Prompt(miniconda3),打开。
- 添加清华镜像源,提高软件下载速度
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
- 配置miniconda开发环境
使用一下命令,创建一个pytorch虚拟环境
conda create -n pytorch python=3.10
-n 后面跟虚拟环境名称
python=设置python版本
- 通过以下命令激活虚拟环境
conda activate pytorch
之后,可以在该环境下配置pytorch
3. pytorch安装
进入pytorch官网https://pytorch.org/,查找对应的下载命令,我的是windows、CPU、python版本,所以选择如下图所示配置
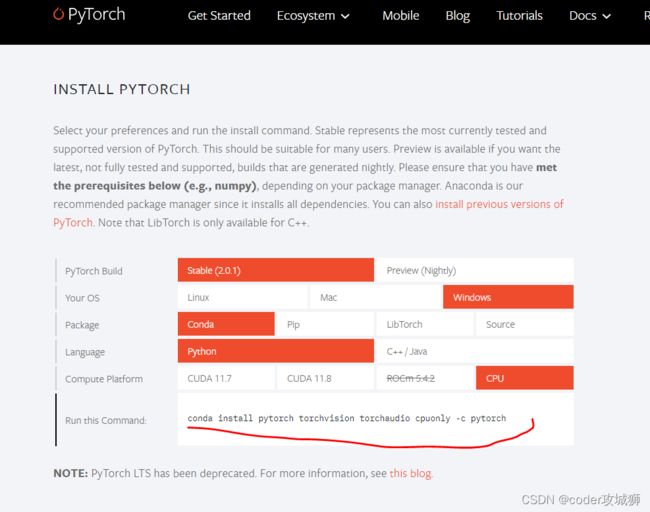
复制图中对应的安装命令,即可安装pytorch
conda install pytorch torchvision torchaudio cpuonly -c pytorch

注意,此命令在激活的pytorch环境下安装
- 打开vscode,配置pytorch环境
在vscode中输入ctrl+shif+p打开命令行界面,输入Python:Select Interpreter选择python的开发编译环境
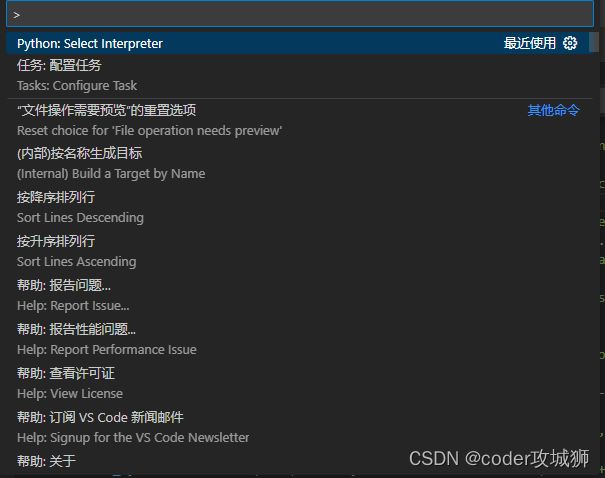
选择Python 3.10.12(‘pytorch’)作为当前环境即可

新建test.py文件,输入如下代码,按F5执行,若成功,则pytorch配置成功。
import torch
print(torch.__version__)
print(torch.cuda.is_available())
或者执行
python test.py

4. yolov8安装配置
在pytorch环境激活的情况下,使用一下命令安装yolov8
pip install ultralytics
安装完成后,通过命令进行测试
yolo task=detect mode=predict model=yolov8n.pt imgsz=640 show=True save=True
命令会自己到github下载对应的测试数据bus.jpg和zidane.jpg两张图片 和默认的权重文件yolov8n.pt
如果无法下载yolov8n.pt,可以自己下载后,复制到对应的路径下也可以。
D:\Install\miniconda3\envs\pytorch\Lib\site-packages\ultralytics\yolo\v8\detect
如果缺少环境,下载ultralytics源码,执行下面命令安装依赖
pip install -r requirements.txt
二、yolov8自定义数据集
- 数据采集,根据自己项目需要,采集场景图片,图像大小没关系,后期yolo会根据配置,自动调整大小
- 对数据进行标注
安装labelImg数据标注工具,之后对数据进行标注

1、打开标注前图像数据所在文件夹
2、设置标注后标签文件保存位置,该位置下仅保存txt类型的标签数据
类别 box中心x box中心y box宽 box高
0 0.044531 0.735417 0.023438 0.048611
0 0.084766 0.625694 0.025781 0.054167
0 0.154297 0.620833 0.022656 0.058333
0 0.275000 0.584028 0.037500 0.076389
0 0.289844 0.868750 0.034375 0.070833
3、数据分类
按照图像、标签新建文件夹,并在每个文件夹下新建train和val文件夹,注意路径中不能有中文,路径如下所示


使用如下代码,将原始图像数据和标注数据进行分类
import sys,os
import shutil
imgPath = "F:/images/"
labelPath = "F:/data/Annotation"
yoloImagePath = "F:/data/images"
yoloLabelsPath = "F:/data/labels"
# labels = os.listdir(labelPath)
f=os.walk(labelPath)
#80%数据做训练,20%做矫正
persent=0.8
for dirpath,dirNames,filenames in f:
trainNum = int(len(filenames)*persent)
for i,filename in enumerate(filenames):
name=filename.split('.')[0]
if name=='classes':
continue
imgSrc=imgPath+name+".jpg"
imgDst=''
labelSrc=labelPath+"/"+filename
labelDst=''
# 训练数据
if i<trainNum:
imgDst = yoloImagePath+"/train"
labelDst = yoloLabelsPath+"/train"
else:
#矫正数据
imgDst = yoloImagePath+"/val"
labelDst = yoloLabelsPath+"/val"
shutil.copy(imgSrc,imgDst)
shutil.copy(labelSrc,labelDst)
4.新建配置文件.yaml,用于指定训练数据、验证数据的路径
#训练数据路径
train: F:/data/images/train
#验证数据路径
val: F:/data/images/val
# number of classes
nc: 1
# class names
names: ['acupoint']
自此,自定义数据的搜集和标注完成
三、自定义数据训练
接下来开始进行训练,在开始菜单打开anaconda prompt(miniconda3),使用conda activate pytorch后,使用以下命令
yolo task=detect mode=train model=yolov8n.pt data=F:/data/acupoint.yaml epochs=100 batch=16
task:指定运行的任务类型,有detect\segment\classify\init
mode:指定是train、predict、val
model:选择配置值权重模型
data:指定.yaml所在位置,
epochs:迭代次数
batch:一次加载多少张图片后更新权重
训练后,结果默认保存在以下目录中,
D:\Install\miniconda3\envs\pytorch\Lib\site-packages\ultralytics\yolo\v8\detect\runs\detect\train2

其中best.pt即为后续预测需要使用的模型文件
四、摄像头数据预测
训练结束后,使用
yolo task=detect mode=predict model=./runs/detect/train2/weights/best.pt source=0 show=True save=True
打开摄像头开始进行预测,默认图像大小为480x640.
其中model:自定义数据训练的模型结果
source:指定预测数据,可以是图片路径或视频路径,0表示使用usb摄像头0实时读取数据
show:是否实时显示结果
save:是否保存结果
以上是经过几天摸索,并经过实践验证的,可以行的通。后续会接着研究如何使用代码获取预测结果。