特征工程系列:特征预处理(上)
关于作者:JunLiang,一个热爱挖掘的数据从业者,勤学好问、动手达人,期待与大家一起交流探讨机器学习相关内容~
0x00 前言
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。
那特征工程是什么?
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
虽然我们也有自动的机器学习框架,如 AutoML(但该框架也强调了它需要好的特征才能跑出好的效果!)。特征工程永不过时,即使对于自动化方法,其中也有一部分经常需要根据数据类型、领域和要解决的问题而设计特殊的特征。
特征工程又包含了Data PreProcessing(数据预处理)、Feature Extraction(特征提取)、Feature Selection(特征选择)和Feature construction(特征构造)等子问题,而数据预处理又包括了数据清洗和特征预处理等子问题,本章内容主要讨论数据预处理的方法及实现。
0x01 特征预处理介绍
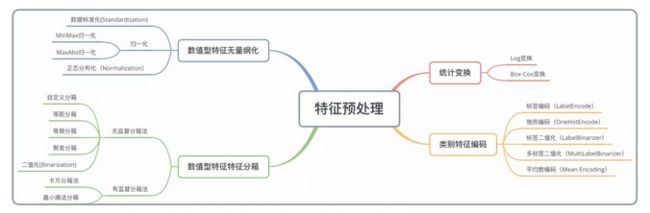
特征预处理包括无量纲化、特征分桶、统计变换和特征编码等步骤,详情可参考下图:
0x02 数值型特征无量纲化
我们的数据一般都是有单位的,比如身高的单位有m,cm,这个无量纲化并不是说把m变成cm,而是说,无论是m还是cm,最后都会变成1,也就是没有了单位。
无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和归一化。
数据标准化的原因:
-
某些算法要求样本具有零均值和单位方差;
-
需要消除样本不同属性具有不同量级时的影响。
-
归一化有可能提高精度;
数量级的差异将导致量级较大的属性占据主导地位,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要);
-
数量级的差异将导致迭代收敛速度减慢;
当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;
-
依赖于样本距离的算法对于数据的数量级非常敏感。
-
1.数据标准化(Standardization)
标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。
1)定义
基于原始数据的均值(mean)和标准差(standarddeviation)进行数据的标准化。将A的原始值x使用z-score标准化到x’。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。
标准化公式:

均值和标准差都是在样本集上定义的,而不是在单个样本上定义的。标准化是针对某个属性的,需要用到所有样本在该属性上的值。
2)标准化效果

3)优缺点
优点:
Z-Score最大的优点就是简单,容易计算,Z-Score能够应用于数值型的数据,并且不受数据量级的影响,因为它本身的作用就是消除量级给分析带来的不便。
缺点:
-
估算Z-Score需要总体的平均值与方差,但是这一值在真实的分析与挖掘中很难得到,大多数情况下是用样本的均值与标准差替代;
-
Z-Score对于数据的分布有一定的要求,正态分布是最有利于Z-Score计算的;
-
Z-Score消除了数据具有的实际意义,A的Z-Score与B的Z-Score与他们各自的分数不再有关系,因此Z-Score的结果只能用于比较数据间的结果,数据的真实意义还需要还原原值;
-
在存在异常值时无法保证平衡的特征尺度。
4)实现代码:
from sklearn.preprocessing import StandardScaler
#标准化,返回值为标准化后的数据
standardScaler = StandardScaler().fit(X_train)
standardScaler.transform(X_train)2.归一化
1)MinMax归一化
区间缩放法利用了边界值信息,将属性缩放到[0,1]。
公式:
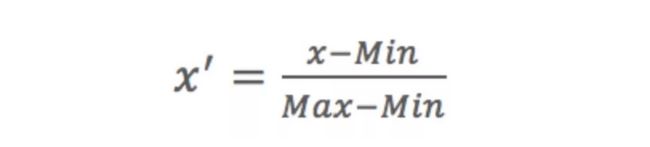
效果

实现代码
from sklearn.preprocessing import MinMaxScaler
#区间缩放,返回值为缩放到[0, 1]区间的数据
minMaxScaler = MinMaxScaler().fit(X_train)
minMaxScaler.transform(X_train)缺点:
-
这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义;
-
MinMaxScaler对异常值的存在非常敏感。
2)MaxAbs归一化
单独地缩放和转换每个特征,使得训练集中的每个特征的最大绝对值将为1.0,将属性缩放到[-1,1]。它不会移动/居中数据,因此不会破坏任何稀疏性。
MaxAbs公式

效果

缺点:
-
这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义;
-
MaxAbsScaler与先前的缩放器不同,绝对值映射在[0,1]范围内。
在仅有正数据时,该缩放器的行为MinMaxScaler与此类似,因此也存在大的异常值。
实现代码
from sklearn.preprocessing import MaxAbsScaler
maxAbsScaler = MaxAbsScaler().fit(X_train)
maxAbsScaler.transform(X_train)3.正态分布化(Normalization)
1)定义
正则化的过程是将每个样本缩放到单位范数(每个样本的范数为1),如果要使用如二次型(点积)或者其它核方法计算两个样本之间的相似性这个方法会很有用。
该方法是文本分类和聚类分析中经常使用的向量空间模型(Vector Space Model)的基础。
Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(l1-norm,l2-norm)等于1。
2)规则为l2的公式

3)正则化效果
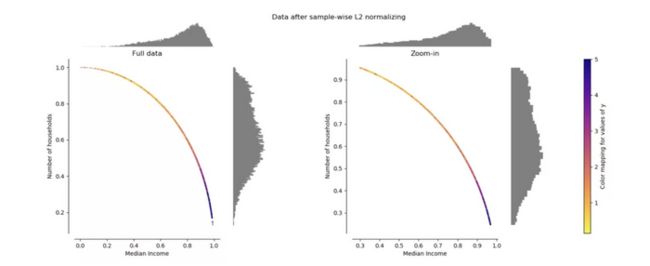
可以在上面的两个图中看到所有样本都映射到单位圆上。在我们的示例中,两个选定的特征仅具有正值; 因此,转换后的数据仅位于正象限中。如果某些原始特征具有正值和负值的混合,则情况并非如此。
4)实现代码
from sklearn.preprocessing import Normalizer
#归一化,返回值为归一化后的数据
normalizer = Normalizer(norm='l2').fit(X_train)
normalizer.transform(X_train)4.标准化与归一化对比
1)标准化与归一化的异同
相同点:
它们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
不同点:
-
目的不同,归一化是为了消除纲量压缩到[0,1]区间;
标准化只是调整特征整体的分布;
-
归一化与最大,最小值有关;
标准化与均值,标准差有关;
-
归一化输出在[0,1]之间;
标准化无限制。
2)什么时候用归一化?什么时候用标准化?
-
如果对输出结果范围有要求,用归一化;
-
如果数据较为稳定,不存在极端的最大最小值,用归一化;
-
如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
3)归一化与标准化的应用场景
-
在分类、聚类算法中,需要使用距离来度量相似性的时候(如SVM、KNN)、或者使用PCA技术进行降维的时候,标准化(Z-score standardization)表现更好;
-
在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法。
比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围;
-
基于树的方法不需要进行特征的归一化。
例如随机森林,bagging与boosting等方法。
如果是基于参数的模型或者基于距离的模型,因为需要对参数或者距离进行计算,都需要进行归一化。
一般来说,建议优先使用标准化。对于输出有要求时再尝试别的方法,如归一化或者更加复杂的方法。很多方法都可以将输出范围调整到[0, 1],如果我们对于数据的分布有假设的话,更加有效的方法是使用相对应的概率密度函数来转换。
除了上面介绍的方法外,还有一些相对没这么常用的处理方法:RobustScaler、PowerTransformer、QuantileTransformer和QuantileTransformer等。
0x03 数值型特征特征分箱(数据离散化)
离散化是数值型特征非常重要的一个处理,其实就是要将数值型数据转化成类别型数据。连续值的取值空间可能是无穷的,为了便于表示和在模型中处理,需要对连续值特征进行离散化处理。
分箱的重要性及其优势:
-
离散特征的增加和减少都很容易,易于模型的快速迭代;
-
稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
-
离散化后的特征对异常数据有很强的鲁棒性;
比如一个特征是年龄>30是1,否则0。
如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
-
对于线性模型,表达能力受限;
单变量离散化为N个后,每个变量有单独的权重,相当于模型引入了非线性,能够提升模型表达能力,加大拟合;
-
离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
-
特征离散化后,模型会更稳定;
比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。
当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
-
特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险;
-
可以将缺失作为独立的一类带入模型;
-
将所有变量变换到相似的尺度上。
1.无监督分箱法
1)自定义分箱
自定义分箱,是指根据业务经验或者常识等自行设定划分的区间,然后将原始数据归类到各个区间中。
2)等距分箱
定义
按照相同宽度将数据分成几等份。
从最小值到最大值之间,均分为 N 等份, 这样, 如果 A,B 为最小最大值, 则每个区间的长度为 W=(B−A)/N , 则区间边界值为A+W,A+2W,….A+(N−1)W 。这里只考虑边界,每个等份里面的实例数量可能不等。
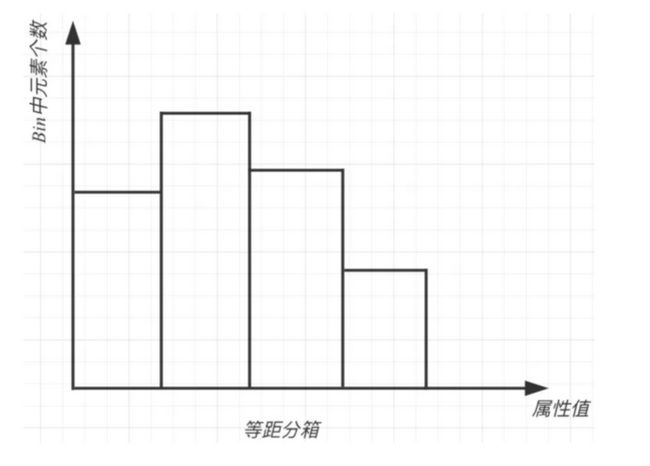
缺点是受到异常值的影响比较大
实现程序
import pandas as pd
df = pd.DataFrame([[22,1],[13,1],[33,1],[52,0],[16,0],[42,1],[53,1],[39,1],[26,0],[66,0]],columns=['age','Y'])
df['age_bin_2'] = pd.cut(df['age'],3) #新增一列存储等距划分的分箱特征
display(df)
# 输出
age Y age_bin
0 22 1 (12.947, 30.667]
1 13 1 (12.947, 30.667]
2 33 1 (30.667, 48.333]
3 52 0 (48.333, 66.0]
4 16 0 (12.947, 30.667]
5 42 1 (30.667, 48.333]
6 53 1 (48.333, 66.0]
7 39 1 (30.667, 48.333]
8 26 0 (12.947, 30.667]
9 66 0 (48.333, 66.0]3)等频分箱
定义
将数据分成几等份,每等份数据里面的个数是一样的。
区间的边界值要经过选择,使得每个区间包含大致相等的实例数量。比如说 N=10 ,每个区间应该包含大约10%的实例。

实现程序
import pandas as pd
df = pd.DataFrame([[22,1],[13,1],[33,1],[52,0],[16,0],[42,1],[53,1],[39,1],[26,0],[66,0]],columns=['age','Y'])
df['age_bin_1'] = pd.qcut(df['age'],3) #新增一列存储等频划分的分箱特征
display(df)
# 输出
age Y age_bin
0 22 1 (12.999, 26.0]
1 13 1 (12.999, 26.0]
2 33 1 (26.0, 42.0]
3 52 0 (42.0, 66.0]
4 16 0 (12.999, 26.0]
5 42 1 (26.0, 42.0]
6 53 1 (42.0, 66.0]
7 39 1 (26.0, 42.0]
8 26 0 (12.999, 26.0]
9 66 0 (42.0, 66.0]4)聚类分箱
定义
基于k均值聚类的分箱:k均值聚类法将观测值聚为k类,但在聚类过程中需要保证分箱的有序性:第一个分箱中所有观测值都要小于第二个分箱中的观测值,第二个分箱中所有观测值都要小于第三个分箱中的观测值,等等。
实现步骤
-
Step 0:
对预处理后的数据进行归一化处理;
-
Step 1:
将归一化处理过的数据,应用k-means聚类算法,划分为多个区间:
采用等距法设定k-means聚类算法的初始中心,得到聚类中心;
-
Step 2:
在得到聚类中心后将相邻的聚类中心的中点作为分类的划分点,将各个对象加入到距离最近的类中,从而将数据划分为多个区间;
-
Step 3:
重新计算每个聚类中心,然后重新划分数据,直到每个聚类中心不再变化,得到最终的聚类结果。
实现代码
from sklearn.cluster import KMeans
kmodel=KMeans(n_clusters=k) #k为聚成几类
kmodel.fit(data.reshape(len(data),1))) #训练模型
c=pd.DataFrame(kmodel.cluster_centers_) #求聚类中心
c=c.sort_values(by=’列索引') #排序
w=pd.rolling_mean(c,2).iloc[1:] #用滑动窗口求均值的方法求相邻两项求中点,作为边界点
w=[0] +list(w[0] + [ data.max() ] #把首末边界点加上
d3= pd.cut(data,w,labels=range(k)) #cut函数5)二值化(Binarization)
定义
二值化可以将数值型(numerical)的feature进行阀值化得到boolean型数据。这对于下游的概率估计来说可能很有用(比如:数据分布为Bernoulli分布时)。
公式
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式如下:

实现代码
from sklearn.preprocessing import Binarizer
# Binarizer函数也可以设定一个阈值,结果数据值大于阈值的为1,小于阈值的为0
binarizer = Binarizer(threshold=0.0).fit(X_train)
binarizer.transform(X_train)2.有监督分箱法
1)卡方分箱法
定义
自底向上的(即基于合并的)数据离散化方法。它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
基本思想
对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
实现步骤
-
Step 0:
预先定义一个卡方的阈值;
-
Step 1:
初始化;
根据要离散的属性对实例进行排序,每个实例属于一个区间; -
Step 2:
合并区间;
-
计算每一对相邻区间的卡方值;
-
将卡方值最小的一对区间合并;
-

Aij:第i区间第j类的实例的数量;Eij:Aij的期望频率(=(Ni*Cj)/N),N是总样本数,Ni是第i组的样本数,Cj是第j类样本在全体中的比例;阈值的意义
类别和属性独立时,有90%的可能性,计算得到的卡方值会小于4.6。大于阈值4.6的卡方值就说明属性和类不是相互独立的,不能合并。如果阈值选的大,区间合并就会进行很多次,离散后的区间数量少、区间大。
注意
-
ChiMerge算法推荐使用0.90、0.95、0.99置信度,最大区间数取10到15之间;
-
也可以不考虑卡方阈值,此时可以考虑最小区间数或者最大区间数。
指定区间数量的上限和下限,最多几个区间,最少几个区间;
-
对于类别型变量,需要分箱时需要按照某种方式进行排序。
实现代码
https://github.com/tatsumiw/ChiMerge/blob/master/ChiMerge.py
2)最小熵法分箱
需要使总熵值达到最小,也就是使分箱能够最大限度地区分因变量的各类别。
熵是信息论中数据无序程度的度量标准,提出信息熵的基本目的是找出某种符号系统的信息量和冗余度之间的关系,以便能用最小的成本和消耗来实现最高效率的数据存储、管理和传递。
数据集的熵越低,说明数据之间的差异越小,最小熵划分就是为了使每箱中的数据具有最好的相似性。给定箱的个数,如果考虑所有可能的分箱情况,最小熵方法得到的箱应该是具有最小熵的分箱。
0x0FF 总结
-
特征预处理是数据预处理过程的重要步骤,是对数据的一个的标准的处理,几乎所有的数据处理过程都会涉及该步骤。
-
我们对特征进行分箱后,需要对分箱后的每组(箱)进行woe编码和IV值的计算,通过IV值进行变量筛选后,然后才能放进模型训练。
-
分箱后需要进行特征编码,如:
LabelEncode、OneHotEncode或LabelBinarizer等。
如有错误欢迎指正~
参考文献
[1] sklearn中的数据预处理. http://d0evi1.com/sklearn/preprocessing/
[2] 归一化与标准化. https://ssjcoding.github.io/2019/03/27/normalization-and-standardization/
[3] Preprocessing Data : 類別型特徵_OneHotEncoder & LabelEncoder 介紹與實作. https://medium.com/ai%E5%8F%8D%E6%96%97%E5%9F%8E/preprocessing-data-onehotencoder-labelencoder-%E5%AF%A6%E4%BD%9C-968936124d59
[4] 特征工程之分箱. https://blog.csdn.net/Pylady/article/details/78882220
[6] https://www.leiphone.com/news/201801/T9JlyTOAMxFZvWly.html