B1_Python常见的数据类型详解
文章目录
-
- 数据类型分类
-
- 1. 根据数据表达的内容进行分类
- 2. 根据可变和不可变进行分类
-
- 不可变数据类型
- 可变数据类型
- 数据类型用法详解
-
- Number 类型
-
- 1. 常用的Number类型说明
- 2. 进制说明和转换
- 3. 二进制的位宽(位数)的两种求解方式
- 4. 浮点类型float常用操作
- 5. 关于数字类型常用的数学函数
- Bool 布尔数据类型
-
- 1. 布尔数据类型说明
- 2. 布尔数据类型和其他数据类型之间的转换
- 字符串 String
-
- 1. 字符串数据类型说明
- 2.创建字符串的三种方式
- 3. 字符串的转义以及格式化
- 4. 字符串的访问和切片操作
- 5.字符串的判断操作
- 6. 字符串的空格操作
- 7. 字符串拼接
- 8. 字符串拆分
- 9. 字符串的查找和替换
- 10.字符串变换
- 元组(tuple)
-
- 1. 元组数据类型说明
- 2. 创建元组
- 3.访问元组
- 4.删除元组
- 5.元组的连接和复制
- 6.元组的其他内置函数操作
- 列表(list)
-
- 1. 列表数据类型
- 2. 列表的访问
- 3. 列表的常见操作
- 集合(set 和 frozenset)
-
- 1. 集合数据类型说明
- 2. 常见的集合操作符号说明
- 2. 集合的创建
- 3. 集合常见操作
- 4. 集合遍历和推导式
- 字典(dict)
-
- 1. 字典数据类型说明
- 2. 字典的创建方式
- 3. 字典增加元素
- 4. 字典删除元素
- 5. 访问字典
数据类型分类
1. 根据数据表达的内容进行分类
- 数字类型(
number) - 字符串类型(
str) - 布尔类型(
bool) - 元组(
tuple) - 列表(
list) - 集合(
set) - 字典(
dict)
2. 根据可变和不可变进行分类
不可变数据类型
-
什么是不可变数据类型?
指的是数据类型对象所指定内存中的值不可以被改变,不可以就地修改值.
也就是说不可变的数据类型,如果要改变变量的值,或者是某个对象的值的时候,就是要重新创建一个
变量,计算机会重新开辟出一个内存空间来存储新的值,不会在原来的内存位置进行修改 -
Python中的不可变数据类型
number数字bool布尔string字符串tuple元组
可变数据类型
-
什么是可变数据类型?
该数据类型的对象所在的内存空间上的值可以被改变,可以就地修改值
对象的值(变量)被改变以后,其所指向的内存地址上的对应的值直接被改变,没有发生复制,也不用开辟
新的内存地址来存储新的值 -
Python中的可变数据类型
-
List列表 -
Set集合 -
Dict(字典)
数据类型用法详解
Number 类型
1. 常用的Number类型说明
整型(int)
不带小数点的整数,python3的整型是没有限制大小的,可以当作long类型来使用,python3中不再有long类型
浮点型(float)
浮点型由整数部分和小数部分组成,浮点型也可以用科学计数法表示(2.5e^2 = 2.5 * 10 ^ 2 = 250)
复数(complex)
复数由实数部分和虚数部分构成,可以使用a+bj,或者complex(a,b)表示,复数的实数部分a和虚数部分b
都是浮点类型
- 示例代码
intNumber = 123 # int
print(type(intNumber), intNumber)
floatNumber = 123.456 # float
print(type(floatNumber), floatNumber)
complexNumber = 3 + 5j # complex
print(type(complexNumber), complexNumber)
- 运行结果
<class 'int'> 123
<class 'float'> 123.456
<class 'complex'> (3+5j)
-
还可以使用0x or 0X 后者 0o 0O 来表示16进制和8进制的数据 -
示例代码
decNumber = 123
hexNumber = 0x123
octNumber = 0o123
print(type(decNumber),decNumber)
print(type(hexNumber),hexNumber)
print(type(octNumber),octNumber)
- 运行结果
<class 'int'> 123
<class 'int'> 291
<class 'int'> 83
2. 进制说明和转换
b:二进制 -> bin()o:八进制 -> oct()d:十进制 -> int()h:十六进制 -> hex()
- 代码示例
numberDec = 100
numberBin = bin(numberDec) # 转换为二进制
numberOct = oct(numberDec) # 转换为八进制
numberHex = hex(numberDec) # 转换为十六进制
print("numberBin: {},type(numberBin): {}".format(numberBin, type(numberBin)))
print("numberOct: {},type(numberOct): {}".format(numberOct, type(numberOct)))
print("numberHex: {},type(numberHex): {}".format(numberHex, type(numberHex)))
- 运行结果
numberBin: 0b1100100,type(numberBin): <class 'str'>
numberOct: 0o144,type(numberOct): <class 'str'>
numberHex: 0x64,type(numberHex): <class 'str'>
注意: bin() oct() hex() 的返回类型都是字符串,不是直接的数字或者是其他的类型,返回的是字符串
- 其他的进制转换为十进制
# 注意这里的结果,并且要知道是为什么 str(numberBin) != "0b1100100"
# str() 在计算的时候,会先将里面的0b或者是0x后者是0o的字符串转换为十进制再进行str()
number1 = int(str(numberBin),2)
number2 = int(str(numberOct),8)
number3 = int(str(numberHex),16)
print("number1: {},type(number1): {}".format(number1, type(number1)))
print("number2: {},type(number2): {}".format(number2, type(number2)))
print("number3: {},type(number3): {}".format(number3, type(number3)))
# 正确的写法是
numberBin = "0b1100100"
numberOct = "0o144"
numberHex = "0x64"
number1 = int(str(numberBin),2)
number2 = int(str(numberOct),8)
number3 = int(str(numberHex),16)
print("number1: {},type(number1): {}".format(number1, type(number1)))
print("number2: {},type(number2): {}".format(number2, type(number2)))
注意: str(0x64) 的结果是 ""100"",而不是"ox64",其他的进制情况是一样的,也就是说str()在转换数字类型字符串的时候, 如果数字类型不是十进制的,会先转换为十进制,然后再转换为十进制的字符串
3. 二进制的位宽(位数)的两种求解方式
-
1. 使用len(bin(number))的方式 -
2. 使用number内置函数bit_length()的方式 -
实例代码
number = 256
# 注意去除掉前面的两个0b,因为是0的时候0b0,如果是负数的时候,其表达式是-0b所以要从3的位置截取
bitLength1 = len(bin(number)[2:]) if number > 0 else len(bin(number)[3:])
bitLength2 = number.bit_length()
print("bitLength1: {},bitLength2: {}".format(bitLength1,bitLength2))
- 运行结果
bitLength1: 9,bitLength2: 9
4. 浮点类型float常用操作
-
as_integer_ratio()返回元组(x,y),number = k, number.as_integer_ratio() ==> (x,y) x / y = k
-
hex()以十六进制表示浮点数
-
fromhex()将十六进制小数以字符串输入,返回十进制小数
-
is_integer()判断小数是不是整数,比如3.0为一个整数,而3.000001不是,返回布尔值
- 代码示例
numberFloat = 0.25
(x, y) = numberFloat.as_integer_ratio()
numberFloatHex = numberFloat.hex()
numberFloat = float.fromhex("0x1.0000000000000p-2")
numberFloat1 = 3.00001
numberFloat2 = 3.0
isInteger1 = numberFloat1.is_integer()
isInteger2 = numberFloat2.is_integer()
print("{} / {} = {}".format(x, y, numberFloat))
print("0.25_hex(): {}".format(numberFloatHex))
print("numberFloatFromHex: {}".format(numberFloat))
print("{} is_integer: {}, {} is_integer: {}".format(
numberFloat1, isInteger1, numberFloat2, isInteger2))
- 运行结果
1 / 4 = 0.25
0.25_hex(): 0x1.0000000000000p-2
numberFloatFromHex: 0.25
3.00001 is_integer: False, 3.0 is_integer: True
5. 关于数字类型常用的数学函数
-
abs(x)返回数字的绝对值,例如abs(-3) = 3
-
ceil(x)返回一个浮点数的向上取整结果,例如: math.ceil(1.0003) = 2,这里注意是负数的情况
math.ceil(-2.3334) = -2,不是-3 -
floor(x)返回一个浮点数的向下取整结果,例如: math.floor(1.988) = 1 ,负数是一样的道理,
floor取的是小整数,math.floor(-2.33334)=-3,这里不是-2 -
round(x,n)四舍五入保留小数点后n位.例如round(2.35763,2) = 2.36
-
exp(x)e^x 次方,e的x次幂,例如exp(10) = e ^ 10
-
fabs(x)求float数据的整数部分.例如: math.fabs(2.345) = 2
-
log(x,n)以n为底数的logx值. 例如: log(2,3) = log2^3
-
modf(x)返回float的小数部分和整数部分,注意小数部分在前,整数部分在后
例如: math.modf(2.34567) = (0.34567,2) -
pow(x,y)计算xy的结果并返回,等同于xy,即 x的y次幂,例如pow(2,3) = 2 ** 3 = 8
-
sqrt(x)计算x的算术平方根,例如sqrt(9) = 3
- 代码示例
x = -2.435123
y = 1.2345
print("abs(x): {}".format(abs(x)))
print("ceil(x): {}".format(math.ceil(x))) # 向上取整数,注意负数的时候,也是取最大值,比如-3. 多的ceil() 为-3
print("ceil(y): {}".format(math.ceil(y)))
print("floor(x): {}".format(math.floor(x))) # 向下取整数
print("round(x,n): {}".format(round(x,2))) # 四舍五入保留小数点后几位
print("exp(x): {}".format(math.exp(x))) # e^x
print("fabs(x): {}".format(math.fabs(x))) # 求整数部分的绝对值
print("log(y): {}".format(math.log(y,10)))
print("log10(y): {}".format(math.log10(y)))
print("modf(x): {}".format(math.modf(x))) # 返回小数部分和整数部分,整数部分在后,小数部分在前,返回的是一个元组
print("pow(2,6): {}".format(pow(2,6))) # x ** y 运算后的值
- 运行结果
abs(x): 2.435123
ceil(x): -2
ceil(y): 2
floor(x): -3
round(x,n): -2.44
exp(x): 0.08758697318777672
fabs(x): 2.435123
log(y): 0.09149109426795106
log10(y): 0.09149109426795106
modf(x): (-0.4351229999999999, -2.0)
pow(2,6): 64
sqrt(9): 3.0
Bool 布尔数据类型
1. 布尔数据类型说明
- 代码示例
boolValF = False
boolValT = True
print("boolValF: {},type(boolValF): {}".format(boolValF, type(boolValF)))
print("boolValT: {},type(boolValT: {})".format(boolValT, type(boolValT)))
# bool类型本质上保存的还是一个数字int,False = 0,True = 1
print("int(False): {},int(True): {}".format(int(False),int(True)))
print("0 == False: {},1 == True: {}".format(False == 0,True == 1))
- 运行结果
boolValF: False,type(boolValF): <class 'bool'>
boolValT: True,type(boolValT: <class 'bool'>)
int(False): 0,int(True): 1
0 == False: True,1 == True: True
2. 布尔数据类型和其他数据类型之间的转换
- bool 类型和其他的数据类型之间的转换
bool -> int 说明: bool上的True 和 False,本质上就是1和0, bool -> int int(True) = 1,int(False) = 0
int -> bool 说明: bool(0) = False else bool(!0) = True
bool -> str 说明: str(True) or str(False),会先将True或者False转换为int,然后将int转换为str
str -> bool 说明: bool(str) = True if str != “” else False
- 代码示例
print("int(True): {},int(False): {}".format(int(True),int(False)))
print("bool(1): {},bool(0): {},bool(-1): {}".format(bool(1),bool(0),bool(-1)))
print("str(False): {},str(True): {}".format(str(False),str(True)))
print("bool(''): {},bool(' '): {}".format(bool(""),bool(" ")))
- 运行结果
int(True): 1,int(False): 0
bool(1): True,bool(0): False,bool(-1): True
str(False): False,str(True): True
bool(''): False,bool(' '): True
字符串 String
1. 字符串数据类型说明
字符串就是把一些字符,包括数字,字母,标点符号,特殊字符等串起来的数据.字符串是一个不可变的数据
类型,无论对字符串执行何种操作,源字符串的值都不会改变,会创建一个新的字符串来保存改变后的结果,例如:
s = "a c d ".strip(), 在python中,没有单字符的概念,单字符也是一个字符串.
2.创建字符串的三种方式
单引号('abc')双引号("abc")三引号(""" abc """)
- 说明
这三种方式都可以创建字符串,并且单引号里面可以包裹双引号,双引号里面也可以包裹单引号.
被包裹的单引号或者双引号,会被当成普通的字符,不会再当成是字符串的标识符号
三引号里面如果有回车换行符,会被当场一个\n换行符号
- 代码示例
"""
创建字符串的几种方式
"""
s1 = 'Fioman And Hammer'
s2 = "Fioman And Hammer"
s3 = """
我是一只小小鸟,
想要飞,怎么也飞不高,
因为"热爱",所以才会这么'认真'
"""
s4 = "Fioman 'And' Hammer"
s5 = 'Fioman "And" Hammer'
print(s1)
print(s2)
print(s3)
print(s4)
print(s5)
- 运行结果
Fioman And Hammer
Fioman And Hammer
我是一只小小鸟,
想要飞,怎么也飞不高,
因为"热爱",所以才会这么'认真'
Fioman 'And' Hammer
Fioman "And" Hammer
3. 字符串的转义以及格式化
python的转义字符,当使用到特殊字符的时候,Python使用反斜杠()转义字符.
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \’ | 单引号 |
| \" | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如: \o12代表换行 |
| \xyy | 十六进制数,yy代表字符,例如\x0a达标换行 |
| \other | 其他的字符以普通格式输出 |
- 代码示例
s1 = "D: \three\two\one\now\rest"
# 如果直接打印的话,就不行,里面包含了转义字符
print(s1)
# 怎么让它打印的结果,让转义字符失效呢,第一个就是在转义字符串前面增加一个反斜杠
s2 = "D: \\three\\two\one\\now\\rest"
print(s2)
# 第二种方式就是在字符画前面加一个r或者R,r表示就是源字符串,忽略掉字符串的额转义|
s3 = r"D: \three\two\one\now\rest"
print(s3)
- 运行结果
D: hree wo\one
est
D: \three\two\one\now\rest
D: \three\two\one\now\rest
4. 字符串的访问和切片操作
-
索引
索引就是下标,从0开始. s = “0123456789”. s[0] = 0,s[9] = 9,s[-1] = 9,s[-2] = 8
-
切片
可以使用下标来截取字符串的部分子串内容
语法: str[start:end :offset] offset 代表步长,默认不给的话就是取值1
- 代码示例
# 索引访问
s = "0123456789"
print(s[0], s[1], s[9], s[-1], s[-2])
# 切片
s1 = s[:2]
s2 = s[1:2]
s3 = s[:8:2] # [0,8) 每隔两个取一个字符
s4 = s[::4] # [0,9] 每隔4个取一个字符
s5 = s[1:10:3] # [1,10) 每隔三个取一个字符
s6 = s[-1:-9:-2] # 倒着取,步长是负的时候,表示往前走
s7 = s[-5:-9:-1] # 步长是负的才行
s8 = s[-5:-9:1] # 如果步长是正的,表示从-5开始,往-9正着走.下一步就是-4,-3,不在这个范围内.所以返回空串
print("s[:] = {}".format(s))
print("s[:2] = {}".format(s1))
print("s[1:2] = {}".format(s2))
print("s[:8:2] = {}".format(s3))
print("s[::4] = {}".format(s4))
print("s[1:10:3] = {}".format(s5))
print("s[-1:-9:-2] = {}".format(s6))
print("s[-5:-9:-1] = {}".format(s7))
print("s[-5:-9:1] = {}".format(s8))
- 运行结果
0 1 9 9 8
s[:] = 0123456789
s[:2] = 01
s[1:2] = 1
s[:8:2] = 0246
s[::4] = 048
s[1:10:3] = 147
s[-1:-9:-2] = 9753
s[-5:-9:-1] = 5432
s[-5:-9:1] =
5.字符串的判断操作
-
in 方法判断某个字符串是否存在目标字符串中.例如:s=“abcdefgh” “a” in s = True “z” in s = False
-
not in 方法和in方法的返回结果相反
-
is 方法 和 ==is判断内存地址是否相同,比较两个字符串是不是指向同一块内存地址
== 是用来判断两个字符串的内容是否相同 -
endswidth("s")判断字符串是否以"s"结尾,可以用来判断某个文件的类型,比如txt或者是图片bmp
-
isalnum()判断输入的字符串是否包含数字或字母,就是包含字母或者数字的时候才返回True,否则返回False
-
isalpha()判断输入的字符串是英文字母,如果全部是英文字母,返回True,否则返回False
-
isdigit()判断输入的字符串是否都是数字
-
islower()是否是小写字母.如果全部是小写,返回True,否则返回False
-
isupper()是否是大写字母.如果全部是大写,返回True,否则返回False
- 代码示例
s = "I learned in life that you have to take the hard knocks the way they are "
s1 = "I learned in life that you have to take the hard knocks the way they are "
isIn = "life" in s
isNotIn = "life" not in s
print(s)
print("life in s: {}".format(isIn))
print("life not in s: {}".format(isNotIn))
print("s is s1: {}".format(s is s1))
print("s == s1: {}".format(s == s1))
print("id(s) == id(s1): {}".format(id(s) == id(s1)))
s2 = "test.bmp"
print("s2.endwidths('bmp'): {}".format(s2.endswith(".bmp")))
s3 = "abc123"
s4 = "abc"
s5 = "123"
print("s3.isalnum(): {}".format(s3.isalnum())) # 是否是字母或者数字
print("s4.isalnum(): {}".format(s4.isalnum())) # 是否是字母或者数字
print("s5.isalnum(): {}".format(s5.isalnum())) # 是否是字母或者数字
print("{}.isalpha(): {}".format(s3,s3.isalpha()))
print("{}.isalpha(): {}".format(s4,s4.isalpha()))
print("{}.isdigit(): {}".format(s3,s3.isdigit()))
print("{}.isdigit(): {}".format(s5,s5.isdigit()))
s6 = "ABc"
s7 = "ABC"
s8 = "abc"
print("{}.islower(): {}".format(s6,s6.islower()))
print("{}.islower(): {}".format(s8,s8.islower()))
print("{}.isupper(): {}".format(s6,s6.isupper()))
print("{}.isupper(): {}".format(s7,s7.isupper()))
- 运行结果
I learned in life that you have to take the hard knocks the way they are
life in s: True
life not in s: False
s is s1: True
s == s1: True
id(s) == id(s1): True
s2.endwidths('bmp'): True
s3.isalnum(): True
s4.isalnum(): True
s5.isalnum(): True
abc123.isalpha(): False
abc.isalpha(): True
abc123.isdigit(): False
123.isdigit(): True
ABc.islower(): False
abc.islower(): True
ABc.isupper(): False
ABC.isupper(): True
6. 字符串的空格操作
-
lstrip()默认去除掉字符串左边的空格和换行.例如:" ab cd efg ".lstrip() = "ab cd efg "
-
rstrip()默认去除掉字符串右边的空格和换行.例如: "hello ".rstrip() = “hello”
-
strip()默认去除掉字符串两边的空格和换行. 例如: " Hello World! ".strip() = “Hello World!”
-
strip("m")去除掉两端(注意是两端,如果两端没有,就不去除)指定的字符m,例如: “momnet.strip(“m”) = omnet”
- 代码示例
s = " Hello World "
s1 = "Hello World"
print("{}.lstrip(): \n{}".format(s,s.lstrip()))
print("{}.rstrip(): \n{}".format(s,s.rstrip()))
print("{}.strip() : \n{}".format(s,s.strip()))
print("{}.strip('H'): \n{}".format(s1,s1.strip("H")))
- 运行结果
Hello World .lstrip():
Hello World
Hello World .rstrip():
Hello World
Hello World .strip() :
Hello World
Hello World.strip('H'):
ello World
7. 字符串拼接
-
%号进行拼接("%s %s"%("Fioman","Hammer"))类似的占位符%s是一个占位符,它仅代表是一段字符串,并不是拼接的实际内容.拼接的实际内容
在一个单独的%号后面,放在一个元组里面.
类似的占位符还有: %d(代表一个整数), %f(代表一个浮点数), %x(代表一个十六机制数)
- 代码示例
s1 = "%s:%d:%f:%x" % ("a", 1, 2.32, 0x123)
print(s1)
- 运行结果
a:1:2.320000:123
format()拼接方式
采用{}进行站位,如果{}里面是缺省的,后面就是默认一一对应,如果{}里面有数字,则是按照数字进行对位.
如果{}里面是变量名称,则按照变量名称进行对位
- 代码示例
s2 = "{} And {}".format("Fioman", "Hammer")
s3 = "{0} And {1} And {3} And {2}".format("Fioman", "Hammer","Good","Very")
s4 = "{Fioman} And {Hammer} And {Very} And {Good}".format(
Fioman="Fioman", Hammer="Hammer", Very="Very", Good="Good")
print(s2)
print(s3)
print(s4)
- 运行结果
Fioman And Hammer
Fioman And Hammer And Very And Good
Fioman And Hammer And Very And Good
() 类似元组方式
类似元组的方式,例如: (“a” “b”),注意和(“a”,“b”)的区别,后面是一个元组,前面是一个拼接字符串,
通过这种元组的字符串,不能拼接变量,必须全部都是字符串的使用才可以直接使用,灵活性太低,
不推荐使用
- 代码示例
t1 = ("Fioman","And","Hammer","Very","Good") # 这是一个元组
s1 = ("Fioman" " " "And" " " "Hammer" " " "Very" "Good") # 拼接后的字符串,会自动去除掉中间的空格
print(t1,type(t1))
print(s1,type(s1))
- 运行结果
('Fioman', 'And', 'Hammer', 'Very', 'Good') <class 'tuple'>
Fioman And Hammer VeryGood <class 'str'>
-
面向对象模板拼接Template先将s构建成一个Template模板对象,而后进行拼接
- 代码示例
from string import Template
s = Template("${s1} ${s2} ${s3} ${s4} ${s5} haha~~~~")
s = s.safe_substitute(s1="Fioman",s2="And",s3="Hammer",s4="Very",s5="Good")
print(s,type(s))
- 运行结果
Fioman And Hammer Very Good haha~~~~ <class 'str'>
常用的+号方式进行拼接字符串
- 代码示例
s1 = "The"
s2 = "World"
s3 = "Is"
s4 = "Beautiful"
s = s1 + " " + s2 + " " + s3 + " " + s4 + "!"
print(s)
- 运行结果
The World Is Beautiful!
-
joint拼接方式str对象自带的joint()方法,接收一个序列参数,可以实现拼接.拼接时,如果元素不是字符串,则需要先
转换一下.joint()前面的字符串,是在拼接的时候序列的两个元素之间连接的字符,这种方式适合按照
一定的格式或者是在拼接的时候插入固定的字符的时候进行使用
- 代码示例
strList =[s1,s2,s3,s4]
s5 = " ".join(strList)
s6 = "_".join(strList)
print(s5)
print(s6)
- 运行结果
The World Is Beautiful
The_World_Is_Beautiful
-
f-string方式和format类似,但是不再使用format的方式,而是直接f后面跟{},里面跟变量即可
例如: name1 = “Fioman” name2 = “Hammer” s = f"{name1} And {Name2}"
- 代码示例
name1 = "Fioman"
name2 = "Hammer"
s = f"{name1} And {name2} Is Very Excellent"
print(s)
- 运行结果
Fioman And Hammer Is Very Excellent
8. 字符串拆分
-
split()str.split(sep=None,maxsplit=-1) 根据界定符sep拆分为字符串列表.如果sep未提供或者是None
则按照空格作为定界符.在这种情况下,如果存在前导或者尾随空格,则不会反悔任何空字符串.
同样的,多个空格将被视为单个定界符.如果提供了maxsplit,则诸多完成maxsplit个拆分,(因此
,列表中最多包含maxsplit + 1个元素)如果未指定maxsplit或者指定位-1,则对拆分数没有限制,
并且所有的可能的拆分都将返回列表中
- 代码示例
s = " Hammer is Beautiful "
strList = s.split()
print(strList)
strList = s.split(maxsplit=2)
print(strList)
strList = s.split("i",maxsplit=1)
print(strList)
strList = s.split("is",maxsplit=1)
print(strList)
- 运行结果
['Hammer', 'is', 'Beautiful']
['Hammer', 'is', 'Beautiful ']
[' Hammer ', 's Beautiful ']
[' Hammer ', ' Beautiful ']
-
rsplit()rsplit()函数与split()函数非常的相似,唯一的区别就是rsplit是分割字符串的时候,从末尾开始
一直到最前面
- 代码示例
s = "我是一只小小鸟,想要飞却怎么也飞不高,飞啊飞也飞不高!"
strList1 = s.rsplit(",")
strList2 = s.rsplit(",",maxsplit=1)
strList3 = s.split(",",maxsplit=1)
print(strList1)
print(strList2)
print(strList3)
- 运行结果
['我是一只小小鸟', '想要飞却怎么也飞不高', '飞啊飞也飞不高!']
['我是一只小小鸟,想要飞却怎么也飞不高', '飞啊飞也飞不高!']
['我是一只小小鸟', '想要飞却怎么也飞不高,飞啊飞也飞不高!']
3.partition("s")
> 将字符串按照s进行分割,返回一个元组,包括目标字符串按照s分割的坐标的字符串,s字符串,和s后面的字符串.如果目标字符串中
没有s,则返回原来的字符串,后面跟两个空串
- 代码示例
s = "我是一只小小鸟,想要飞却怎么也飞不高,飞啊飞也飞不高!"
a = s.partition("小")
print(a,type(a))
b = s.partition("猛")
print(b,type(b))
- 运行结果
('我是一只', '小', '小鸟,想要飞却怎么也飞不高, 飞啊飞也飞不高!') <class 'tuple'>
('我是一只小小鸟,想要飞却怎么也飞不高, 飞啊飞也飞不高!', '', '') <class 'tuple'>
-
rpartition和partition功能是一样的,只是它是从目标字符串的右边进行分割
- 代码示例
s = "我是一只小小鸟,想要飞却怎么也飞不高,飞啊飞也飞不高!"
a = s.rpartition("飞")
print(a,type(a))
b =s.rpartition("猛")
print(b,type(b))
- 运行结果
('我是一只小小鸟,想要飞却怎么也飞不高,飞啊飞也', '飞', '不高!') <class 'tuple'>
('', '', '我是一只小小鸟,想要飞却怎么也飞不高,飞啊飞也飞不高!') <class 'tuple'>
9. 字符串的查找和替换
-
find(sub,start=None,end=None)在目标字符串中进行查找字符串的操作,从start开始,如果不填,默认是字符串的最坐标,end结束,如果不填
表示字符串最右边.从左边开始查找sub子串,如果存在则返回sub的索引,如果不存在返回-1 -
rfind(sub,start=None,end=None)同上,只是从右边开始查找
-
index()和find()功能类似,不同的地方是如果没有找到满足条件的子串,则报错
- 代码示例
s = "我是一只小小鸟,想要飞却怎么也飞不高,飞啊飞也飞不高!"
index1 = s.find("飞")
index2 = s.rfind("飞")
index3 = s.index("飞")
index4 = s.find("飞",22)
index5 = s.find("猛")
print("index(飞): {}".format(index1))
print("index(飞): {}".format(index3))
print("index(飞) from right: {}".format(index2))
print("index(飞) start_22,en_-1: {}".format(index4))
print("index('猛'): {}".format(index5))
- 运行结果
index(飞): 10
index(飞): 10
index(飞) from right: 23
index(飞) start_22,en_-1: 23
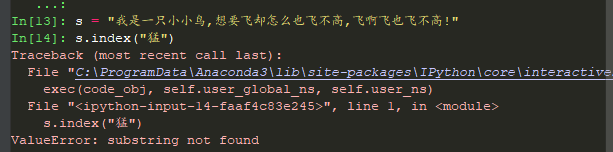
index('猛'): -1
如果使用index("猛")会直接报错
4. 字符串替换replace(old,new,times)
> replace函数,old参数传入要被替换的旧字符串,new为替换的新字符串,times表示替换的次数,如果
times不传入,默认替换掉所有old字符串
- 代码示例
s = "我是一只小小鸟,想要飞却怎么也飞不高,飞啊飞也飞不高!"
s1 = s.replace("飞","跑")
s2 = s.replace("飞","跑",2)
s3 = s.replace("猛","跑",2) # 如果要被替换的字符串不存在,就维持原来的字符串不变
print(s1)
print(s2)
print(s3)
- 运行结果
我是一只小小鸟,想要跑却怎么也跑不高,跑啊跑也跑不高!
我是一只小小鸟,想要跑却怎么也跑不高,飞啊飞也飞不高!
我是一只小小鸟,想要飞却怎么也飞不高,飞啊飞也飞不高!
10.字符串变换
-
lower()转换目标字符串的所有的大写字母为小写
-
upper()转换目标字符串的所有的小写字母为大写
-
capitalize()将字符串的第一个字母变成大写,其他的字母变成小写
-
swapcase()大小写进行转换,大写换成小写,小写换成大写
-
title()返回标题化的字符串,就是说所有单词都是大写开始,其余字母均为小写
-
center(width,fillchar)返回一个原字符串居中,并使用fillchar填充至长度width的新字符串,默认填充字符为空格
-
ljust(width,fillchar)返回一个原字符串左对齐,并使用fillchar填充至指定宽度的新字符串.默认为空格.如果指定的长度小于
原字符串的长度,则返回原字符串,注意如果需要填充,填充的字符在右边,左对齐指的是原字符串 -
rjust(width,fillchar)返回原字符串右对齐,并使用fillchar填充至长度为width的新字符串,如果指定的长度小于字符串的长度则
返回原字符串 -
zfill(width)返回指定长度的字符串,原字符串右对齐,前面(左边)填充0
-
expandtabs([tabsize])把字符串中tab符号("\t")转换为适当数量的空格,默认情况下是8个
- 代码示例
sUpper = "FIOMAN"
sLower = "fioman"
s = "FioMan"
s2 = "abc\t123"
print("{}.lower(): {}".format(sUpper,sUpper.lower()))
print("{}.upper(): {}".format(sLower,sLower.upper()))
print("{}.capitalize(): {}".format(sUpper,sUpper.capitalize()))
print("{}.swapcase(): {}".format(s,s.swapcase()))
print("{}.title(): {}".format(sLower,sLower.title()))
print("{}.center(10): {}".format(s,s.center(20)))
print("{}.center(10,*): {}".format(s,s.center(20,"*")))
print("{}.center(5,*): {}".format(s,s.center(5,"*")))
print("{}.ljust(10,*): {}".format(s,s.ljust(10,"*"))) # 填充右边
print("{}.rjust(10,*): {}".format(s,s.rjust(10,"*"))) # 填充左边
print("{}.zfill(10): {}".format(s,s.zfill(10))) # 前面填充0
print("{}.expandtabs(): {}".format(s2,s2.expandtabs()))
- 运行结果
FIOMAN.lower(): fioman
fioman.upper(): FIOMAN
FIOMAN.capitalize(): Fioman
FioMan.swapcase(): fIOmAN
fioman.title(): Fioman
FioMan.center(10): FioMan
FioMan.center(10,*): *******FioMan*******
FioMan.center(5,*): FioMan
FioMan.ljust(10,*): FioMan****
FioMan.rjust(10,*): ****FioMan
FioMan.zfill(10): 0000FioMan
abc 123.expandtabs(): abc 123
-
字符串过滤,将一些特殊字符显示为**,使用maketrans和tanslate在开发一些程序的时候,有一些词汇可能不能很好的显示,则这个时候,可以采用过滤的方式,将其转换为**马赛克的形式显示
maketrans(a,b) 替换表,将b替换为a,然后translate(m1).translate(m2),按照maketrans()生成的m1表和m2表去替换过滤掉
字符串,然后返回新的字符串
- 代码示例
wordsOriginal = "不要随便骂人是傻逼,那是一个非常垃圾的行为"
sensitiveStr1 = wordsOriginal.maketrans("傻逼","**")
sensitiveStr2 = wordsOriginal.maketrans("垃圾","**")
newWords = wordsOriginal.translate(sensitiveStr1).translate(sensitiveStr2)
print("newWords: {}".format(newWords))
- 运行结果
newWords: 不要随便骂人是**,那是一个非常**的行为
元组(tuple)
1. 元组数据类型说明
元组是一个不可变的序列,不可变就是元组里面的元素是不可以被修改的,序列就是代表元组也是一组有序的序列
2. 创建元组
有三种方法,创建一个元组
1> 直接用小括号()创建,中间用逗号隔开,注意如果只有一个元素,也要加上逗号.a = (2) 和 a = (2,)是不同的,
前者是一个数字int类型值为2,后者是一个只有一个元素的元组.
2> 使用逗号表达式进行创建 tun3 = 1,2,3
3> 使用tuple(seq) tuple() 根据seq这个序列创建一个元组,如果什么都不传入,tuple()表示创建一个空元组
- 代码示例
tup1 = (1,2,3)
tup2 = 1,2,3
tup3 = tuple([1,2,3])
print("tup1: {}".format(tup1))
print("tup2: {}".format(tup2))
print("tup3: {}".format(tup3))
# 创建空的元组
tup1 = ()
tup2 = tuple()
tup3 = (1,)
int1 = (1)
print("tup1: {}".format(tup1))
print("tup2: {}".format(tup2))
print("tup3: {}".format(tup3))
print("int1: {}".format(int1))
- 运行结果
tup1: (1, 2, 3)
tup2: (1, 2, 3)
tup3: (1, 2, 3)
tup1: ()
tup2: ()
tup3: (1,)
int1: 1
3.访问元组
可以通过下标的方式访问元组,和列表字符串一样,支持切片操作,但是不支持赋值操作,就是元组里面的元素是不可更改的
但是,如果元组里面的元素含有可变对象的时候,它里面的可变对象是可以被更改的
- 代码示例
tup = (1,2,3,4,5,6)
tup1 = tup[0]
tup2 = tup[2:4]
tup3 = [x for x in tup]
tup4 = (x for x in range(10)) # 这不是一个元组推导式,这是一个生成器表达式
print("tup[0]: {}".format(tup1))
print("tup[2:4]: {}".format(tup2))
print("for tup: {}".format(tup3))
print("tup4: {},type(tup4): {}".format(tup4,type(tup4)))
tup = ([1,2],3,4,5,6)
tup[0][0] = 100
tup[0][1] = 200
print(tup)
- 运行结果
tup[0]: 1
tup[2:4]: (3, 4)
for tup: [1, 2, 3, 4, 5, 6]
tup4: <generator object <genexpr> at 0x000002F82566E6D8>,type(tup4): <class 'generator'>
([100, 200], 3, 4, 5, 6)
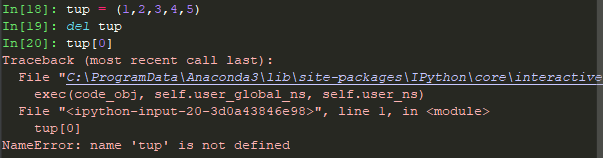
4.删除元组
元组中的元素是不可以被删除的,但是可以使用del语句来删除整个元组
5.元组的连接和复制
可以使用"+“和”"对元组进行组合连接和复制例如tup1 = (1,2) tup2 = (3,4),这tup1 + tup2 = (1,2,3,4)
tup12 = (1,2,1,2) tup2 * 4 = (3,4,3,4,3,4,3,4)
- 代码示例
tup1 = (1,2,3)
tup2 = (4,5,6)
tup3 = tup1 + tup2
tup4 = tup1 * 2
tup5 = tup2 * 3
print("{} + {} = {}".format(tup1,tup2,tup3))
print("{} * 2 = {}".format(tup1,tup4))
print("{} * 3 = {}".format(tup2,tup5))
- 运行结果
(1, 2, 3) + (4, 5, 6) = (1, 2, 3, 4, 5, 6)
(1, 2, 3) * 2 = (1, 2, 3, 1, 2, 3)
(4, 5, 6) * 3 = (4, 5, 6, 4, 5, 6, 4, 5, 6)
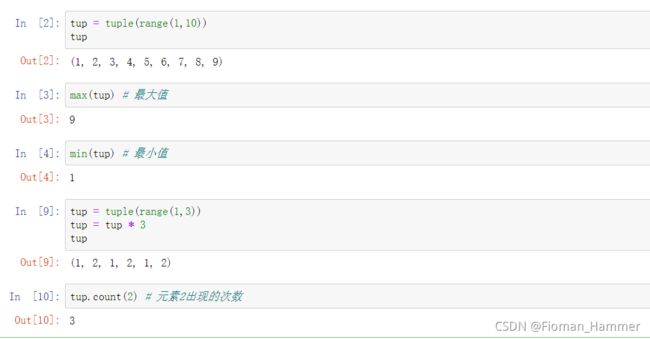
6.元组的其他内置函数操作
-
tuple(iter)

-
len(tup)返回元组元素的个数

-
max(tup) min(tup) count(x)返回元组的最大元素,最小元素,元素x出现的次数
-
for t in tup:遍历元组

列表(list)
1. 列表数据类型
列表是一个连续的,可以存储不同数据类型的一个容器,和Java的数组本质上的不同就是Python的列表的
元素可以是不同类型的元素.列表在存储上是连续的,如果添加了元素或者删除了元素,会自动的移动元
素的位置,使得它们之间是没有缝隙的,列表中存储的元素内容是可变的,支持索引,切片操作

2. 列表的访问
列表访问可以通过索引的方式进行访问,还可以通过切片的方式访问
索引操作(正值表示从前往后,负值表示从后往前)

切片操作,正向和负向的问题 lst[start:end:offset]

3. 列表的常见操作
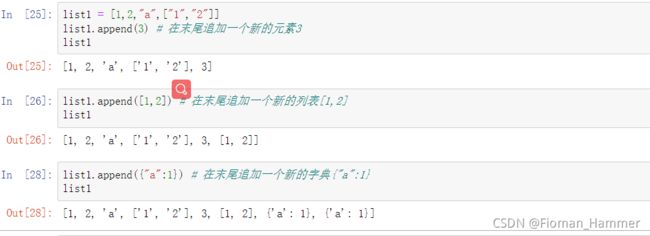
-
增加元素append() -> 列表的末尾增加新的元素,注意append(x)中的x会被当成一个元素,插入到原来的列表的后面
insert(index,elem) -> 在index的前面插入一个元素,如果是负数也是一样的,插入的元素一定是在lst[index]这个元素的前面
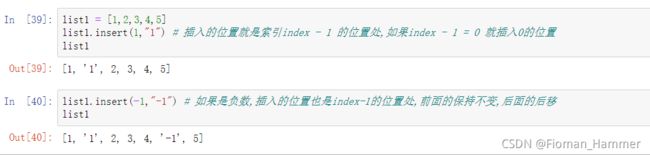
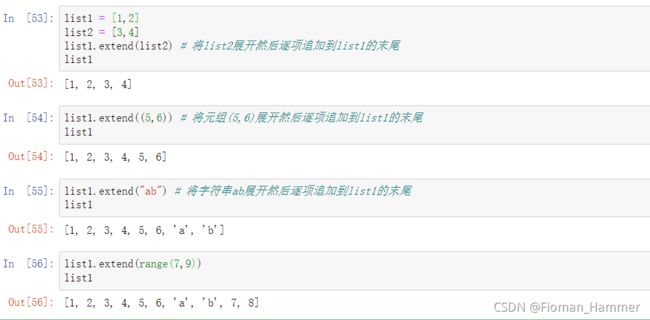
extend(iter),根据可迭代对象iter扩展原来的列表,iter展开,然后逐项增加到原来的列表当中
切片赋值 lst[start : end : offset],切片赋值的时候注意切片的长度,如果offset > 0,但是start >= end
就变成了插入,如果start < end,就是将切片的地方进行赋值替换. 如果offset < 0,但是start <= end,
就变成了插入,如果start > end,就是将切片的地方进行赋值替换.
也就是还说,如果你根据步长以及start和end,这个时候切片出来的内容是空列表,就变成了
insert(start,elem), 其他的时候就是 lst[slice] = element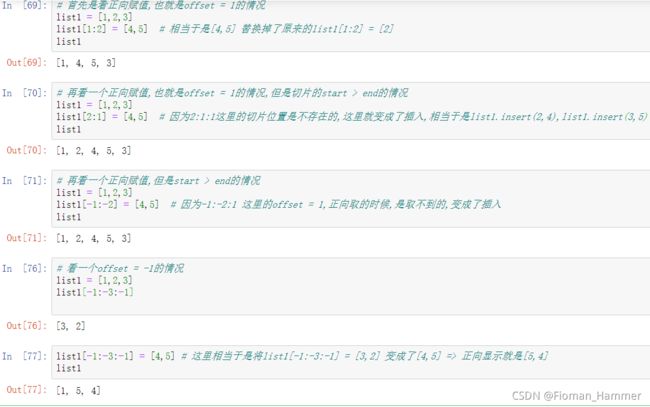
-
删除元素pop(index) 根据索引弹出删除元素,列表就地修改,返回弹出来的元素.如果index不给,默认是-1
弹出最后一个元素,如果index超限,报错
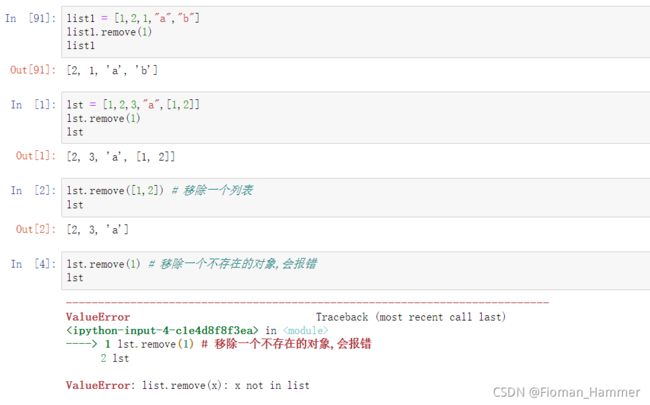
remove(obj) => 移除掉列表中存在的obj对象,返回None.如果obj不存在,则会报错
通过切片赋值的方式删除元素lst[start:end] = [],将一部分列表直接赋值为空,这里只针对offset>0的情况,如果offset<0,lst[start:end] 如果start < end 的时候,赋值为[]会报错
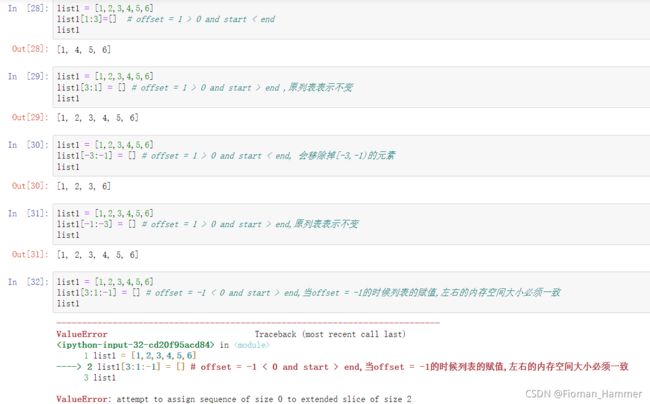
-
查找元素list.index(x[,start[,end]) x是查找的对象,起始位置,默认是0到len(list)-1,可不提供.
返回list列表中从start到end的第一个x元素的下标,如果不存在,则报错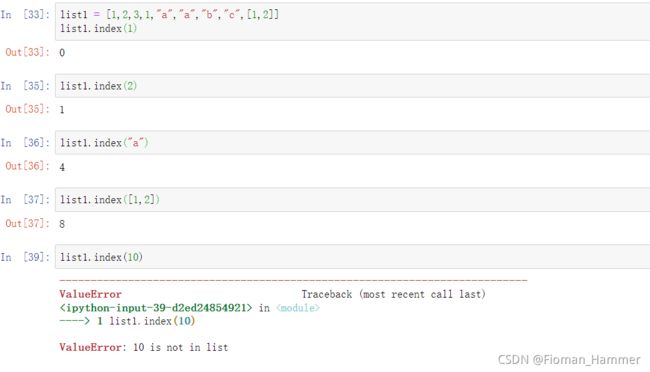
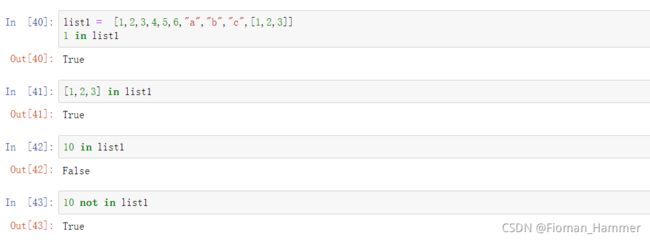
elem in lst: 元素elem是否在lst列表中 elem not in lst: 元素elem是否不再lst列表中
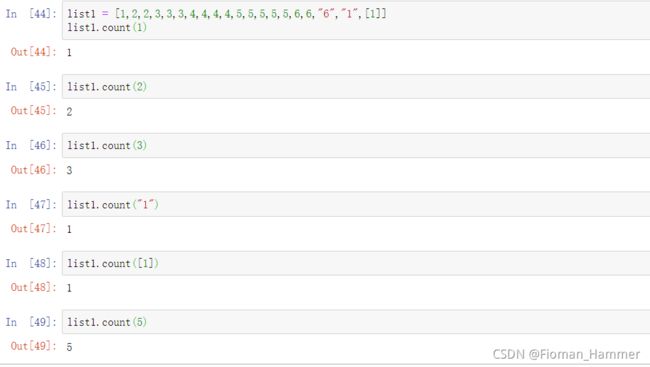
lst.count(x) 统计lst列表中x元素出现的次数,如果不存在返回0
-
列表排序lst.sort(key=None,reverse=False) 列表原地排序,默认是按照升序进行排列,不进行翻转
key可以自己制定排序的规则,一般可以使用lambda表达式
sorted(lst,key=None,reverse=False),对列表进行排序和sort的功能差不多,唯一的区别是这里会创建
一个新的列表用来存储排序后的结果,而原来的lst不变.而sort是在原来的列表上进行的就地排序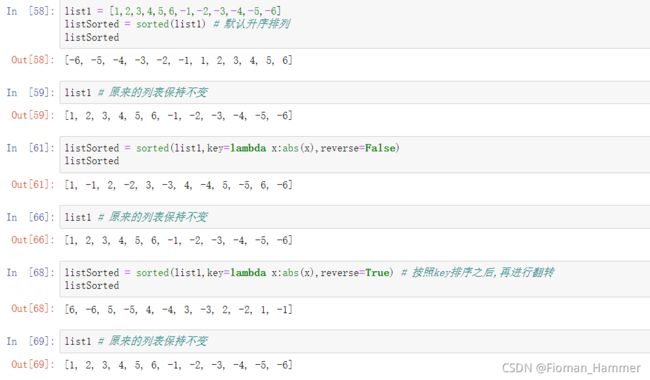
list.reverse() 列表翻转,返回值是None,就地修改原来的列表
reversed(lst) 列表翻转,返回值是列表翻转后的迭代器,这里翻转之后一般
加上list(reversed(list))将结果列表化
list[:,:-1] 通过切片的方式进行翻转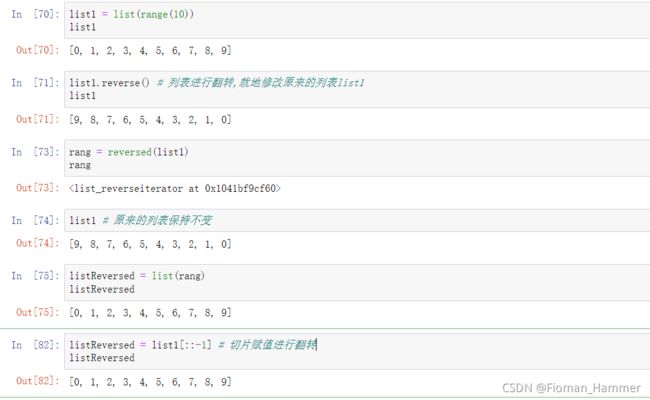
-
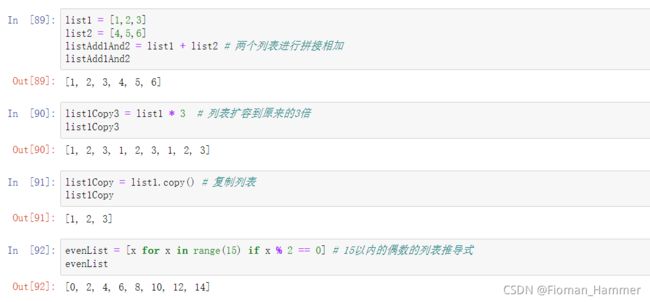
列表的拼接和复制以及列表推导式- 可以使用+号拼接两个列表,a + b,列表b的元素会展开逐项加到a列表的后面
- 使用*号复制列表 a ** 2 ,相当于是列表a会复制1分逐项增加到a列表的后面返回
- list.copy() 复制一个一模一样的列表进行返回
- list4 = [x for x in range(101) if x % 2 == 0] 列表推导式,存放100以内的正偶数
集合(set 和 frozenset)
1. 集合数据类型说明
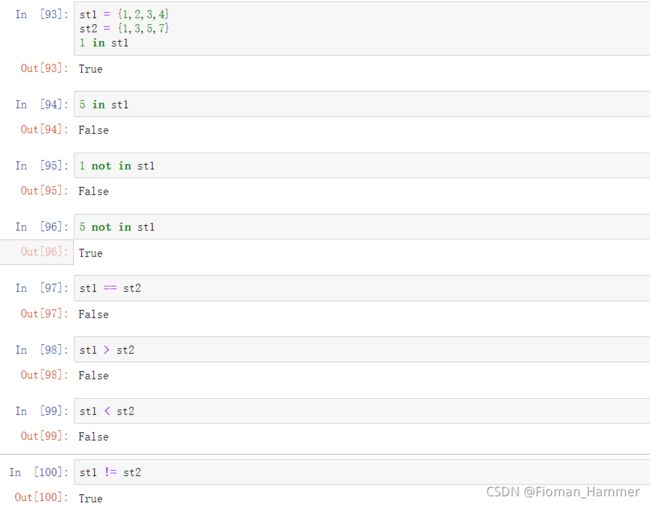
- 集合保存的是一组无序的可哈希的值,我们常说的集合(可变集合)本事是可变的,不可哈希的.
- 因为无序,所以集合可以用来去重,但是不可以索引访问,不可以切片
- 集合里面的元素保存的都是不可变的类型,是可哈希的,可以当作字典的键
- 集合支持 in 和 not in,count() 以及len()操作
- 集合本身是不可哈希的,不能作为集合的元素.但是不可变集合(frozen set)是可哈希的,可以作为集合的元素
2. 常见的集合操作符号说明
| 数学符号 | python符号 | 含义 |
|---|---|---|
| ∈ | in | 是 目标集合的成员 |
| ∉ | not in | 不是目标集合的成员 |
| = | == | 等于 两个集合具有相同的元素 |
| ≠ | != | 不等于 两个集合具有不完全相同的元素 |
| ⊂ | < | 是 … 的(严格)子集,不包含两个集合相等的情况 |
| ⊆ | <= | 是 … 的子集,包含两个集合相等的情况 |
| ⊃ | > | 是… 的(严格)超集,不包含两个集合相等的情况 |
| ⊇ | >= | 是 … 的超集,包含两个集合相等的情况 |
| ∩ | & | 交集 (两个集合相同的部分) |
| ∪ | ||
| - or \ | - | 差集或相对补集 a- b = a - a∩b |
| △ | ^ | 对称差分 a^b = a∪b - a∩b |

2. 集合的创建
- set() 创建一个空集合,注意不能直接使用st = {},这样创建的是一个字典
- set = {1,2,3} # 直接赋值的方式创建一个集合
- set(iter) # 根据一个可迭代对象创建集合,iter可以是另外一个集合,或者是列表,元组,字典,字符串

3. 集合常见操作
-
add 添加一个元素set.add(elment),是将element作为一个元素添加到原来的集合当中,不对element进行展开

-
update() 迭代更新原集合set.update(elment) => 和add不同的是,update会将element进行展开(如果是可迭代对象并且可以展开的话)
然后合并到set集合中去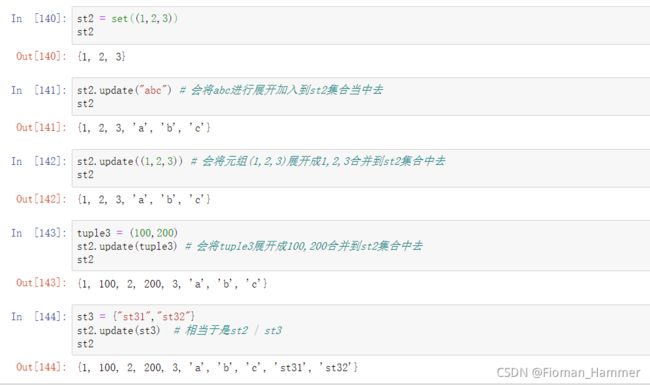
-
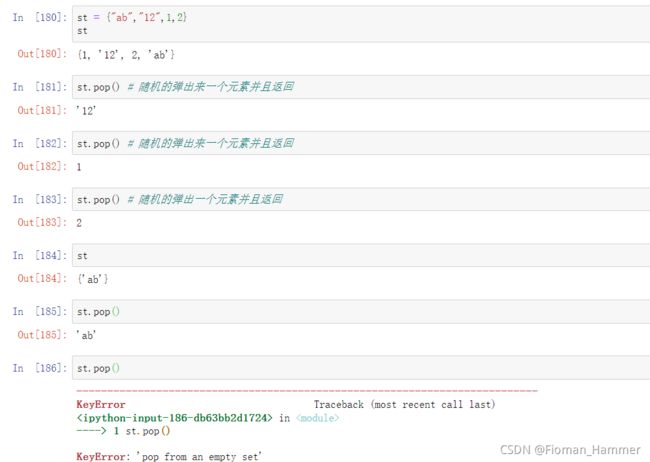
pop()随机的删除一个元素,如果集合本身为空,则报错
-
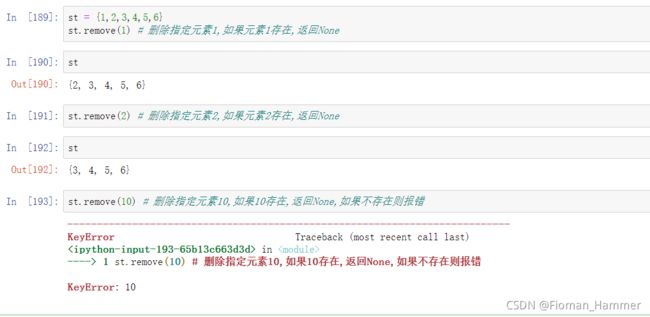
set.remove(elem)删除集合set中的指定元素,如果删除的元素不存在,则报错
-
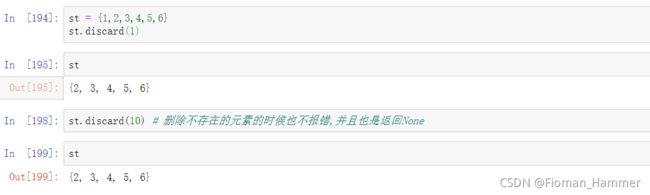
set.discard(elem)删除指定元素elem,和remove功能相同,唯一的区别就是discard(elem),如果elem不存在于集合中也不报错
-
set.clear()删除集合中所有的元素,原来的集合会变成一个空集合
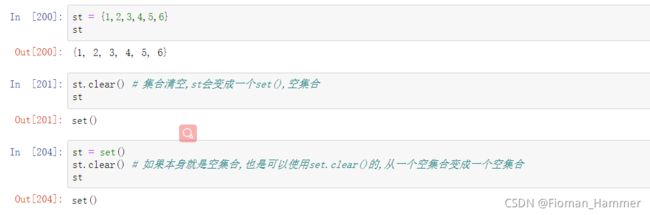
-
del set删除集合对象,删除之后整个set对象就不存在了,无法再进行访问
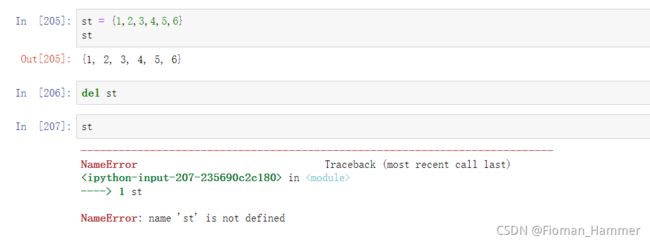
-
st1.intersection(st2) st1.intersection_update(st2)- st1.intersection(st2) 等同于st1 & st2,返回st1和st2的交集,不会改变st1和st2的值
- st1.intersection_update(st2) 等同于 st1 = st1 & st2,返回None,但是会将st1和st2的交集的结果赋值给st1,会改变st1的值

-
st1.union(st2)st1.union(st2) 等通过与 st1 | st2 返回st1 和 st2的并集,不会改变st1和st2的值
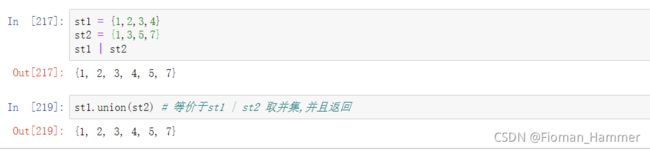
-
A.difference(B) 和 A.difference_update(B)- A.difference(B) 等同于A-B,计算A和B的差集,并返回.不改变A和B的值
- A.difference_update(B) 等同于 A = A - B,计算A和B的差集,并且赋值给A,返回None
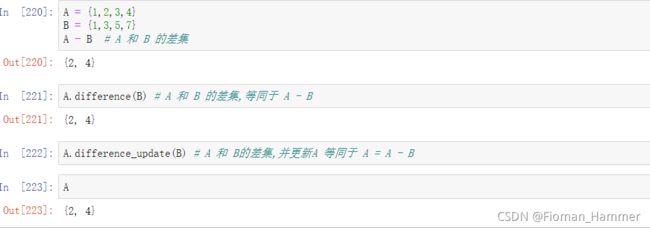
-
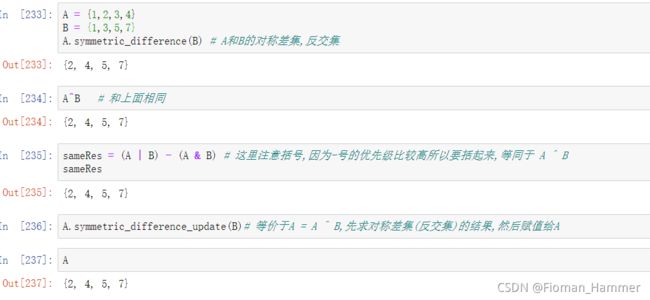
A.symmetric_difference(B)对称差集(反交集)- 计算A和B的对称差集,也叫反交集,等同于 A ^ B, 计算过程等同于= A|B - A&B
- A.symmetric_difference_update(B) 等价于A = A^B,先求对称差集,然后赋值给A,返回None
-
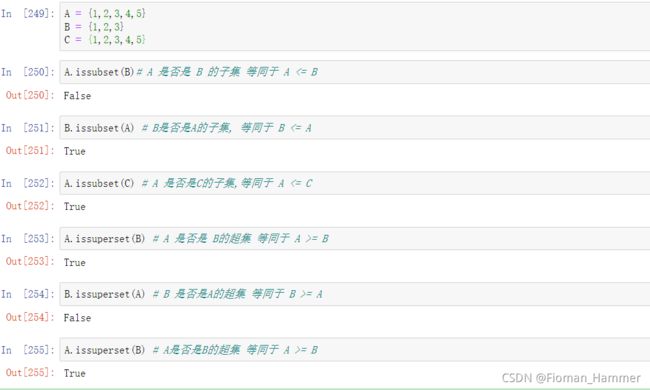
A.issubset(B) 和 A.issuperset(B)- A.issubset(B) A是否是B的子集 (包含A==B的情况),等价于 A <= B
- A.issuperset(B) A是否是B的超集 (包含A == B的情况),等价于 A >= B
4. 集合遍历和推导式
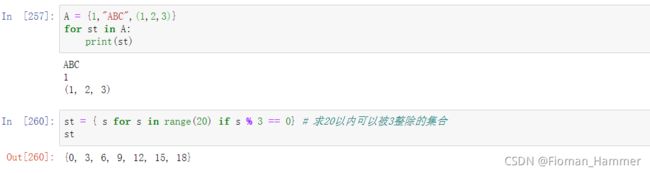
- for s in st: 遍历一个集合,s为集合中的元素
- {s for s in iter if s somecondition} 集合推导式,根据一个可迭代对象,生成一个新的集合
字典(dict)
1. 字典数据类型说明
- Dict是一个无序的,可变的序列,它是以键值对(key-value)的形式存储.
- Dict是Python中唯一的映射类型.就是元素和元素之间有对应关系,通过键可以找到值
- Dict是通过键而不是索引读取元素,字典类型有时候也被称为关联数组或者散列表(hash)
- Dict可变,并且支持嵌套
- Dict的键必须是唯一的,并且不可变的.
- Dict的值可以是任意的Python类型,也可以是自定义的类型
2. 字典的创建方式
-
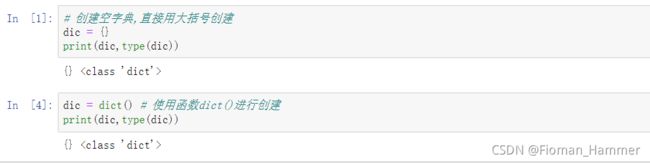
创建空字典- dic = {}
- dic = dict()
-
直接赋值的方式创建字典dic = {key1:value1,key2:value2,key3:value3,key4:value4}

-
通过函数dict和关键字参数创建dic = dict(key1=value1,key2=value2,key3=value3)

-
通过dict和二元组的元组进行创建dic = dict(tup) => 其中tup = (tup1,tup2,tup3,tup4) 内部的tup都是二元组,只有两个元素的元组

-
通过dict() 和 二元组列表进行创建dic = dict(list) => 其中list里面的元素全部都是二元组.

-
通过dict() 和二元列表元组进行创建dic = dict(tup) => tup是一个全部都是二元列表的元组.

-
通过dict()和二元列表的列表创建dic = dict(lst) => 其中lst是只包含二元列表的列表
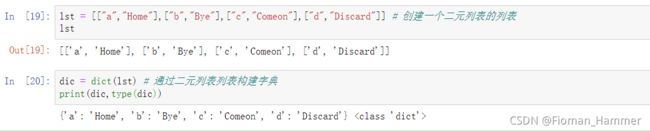
-
通过dict()和zip结合创建字典dic = dict(zip(iter1,iter2)) => 将iter1作为键,iter2作为值构建字典,其中生成的字典的元素个数,
由min(len(iter1),len(iter2))来确定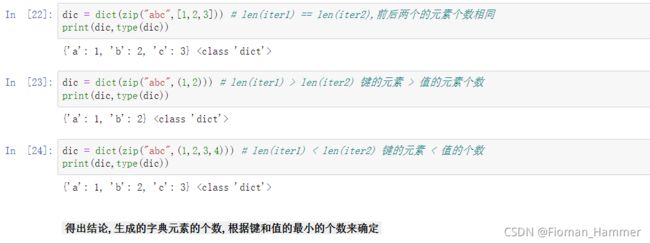
-
通过dict.fromkeys)创建dic = dict.fromkeys(iterForKey,defaultVal) => 通过一个可迭代的序列创建字典,key是可迭代序列
的元素,默认值是defaultVal
-
通过字典推导式dic = {key:func(key) for key in …} => 字典推导式

3. 字典增加元素
-
dic[key] = value使用dic[key]=value 的形式,如果key已经存在,则是赋值,将原来的key对应的oldValue赋值为新的value,如果key不存在,则是创建一个新的newKey=key并赋值为value
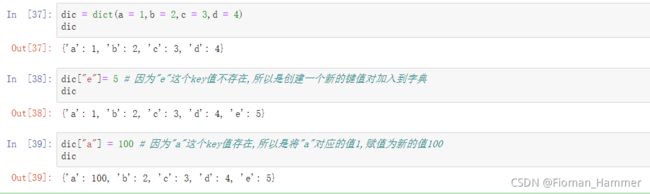
-
oldDict.update(newDict)如果使用update方法,传入的是一个新的dict对象,key不存在则是添加元素,如果已经存在则是覆盖掉旧的值
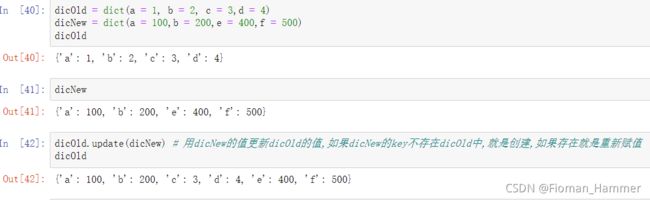
-
使用dict.update(key1=value1,key2=value2,key3=value3)同样使用update(),传入的是关键字参数,如果key不存在,则是创建,如果存在则是赋值
关键字参数有一个局限就是更新的字典的键只能是字符串,不能是其他的类型
-
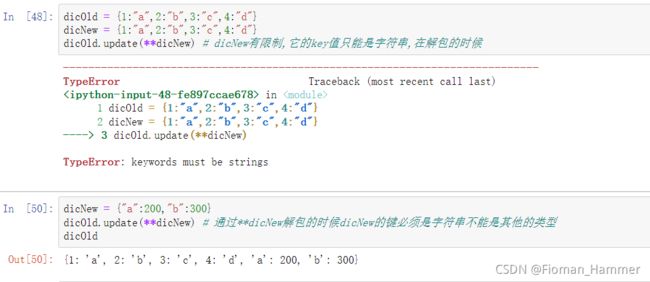
dict.update(**dict)通过字典解包的形式,等同于dic.update(key1=value1,key2=value2),关键字传参,最后添加的只能是字符换的键
4. 字典删除元素
-
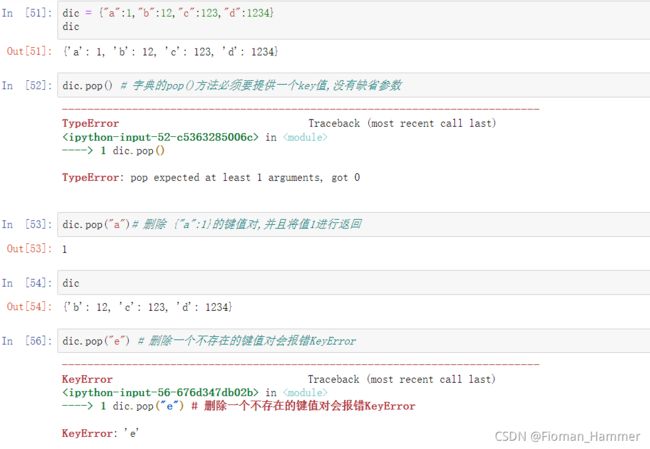
pop()dic.pop(someKey) # 删除要删除的键值对,并且把删除的键值对的值进行返回
-
popitem()dict.popitem() => 随机删除一个键值对,并将这个删除的键值对以元组(key,value)的方式进行返回
如果dict是空字典,则报错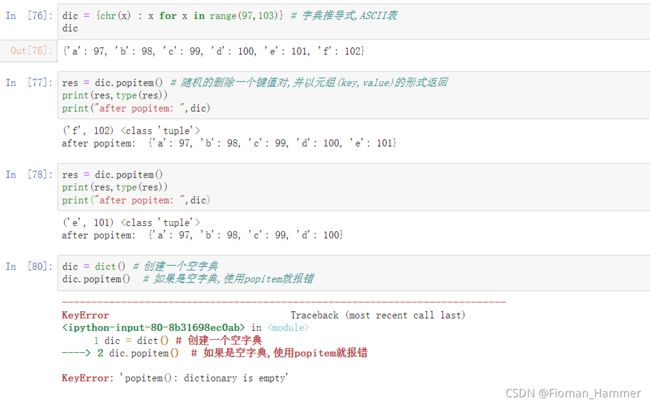
-
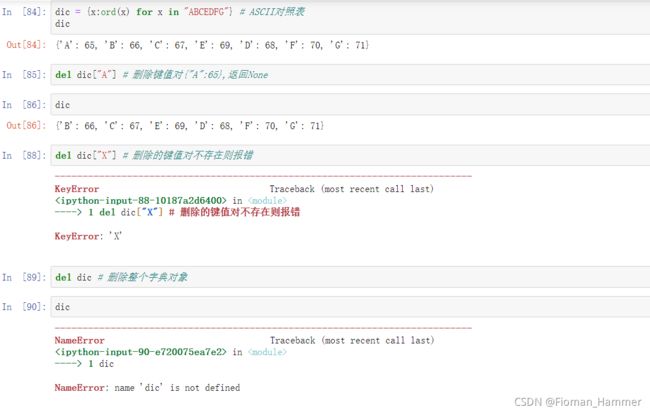
del dic or del dic[somekey]全局删除dic,后面可以是字典对象dic,也可以是字典的某一项del dic[key].如果删除的key不存在,报错
-
dict.clear()dict.cleart() => 清空字典,清空字典的所有的条目,得到一个新的空字典
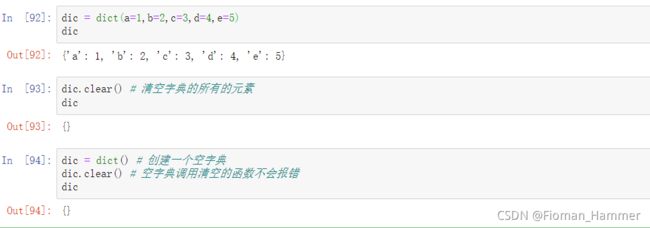
5. 访问字典
-
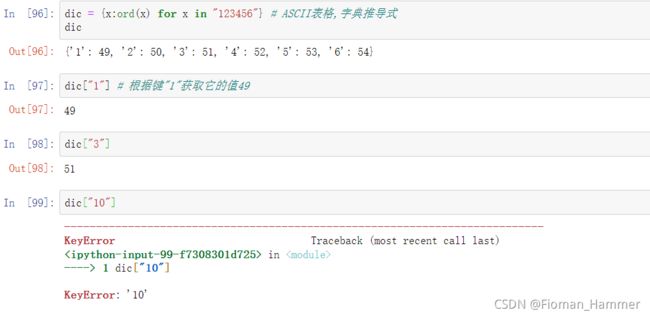
dict[key]dict[key] 根据key获取value的值,如果key不存在报keyError异常
-
dict.get(key,defaultVal=None)根据key获取value的值,比dic[key]多一个功能是如果key不存在,不会报错,返回一个defaultVal,如果
defaultVal没有提供,默认是None值
-
dict.setdefault(key,defaultVal)dict.setdefault(key,defaultVal) => 会根据key值获取key对应的val进行返回,如果key不存在,则会创建一个
key,dic[key]=defaultVal,并返回defaultVal,defaultVal如果没有提供,则默认是None值
-
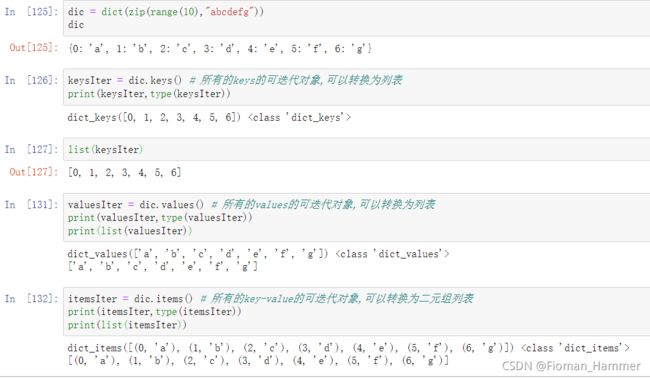
keys() values() items()- keys() 返回一个可迭代对象,里面包含所有的key的一个序列,类型是dict_keys
- values() 返回一个可迭代对象,里面包含所有的values的一个序列,类型是dict_values
- items() 返回一个可迭代对象,里面包含所有的(key,value)的一个序列,类型是dict_items
-
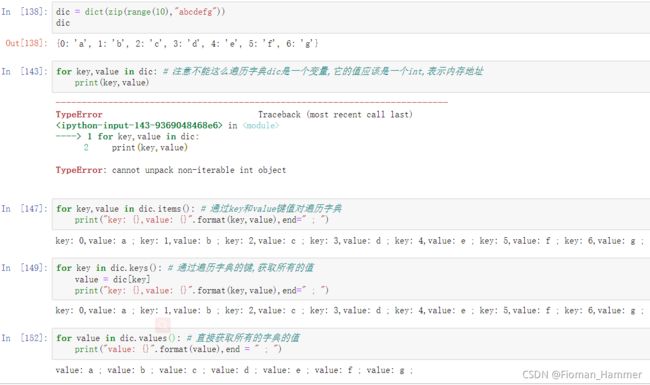
遍历字典- for key,value in dic.items() => 遍历字典的键值对,注意不能直接写 in dic
- for key in dic.keys() => 遍历所有的key,通过key访问value
- for value in dic.values() => 直接遍历所有的value,来获取字典的值
-
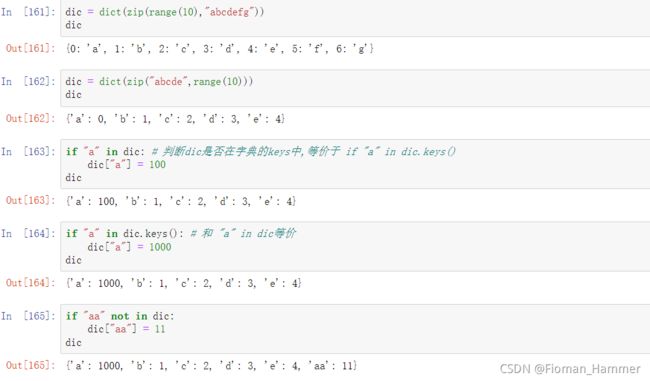
字典的其他操作- 判断某个key是否存在于字典中.
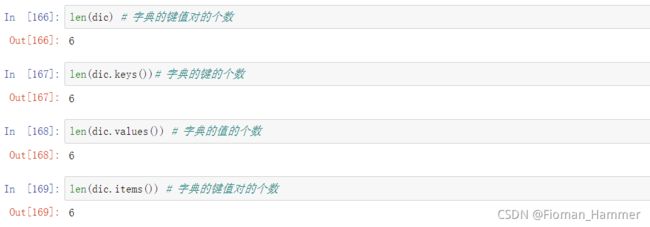
if key in dic: - len(dic) 返回字典的键值对的个数,
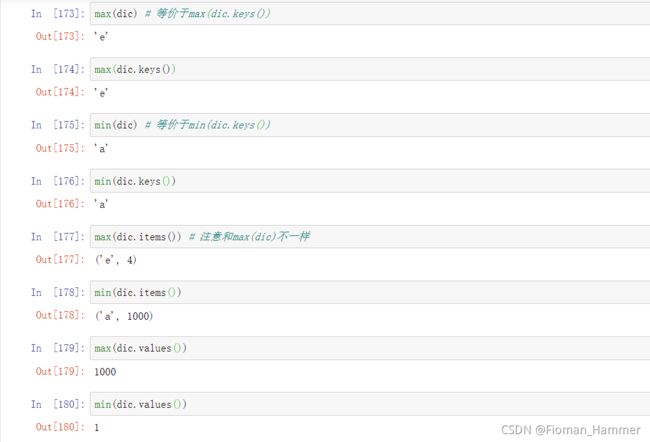
len(dic)==len(dic.keys())==len(dic.values()) max(dic) 和 min(dic)都是求的键的最大值和最小值,等价于max(dic.keys())和min(dic.keys())
- 判断某个key是否存在于字典中.