excel中pandas的使用
1. pandas
pandas documentation — pandas 1.3.3 documentation
pandas 是一个Python包,提供快速、灵活和富有表现力的数据结构,旨在使处理“关系”或“标记”数据既简单又直观。它旨在成为在 Python 中进行实用、真实世界数据分析的基本高级构建块。此外,它还有一个更广泛的目标,即成为任何语言中可用的最强大、最灵活的开源数据分析/操作工具。它已经在朝着这个目标前进。
pandas 非常适合许多不同类型的数据:
具有异构类型列的表格数据,如 SQL 表或 Excel 电子表格
有序和无序(不一定是固定频率)时间序列数据。
具有行和列标签的任意矩阵数据(同种类型或异类)
任何其他形式的观察/统计数据集。数据根本不需要标记即可放入pandas数据结构中
2. Pandas 功能简介:
轻松处理浮点和非浮点数据中的缺失数据(表示为 NaN)
大小可变性:可以从 DataFrame 和更高维度的对象中插入和删除列
自动和显式数据对齐:对象可以明确地对齐一组标签,或者用户可以简单地忽略标签和让
Series,DataFrame等自动对齐数据你计算强大、灵活的分组功能,可对数据集执行拆分-应用-组合操作,用于聚合和转换数据
使它易于转换衣衫褴褛,在其他Python和NumPy的数据结构不同索引的数据转换成数据帧对象
基于标签的智能切片、花式索引和 大数据集子集
直观的合并和连接数据集
灵活地重塑和旋转数据集
轴的分层标记(每个刻度可能有多个标签)
强大的 IO 工具,用于从平面文件(CSV 和分隔符)、Excel 文件、数据库加载数据,以及从超快HDF5 格式保存/加载数据
时间序列特定功能:日期范围生成和频率转换、移动窗口统计、日期偏移和滞后。
3.在pycharm中安装 pandas
3.1 安装方法1 文件->设置->项目->搜索pandas 进行安装
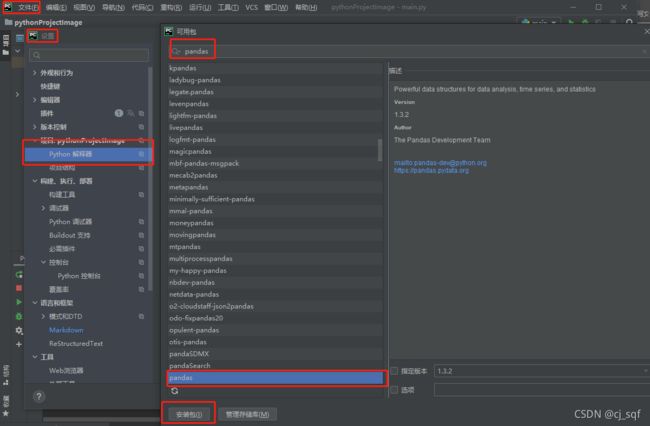
3.2 安装方法2 命令安装
pip install pandas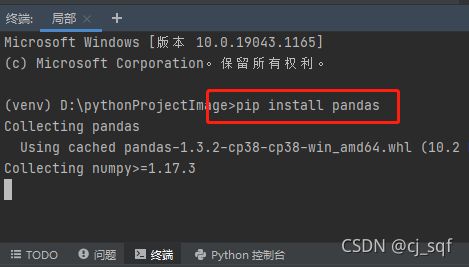
3.3 补充安装 openpyxl
pip install openpyxl
4.读取excel表格
#导入库
import pandas as pd
#设置最大显示行列
pd.set_option('display.max_columns', 1000)
pd.set_option('display.width', 1000)
pd.set_option('display.max_colwidth', 1000)
pd.set_option('display.max_rows', 1000)
#读取表格 sheet_name 表示第几张表 header 表示从第几行开始读
data1 = pd.read_excel(r'D:\Desktop\MvCameraNode-CH.xlsx', sheet_name=0, header=0)
#打印前100行
print(data1.head(100))5.新建一个pandas表
df = pandas.DataFrame()6. 将pandas表内的字符串转化为数值
df['name'] = df['name'].apply(
lambda x: float(x.split()[0].replace(',', ''))
if(',' in str(x)) else float(x))7.新增一列=a列-b列
df.loc[:, "c"] = df["a"] - df["b"]
8.将pd存储为表格-支持多sheet存储
df.to_excel(path, index=False, sheet_name="a")
writer = pandas.ExcelWriter(path, mode="a", engine="openpyxl")
df2.to_excel(writer, index=False, sheet_name="b")
writer.save()
writer.close()