【Linux】基础IO
文章目录
- 1. C语言的文件IO
- 2. Linux系统的文件IO
-
- 2.1 open函数和close函数
- 2.2 write函数
- 2.3 read函数
- 2.4 文件描述符fd的理解
- 2.5 重定向
- 2.6 重定向函数
- 2.7 缓冲区
- 3. 文件系统
-
- 3.1 磁盘的物理结构
- 3.2 磁盘的存储结构
- 3.3 磁盘的逻辑结构
- 3.4 inode
- 3.5 软硬链接
-
- 3.5.1 软链接
- 3.5.2 硬链接
- 3.6 文件的三个时间
1. C语言的文件IO
在学习系统的基础IO之前,我们先看看C语言的文件操作是如何做的。
fopen函数可以用来打开一个文件,并返回文件指针,以便在程序中进行文件的读取和写入操作。
它有以下几种打开方式
- ‘‘r’’ :以只读方式打开文件。文件必须存在,否则打开失败。
- ‘‘w’’:以写入方式打开文件。如果文件不存在,创建一个新文件;如果文件存在,会在打开时对文件内容进行清空。
- ‘‘a’’:以追加方式打开文件。如果文件不存在,创建一个新文件;如果文件已存在,在文件末尾添加数据。
- “r+”:以读写方式打开文件。如果文件不存在,打开失败;如果文件存在,会在打开时对文件内容进行清空。
- “w+”:以读写方式打开文件。如果文件不存在,创建一个新文件;如果文件存在,会在打开时对文件内容进行清空。
- “a+”:以读写方式打开文件。如果文件不存在,创建一个新文件;如果文件存在,在文件末尾添加数据。
下面演示fopen函数的使用
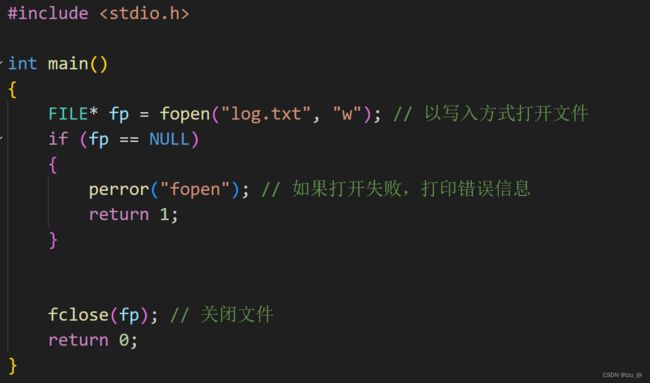
运行之后,再查看当前目录,发现文件就被创建好了。
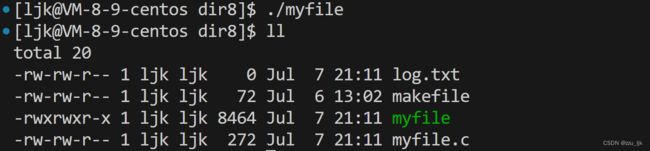
下面试着向这个文件中写入一些东西

运行程序,再查看文件内容,就可以发现有我们想要的内容了。

再试着向文件中读取东西
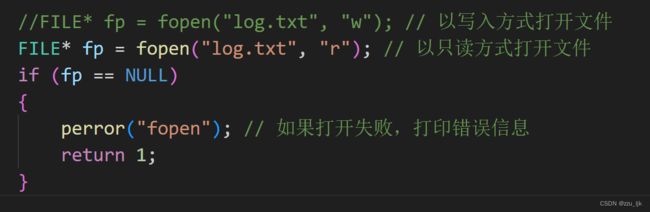
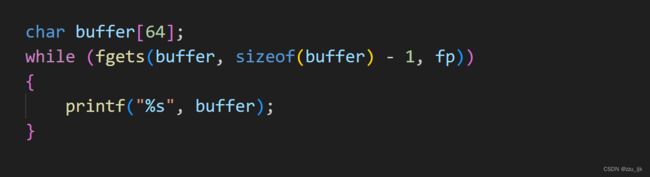
运行程序,就可以得到文件的内容了。

如果以"a"的形式打开,那么就会在文件末尾添加新内容,这里不再演示了。
这里有一个小细节,文件在程序中被创建之后默认权限为664。这与我们在命令行中创建文件是一样的,都是普通文件的默认权限666以及umask决定的,默认权限 & ~uamsk得到文件的起始权限。

![]()
2. Linux系统的文件IO
上面我们认识了C语言的文件IO操作,但除了C语言,C++,Java,Python,Go等语言都是有文件IO操作的,它们的操作接口都不一样。
但是它们操文件的时候,必然是要访问文件的,文件在哪里?在磁盘上,磁盘又属于硬件,在操作系统下层,那么上层用于要访问磁盘上的文件就必然要经过操作系统,也就必须要使用操作系统的系统调用接口。也就是说,上层语言的文件操作接口无论如何变化,它们都必须调用系统调用接口!了解系统的文件操作,更能让我们深刻理解上层不同语言变化的文件操作!
2.1 open函数和close函数

图中第一个函数是在文件已存在的情况下使用的,第二个函数在文件不存在的情况下使用的。
第一个参数是文件路径。如果只给出了文件名,会默认在当前路径下创建。
第二个参数是打开文件方式。它是利用比特位进行传递的,即整数flags有32个比特位,不同的比特位有不同的意义,通过在函数内部查看flags的每个比特位,就知道文件具体打开方式是什么。
第三个参数即权限,它决定了创建文件的默认权限是多少。
如果成功,它的返回值是文件描述符,具体什么是文件描述符后面再说。如果失败,返回-1。
以写入的形式打开文件

这里第二个参数中,O_WRONLY表示以写入形式打开文件,O_CREAT表示文件不存在时会创建文件,O_TRUNC表示每次打开文件时会清空文件内容。如果没有O_TRUNC,每次打开文件时,会以覆盖的形式写入文件,可能会出现文件前面的内容是这次写入的,后面的内容是上次残留的。
如果要进行追加的操作呢?使用O_APPEND

以只读形式打开文件

对于文件的关闭,有close函数,传入打开文件时返回的整数即可。

2.2 write函数

使用write函数可以向对应的文件中写入内容。
第一个参数为要写入的文件的fd。
第二个参数为指向要写入的数据的缓冲区的指针,数据从这个缓冲区写入写入文件中。
第三个参数为写入数据的字节数。
如果写入成功,返回写入数据的字节数。如果写入失败,返回-1。
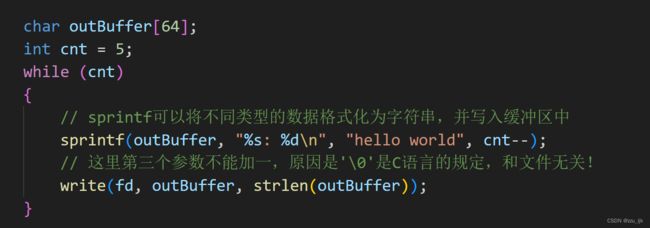
2.3 read函数

将文件内容读入到缓冲区中
第一个参数是文件的fd。
第二个参数是要读入的缓冲区,数据从文件中写入到这个缓冲区中。
第三个参数为最多写入的字节数。
如果写入成功,返回值为写入的字节数。如果写入失败,返回-1。

运行程序,就可以得到文件的内容了。

2.4 文件描述符fd的理解
文件操作的本质是:进程和被打开文件的关系。那么进程一定是可以打开多个文件的,系统中一定会存在大量被打开的文件,操作系统也一定要对大量打开的文件做管理,如何管理?先描述,再组织!操作系统为了管理对应的打开文件,必定要为文件创建对应的内核数据结构标识文件,即struct file,它包含了文件的大部分属性。
那么具体是如果做的呢?使用文件描述符fd。
下面我们在程序中打开几个文件,看看他们的fd是怎样的。
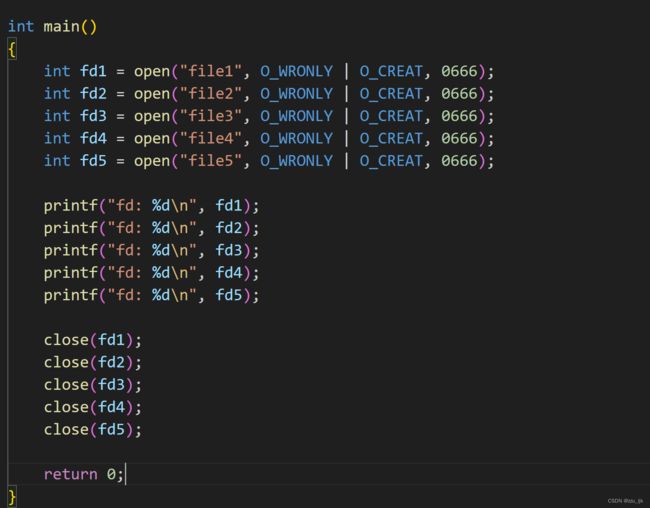
运行结果如下

为什么自己打开的文件的fd从3开始?
每次运行程序时,会默认打开3个标准输入输出流。

C语言中,虽然我们用的不是fd,而是FILE结构体来找到打开的文件的。但是C语言封装了系统调用接口,这也就是说,FILE结构体中一定封装了fd。
我们可以尝试打印出那三个标准输入输出流的fd


所以,我们自己打开文件的文件描述符是从3开始的,0、1、2都被占用了!
文件描述符为什么是连续的整数
一个进程要打开许多文件,就要就打开的文件做管理。在进程的PCB中存在一个指针struct files_struct *files,它指向一个结构体,这个结构体中又包含一个数组,这个数组叫做struct file *fd_array[],这是一个指针数组,它的每一个元素指向被打开文件的结构体,它也就是所谓的文件描述符表。第一个元素指向管理标准输入流的结构体,第二个元素指向管理标准输出流的结构体,第三个元素指向管理标准错误的结构体。当再打开文件时,从0开始往后找,找一个没有被占用的且最小的数组下标,发现是3,则返回的fd就是3。


图中最后一个结构体指针即文件描述符表
文件描述符的分配规则:使用没被占用的且最小的!比如默认打开3个标准输入输出流之后,再打开其他文件,分配的文件描述符就是3,如果关闭0号文件描述符指定的文件,再打开其他文件,就会分配0。
2.5 重定向
下面通过代码演示重定向是什么

关闭文件描述符1,即关闭标准输出,然后再打开其他的文件,此时该文件就会分配文件描述符1。在printf和fprintf中,会将内容打印到stdout中,但是这里stdout被改成了log.txt文件,那么内容就会打印到log.txt中,而不是显示器上。
但是现在还仍不能打印到文件中,原因是文件和显示器的刷新策略不一样,这里应该主动刷新缓冲区。


重定向的本质是:上层用的fd不变,在内核中更爱fd对应的struct file*的地址
但是,上面重定向的方法是不是有麻烦了,下面介绍一个重定向函数
2.6 重定向函数

![]()
它会将oldfd对应的资源拷贝给newfd的资源,也就是将第一个参数指向的文件资源拷贝给第二个参数。同时会将newfd指向的文件进行close。

下面通过dup2函数再次函数输出重定向和输入重定向
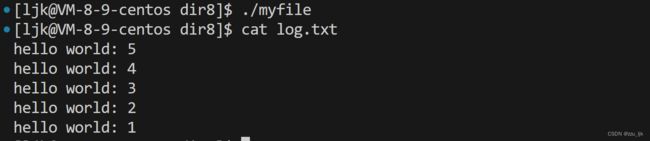
输出重定向

查看运行效果
输入重定向
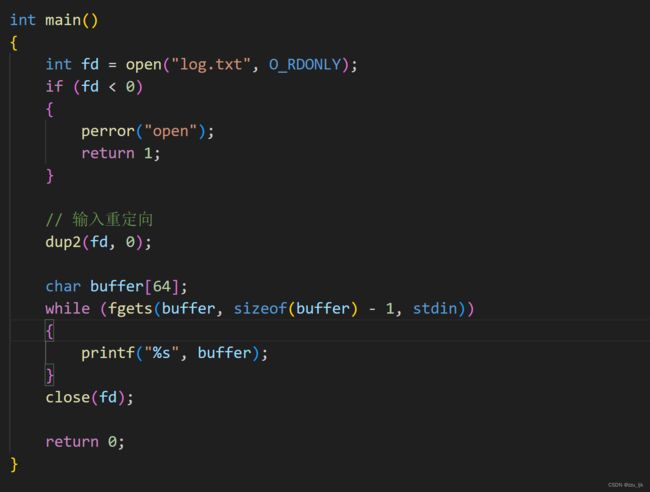
查看运行效果

2.7 缓冲区
下面的代码分别用了三个C语言的库函数和一个系统调用函数向显示屏输出信息。
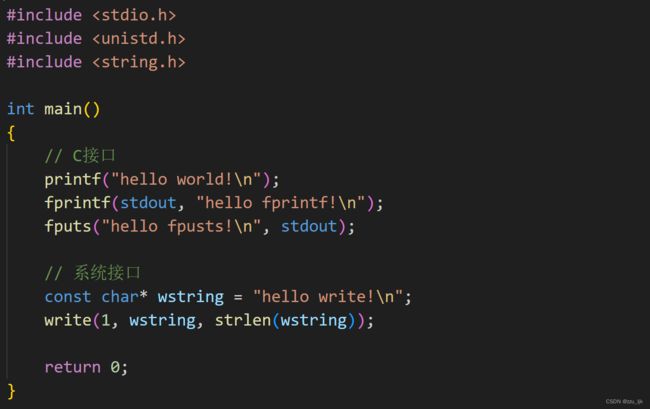
运行程序,打印数据到屏幕上

重定向到文件中

可以看到,上面的操作都是没有任何问题的,都达到了我们预期的效果。
下面我在代码下面添加一个fork函数

运行程序

这也是没有什么问题的,下面我将数据重定向到文件中。

???这就出现问题了,write函数只打印了一次,而其他C语言库的函数打印了两次。
为了解释这个问题,我们就需要先理解一下缓冲区!
缓冲区本质就是一块内存,就是一块用来做缓存的空间。
只要是内存,就会衍生出一些问题,谁申请的?属于谁的?为什么要有?
进程在内存中,进程如果要向磁盘文件写入数据,不能说有一点数据就立马要写入,频繁的写入会造成时间成本问题,而是将数据都先保存起来,在合适的时候一起写入。
就好比平时发快递的时候,不会说是为某个快递专门进行运输,而是等快递积累到一定程度了再一起运输快递。
fwrite函数,与其理解fwrite函数是写入数据到文件的函数,倒不如理解它是拷贝函数!将数据从进程,拷贝到"缓冲区"或者外设中!
那么缓冲区什么时候刷新呢?这里就要谈到缓冲区刷新策略的问题。
缓冲区刷新策略
如果有一块数据,一次直接写入外设肯定是比多少次分批量写入外设效率高的!
缓冲区一定会结合具体的设备,定制自己的刷新策略,一般而言,我们有三种刷新策略。
- 无缓冲 – 立即刷新,就跟没有缓冲区一样
- 行缓冲 – 行刷新,比如显示器
- 全缓冲 – 缓冲区满了再刷新,比如磁盘文件
无刷新很少,我们一般不考虑。
向显示器写入的时候,就是行刷新,我们如果不用换行符,就不会刷新缓冲区内的数据。为什么显示器采用的是行缓冲?缓冲区满了之后再刷新缓冲区的策略虽然是最高的,但是显示器比较特殊,显示器不是给其他设备看的,它是给人看的,人的阅读习惯就按行去读,那显示器最好就是按行显示。如果按全缓冲,缓冲一次就是很多内容,对人来讲是不舒服的。所以显示器既想保证效率,又想保证刷新的效果比较好,就采用了行缓冲的策略,更满足人的阅读习惯的同时还让效率不那么低。
效率最好的策略是全缓冲,在缓冲区满了之后一次刷新。一般向磁盘文件写入数据的时候效率采用全缓冲。
除了上面的刷新策略,还有其他刷新的方式,比如用户强制刷新,或者进程退出。
上面的现象一定是和缓冲区有关的,我们目前虽然不能确定缓冲区在哪里,但是我们能确定缓冲区一定不在内核中,因为如果在内核中,write也应该打印两次。
我们之前所谈论的缓冲区,都是用户层面的缓冲区。这个缓冲区,在stdout,stdin,stderr或者其他文件指针指向的FILE结构体中,这个结构体,包含了fd,也包含了一个缓冲区。所以我们自己要强制刷新的时候,用fflush,传入的一定是一个文件指针。
如何解释上面fork之后导致的问题?
在代码结束之前,创建子进程。
如果我们没有进行重定向,我们会看到四条消息,stdout默认使用的是行刷新,在进程fork之前,三条C函数已经将数据进行代言输出到显示器上,FILE内部也就不存在对应的数据了。
如果我们进行了重定向,本来应该打印到显示器上,结果重定向到了磁盘文件中,写入文件变成了磁盘文件,采用的刷新策略是全缓冲!之前的C语言函数,虽然带了’\n’,但是不足以将stdout缓冲区写满,数据并没有被刷新!此时再进行fork,创建子进程,子进程和父进程进行进程退出!谁先退出,一定要进行缓冲区刷新,刷新缓冲区的内容,就会发生写时拷贝,所以数据一定会有两份!write为什么只有一份数据?上面的过程都喝write无关,write没有FILE,而用的是fd,就没有C提供的缓冲区。
3. 文件系统
上面所说的一切都是进程与被打开文件之间的关系,如何文件没有打开呢?操作系统如果管理呢?
磁盘上面有大量的文件,这些文件是必须要被静态管理起来的,方便我们随时打开。所以,不要认为文件被打开才需要被管理,文件没有被打开照样需要被管理。
3.1 磁盘的物理结构
我们现在买到的笔记本很少见到磁盘了,现在笔记本用的都是固态硬盘。磁盘是我们计算机中唯一的一个机械结构,其他硬件很多都是电路结构,而只有硬盘是机械结构+外设,这也就决定了硬盘访问会很慢!(相对于其他设备)
我们现在虽然很少见到磁盘了,但磁盘仍然是企业的主流,SSD存储很快,但是造价高,且没有磁盘便宜,所以企业内保存大量数据时会优先考虑磁盘。

磁盘就是这个样子,磁盘的两个面都是光的,叫做盘面,且被磁化处理过,磁盘上那个像刀一样的东西叫做磁头,磁头不是只有一个,磁盘的每一个面都有磁头。一旦运行起来,磁盘盘面高速旋转,磁头左右摆动。磁盘中有马达,马达会控制盘片旋转和磁头摆动。
磁盘的密封性要求非常高,一般磁盘是在真空的环境中进行组装的。且磁盘不能拆,拆开之后磁盘立马报废!
磁头和盘面是没有接触的,只是看起来很近。磁盘必须防止抖动,如果磁盘高速旋转的时候磁盘被晃了一下,磁头就会上下摆动,磁头就可能会挨到盘面,一旦挨到盘面就把磁盘刮花了,刮花之后就会导致二进制数据丢失。
3.2 磁盘的存储结构
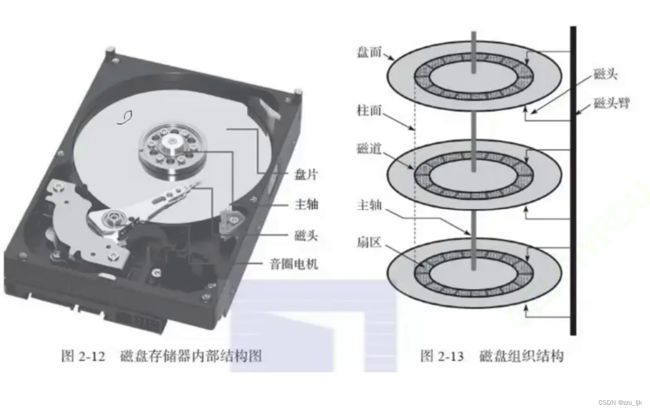
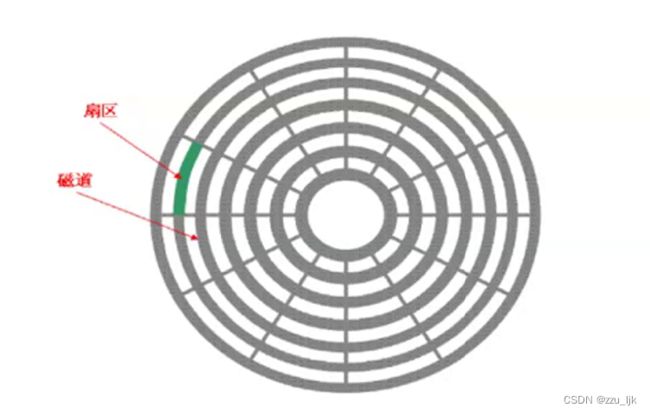
磁盘的盘面就是一系列的同心圆,我们称每个同心圆为磁道。磁盘寻址的时候,基本单位不是bit,更不是byte,一般而言,磁盘的单位是扇区,扇区即那些扇形区域块,大小为512byte。
靠近圆心的扇区较窄,远离圆心的扇区较宽,但是它们的大小都是512byte,这样磁盘空间虽然有一些浪费,但是效率更高。
所以,在单面上,如何定位一个扇区呢?确认它在哪个磁道,再确认它在对应磁道的哪一个扇区。磁道的周长不一样,但是存储的数据大小也是一样的。磁头来回摆动就是确认在哪一个磁道,盘片旋转就是让磁头定位扇区。

在一摞盘面上,柱面上的磁道周长都一样。磁头和面数是相头的,且磁头是连在一起的,它们是共进退的。所以,计算机在寻址的时候,不是一个磁头去一面上找,而是所有磁头在所有面的同样磁道处去找。
那么,如何在磁盘中定义任何一个扇区呢?先定位在哪一个磁道(定位柱面),磁头这时候就不动了,再定位是哪一个磁头(定位盘面),最后定位在哪一个扇区。
柱面对应英文单词cylinder,磁头对应head,扇区对应sector,所以磁盘定位扇区,采用的硬件的基本定位方式,可以称为CHS定位法!
3.3 磁盘的逻辑结构
磁盘物理上是圆形的,我们可以将它想象成一个线性结构,就跟磁带一样!

将磁盘从逻辑上看作为一个sector arr[n]。这样,对磁盘进行管理,就转化成了对数组进行管理,这也就叫做:先描述,再组织。
这样的话,要找到磁盘的一个扇区,应该如何做呢?只要知道这个扇区的下标,就算定位了一个扇区! 在操作系统内部,我们称这种地址为LBA地址。
假如某个磁盘有4个盘面,每个盘面10个磁道,每个磁道100个扇区,每个扇区512byte,则:

如果此时要寻找123号磁盘位置,123 / 1000 = 0,则定位在0号盘面。123 % 100 = 1,则定位在1号磁道,123 % 100 = 23,则定位在23号扇区。
这样,我们就完成了对磁盘的逻辑抽象。
为什么操作系统要进行逻辑抽象呢?直接用CHS不行吗?
便于管理,且可以不让操作系统的代码和硬件强耦合!具体底层用的是什么,操作系统看的都是LBA,这样底层发生变化时并不会影响操作系统。
3.4 inode
在计算机文件系统中,inode是一个数据结构,用于存储文件或目录的元数据。每个文件或目录都与一个唯一的inode相关联。该inode存储了与文件或目录相关的信息,例如文件的所有者,权限,大小,创建时间和修改时间等。
inode包含了文件或目录的索引信息,这些索引指向存储文件数据的磁盘块。通过inode,操作系统可以快速地访问文件或目录的元数据以及它们的实际数据。inode还允许文件系统跟踪文件的链接数量,这对于实现硬链接和软链接等功能很重要。
一个文件,一个inode,且inode的大小固定不变,一般是128字节,不同的平台可能不一样。inode几乎保存了文件的所有属性,但文件名不在inode中存储!
inode为了区分彼此,每个inode都有它的编号。ls -li显示文件的inode编号。

系统中有一个inode table,它里面保存了所有可用(已经使用+没有使用)的inode。
在查找文件的时候,统一使用的是inode编号。
而文件内容会存储在磁盘的data block中,它的大小随着应用类型的变化而变化。磁盘中,Data blocks中保存的是分组内部所有文件的数据块!
如果理解创建一个空文件?
- 通过遍历inode位图的方式,找到一个空闲的inode
- 在inode表中找到对应的inode,并将文件的属性信息填充到inode结构中
- 将该文件的文件名和inode指针添加到目录文件的数据库中
如何理解对文件写入信息?
- 通过文件的inode编号找到对应的inode结构
- 通过inode结构找到存储该文件内容的数据块,并将数据写入数据块
- 若不存在数据块或者数据块已被写满,则通过遍历位图的方式找到一个空闲的块号,并在数据区中找到对应的空闲块,再将数据写入数据块,最后还需要建立数据块和inode的映射关系
如何理解删除一个文件?
- 将该文件对应的inode在inode位图中置为无效
- 将该文件申请过的数据块在块位图中置为无效
所以,删除文件并不会将文件对应的信息真正的删除,而是将它的inode编号和数据块置为无效,所以删除文件后短时间内是可以恢复的。这里说是短时间,是因为该文件的inode和数据块已经置为无效,在后续创建其他文件或者是对其他文件进行写入操作申请inode号和数据块号时,可能会将该置为无效了的inode号和数据块分配出去,此时被删除的文件的数据就会被覆盖,也就无法恢复文件了。
为什么拷贝文件的时候很慢,而删除文件的时候很快?
因为拷贝文件需要先创建文件,然后再对文件进行写入操作,这就需要先申请inode编号并填入文件的属性信息,然后申请数据块,才能进行文件内容的拷贝。而删除文件只需要将文件的inode和数据块置为无效,无需真正地删除文件,因此拷贝文件是很慢的,而删除文件是很快的。
如何理解目录?
- Linux下一切皆文件,目录也可以被看作文件
- 目录有自己的属性信息,目录的inode结构当中存储的就是该目录的属性信息,比如目录的大小,目录的拥有者等
- 目录也有自己的内容,目录的数据块中存储的就是目录中的文件名及对应的inode指针
注意:每个文件的文件名并没有存储在自己的inode结构当中,而是存储在文件所处目录的数据块中。因为计算机本身并不关注文件的文件名,而是关注文件的inode号,而文件名和inode指针存储在其目录文件的文件内容当中后,目录通过文件名和inode指针即可以将文件名和文件内容及属性链接起来。
3.5 软硬链接
3.5.1 软链接

l类型的文件就是软链接文件
软链接文件有自己的inode,说明它是一个独立的文件。

软链接有它自己的inode和数据块,其中数据块中保存的是目标文件的路径。如果目标文件不存在,原文件就会失效。
软链接其实也就相当于Windows下的快捷方式!
我们双击Windows下的快捷方式,就能打开目标文件,原因就是Windows下保存了目标文件的路径。
所以软链接的作用是什么?
如果一个可执行文件的目录很复杂,我们每次执行它去找的时候就很繁琐,这时我们建立软链接,相当于创建一个快捷方式,在别的目录下去执行这个文件,这就方便多了!
3.5.2 硬链接
创建硬链接

可以发现硬链接的inode编号和原文件是一样的!

向原文件中写入数据,可以发现原文件的大小和硬链接文件的大小都改变了,且可以通过硬链接直接打印文件内容。


所以建立硬链接是做了什么?
创建硬链接,没有分配新的inode和数据块,而是用的目标文件的inode和数据块。创建硬链接的本质就是在指定目录下,新增文件名和inode的映射关系! 每个inode都有一个计数器,表示有多少个文件名指向它。

如果删除原文件,硬链接会发生什么?

可以发现只是inode的引用计数变为1,而文件并没有被真正地删除,那么文件什么时候算是被真正地删除呢?当引用计数为0的时候!
硬链接有什么作用呢?
创建一个普通文件,硬链接数是1,它自己本身就是一个文件名和自己inode的映射关系,所以默认硬链接数为1,而创建一个目录,硬链接数为2,为什么?空目录中有名字有一个点的目录,它指向该空目录。

若在目录中创建一个文件再创建一个文件,硬链接就变为3了。

注意:Linux不允许给目录创建文件!
![]()
确切来说,是不允许用户创建,操作系统可以给目录创建一个点和两个点的硬链接。
3.6 文件的三个时间
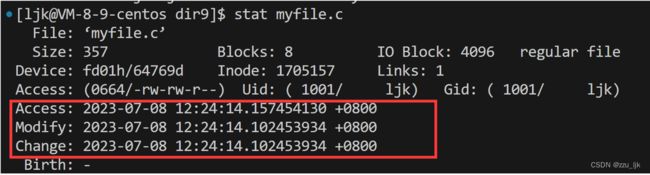
Change时间:表示文件属性的修改时间
Modify时间:表示文件内容被修改的时间,但是文件内容大小也属于文件属性,修改该时间大概率也会修改到Change时间
Access时间:表示最近访问文件的时间。但是往往访问文件是很频繁的,如果每次访问文件都改变时间,会影响系统的效率,所以策略是当访问一定次数了才会修改Access时间。