MySQL分区分库分表和分布式集群
目录
MySQL分区表的原理
分库分表
垂直分表
水平分表
一致性哈希算法
分布式分库分表的主键ID问题(雪花算法)
雪花算法应用:搭建发号器
MySQL并发方案:读写分离
MySQL分区表的原理
分区表是一个独立的逻辑表,对用户来说是透明的,底层MySQL会将其分成多个物理子表,每一个分区表都会使用一个独立的表文件。
创建表的时候使用partition by 子句定义每个分区存放的数据,执行查询时,优化器会根据分区定义过滤那些没有需要的数据的分区,这样只需要查询数据所在分区即可。
分区的主要目的是将数据按照一个较粗的粒度分在不同的表中,这样可以将相关的数据存放在一起,而且如果想一次性删除整个分区的数据也很方便
分区适用场景:
- ① 表非常大,无法全部存在内存,或者只在表的最后有热点数据,其他都是历史数据;
- ② 分区表的数据更易维护,可以对独立的分区进行独立的操作;
- ③ 分区表的数据可以分布在不同的机器上,从而高效使用资源;
- ④ 可以使用分区表来避免某些特殊的瓶颈;
- ⑤ 可以备份和恢复独立的分区。
分区的限制:
- ① 一个表最多只能有 1024 个分区;
- ② 5.1版本中,分区表表达式必须是整数, 5.5可以使用列分区;
- ③ 分区字段中如果有主键和唯一索引列,那么主键列和唯一列都必须包含进来;
- ④ 分区表中无法使用外键约束;
- ⑤ 需要对现有表的结构进行修改;
- ⑥ 所有分区都必须使用相同的存储引擎;
- ⑦ 分区函数中可以使用的函数和表达式会有一些限制;
- ⑧ 某些存储引擎不支持分区;
- ⑨ 对于 MyISAM 的分区表,不能使用 load index into cache;
- ⑩ 对于 MyISAM 表,使用分区表时需要打开更多的文件描述符。
分库分表
因为 MySQL 本质上是一个单机数据库,假设有1TB 的数据,如果一个库撑不住,我把它拆成 100 个库,每个库就只有 10GB 的数据了,这不就可以了么? 需要先明确一个原则,那就是能不拆就不拆,能少拆不多拆。分库分表一定是数据量和并发大到所有招数都不好使了,我们才拿出来的最后一招。
分库分表要解决的问题:
- 并发量很大,但是数据量比较少,可以只分库,不分表
- 并发量不大,但是数据量比较大,可以只分表,不分库
- 并发量很大,数据量也比较多时,既要分库,也要分表
总结:数据量大就分表:减少每次查询的数据总量;并发高就分库:把并发请求分散到多个实例中去;
分库分表的原理是通过一些 HASH算法 或者工具实现将一张数据表垂直或者水平进行物理切分。
分库分表缺点:
有些分表的策略基于应用层的逻辑算法,一旦逻辑算法改变,整个分表逻辑都会改变,扩展性较差对于应用层来说,逻辑算法会增加开发成本
垂直分表
把主键和一些列放在一个表,然后把主键和另外的列放在另一个表中。“大表拆小表”, 基于表中字段拆分,将不常用的,数据较大的拆分到扩展表,一般针对几百列的大表进行拆分。
使用场景:如果一个表中某些列常用,而另外一些列不常用(可以把常用的列单独拆分出来,查询的时候只查询常用的列即可);可以使数据行变小,一个数据页能存储更多数据,查询时减少 I/O 次数。
缺点:管理冗余列,查询所有数据需要 JOIN 操作;
水平分表
针对数据量巨大的单表,按照某种规则,拆分到多个表中,但是这些表还是在一个库中。分割后可以降低在查询时需要读取的数据和索引的页数,同时也降低了索引的层数,提高查询速度。
使用场景:表中的数据本身就有独立性,例如表中分别记录各个地区的数据或者不同时期的数据,特别是有些数据常用,有些不常用;需要把数据存放在多个介质上(最新的数据放到不同服务器上,或者做缓存)。
特点:每个库/表的结构都一样,每个库/表的数据都不一样,每个库/表的并集是全量数据。
【问题】设定网址的用户数量在千万级,但是活跃用户的数量只有 1%,如何通过优化数据库提高活跃用户的访问速度?
- 使用分区:可以使用MySQL的分区,因为MySQL分区可以按照一个规则(把活跃用户分在一个区,不活跃的用户分到另一个区),在进行查询的时候,可以进行操作活跃用户的时候,只操作活跃用户的那个区。
- 使用分库分表:通过 水平切分 的方式,把活跃用户的数据切分成一个表,不活跃用户的数据放到另外一张表中,查询的时候只查询活跃用户的数据表即可。这样就提高了数据库的查询速度。
水分库分表规则:
- RANGE ,按照范围拆分,比如0-10000一个表, 10001到20000一个表
- HASH取模,比如通过用户ID取模,然后分配到不同的库表中。
- 地理区域,比如按照华北,东北等区域区分。
- 时间拆分,比如将6个月前的数据拆出去放到一张表,随着时间的流逝,这些表的数据查询的几率很小,这也是冷热数据分离。
优点:单库/表的数据减少,有利性能; 库/表结构相同,程序改动小。
缺点:给应用增加复杂度,通常查询时需要多个表名,查询所有数据都需 UNION 操作;数据扩容难度大,比如取模的值变了应该怎么办?
根据10取模, 数据1保存到节点1上, 数据2保存到节点2上;根据11取模, 因为分子发生了变化,所以取模的值都变化。
此时需要用到 一致性哈希算法
一致性哈希算法
也是使用取模的方法,但是普通取模算法是对服务器的数量进行取模,而一致性哈希算法是对 2^32 取模,是一个固定值。可以想象成是对 2^32 取模运算的结果值组织成一个圆环(就像钟表的圆可以理解成由60个点组成的圆),而此处把这个圆想象成由 2^32 个点组成的圆,这个圆环被称为哈希环。
第一步:对存储节点进行哈希计算,也就是对存储节点做哈希映射,比如根据节点的 IP 地址进行哈希;
第二步:当对数据进行存储或访问时,对数据进行哈希映射;所以,一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上。

一致性哈希算法虽然减少了数据迁移量,但是存在节点分布不均匀的问题,如何解决?
比如下面的哈希环上出现节点分布不均匀的情况,导致其中某几个节点压力过大,其中数据2落在C节点上,数据3、4、5、6、1 落在A节点上,而B节点上没有数据。导致B节点太空闲,而A节点压力太大。

此时,可以随机散落一些虚拟节点,和真实节点做个映射。
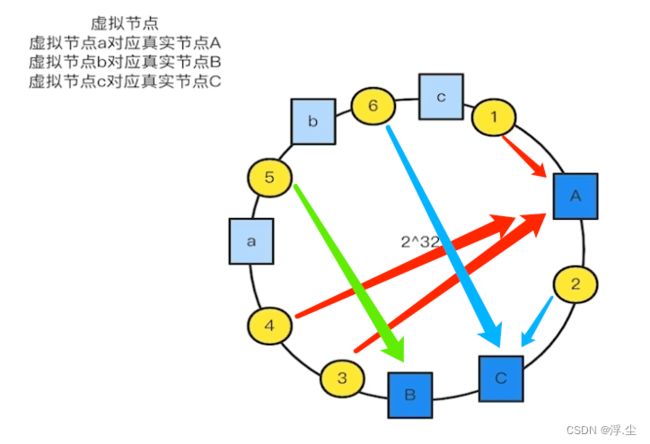
映射之后,最终的数据1、3、4落在A节点,数据2、6落在C节点,数据5落在B节点,情况比上面稍微好了一点。
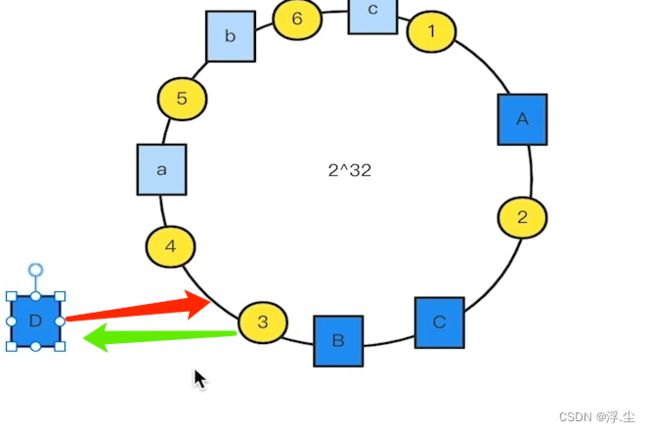
假如现在增加一个节点D,需要迁移原来节点的数据,迁移之前需要停服务。如下图所示,原来的数据3落在A上,现在要迁移到D上。移除节点同样的道理。
分布式分库分表的主键ID问题(雪花算法)
1、redis incr 命令
2、UUID(但是uuid有个问题就是其是无序的字符串,如果使用uuid当做主键,那么主键索引就会失效。)
3、snowflake算法(雪花算法) https://www.sohu.com/a/232008315_453160
雪花算法的优缺点:
- 雪花算法的优点:高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id;基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增;不依赖第三方库或者中间件;算法简单,在内存中进行,效率高。
- 雪花算法的缺点:依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
雪花算法应用:搭建发号器
- UUID 一般会使用它生成 Request ID 来标记单次请求,不推荐作为分表的ID;
- Snowflake 算法完全可以弥补 UUID 存在的不足,因为它不仅算法简单易实现,也满足 ID 所需要的全局唯一性,单调递增性,还包含一定的业务上的意义。
- Snowflake 的核心思想是将 64bit 的二进制数字分成若干部分,每一部分都存储有特定含义的数据,比如说时间戳、机器 ID、序列号等等,最终生成全局唯一的有序 ID。
- 41 位的时间戳大概可以支撑约69 年,对于一个系统是足够了。

参考资料:10 | 发号器:如何保证分库分表后ID的全局唯一性?-极客时间
MySQL并发方案:读写分离
读写分离是提升 MySQL 并发的首选方案:使用多个具有相同数据的 MySQL 实例来分担大量的查询请求。一个分布式的存储系统,想要做分布式写是比较困难的,因为很难解决好数据一致性的问题。但实现分布式读就相对简单很多。实现方案:配置一主多从,保持数据实时同步复制;读从库,写主库。
如何来实施 MySQL 的读写分离方案,需要做两件事:
1. 部署一主多从多个 MySQL 实例,并让它们之间保持数据实时同步。
2. 分离应用程序对数据库的读写请求,分别发送给从库和主库。
MySQL 集群需要执行很多操作: 主库需要提交事务、更新存储引擎中的数据、把 Binlog 写到磁盘上、给客户端返回响应、把 Binlog 复制到所有从库上、每个从库需要把复制过来的 Binlog 写到暂存日志中、回放这个 Binlog、更新存储引擎中的数据、给主库返回复制成功的响应。
关于以上操作的顺序,默认情况下,MySQL 采用异步复制的方式,执行事务操作的线程不会等复制 Binlog 的线程。

主从两个数据库更新数据实际的时序是这样的:
* 在主库的磁盘上写入 Binlog;
* 主库更新存储引擎中的数据;
* 给客户端返回成功响应;
* 主库把 Binlog 复制到从库;
* 从库回放 Binlog,更新存储引擎中的数据。
从库的数据是有可能比主库上的数据旧一些的,这个主从之间复制数据的延迟,称为“主从延迟”。正常情况下,主从延迟基本都是毫秒级别,你可以认为主从就是实时保持同步的。一旦主库或者从库繁忙的时候,有可能会出现明显的主从延迟。如果主库宕机并且主从存在延迟的情况下,切换到从库继续读写,可以保证业务的可用性,但是主从延迟这部分数据就丢失了。此时要么选择不丢数据但是让服务不可用,要么丢一部分数据迅速切到从库让业务继续。
在 MySQL 中,无论是复制还是备份恢复,依赖的都是全量备份和 Binlog,全量备份相当于备份那一时刻的一个数据快照,Binlog 则记录了每次数据更新的变化,也就是操作日志。几乎所有的存储系统和数据库,都是用这一套方法来解决备份恢复和数据复制问题的。MySQL 自身就提供了主从复制的功能,通过配置就可以让一主一备两台 MySQL 的数据库保持数据同步。 高可用依赖的是数据复制,数据复制的本质就是从一个库备份数据,然后恢复到另外一个库中去。
MySQL默认使用异步复制(提交事务和复制这两个流程在不同的线程中执行,互相不会等待),主从延迟基本都是毫秒级别;同步复制(等待从库复制完数据才会返回给客户端,需要很长的等待时间)这种方式在实际项目中基本上没法用,性能太差。MySQL 从 5.7 版本开始,增加一种半同步复制(Semisynchronous Replication)的方式。半同步复制介于二者之间,事务线程不用等着所有的复制成功响应,只要一部分复制响应回来之后,就可以给客户端返回了。
大的电商系统支付完成后是不会自动跳回到订单页的,它增加了一个无关紧要的“支付完成”页面,其实这个页面没有任何有效的信息,就是告诉你支付成功,然后再放一些广告什么的。你如果想再看刚刚支付完成的订单,需要手动点一下,这样就很好地规避了主从同步延迟的问题。