ACL2023 - AMPERE: AMR-Aware Prefix for Generation-Based Event Argument Extraction Model
AMPERE: AMR-Aware Prefix for Generation-Based Event Argument Extraction Model

论文:https://arxiv.org/pdf/2305.16734.pdf
代码:https://github.com/PlusLabNLP/AMPERE
期刊/会议:ACL 2023
摘要
事件论元抽取(EAE)识别给定事件的事件论元及其特定角色。最近在基于生成的EAE模型方面取得的进展显示出了与基于分类的模型相比的良好性能和可推广性。然而,现有的基于生成的EAE模型大多侧重于问题的重新表述和提示设计,而没有纳入已被证明对基于分类的模型有效的额外信息,例如输入段落的抽象语义表示(AMR)。由于基于生成的模型中普遍使用的自然语言形式和AMR的结构化形式的异构性,将这些信息纳入基于生成的模式是具有挑战性的。在这项工作中,我们研究了将AMR纳入基于生成的EAE模型的策略。我们提出了AMPERE,它为生成模型的每一层生成AMR感知前缀。因此,前缀将AMR信息引入到基于生成的EAE模型中,然后改进生成。我们还向AMPERE引入了一种调整后的复制机制,以帮助克服AMR图带来的潜在噪声。对ACE2005和ERE数据集的综合实验和分析表明,在减少训练数据的情况下,AMPERE可以获得4%-10%的F1绝对成绩提高,而且在不同的训练规模下,它通常都很强大。
1、简介
最近,提出了基于生成的EAE模型(Hsu et al, 2022a; Lu et al, 2021; Li et al, 2021; Paolini et al, 2021; Parekh et al, 2022),与传统的基于分类的方法相比,该模型显示出了极大的可推广性和竞争性(Chen et al, 2015; Ma et al, 2020; Hsu et al, 2022b; Fincke et al, 2022)。然而,现有的基于生成的EAE模型大多侧重于问题的重新表述和提示设计,而没有纳入辅助句法和语义信息,这些信息在基于分类的方法中被证明是有效的(Huang et al, 2016; Xu and Huang, 2022; Huang et al, 2018; Ahmad et al, 2021; Veyseh et al, 2020)。
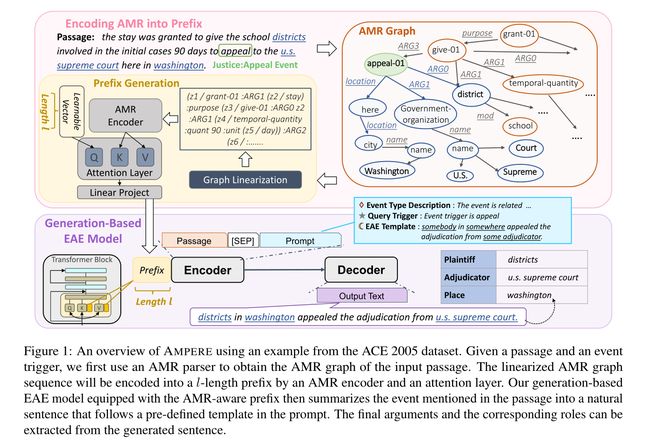
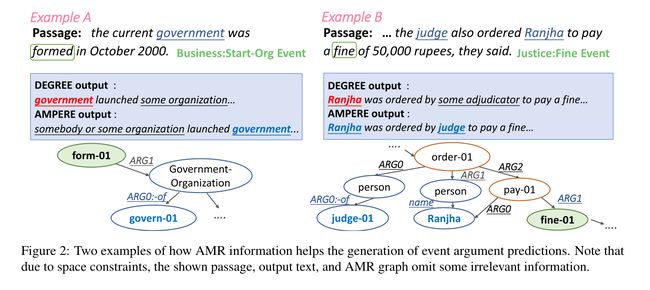
在这项工作中,我们探索了如何将辅助的结构化信息纳入基于生成的EAE模型中。我们关注抽象语义表示(AMR)(Banarescu et al,2013),它从输入句子中提取丰富的语义信息。如图1的示例所示,AMR图总结了输入段落的语义结构,其许多节点和边与事件结构有很强的相似性。例如,触发词appeal可以映射到节点“appeal-01”,appeal的主体可以使用边缘“ARG0”找到。因此,AMR图可以为模型计算事件论元提供重要线索,从而提高基于分类的方法的性能(Zhang and Ji,2021)和更好的可推广性(Huang et al,2018)。然而,目前尚不清楚如何将AMR最好地集成到基于生成的方法中。基于生成的EAE模型中AMR图和自然语言提示之间的异构性造成了模型设计的困难。
为了克服这一挑战,我们提出了AMPERE(AMr-aware Prefix for generation-based Event aRgument Extraction),它将AMR图编码为前缀(Li and Liang,2021),以调节基于生成的EAE模型。具体地,使用额外的AMR编码器将输入AMR图编码为密集向量。然后,这些向量将被分解并作为前缀分发到基于生成的EAE模型中的每个Transformer层。这些生成的前缀被转换为附加的键和值矩阵,以影响注意力计算,从而引导生成。
我们还为AMPERE引入了一种调整后的复制机制,以克服AMR图带来的潜在噪声。具体来说,正如我们在图1中所观察到的,AMR解析器将包括额外的规范化(将washington变成Washington)和单词消歧(使用appeal-01而不是appeal)来创建AMR图。这种规范化可能会影响生成原始输入中没有的一些单词,尤其是在训练数据有限的情况下。因此,我们应用了一种复制机制(See et al, 2017),并添加了一个额外的正则化损失项来鼓励从输入文章中进行复制。
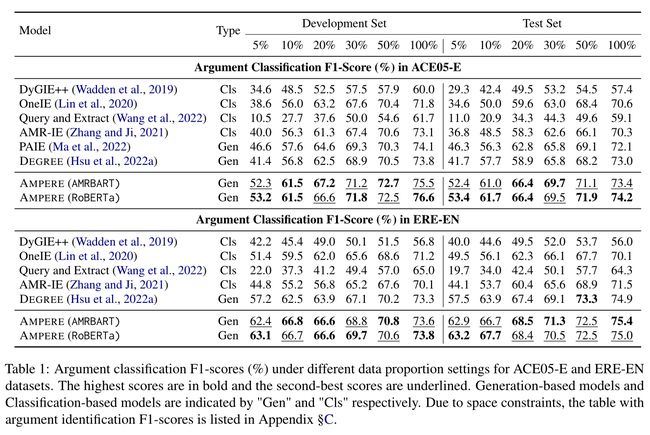
我们使用不同比例的训练数据在ACE 2005(Doddington et al, 2004)和ERE(Song et al, 2015)数据集上进行了实验。我们的结果表明,AMPERE在两个数据集中都优于先前的几种EAE工作。在只使用5%或10%训练数据的低资源设置下,我们可以获得4%-10%的F1绝对改进分数,而且我们的方法在不同的训练规模和不同的数据集上通常都很强大。我们还对将AMR信息纳入基于生成的EAE模型的不同方法进行了全面研究。我们将展示AMPERE是我们探索的各种方法中最好的方法。
2、方法
AMPERE使用DEGREE(Hsu et al. 2022a)作为基于基线生成的EAE模型,并使用AMR感知前缀对其进行扩充,如图1所示。为了生成AMR感知前缀,我们首先使用预训练的AMR解析器来获得输入句子的AMR图。然后,通过图线性化和AMR编码器将图转换为密集向量。然后,这些密集向量将被分解并分布到我们基于基线生成的EAE模型的每一层,因此生成以AMR信息为指导。最后,我们介绍了AMPERE的训练损失和我们调整后的复制机制,该机制可以帮助AMPERE克服AMR图带来的额外噪声。
2.1 基于生成的EAE模型
尽管我们的AMR感知前缀对所使用的基于生成的EAE模型是不可知的,但我们选择DEGREE(Hsu et al. 2022a)作为我们的基线模型,因为它具有很好的可推广性和性能。在这里,我们提供了该模型的简要概述。
给定一段话和一个事件触发词,DEGREE首先准备prompt,其中包括一个事件类型描述(一个描述触发词的句子)和一个特定于事件类型的模板,如图1所示。然后,给定文章和提示,DEGREE按照EAE模板的格式总结文章中的事件,以便通过比较模板和输出文本可以轻松解码最终预测。以图1中的案例为例,通过将“districts in washington appealed the adjudication from u.s. supreme court.”与 “somebody in somewhere appealed the adjudication from some adjudicator.”的模板进行比较,我们可以知道“districts”是“Plaintiff”角色的论点。这是因为在模型的预测中,“Plaintiff”角色的相应占位符“somebody”已被“districts”取代。
2.2 AMR Parsing
我们方法的第一步是准备获得输入段落的AMR图。我们认为SPRING(Bevilacqua et al. 2021)是一个基于BART的AMR解析器,在AMR 3.0标注上进行了训练,是我们的AMR语法分析器。如图1所示,AMR解析器将输入句子编码为AMR图,这是一个有向图,其中每个节点表示一个语义概念(例如,“give01”、“appeal-01”),每个边描述两个概念之间的分类语义关系(例如,ARG0、location)。
2.3 AMR-Aware 前缀生成
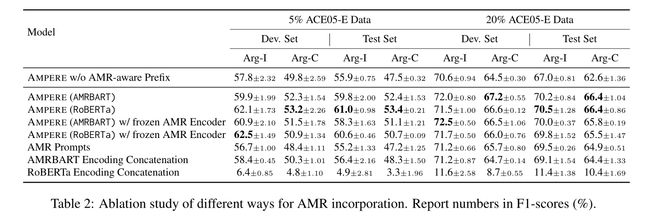
我们的下一步是将信息嵌入到我们基于生成的EAE模型的前缀中(Li and Liang,2021)。为了对AMR图进行编码,我们遵循Konstas等人(2017)的做法,采用深度优先搜索算法将AMR图线性化为序列,如图1中的示例所示。然后,AMR编码器适于对序列的表示进行编码。我们的方法的优点之一是可以灵活地使用与我们基于生成的EAE模型具有不同特征的模型来编码AMR。在这里,我们考虑两个AMR编码器来形成不同版本的AMPERE:
AMPERE(AMRBART):我们考虑使用当前最先进的AMR文本模型的编码器部分——AMRBART(Bai et al. 2022),该模型在AMR 3.0数据上进行了预训练。该模型基于BART-large,并通过添加AMR中的所有关系和语义概念作为额外的标记来扩大其词汇表。使用该模型作为我们的AMR编码器使AMPERE能够利用来自其他任务的知识。
AMPERE(RoBERTa):RoBERTa-large(Liu et al. 2019b)也被认为是我们的AMR编码器,因为预训练的掩蔽语言模型是执行编码任务的典型选择。为了使RoBERTa更好地解释AMR序列,我们遵循Bai等人(2022)将AMR中的所有关系(例如ARG0、ARG1)添加为特殊标记。然而,由于模型没有在丰富的AMR到文本数据上进行预训练,因此我们不将语义概念(例如,以-01结尾的概念)作为额外的标记。
在得到线性化序列的表示后,我们准备 l l l个可学习向量作为查询和注意力层,其中 l l l是控制所用前缀长度的超参数。这些查询将使用线性化的AMR序列的表示来计算注意力,然后,我们将获得一组压缩的密集向量 P \mathbf{P} P。该 P \mathbf{P} P将被转换为前缀(Li and Liang,2021),我们将其注入到基于生成的EAE模型中。
更具体地说,我们首先将 P \mathbf{P} P分解为 L L L个片段,其中 L L L是基于基于生成的EAE模型层数, P = { P 1 , P 2 , … , P L } \mathbf{P}=\{P^1,P^2,\ldots,P^L \} P={P1,P2,…,PL}。然后,在EAE模型的第 n n n层中,前缀被分为两个矩阵,代表附加的键和值矩阵: P n = { K n , V n } P^n=\{K^n,V^n\} Pn={Kn,Vn},其中 K n & V n K^n \& V^n Kn&Vn是附加的键和值域矩阵,它们可以进一步写成 K n = { k 1 n , … , k l n } K^n=\{k^n_1,\ldots,k^n_l\} Kn={k1n,…,kln}和 V n = { v 1 n , … , v l n } V^n=\{v^n_1,\ldots,v^n_l\} Vn={v1n,…,vln}。 k k k和 v v v是在Transformer层中具有相同隐藏维度的向量。这些附加的键和值矩阵将与注意力块中的原始键和值阵连接。因此,在计算点积注意力时,每个位置的查询都会受到这些AMR感知前缀的影响。生成逐层查询和键的原因是为了施加更强的控制。我们生成逐层键值对,因为每一层可能嵌入不同的信息。这些关键点影响模型对相应生成值的表示的加权。关于分层控制与单层控制的实证研究可以在Liu等人(2022b)中找到。
值得注意的是,Li and Liang(2021)的前缀调整技术使用了一组固定的前缀,而不考虑输入句子的变化,当输入段落变化时,AMPERE会生成一组不同的前缀。并且变化反映了不同AMR图的表示。
在我们基于生成的EAE模型中,我们可以将前缀注入编码器自注意块、解码器交叉注意块或解码器自注意块。基于我们的初步实验,我们观察到在编码器自注意块和解码器交叉注意块中使用前缀在AMPERE中效果最好。
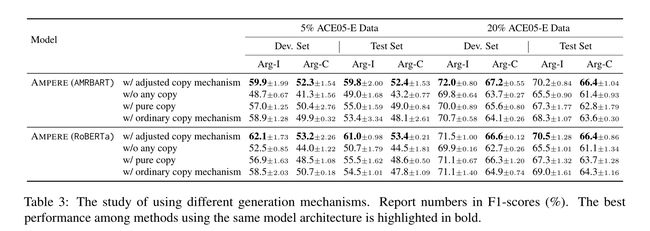
2.4 调整复制机制
我们遵循DEGREE的设置,使用BART-large(Lewis et al. 2020)作为预训练的生成模型,并且我们基于生成的EAE模型的训练目标是在给定先前生成的token和编码器的输入上下文 x 1 , x 2 , … , x m x_1,x_2,\ldots,x_m x1,x2,…,xm的情况下,最大化生成ground-truth的条件概率。
L o s s = − log ( ∑ i P ( y i ∣ y < i , x 1 , … , x m ) ) Loss=-\log ( \sum_i P(y_i|y_{
其中 y i y_i yi是解码器在步骤 i i i的输出。在DEGREE的设置中,预测token t t t的概率完全依赖于生成模型。尽管这种设置更类似于BART-large的预训练方式,从而更好地利用了预训练的效果,但对最终预测的松散约束可能会产生错误文本(Ji et al,2022)或不遵循模板的输出。如果使用更少的训练数据并且呈现更多的输入噪声,例如在合并AMR图时,则这样的问题可能会被放大。
为了增强控制,一种常用的技术是将复制机制(See et al, 2017)应用于基于生成的事件模型(Huang et al, 2022, 2021),
P ( y i = t ∣ y < i , x 1 , … , x m ) = w g e n i P g e n ( y i = t ∣ y < i , x 1 , … , x m ) + ( 1 − w g e n i ) ( ∑ j = 0 m P c o p y i ( j ∣ y < i , x 1 , … , x m ) ) P(y_i=t|y_{
w g e n i ∈ [ 0 , 1 ] w_{gen}^i \in [0,1] wgeni∈[0,1]是生成的概率,通过将最后的解码器隐藏状态传递到附加网络来计算。 P c o p y i ( j ∣ ⋅ ) P_{copy}^i(j|\cdot) Pcopyi(j∣⋅)是复制输入token x j x_j xj的概率,并且它是通过使用时间步骤 i i i的最后一个解码器层中的交叉注意力权重来计算的。当 w g e n i = 1 w^i_{gen}=1 wgeni=1时,它是DEGREE使用的原始模型,而如果 w g e n i = 0 w^i_{gen}=0 wgeni=0,该模型将仅从输入生成token。
我们调整复制机制的核心思想是鼓励模型进行更多的复制,这是通过在AMPERE的损失函数中引入 w g e n i w^i_{gen} wgeni上的正则化项来实现的:
L o s s A M P E R E = − log ( ∑ i P ( y i ∣ Y < i , x 1 , … , x m ) ) + λ ∑ i w g e n i Loss_{AMPERE}=- \log (\sum_i P(y_i|Y_{
λ \lambda λ是超参数。与完全依赖从输入复制相比,我们的方法仍然允许生成模型自由生成输入中没有出现的token。与普通的复制机制相比,额外的正则化将引导模型进行更多的复制。利用这种损失,我们端到端地训练整个AMPERE。
3、实验
4、总结
在本文中,我们介绍了AMPERE,这是一个配备了AMR感知前缀的基于生成的模型。通过我们的全面研究,我们表明前缀可以作为连接AMR信息和生成模型空间的有效媒介,从而实现辅助语义信息与模型的有效集成。此外,我们引入了一种调整后的复制机制,以帮助AMPERE更准确、稳定地生成输出,而不考虑AMR图带来的额外噪声。通过我们的实验,我们表明AMPERE在每个环境中都实现了一致的改进,并且这种改进在低资源环境中尤为明显。
更多CV和NLP论文解读