nn.AdaptiveAvgPool2d与AdaptiveMaxPool2d
关于PyTorch含有的自适应池化Adaptive Pooling池化层
学习目标:自适应池化层
疑惑:在设计神经网络模型的时候,往往需要将特征图与分类对应上,即需要卷积层到全连接层的过渡。但在这个过渡期,不知道首个全连接层的初始化输入设置为多少?
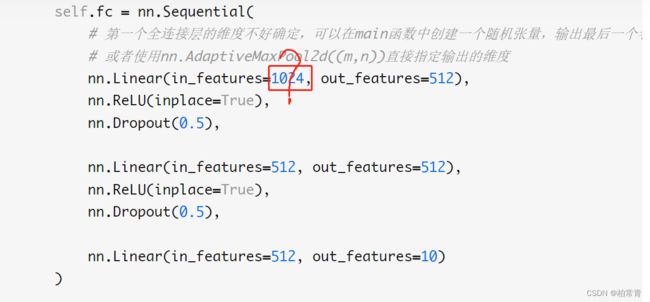
- 学会使用pytorch的自适应池化层nn.AdaptiveMaxPool指定输出的维度,学会读神经网络模型层与层之间的变化。
学习内容:代码示例
提示:网络模型分为三部分,特征提取层,过渡层conv,全连接层
- 模型源码:
class KpClassify(nn.Module):
def __init__(self):
super().__init__()
self.feature = KeyPointsModel() # 特征提取网络
self.conv = nn.Sequential(
nn.Conv2d(in_channels=24, out_channels=48, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=48), # 输入图像的通道数量
nn.ReLU(inplace=True), # 此处inplace,选择是否覆盖。表示Relu得到的结果是否覆盖Relu之前的结果
# 使用inplace=True进行覆盖,可以节约内存,不需要单独创建变量保存数据
nn.Conv2d(in_channels=48, out_channels=48, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=48),
nn.ReLU(inplace=True),
# 如果想直接确定全连接层的维度,可以使用自适应池化,无论前面的卷积池化的维度变成什么,最后的输出维度都是batchsize*channels*n*n
# 将每个通道的输出特征固定为n*n.n=9
nn.AdaptiveMaxPool2d((9, 9))
)
self.fc = nn.Sequential(
nn.Linear(in_features=48 * 9 * 9, out_features=512), # 首个Linear的输入为:通道数*池化输出,即48*9*9
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(in_features=512, out_features=512),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(in_features=512, out_features=9)
)
def forward(self, x):
x = self.feature(x)
x = self.conv(x)
# x.size()默认是批量的大小.按批量展开数据即可得到输入全连接的维度
x = x.view(x.size()[0], -1)
x = self.fc(x)
return x
这里的特征提取层,可以是其他写好的模型,我这里是前面博客提到的关键点特征提取的模型KeyPointsModel。
class KeyPointsModel(nn.Module):
def __init__(self):
super(KeyPointsModel, self).__init__()
# these layers have no relu layer
no_relu_layers = ['conv6_2_CPM', 'Mconv7_stage2', 'Mconv7_stage3',
'Mconv7_stage4', 'Mconv7_stage5', 'Mconv7_stage6']
self.maxpool = nn.MaxPool2d(kernel_size=2, stride=2, padding=0, return_indices=True)
self.maxunpool = nn.MaxUnpool2d(2, stride=2)
# stage 1
block1_0_0 = OrderedDict([
('conv1_1', [3, 64, 3, 1, 1]),
('conv1_2', [64, 64, 3, 1, 1]),
])
block1_0_1 = OrderedDict([
('conv2_1', [64, 128, 3, 1, 1]),
('conv2_2', [128, 128, 3, 1, 1]),
])
block1_0_2 = OrderedDict([
('conv3_1', [128, 256, 3, 1, 1]),
('conv3_2', [256, 256, 3, 1, 1]),
('conv3_3', [256, 256, 3, 1, 1]),
('conv3_4', [256, 256, 3, 1, 1]),
])
block1_0_3 = OrderedDict([
('conv4_1', [256, 512, 3, 1, 1]),
('conv4_2', [512, 512, 3, 1, 1]),
('conv4_3', [512, 512, 3, 1, 1]),
('conv4_4', [512, 512, 3, 1, 1]),
('conv5_1', [512, 512, 3, 1, 1]),
('conv5_2', [512, 512, 3, 1, 1]),
('conv5_3_CPM', [512, 128, 3, 1, 1])
])
block1_1 = OrderedDict([
('conv6_1_CPM', [128, 512, 1, 1, 0]),
('conv6_2_CPM', [512, 24, 1, 1, 0])
])
blocks = {}
blocks['block1_0_0'] = block1_0_0
blocks['block1_0_1'] = block1_0_1
blocks['block1_0_2'] = block1_0_2
blocks['block1_0_3'] = block1_0_3
blocks['block1_1'] = block1_1
# stage 2-6
for i in range(2, 7):
blocks['block%d' % i] = OrderedDict([
('Mconv1_stage%d' % i, [152, 128, 7, 1, 3]),
('Mconv2_stage%d' % i, [128, 128, 7, 1, 3]),
('Mconv3_stage%d' % i, [128, 128, 7, 1, 3]),
('Mconv4_stage%d' % i, [128, 128, 7, 1, 3]),
('Mconv5_stage%d' % i, [128, 128, 7, 1, 3]),
('Mconv6_stage%d' % i, [128, 128, 1, 1, 0]),
('Mconv7_stage%d' % i, [128, 24, 1, 1, 0])
])
for k in blocks.keys():
blocks[k] = make_layers(blocks[k], no_relu_layers)
self.model1_0_0 = blocks['block1_0_0']
self.model1_0_1 = blocks['block1_0_1']
self.model1_0_2 = blocks['block1_0_2']
self.model1_0_3 = blocks['block1_0_3']
self.model1_1 = blocks['block1_1']
self.model2 = blocks['block2']
self.model3 = blocks['block3']
self.model4 = blocks['block4']
self.model5 = blocks['block5']
self.model6 = blocks['block6']
def forward(self, x):
# block0
out1_0_0 = self.model1_0_0(x)
output, indices = self.maxpool(out1_0_0)
output_un_pool = self.maxunpool(output, indices)
out1_0_1 = self.model1_0_1(output_un_pool)
output, indices = self.maxpool(out1_0_1)
output_un_pool = self.maxunpool(output, indices)
out1_0_2 = self.model1_0_2(output_un_pool)
output, indices = self.maxpool(out1_0_2)
output_un_pool = self.maxunpool(output, indices)
out1_0 = self.model1_0_3(output_un_pool)
# block1
out1_1 = self.model1_1(out1_0)
concat_stage2 = torch.cat([out1_1, out1_0], 1)
out_stage2 = self.model2(concat_stage2)
concat_stage3 = torch.cat([out_stage2, out1_0], 1)
out_stage3 = self.model3(concat_stage3)
concat_stage4 = torch.cat([out_stage3, out1_0], 1)
out_stage4 = self.model4(concat_stage4)
concat_stage5 = torch.cat([out_stage4, out1_0], 1)
out_stage5 = self.model5(concat_stage5)
concat_stage6 = torch.cat([out_stage5, out1_0], 1)
out_stage6 = self.model6(concat_stage6)
return out_stage6
2.注意事项
注意点1:自适应池化层的作用和使用方法

注意点2:非常重要的函数,相当于特征图扁平化过程,x = x.view(x.size()[0], -1),不起眼,但作用大,容易忽略
- 测试模型输出

进阶:
-
关于BatchNormal2d的作用:
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
功能:对输入的四维数组进行批量标准化处理。对于所有的batch中样本的同一个channel的数据元素进行标准化处理,即如果有C个通道,无论batch中有多少个样本,都会在通道维度上进行标准化处理,一共进行C次。 -
在PyTorch中有六种形式的自适应池化Adaptive Pooling
自适应最大池化Adaptive Max Pooling:
torch.nn.AdaptiveMaxPool1d(output_size)
torch.nn.AdaptiveMaxPool2d(output_size)
torch.nn.AdaptiveMaxPool3d(output_size)自适应平均池化Adaptive Average Pooling:
torch.nn.AdaptiveAvgPool1d(output_size)
torch.nn.AdaptiveAvgPool2d(output_size)
torch.nn.AdaptiveAvgPool3d(output_size)