hive load data inpath 空目录_Hive快速入门
导读
什么是Hive?
Hive是如何运行的?
Hive如何使用?【重点】
什么是Hive?
一句话来说,Hive是基于Hadoop的数据仓库,和MySQL语法相似,但是是完全不同的两种东西,Hive是在HDFS上层的封装
实质:将HQL语句转换为MR程序,如下图所示

我想大家肯定有疑问,为啥需要用HIve?
Hive主要就是写SQL,简单易上手,比写代码方便,相对于繁杂的MR任务来说
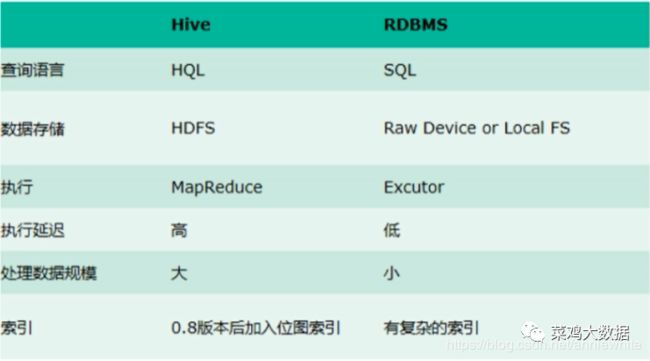
Hive和RDMS数据库的区别?
除了SQL语句高度相似外没有任何联系,具体区别见下图
Hive由哪几部分组成?
学习过MySQL的同学应该对下图高度熟悉,和MySQL非常类似
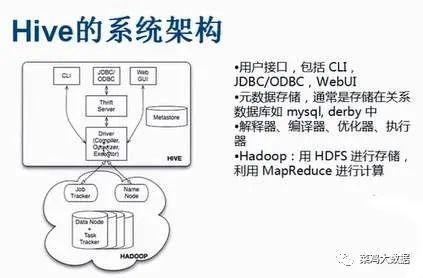
具体几部分功能:
client:这个毫无疑问,就是提供接口供用户访问的
Meta Store:存储元数据,信息包括 DataBase,表名,列类型以及表的分区所在目录
Driver 完成HQL查询语句的编译,优化,以及生成逻辑执行计划的生成
具体分为以下几部分,解释器:将HiveSQL语句转换为抽象语法树AST
编译器:将AST编译为逻辑执行计划
优化器:对逻辑执行计划进行优化
执行器:调用底层的运行框架执行逻辑执行计划
Hive真的很香吗?
不然Hive也是有缺点的,也就是只能查数据,不支持增删改,当然也就不存在事务了
Hive是如何运行的?
上图
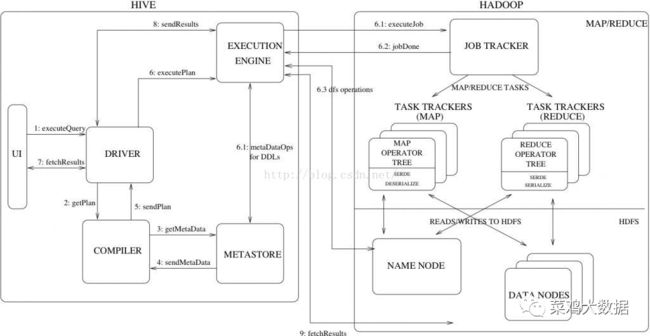
步骤:
1. 用户提交查询等任务给Driver。
2. 编译器获得该用户的任务Plan。
3. 编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
4. 编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
5. 将最终的计划提交给Driver。
6. Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作
7. 获取执行的结果。
8. 取得并返回执行结果。
Hive使用指南
Hive三大操作,建表,导入数据,写查询,以写查询最为重要,也最难
库的相关操作
创建库
create database if not exists mydb;查看库
show databases;切换库
use mydb;和MySQL一摸一样,没啥好说的
主要是表的操作
先说明以下,Hive除了和MySQL类似支持常见的字段外,还支持以下几种复杂数据类型,支持格式多样化了,但是处理起来就有点难度了

我们都知道,表操作最常用的就是建表,相比于MySQL,HQL有以下不同
首先是表的种类,Hive有好几种表,内部表,外部表,分区表,分桶表
先说概念上的区别,SQL语句的区别稍后说
内部表和外部表区别
删除内部表,数据和元数据都删除
删除外部表,只删除元数据
如何选择?
内部表:对原始数据或比较重要的中间数据进行建表存储;
外部表:比如某个公司的原始日志数据存放在一个目录中,多个部门对这些原始数据进行分析,那么创建外部表是明智选择,这样原始数据不会被删除;
分区和分桶表的区别?
分桶就是更细粒度的分区,说白了目的就是为了加快查询速度,没有其他作用
创表语句
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]详解:
第一行语句很熟悉,只不过EXTERNAL是什么意思,这就是外部表,添加一个关键字就创建了外部表,创建外部表,在建表的同时指定一个指向实际数据的目录(LOCATION),如果该目录不存在,则自动创建该目录。
第二行就是字段啦,没什么好说的,第二行就是注释,也略过
第四行什么鬼?这就是前文提到的分区表,通过PARTITIONED BY来声明
第五行就是分桶表,Hive 采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中
cluster by 用来指定分桶字段
sorted by 用来指定每个分桶按照什么字段排序
into ... buckets 用来指定分桶的个数
ROW FORMAT是什么意思呢?我要和您掰扯掰扯,对于MySQL来说,直接插入的就是字段,对于Hive来说,插入的是文本为主,好家伙,你想Hive也是一个表结构,他咋能认识文本呢?就得靠字段分隔符进行划分,这就是它起的作用,ROW FORMAT后面有两种形式,DELIMITED 和 SERDE
DELIMITED 形式为:指定分隔符,使用切割的方式解析文本文件,有以下几种方式
DELIMITED [FIELDS TERMINATED BY char] //按字段切分 [COLLECTION ITEMS TERMINATED BY char] //集合元素切分 [MAP KEYS TERMINATED BY char] //Map key value之间切分符 [LINES TERMINATED BY char] //按行切分SERDE形式为:序列化组件,就是一种解析数据的方式,非切割方式,比如正则
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT或者ROW
FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表
的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]STORE AS就是指保存的格式,目前支持TEXTFILE | SEQUENCEFILE | RCFILE | PARQUETFILE
LOCATION指定的是存放的HDFS目录
一个具体的Demo
CREATE TABLE student( name STRING, favors ARRAY, scores MAP, address STRUCTSTRING, city: )ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ';' MAP KEYS TERMINATED BY ':' ; 加载数据
语句结构
L
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]这个显然就很好理解了,说一下overwrite也就是是否覆盖原来的结果
除了LOAD加载数据,还有Insert插入数据
简单版:
INSERT OVERWRITE [INTO] TABLE table_name [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement//示例insert into table student_copy select * from student where age <= 18;复杂版:就是多个查询插入数据,同时可以看到插入到了指定的分区;
// 语法结构:FROM from_statement INSERT OVERWRITE TABLE table_name1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 INSERT OVERWRITE TABLE table_name2 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement2] .... // 实例:from student insert into table student_ptn partition(city='MA') select id,name,sex,age,department where department='MA' insert into table student_ptn partition(city='IS') select id,name,sex,age,department where department='IS' insert into table student_ptn partition(city='CS') select id,name,sex,age,department where department='CS';等等,好像有点麻烦,比如如果我要插入100个分区,难不成我要写100个Insert,这是不科学的!!
Hive有动态分区机制
前提条件,你要开启,不然报错到你怀疑人生,下图为开启配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
接下来就简单了,AMIZING
insert into table test2 partition (age) select name,address,school,age from students;还没有完,还有分桶表
注意:往分桶表中插入数据:请注意不能使用 load 方式直接往分分桶表中导入数据。只能通过
insert....select.... 语法来进行
insert into table student_bck select id,name,sex,age,department from student distribute by age sort by age desc, id asc;查询
和MySQL高度类似啦,给个Demo看一下就好。
SELECT [ALL | DISTINCT] select_ condition, select_ condition, ...FROM table_name a [JOIN table_other b ON a.id = b.id] [WHERE where_condition] [GROUP BY col_list [HAVING condition]][CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list | ORDER BY col_list] ] [LIMIT number]