【深度学习】深度强化学习初学者指南
一、说明
GAN(Generative Adversarial Networks)是一种深度学习模型,它由两个神经网络组成:一个生成网络和一个判别网络。生成网络学习如何生成类似于给定数据集的新数据,而判别网络则学习如何区分生成网络生成的数据和原始数据。这两个网络相互竞争,使得生成器越来越接近于生成真实数据,判别器越来越接近于准确地识别真实数据和生成数据。GAN 已经在许多领域中取得了成功,如图像处理、自然语言处理等。
二、模型发展史介绍
深度强化学习将人工神经网络与强化学习框架相结合,帮助软件代理学习如何实现目标。也就是说,它将函数近似和目标优化结合在一起,将状态和操作映射到它们带来的奖励。
你可能不理解所有这些术语,但它们将在下面以更深入和更通俗易懂的语言进行解释,利用你作为一个个体在世界上移动的个人经历。
虽然神经网络是最近人工智能在计算机视觉、机器翻译和时间序列预测等问题上取得突破的原因,但它们也可以与强化学习算法相结合,创造出像Deepmind的AlphaGo这样令人震惊的东西,这种算法击败了围棋棋盘游戏的世界冠军。这就是为什么你应该关心深度RL。
强化学习是指面向目标的算法,它学习如何实现复杂的目标(目标)或如何在许多步骤中沿特定维度最大化;例如,他们可以在游戏中通过多次移动最大化赢得的分数。强化学习算法可以从一张白纸开始,在适当的条件下,实现超人的表现。就像被责骂和对待激励的宠物一样,这些算法在做出错误决定时受到惩罚,在做出正确决定时受到奖励——这就是强化。
结合深度神经网络的强化算法可以击败玩众多雅达利视频游戏、星际争霸 II 和 Dota-2 的人类专家。虽然这对非游戏玩家来说听起来微不足道,但它比强化学习以前的成就有了巨大的进步,而且最先进的技术正在迅速发展。
强化学习解决了将即时行动与其产生的延迟结果相关联的难题。像人类一样,强化学习算法有时必须等待才能看到他们决策的结果。它们在延迟返回的环境中运作,在这种环境中,可能很难理解在许多时间步长中哪种行动会导致哪种结果。
强化学习算法在更模糊的现实生活中慢慢地表现得越来越好,同时从任意数量的可能动作中进行选择,而不是从可重复视频游戏的有限选项中进行选择。也就是说,他们开始在现实世界中实现目标。如果您有可衡量的 KPI 要达到,深度强化学习可能会有所帮助。DeepMind 在 2021 年 <> 月声称,强化学习可能足以实现通用人工智能 (AGI)。
公司开始将深度强化学习应用于工业问题。
Pieter Abbeel的协变在工业机器人中使用深度RL。Pathmind将深度强化学习应用于工业运营和供应链的模拟,以优化工厂,仓库和物流。谷歌正在将深度强化学习应用于机器人运动和芯片设计等问题,而Microsoft则依靠深度强化学习为其自主控制系统技术提供动力。
三、强化学习基本术语
3.1 强化学习的定义
强化学习可以通过代理、环境、状态、行动和奖励的概念来理解,所有这些都将在下面解释。大写字母倾向于表示事物的集合,小写字母表示该事物的特定实例;例如 是所有可能的动作,而 是集合中包含的特定动作。Aa
- 代理:代理执行操作;例如,送货的无人机,或导航视频游戏的超级马里奥。算法是代理。考虑到在生活中,代理人是你,可能会有所帮助。1
- 动作(A):是代理可以进行的所有可能动作的集合。操作几乎是不言自明的,但应该注意的是,代理通常从离散的、可能的操作列表中进行选择。在视频游戏中,该列表可能包括向右或向左奔跑、跳高或跳低、蹲下或站立不动。在股票市场中,该清单可能包括购买、出售或持有一系列证券及其衍生品中的任何一种。在处理空中无人机时,替代方案将包括3D空间中的许多不同的速度和加速度。
A - 折扣系数:折扣系数乘以代理商发现的未来奖励,以抑制奖励对代理选择行动的影响。 为什么?它旨在使未来的奖励价值低于即时奖励;也就是说,它在代理人中强制执行一种短期享乐主义。通常用小写希腊字母 gamma 表示:γ.如果γ是 .8,并且在 10 个时间步长后有 3 分的奖励,则该奖励的现值为 。折扣系数为 1 将使未来的奖励与即时奖励一样有价值。我们在这里与延迟满足作斗争。
0.8³ x 10 - 环境:代理在其中移动并响应代理的世界。环境将代理的当前状态和操作作为输入,并将代理的奖励及其下一个状态作为输出返回。如果你是主体,环境可能是处理你的行为并决定其后果的物理定律和社会规则。
- 状态(S):状态是主体发现自己所处的具体而直接的情况;即一个特定的地点和时刻,一个瞬间的配置,将代理与其他重要事物(如工具、障碍物、敌人或奖品)联系起来。它可以是环境返回的当前情况,也可以是未来任何情况。您是否曾经在错误的时间出现在错误的地方?这是一种状态。
- 奖励(R):奖励是我们衡量代理在给定状态下行为成功或失败的反馈。例如,在视频游戏中,当马里奥触摸硬币时,他会赢得积分。从任何给定状态,代理以操作的形式向环境发送输出,环境返回代理的新状态(由对先前状态执行操作的结果)以及奖励(如果有)。奖励可以是立即的,也可以是延迟的。他们有效地评估代理的行为。
- 策略 (π):策略是代理用来根据当前状态确定下一步操作的策略。它将状态映射到行动,即承诺最高回报的行动。
- 价值(V):带折扣的预期长期回报,与短期回报相对。 定义为政策下当前状态的预期长期回报。我们会打折奖励,或者降低其估计价值,它们发生得越远。请参阅折扣系数。请记住凯恩斯:“从长远来看,我们都死了。这就是您打折未来奖励的原因。区分很有用
RVπ(s)π - Q 值或操作值 (Q):Q 值类似于 Value,只是它需要一个额外的参数,即当前操作。 指根据策略采取行动 A 从当前状态长期返回。Q 将状态-操作对映射到奖励。请注意 Q 和策略之间的区别。
aQπ(s, a)πs - 轨迹:影响这些状态的状态和操作的序列。来自拉丁语“扔横”。特工的生命不过是一个高高抛起的球,在时空中拱起,没有停泊,很像现代世界的人类。
- 主要区别:奖励是在给定状态下收到的即时信号,而价值是您可能期望从该状态获得的所有奖励的总和。价值是一种长期的期望,而奖励是一种即时的乐趣。价值是晚餐吃菠菜沙拉,期待健康长寿;奖励是晚餐吃可卡因,然后见鬼去吧。它们在时间跨度上有所不同。因此,您可能会遇到价值和奖励分歧的状态:即使您转到具有长期价值潜力的职位,您也可能获得低而即时的奖励(菠菜);或者您可能会获得很高的即时奖励(可卡因),随着时间的推移导致前景减少。这就是为什么价值函数,而不是即时奖励,是强化学习试图预测和控制的。
因此,环境是将当前状态下采取的行动转换为下一个状态和奖励的功能;代理是将新状态和奖励转换为下一个操作的函数。我们可以知道并设置代理的功能,但是在大多数情况下,应用强化学习是有用和有趣的,我们不知道环境的功能。这是一个黑匣子,我们只能看到输入和输出。这就像大多数人与技术的关系:我们知道它做什么,但我们不知道它是如何工作的。强化学习代表了智能体试图近似环境的功能,这样我们就可以将动作发送到黑匣子环境中,从而最大化它吐出的奖励。

在上面的反馈循环中,下标表示时间步长和,每个时间步长都表示不同的状态:时刻的状态和时刻的状态。与其他形式的机器学习(如监督和无监督学习)不同,强化学习只能根据一个接一个发生的状态-动作对来按顺序考虑。tt+1tt+1
强化学习根据它们产生的结果来判断行为。它是面向目标的,其目的是学习一系列行动,引导智能体实现其目标,或最大化其目标功能。以下是一些示例:
- 在电子游戏中,目标是以最多的分数完成游戏,因此在整个游戏中每增加一点积分都会影响代理的后续行为;也就是说,特工可能会知道它应该射击战舰、触摸硬币或躲避流星以最大化其分数。
- 在现实世界中,目标可能是让机器人从A点移动到B点,机器人能够靠近B点的每一英寸都可以算作点。
下面是一个用于强化学习的目标函数示例;即它定义目标的方式。
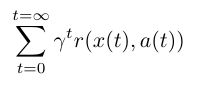
我们将奖励函数 r 与 t 相加,它代表时间步长。因此,这个目标函数计算了我们可以通过运行游戏获得的所有奖励。在这里,x 是给定时间步长的状态,a 是在该状态下执行的操作。r 是 x 和 a 的奖励函数。(我们暂时忽略γ。
强化学习与监督学习和无监督学习的不同之处在于它如何解释输入。我们可以通过描述他们对“事物”的了解来说明他们的区别。
- 无监督学习:那件事就像另一件事。(这些算法学习没有名称的相似性,并且通过扩展,它们可以发现反向并通过识别异常或不同之处来执行异常检测)
- 监督学习:那个东西是“双培根芝士汉堡”。(标签,把名字放在脸上...这些算法学习数据实例与其标签之间的相关性;也就是说,它们需要一个标记的数据集。这些标签用于“监督”和纠正算法,因为它在预测标签时会做出错误的猜测。
- 强化学习:吃那个东西,因为它味道很好,会让你活得更久。(基于短期和长期奖励的行动,例如您摄入的卡路里量或您生存的时间长度。强化学习可以被认为是稀疏反馈环境中的监督学习。
3.2 强化学习的领域选择
想象自主强化学习代理的一种方法是,一个盲人试图只用耳朵和一根白色手杖在世界上航行。代理有小窗口,可以让他们感知周围的环境,这些窗口甚至可能不是他们感知周围事物的最合适方式。
(事实上,决定你的座席应该注意哪些类型的输入和反馈是一个很难解决的问题。这称为域选择。正在学习如何玩视频游戏的算法大多可以忽略这个问题,因为环境是人为的并且受到严格限制。因此,视频游戏提供了实验室的无菌环境,在那里可以测试有关强化学习的想法。领域选择需要人类决策,通常基于有关要解决的问题的知识或理论;例如,为自动驾驶汽车中的算法选择输入域可能包括选择除了摄像头和GPS数据之外还包括雷达传感器。

四、状态-行动对和奖励的复杂概率分布
强化学习的目标是为任何给定状态选择最知名的操作,这意味着必须对操作进行排名,并相对于彼此分配值。由于这些操作是依赖于状态的,因此我们真正衡量的是状态-操作对的值;即从某种状态采取的操作,您在某处执行的操作。以下是一些示例,以证明操作的价值和意义取决于执行该操作的状态:
-
如果行动是嫁给某人,那么在35岁时嫁给一个18岁的人可能意味着与35岁时嫁给一个90岁的人不同,这两种结果可能有不同的动机并导致不同的结果。
-
如果动作是大喊“开火!”,那么在拥挤的剧院里表演动作应该意味着与在一队拿着步枪的人旁边表演动作不同。如果不了解上下文,我们就无法预测行动的结果。
我们将状态-操作对映射到我们期望它们使用 Q 函数生成的值,如上所述。Q 函数将代理的状态和操作作为其输入,并将它们映射到可能的奖励。
强化学习是通过一系列状态-操作对运行代理的过程,观察结果的奖励,并使 Q 函数的预测适应这些奖励,直到它准确地预测代理采取的最佳路径。这种预测被称为政策。
强化学习是一种尝试,用于模拟与大量状态-操作对相关的奖励的复杂概率分布。这就是强化学习与马尔可夫决策过程配对的原因之一,马尔可夫决策过程是一种从复杂分布中采样以推断其属性的方法。它与激发斯坦·乌拉姆发明蒙特卡洛方法的问题非常相似;也就是说,试图推断纸牌的给定一手牌成功的机会。
任何统计方法本质上都是对无知的承认。某些现象(生物、政治、社会学或与棋盘游戏有关)的巨大复杂性使得无法从第一原理进行推理。研究它们的唯一方法是通过统计,测量表面事件并试图在它们之间建立相关性,即使我们不了解它们相关的机制。强化学习,就像深度神经网络一样,就是这样一种策略,它依靠采样从数据中提取信息。
在花费一些时间使用马尔可夫决策过程之类的东西来近似状态-行动对上的奖励概率分布之后,强化学习算法可能倾向于重复导致奖励并停止测试替代方案的操作。在利用已知奖励和继续探索以发现也会导致胜利的新行动之间存在着紧张关系。正如石油公司具有在钻探新储量的同时从已知油田抽出原油的双重功能一样,也可以使强化学习算法在不同程度上进行开发和勘探,以确保它们不会以牺牲已知赢家为代价来放弃奖励行动。
强化学习是迭代的。在其最有趣的应用中,它并不是从知道状态-操作对将产生哪些奖励开始的。它通过一次又一次地运行状态来学习这些关系,就像运动员或音乐家迭代状态以试图提高他们的表现一样。
五、机器学习与时间的关系
你可以说算法是一种更快地聚合时间课程的方法。2强化学习算法与时间的关系与人类不同。算法可以在试验不同动作的同时一遍又一遍地运行相同的状态,直到它可以推断出哪些动作最好从哪些状态中。实际上,算法享受自己的土拨鼠日,在那里他们从愚蠢的混蛋开始,慢慢变得聪明。
由于人类从未在电影之外体验过土拨鼠日,强化学习算法有可能比人类学到更多、更好。事实上,这些算法相对于人类的真正优势并不在于它们的固有天性,而是源于它们同时在许多芯片上并行生活的能力,能够日夜训练而不会感到疲劳,从而学习更多。在围棋游戏中训练的算法,如AlphaGo,将比任何人希望在100辈子中完成的围棋游戏要多得多。3
六、神经网络和深度强化学习
神经网络适合在哪里?神经网络是函数逼近器,当状态空间或动作空间太大而无法完全知道时,它在强化学习中特别有用。
神经网络可用于近似值函数或策略函数。也就是说,神经网络可以学习将状态映射到值,或将状态-操作对映射到 Q 值。与其使用查找表来存储、索引和更新所有可能的状态及其值,这在非常大的问题中是不可能的,我们可以在状态或动作空间的样本上训练神经网络,以学习预测这些相对于我们在强化学习中的目标的价值。
像所有神经网络一样,他们使用系数来近似将输入与输出相关的函数,他们的学习包括通过沿着梯度迭代调整这些权重来找到正确的系数或权重,从而承诺减少误差。
在强化学习中,卷积网络可用于在输入是视觉时识别代理的状态;例如,马里奥所在的屏幕,或无人机之前的地形。也就是说,它们执行图像识别的典型任务。
但是卷积网络从强化学习中的图像中获得的解释与监督学习中的图像不同。在监督学习中,网络将标签应用于图像;也就是说,它将名称与像素匹配。

事实上,它将根据概率对最适合图像的标签进行排名。显示驴的图像,它可能会决定图片 80% 可能是驴,50% 可能是马,30% 可能是狗。
在强化学习中,给定代表状态的图像,卷积网络可以对在该状态下可能执行的动作进行排序;例如,它可能会预测向右跑将返回 5 分,跳跃 7 分,向左跑将返回任何分。
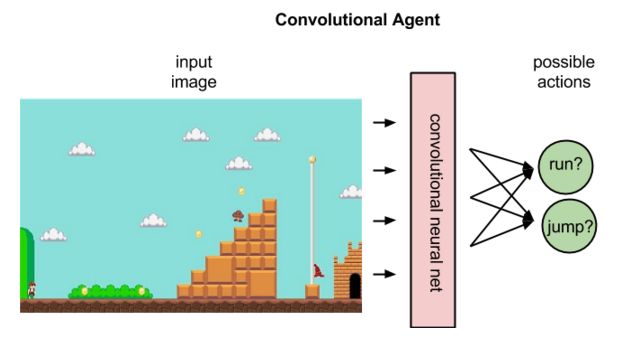
上图说明了策略代理执行的操作,将状态映射到最佳操作。
![]()
策略将状态映射到操作。
如果您还记得,这与 Q 不同,Q 将状态操作对映射到奖励。
更具体地说,Q 将状态-操作对映射到即时奖励与轨迹中后续操作可能收获的所有未来奖励的最高组合。这是来自维基百科的Q的等式:

为预期奖励赋值后,Q 函数只需选择具有最高所谓 Q 值的状态-操作对。
在强化学习开始时,神经网络系数可以随机或随机初始化。利用来自环境的反馈,神经网络可以利用其预期奖励和真实奖励之间的差异来调整其权重并改进其对状态-操作对的解释。
这种反馈循环类似于监督学习中错误的反向传播。然而,监督学习始于神经网络试图预测的地面真相标签的知识。它的目标是创建一个模型,将不同的图像映射到它们各自的名称。
强化学习依赖于环境向其发送标量数字以响应每个新操作。环境返回的奖励可能会变化、延迟或受到未知变量的影响,从而将噪声引入反馈回路。
这导致我们得到 Q 函数的更完整表达式,它不仅考虑了动作产生的即时奖励,还考虑了可能在序列中更深几个时间步长返回的延迟奖励。
像人类一样,Q函数是递归的。就像调用 wetware 方法中包含另一个方法一样,我们都是其中的果实,在给定的状态-操作对上调用 Q 函数需要我们调用嵌套的 Q 函数来预测下一个状态的值,这反过来又取决于之后状态的 Q 函数, 等等。human()human()
七、真实世界的强化学习应用
强化学习是关于做出顺序决策,以通过许多步骤实现目标。虽然其他类型的人工智能执行你可能称之为感知的任务,比如识别图像的内容,但强化学习执行战术和战略任务。游戏是强化学习可以解决的问题的一个很好的代表,但强化学习也被应用于私营和公共部门的现实世界过程。
- 机器人
- 工业运营
- 供应链与物流
- 交通管制
- 竞价和广告
- 推荐系统
- 负载平衡
- 增强型自然语言处理
九、脚注
1)想象一个强化学习算法在行动,以视觉方式描绘它可能会有所帮助。假设算法正在学习玩视频游戏超级马里奥。它试图让马里奥通过游戏并获得最多的积分。为此,我们可以并行启动许多不同的马里奥,并在所有可能的游戏状态的空间中运行它们。这就好像你有1个马里奥在一座山上挖隧道,当他们挖掘时(例如,当他们一次又一次地决定采取哪种行动来影响游戏环境时),他们的经验隧道就像一棵错综复杂和分形的树枝一样分支。马里奥的体验隧道是穿过山脉的光走廊。就像在生活中一样,一个成功的行动可能会使成功的行动更有可能在更大的决策流中成为可能,从而推动获胜的马里奥斯继续前进。你也可以想象,如果每个马里奥都是一个特工,那么在他面前是一个热图,跟踪他可以与状态行动对相关联的奖励。(想象一下,每个状态操作对都有自己的屏幕,上面覆盖着从黄色到红色的热量。许多屏幕组装在一个网格中,就像你可能在华尔街交易员面前看到的那样,有许多显示器。一个动作屏幕可能是“从这个状态跳得更厉害”,另一个可能是“在这个状态下跑得更快”,依此类推。由于一些状态-行动对比其他状态-行动对导致更多的奖励,并且可以采取不同类型的动作,如跳跃、蹲下或跑步,因此奖励对动作的概率分布不是钟形曲线,而是复杂的,这就是为什么使用马尔可夫和蒙特卡洛技术来探索它,就像斯坦乌拉姆探索赢得纸牌一样。也就是说,虽然很难在公式中描述奖励分布,但可以对其进行采样。由于算法开始时是无知的,并且许多通过游戏状态空间的路径尚未探索,因此热图将反映他们缺乏经验;也就是说,他们想象的奖励的热图中可能有空白,或者他们可能只是从一些关于奖励的默认假设开始,这些假设会随着经验而调整。马里奥本质上是由这些热图引导的寻求奖励的导弹,它们在游戏中运行的次数越多,他们未来潜在奖励的热图就越准确。热图基本上是马里奥当前状态中可能的状态-操作对奖励的概率分布。
2)技术使时间和空间崩溃,乔伊斯称之为“不可避免的存在方式”。我们所说的崩溃是什么意思?很长的距离开始表现得像非常短的距离,长周期被加速变成短周期。例如,无线电波使人们能够远距离与他人交谈,就好像他们在同一个房间里一样。其他波长也是如此,最近由光纤电缆启用的视频电话会议也是如此。虽然距离没有被抹去,但对于某些活动来说,距离并不重要。任何数量的技术都可以节省时间。家用电器是将长任务变成短任务的技术的一个很好的例子。但计算也是如此。计算速度或硅处理信息的速度稳步提高。通过并行计算,可以进一步提高速度;即分解计算工作负载并将其分布在多个芯片上以同时处理。并行化硬件是一种并行化时间的方法。这对于需要处理非常大的数据集的算法以及性能随经验而提高的算法特别有用且相关。AI智库OpenAI训练了一种算法来玩流行的多人视频游戏Data 2个月,每天该算法玩的游戏相当于10年的游戏。在这180个月结束时,该算法(称为OpenAI Five)击败了世界冠军人类团队。这一胜利是并行化和加速时间的结果,因此算法可以利用比任何单个人希望收集的更多的经验来获胜。
3)正确的类比实际上可能是学习算法就像一个物种。算法在学习时运行的每个模拟都可以被视为物种的个体。正如算法贯穿游戏的知识被收集到算法的世界模型中一样,任何群体的个体人类都将通过语言进行报告,从而使集体的世界模型,体现在其文本,记录和口头传统中,变得更加智能(至少在理想情况下。引入我们集体模型的颠覆和噪音是另一篇文章的主题,也可能是另一个网站的主题。这更清楚地说明了为什么算法和个体人类之间的竞争,即使人类是世界冠军,也是不公平的。我们正在让一个积累了一万条生命智慧的文明与一袋肉对抗。