JVM垃圾回收——常见的垃圾回收算法
目录
一、垃圾标记
JAVA中的引用
引用计数法
可达性分析算法
二、垃圾收集算法
分代收集理论
标记-清除算法
标记-复制算法
标记-整理算法
三、GC分类
在前面的博客中我们了结了内存分配和内存溢出,现在我们一起探讨一下垃圾回收,垃圾回收需要考虑一些问题比如,那些对象是我们需要回收的?在什么时候回收?怎么样回收?回收时有哪些问题?了解垃圾回收可以解决实际生产中的什么问题等等。
一、垃圾标记
判定一个对象是否死亡(这个对象不会再被引用和访问)有两种方法引用计数法和可达性分析算法。在谈论这两种方法之前先谈论一个问题——JAVA中的引用。
JAVA中的引用
在jdk1.2之后,JAVA对引用的概念进行了扩充,将引用分为了强引用、软引用、弱引用、虚引用。
强引用:强引用就是传统的引用,比如User user=new User()。在任何情况下,只要强引用存在,那么对象就不会被垃圾回收器回收。
软引用:表示一些还有用,但是不是必须存在的对象。只被软引用引用的对象,在JVM将要发生内存溢出时就会把这些软引用的对象进行垃圾回收。
弱引用:弱引用是比软引用更弱的一种引用,当发生垃圾回收时不管内存充足不充足,弱引用的对象都会被回收掉。比如ThreadLocal中就是用弱引用在一定程度上避免内存泄漏的问题。
虚引用:虚引用也被称为“幽灵引用”或者“幻影引用”,他是最弱的一种引用关系,虚引用的存在与否对对象的存活时间并没有影响。也无法通过虚引用获取对象实例,为一个对象设置一个虚引用的唯一目的是为了能在对象被垃圾回收器回收时收到一个系统通知。
引用计数法
引用计数法是在对象中添加一个计数器,每当这个对象被引用那么这个计数器就加1,当释放引用时计数器就减1,当引用计数器减到0时,就认为对象不再被引用。但是大多数的JVM虚拟机并没有采用这种方法来实现垃圾标记,因为这种方法存在一个不足,就是他并不能解决相互引用这种情况。
package com.wssnail.test;
/**
* @author 熟透的蜗牛
* @version 1.0
* @description:测试引用计数法
* @date 2022/10/10 21:03
*/
//jdk17 jvm参数
// -verbose:gc
// -Xmx20M
// -Xms20M
// -Xmn10M
// -Xlog:gc*
// -XX:SurvivorRatio=8
public class TestReferenceCount {
private Object instance;
private static final int _1MB = 1024 * 1024;
//大内存 触发垃圾回收
private byte[] bigData = new byte[4 * _1MB];
public static void main(String[] args) {
TestReferenceCount obj1 = new TestReferenceCount();
TestReferenceCount obj2 = new TestReferenceCount();
obj1.instance = obj2;
obj2.instance = obj1;
obj1 = null;
obj2 = null;
System.gc();
}
}
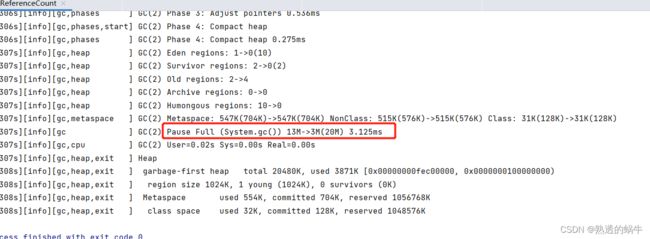
可以看到JVM并没有因为对象相互引用,就没有进行垃圾回收。
可达性分析算法
可达性分析算法是通过一系列的“GC Roots”的根对象做为起始点,然后从这些根结点开始,根据引用关系向下搜索,搜索过程中所走过的路径称为“引用链”,如果一个对象到GC Roots没有任何引用关系,那么认为这个对象就不可能再被引用,即认为是不可达对象。
那么那些对象可以作为GC Roots的对象呢?一般在JAVA中可以作为GC Roots的对象的有以下几个
- 在虚拟机栈(栈帧中的本地变量表)中引用的对象,比如方法中的参数、局部变量、临时变量等。
- 方法区中的类静态属性引用的对象,静态变量。
- 在方法区中常量引用的对象。
- 本地方法栈中引用的对象(Native方法引用的对象)。
- JAVA虚拟机内部的引用,比如一些异常对象(NullPointException、OutOfMemoryError),系统的类加载器。
- 被同步锁(Synchronized关键字)持有的对象。
- 反映JAVA虚拟机内部情况的JMXBean、JVMTI中注册的回调、本地代码缓存等。
二、垃圾收集算法
分代收集理论
分代收集建立在两个分代假说上。即弱分代假说(Weak Generational Hypothesis):绝大多数对象都是朝生夕灭的。强分代假说(Strong Generational Hypothesis):熬过越多次的垃圾收集过程的对象就越难以消亡。
分代理论将堆空间划分为年轻代(Young Generation)和老年代(Old Generation)。但是在垃圾回收时可能会存在跨代引用这种情况,即年轻代的对象被老年代引用着,那么此时就不得不对老年代进行一次GCRoot确保可达性分析的正确性。因此在分代收集理论上增加一条跨代引假说:跨代引用相对于同代引用来说仅占极少数。
那么JVM是如何解决跨地引用的呢?JVM解决跨代引用只需要在新生代上建立一个全局的数据结构(Remembered Set 记忆集),这个结构把老年代划分为若干小块,标识老年代的那一块区域存在着跨代引用,当要发生GC时,只需要对记忆集中记录的对象进行GCRoots扫描即可,避免了对整个老年代的扫描。
标记-清除算法
标记清除算法,正如它的名字一样分为标记和清除两个过程,首先需要标记出需要回收的对象(也有的书上说是标识存活的对象),然后对需要的回收的对象做清除。但是标记清除有两个明显的缺点:第一个就是标记清除的效率并不是很高,而且稳定性也不是很好,如果存在大量需要回收的对象,那么标记和清除阶段就需要花费相当的一段时间。第二个就是内存空间碎片化的问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多,当需要存储大对象而没有足够的连续空间存储时,就不得不提前触发一次垃圾回收。
标记-复制算法
为了解决标记清除带来碎片化的问题,出现了标记复制算法,标记复制算法是将一块区域分成两部分,每次只使用其中的一部分,然后把存活的对象拷贝到另一个区域,再把该区域中“已死”的对象直接清除掉。很明显这样的方法也存在两个问题:第一个就是如果有大量的对象存活,那么这个复制的过程也需要花费相当的一段时间。第二个就是总是有一部分内存没有被使用到而导致内存的浪费。
在实际的HotSpot虚拟机中复制算法是将新生代划分成了Eden区和2个Survivor区,他们的比例是8:1:1。标记复制算法流程如下图
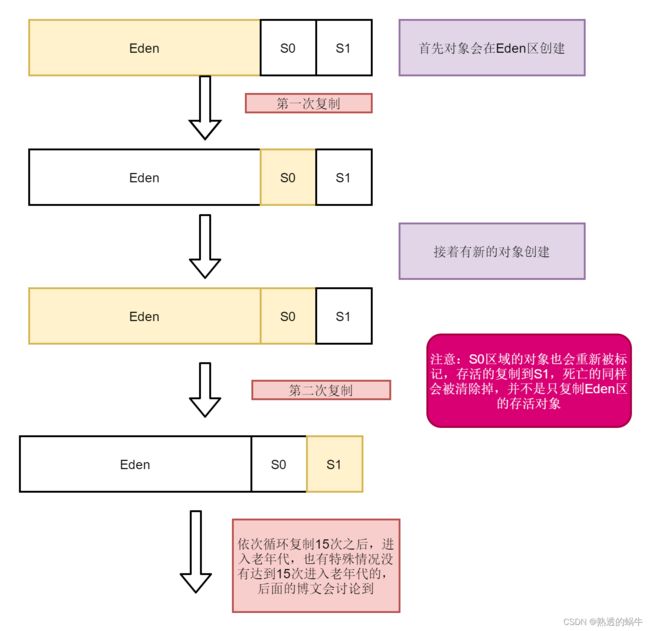
正由于标记复制算法,在存活对象较多时复制大量的对象会花费很多时间,所以一般老年代不使用这种标记复制算法。
标记-整理算法
标记整理的标记过程与标记清除算法一样,标记整理并不是像标记清除那样,直接把可回收的对象直接清除,而是让所有的对象向一侧移动,然后直接清理掉边界以外的内存,这种内存规整的方式,也为对象分配内存的指针碰撞提供了环境。标记整理同样也有不足,比如移动存活的对象时,需要修改指针的位置,这个时候就不得不进行STW(Stop The World)。不移动对象会使得收集器的效率高一些,但是由于内存分配和访问相比垃圾回收频率的高得多,所以降低这部分的时间,吞吐量也会相应的得到提升,所以追求吞吐量的Parallel Old 收集器是基于标记-整理算法实现的,而关注延迟的CMS收集器是基于标记-清除算法实现的。
三、GC分类
新生代收集(Minor GC /Young GC ):只针对新生代的垃圾回收。
老年代收集(Major GC / Old GC):只针对老年代的垃圾回收。目前只有CMS垃圾收集器会单独收集老年代。
混合收集(Mixed GC):收集整个新生代和部分老年代的垃圾收集,目前只有G1收集器具有这样的功能。
整堆收集(Full GC):收集整个堆和方法区的垃圾收集。