SQL高级语句2
SQL高级语句2
- SQL高级语句
-
- 17.---- 连接查询 ----
- 18.自我连接,算排名:
- 19.---- CREATE VIEW ----视图,可以被当作是虚拟表或存储查询。
- 20.---- UNION ----联集,将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类
-
- UNION :生成结果的数据记录值将没有重复,且按照字段的顺序进行排序
- UNION ALL :将生成结果的数据记录值都列出来,无论有无重复
- 21.---- 交集值 ----取两个SQL语句结果的交集
-
- 取两个SQL语句结果的交集,且没有重复
- 22.---- 无交集值 ----显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复
- 23.---- CASE ----是 SQL 用来做为 IF-THEN-ELSE 之类逻辑的关键字
- 24.---- 空值(NULL) 和 无值('') 的区别 ----
- 25.---- 正则表达式 用REGEXP引导 ----
SQL高级语句
17.---- 连接查询 ----
inner join(内连接):只返回两个表中联结字段相等的行
left join(左连接):返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右连接):返回包括右表中的所有记录和左表中联结字段相等的记录
左右表之分,简单点就直接看表在join的哪一边,左边就是左表,右边就是右表
SELECT * FROM location A RIGHT JOIN store_info B on A.Store_Name = B.Store_Name ;
SELECT * FROM location A LEFT JOIN store_info B on A.Store_Name = B.Store_Name ;
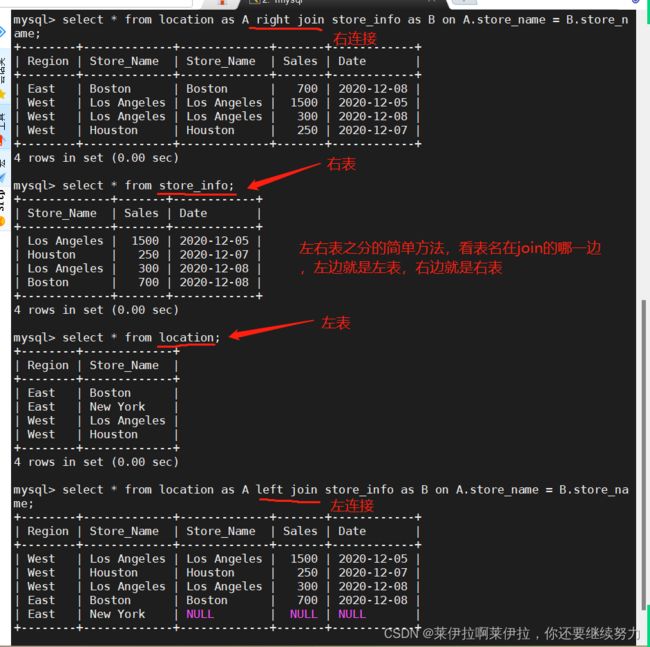
内连接方法一:
SELECT * FROM location A INNER JOIN store_info B on A.Store_Name = B.Store_Name ;
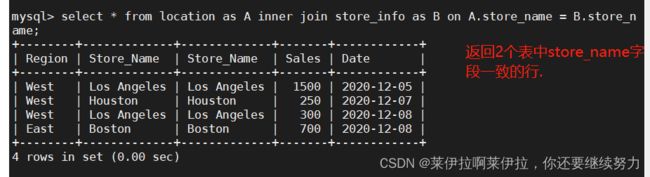
内连接方法二:
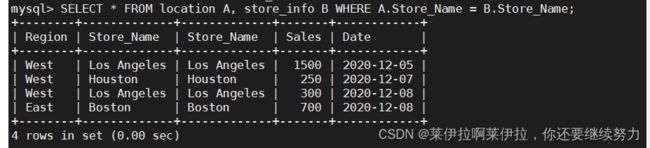
SELECT * FROM location A, store_info B WHERE A.Store_Name = B.Store_Name;
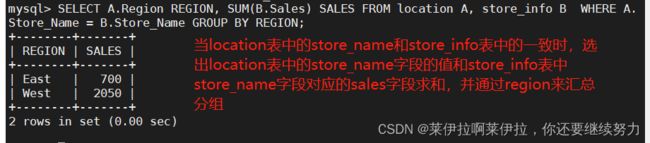
SELECT A.Region REGION, SUM(B.Sales) SALES FROM location A, store_info B
WHERE A.Store_Name = B.Store_Name GROUP BY REGION;
18.自我连接,算排名:
创建2个新表
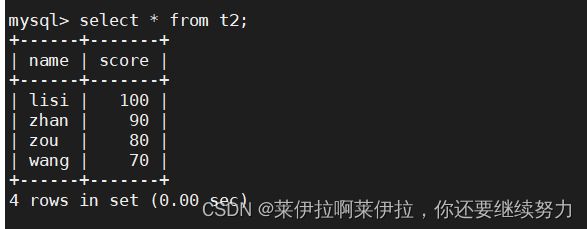
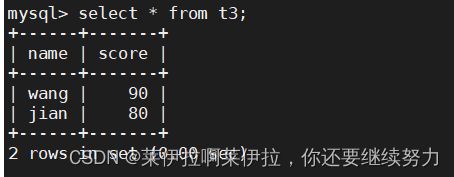
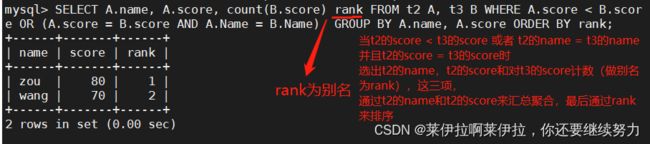
分组汇总后统计 score 字段的值是比自己本身的值小的以及 score 字段 和 name 字段都相同的数量
SELECT A.name, A.score, count(B.score) rank FROM t2 A, t3 B WHERE A.score < B.score OR (A.score = B.score AND A.Name = B.Name) GROUP BY A.name, A.score ORDER BY rank;
19.---- CREATE VIEW ----视图,可以被当作是虚拟表或存储查询。
- 视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。
临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。 - 视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
- 视图的内容会随着源表内容的更改而变化
- 语法:CREATE VIEW “视图表名” AS “SELECT 语句”;
CREATE VIEW V_REGION_SALES AS SELECT A.Region REGION,SUM(B.Sales) SALES FROM location A INNER JOIN store_info B ON A.Store_Name = B.Store_Name GROUP BY REGION;
SELECT * FROM V_REGION_SALES;
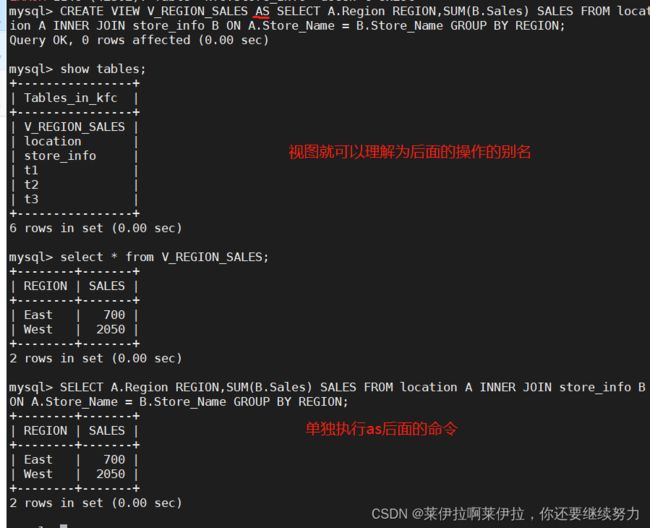
DROP VIEW V_REGION_SALES;
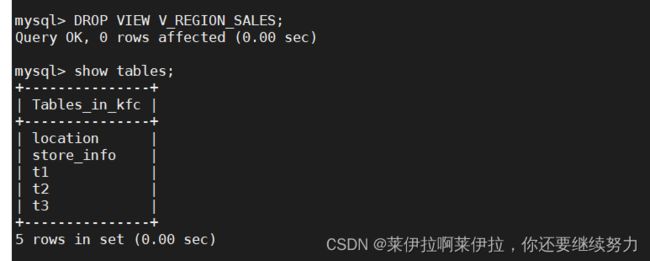
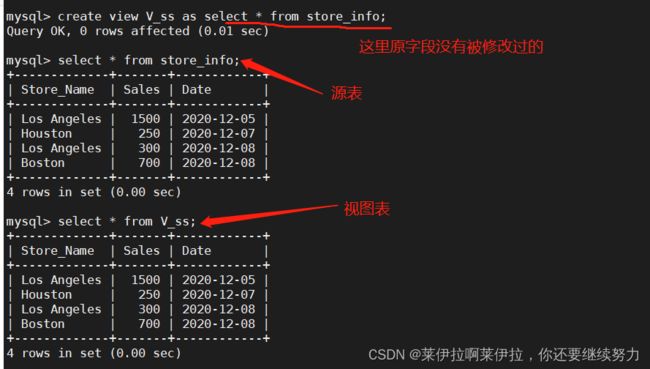
视图模式能不能修改内容要看情况,即as后面的select语句中所的出来的字段不能被修改过,就可以更改数据,但要是被修改过(例如:聚合函数处理,group by 汇总聚合)就不能修改数据。
源字段没有改变的情况
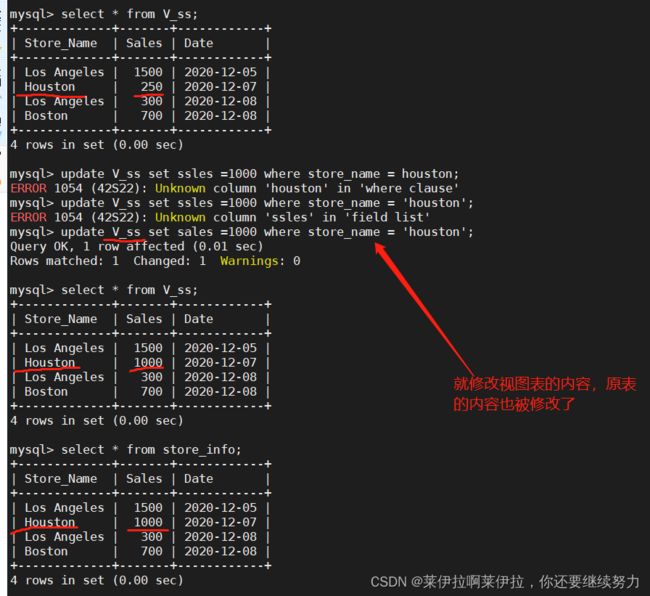
源字段改变的情况
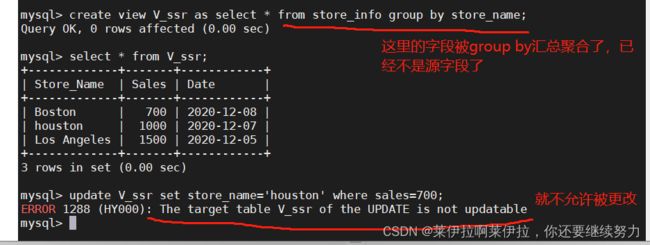
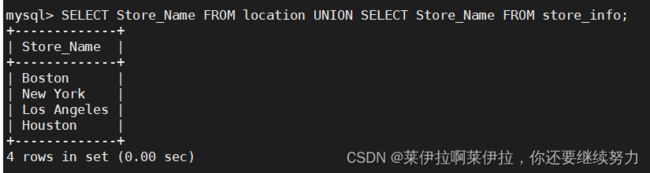
20.---- UNION ----联集,将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类
UNION :生成结果的数据记录值将没有重复,且按照字段的顺序进行排序
语法:[SELECT 语句 1] UNION [SELECT 语句 2];
SELECT Store_Name FROM location UNION SELECT Store_Name FROM store_info;
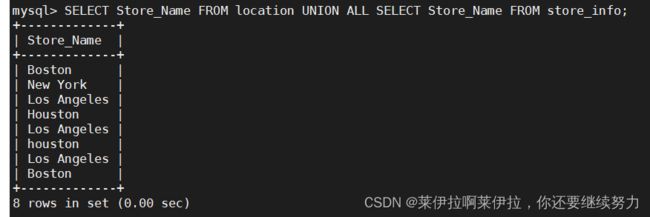
UNION ALL :将生成结果的数据记录值都列出来,无论有无重复
语法:[SELECT 语句 1] UNION ALL [SELECT 语句 2];
SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM store_info;
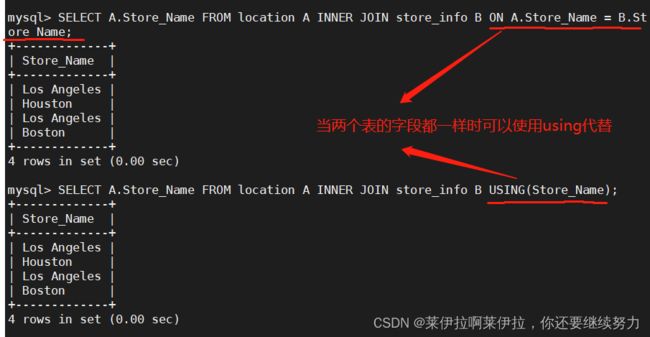
21.---- 交集值 ----取两个SQL语句结果的交集
SELECT A.Store_Name FROM location A INNER JOIN store_info B ON A.Store_Name = B.Store_Name;
SELECT A.Store_Name FROM location A INNER JOIN store_info B USING(Store_Name);
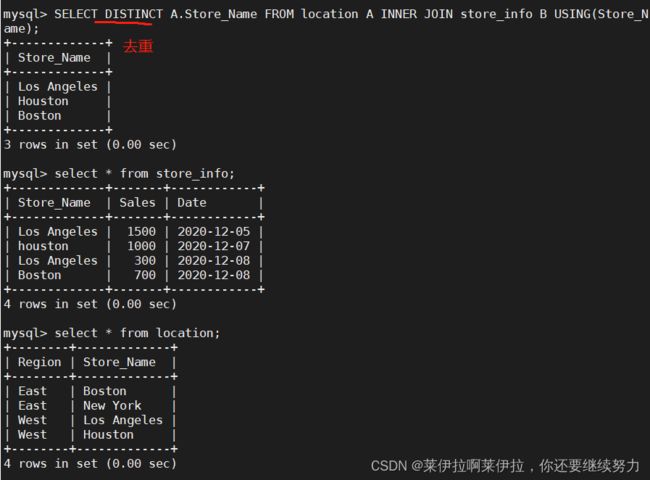
取两个SQL语句结果的交集,且没有重复
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN store_info B USING(Store_Name);
where语句
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) IN (SELECT Store_Name FROM store_info);
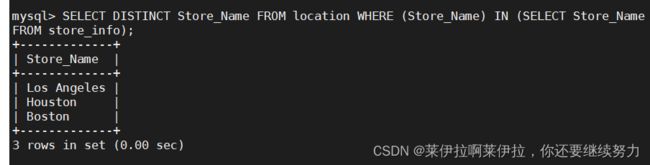
左连接
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN store_info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;
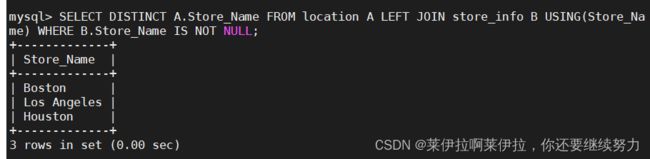
内连接+别名
SELECT A.Store_Name FROM (SELECT B.Store_Name FROM location B INNER JOIN store_info C ON B.Store_Name = C.Store_Name) A GROUP BY A.Store_Name;
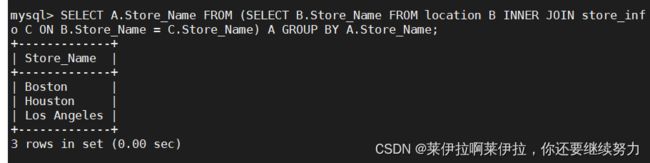
联集
SELECT A.Store_Name FROM (SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM store_info) A GROUP BY A.Store_Name HAVING COUNT(*) > 1;
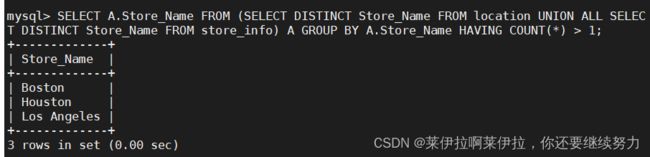
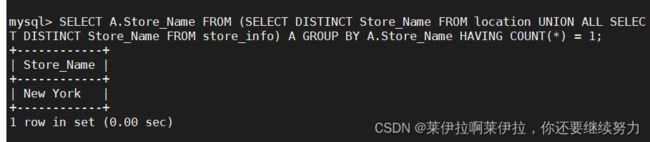
22.---- 无交集值 ----显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复
select语句来求无交集
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) NOT IN (SELECT Store_Name FROM store_info);

LEFT JOIN语句
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN store_info B USING(Store_Name) WHERE B.Store_Name IS NULL;

联集
SELECT A.Store_Name FROM (SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM store_info) A GROUP BY A.Store_Name HAVING COUNT(*) = 1;
23.---- CASE ----是 SQL 用来做为 IF-THEN-ELSE 之类逻辑的关键字
语法:
SELECT CASE (“字段名”)
WHEN “条件1” THEN “结果1”
WHEN “条件2” THEN “结果2”
…
[ELSE “结果N”]
END
FROM “表名”;
#“条件” 可以是一个数值或是公式。 ELSE 子句则并不是必须的。
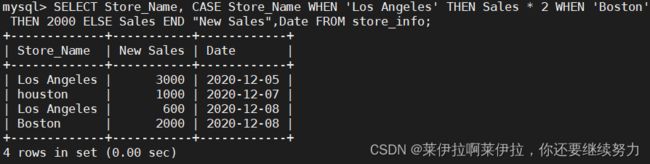
SELECT Store_Name, CASE Store_Name WHEN 'Los Angeles' THEN Sales * 2 WHEN 'Boston' THEN 2000 ELSE Sales END "New Sales",Date FROM store_info;
#“New Sales” 是用于 CASE 那个字段的字段名。
24.---- 空值(NULL) 和 无值(‘’) 的区别 ----
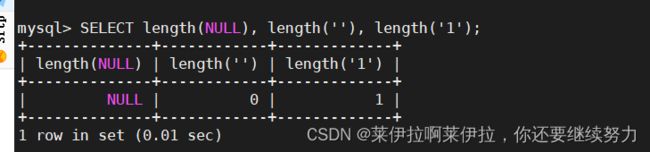
1.无值的长度为 0,不占用空间的;而 NULL 值的长度是 NULL,是占用空间的。
2.IS NULL 或者 IS NOT NULL,是用来判断字段是不是为 NULL 或者不是 NULL,不能查出是不是无值的。
3.无值的判断使用='‘或者<>’'来处理。<> 代表不等于。
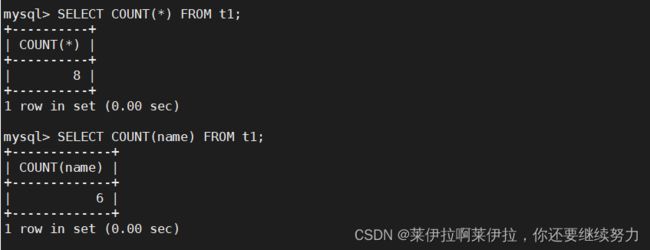
4.在通过 count()指定字段统计有多少行数时,如果遇到 NULL 值会自动忽略掉,遇到无值会加入到记录中进行计算。
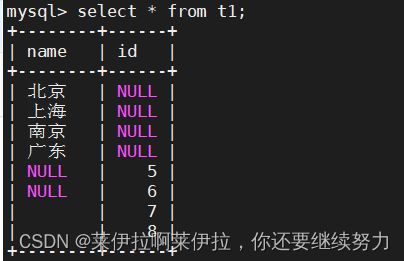
t1 表格
SELECT length(NULL), length(''), length('1');
#统计这几个字段长度
SELECT * FROM t1 WHERE name IS NULL;
SELECT * FROM t1 WHERE name IS NOT NULL;
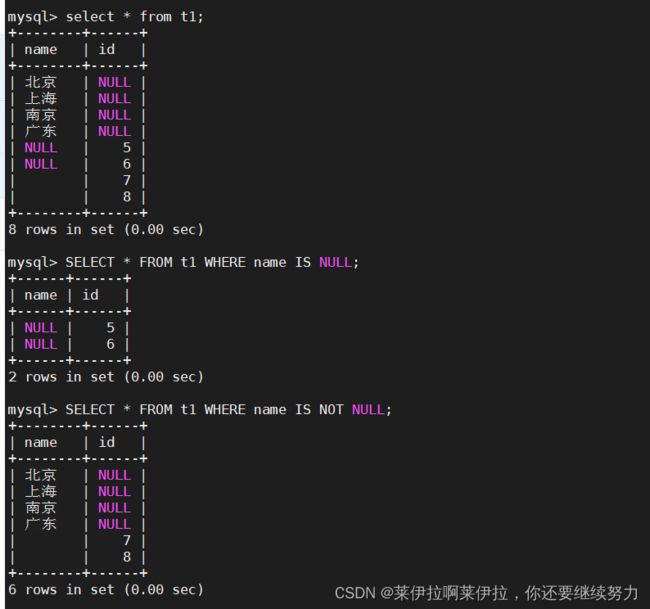
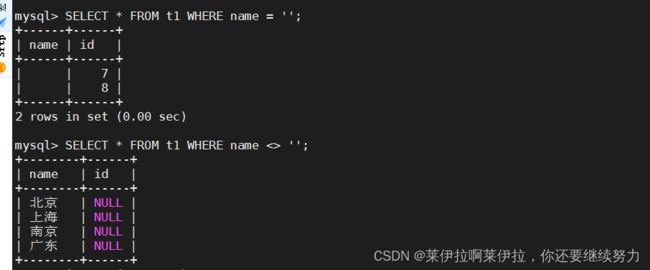
SELECT * FROM t1 WHERE name = '';
SELECT * FROM t1 WHERE name <> '';#<>代表不等于
SELECT COUNT(*) FROM t1;#统计包括null的行的个数
SELECT COUNT(name) FROM t1;#统计不包括null的行的个数
25.---- 正则表达式 用REGEXP引导 ----
| 匹配模式 | 描述 | 实例 |
|---|---|---|
| ^ | 匹配文本的开始字符 | ‘^bd’ 匹配以 bd 开头的字符串 |
| $ | 匹配文本的结束字符 | ‘qn$’ 匹配以 qn 结尾的字符串 |
| . | 匹配任何单个字符 | ‘s.t’ 匹配任何 s 和 t 之间有一个字符的字符串 |
| * | 匹配零个或多个在它前面的字符 | ‘fo*t’ 匹配 t 前面有任意个 o |
| + | 匹配前面的字符 1 次或多次 | ‘hom+’ 匹配以 ho 开头,后面至少一个m 的字符串 |
| 字符串 | 匹配包含指定的字符串 | ‘clo’ 匹配含有 clo 的字符串 |
| p1|p2 | 匹配 p1 或 p2 | ‘bg|fg’ 匹配 bg 或者 fg |
| [...] | 匹配字符集合中的任意一个字符 | ‘[abc]’ 匹配 a 或者 b 或者 c |
| [^...] | 匹配不在括号中的任何字符 | ‘[^ab]’ 匹配不包含 a 或者 b 的字符串 |
| {n} | 匹配前面的字符串 n 次 | ‘g{2}’ 匹配含有 2 个 g 的字符串 |
| {n,m} | 匹配前面的字符串至少 n 次,至多m 次 | ‘f{1,3}’ 匹配 f 最少 1 次,最多 3 次 |
语法:SELECT “字段” FROM “表名” WHERE “字段” REGEXP {模式};
字段内不区分大小写,和shell的正则有所不同
SELECT * FROM store_info WHERE Store_Name REGEXP 'os';
SELECT * FROM store_info WHERE Store_Name REGEXP '^[A-G]';
SELECT * FROM store_info WHERE Store_Name REGEXP 'Ho|Bo';
