论文课后总结
1:论文写作的框架
摘要:用十句话表达论文的主要思想和技术;
介绍:先介绍算法的使用背景,及该背景下的其它算法的特点,然后介绍自己算法的新颖之处,相比其它算法有什么特点;
论文的主体部分:详细地介绍算法思想及其实现过程,并写出伪代码,分析算法的复杂度(主要是时间的复杂度);
实验部分:根据算法的特点选择合适的指标,用同样的数据集将自己的算法与其它算法进行比较,可以用表格或图像的形式呈现;
结论:要客观地评价自己的算法,并提出进一步的工作;
文献引用:写出论文中提到的相关知识点和算法的出处。
2:论文编辑器
用Latex进行论文写作,它可以自动帮我们生成想要的格式(加一些相关命令),所以我们不必为修改论文格式发愁。老师的博客中列出了常见出版社的格式格式要求,见:论文写作2。此外,还需要我们还需要了解常见的Latex语法,Latex常用数学字符、字体、各种符号在Latex所有常用数学符号整理和LaTeX各种命令、符号这两篇博客中总结得比较全面;使用Latex绘图可以借鉴latex-tikz简单绘图和【LaTeX应用】tikz画图中如何控制线条;在论文中写数学公式及矩阵的相关操作可以参考公式对齐和矩阵。
在哪儿用Latex写论文?论文写作三件套WinEdt+SumatraPDF+Texlive,安装教程可以参考LaTex的图文安装。
我之前也安装过CTex,发现CTex的确方便,它已经把上述的工具都集成好了,不用我们挨个去安装、配置,但是安装之前一定要找一个教程照着安装,并提前备份好自己电脑上的环境变量,因为安装时,会修改电脑的环境变量,CTex的程序员在写修改环境变量的时候应该把“+=”写成了“=”,会导致安装好CTex后,电脑上的环境变量只剩一个新的,这是血和泪的教训。
3:论文中词汇的使用:
- 不要加撇号进行缩写,例如:don’t、isn’t,需要将它们展开。
- 禁止在句首加And。
- 不要说我们研究的东西easy、simple。
- 解决问题用handle或address,而不是solve(指彻底解决)
- 用new代替novel。
- 把Only放在靠后的位置
- 用show替代prove(当定义了一个定理并有证明才能用)来表示实验结果。
- 在https://www.linggle.com可以查看单词的使用频率,一般选择频率高的。
4:标点符号前面没有空格,后面要有空格;使用两次左单引号(Esc键下面),就变成了一个左对双引号(现在才知道还能这样做)。
5:论文中的各种引用,为了避免出现多个标签,在定义label时,最好根据表格、图片等用处或内容进行命名。
6:文中的强调文字用\emph{},在{}中写入需要强调的内容,而不是$括起来,后者由更大的间距。
7:论文中的图片可以通过Latex画简单的线段图,也可以用PPT绘制,绘制好后,保存为pdf格式,然后在论文中引用即可。
8:像自己这种不善于表达的,更需要先用中文把意思阐述清楚,“好的中文=好的英文”,如果感觉写出来的英语不对,那就在翻译软件上 中译英后再英译中,多倒腾几遍。
9:借鉴别人论文中的句型也是一个很不错的方式,当熟悉论文写作的套路之后,我们应该就能轻松写出自己的句子了。
10:数学式子是句子的一部分,式子后面要写有逗号或句号;数学表达式中的文字应该使用\mathrm{}括起来;有些数学字符需要用 \ 进行转义,如 应该是 ln 2 \ln 2 ln2($\ln 2$)而不是 l n 2 ln 2 ln2($ln 2$)。
11:如果想要数学表达式的括号与内容的高度匹配,那么需要在括号前面加\left和\right,如\left( some content \right),注意如果想在数学表达式中使用花括号({}),记得在{前加一个转义符\,即\left{ some content \right}。
12:当我们要进行理论推导时,要注意以下几点:
- 尽量言简意赅(可能要改很多遍才能达到这种效果吧)
- 理论要完备;
- 数学表达式中的符号要统一风格(要区别标量和向量,符号是否加粗)
- 重要的结论称为theorem,起辅助作用的某个定义或声明称为引理lemma,定理后的尾巴叫推论corollary,附属的算法叫property,一个对后文的证明不是特别重要却仍然有参考和辅助作用的正确陈述称为命题proposition。
例如:在论文Yue Zhu, James T. Kwok, Zhi-Hua Zhou, Multi-Label Learning with Global and Local Label Correlation, IEEE Transactions on Knowledge and Data Engineering, 2018 (30), 1081–1094. 中,作者在设计和优化目标函数的过程中,就提出了一个引理和一个命题:
局部相关性和全局相关性之间的关系:
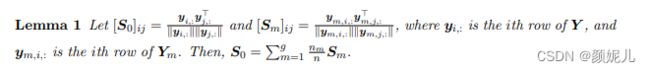
由局部相关性的线性关系到拉普拉斯矩阵的线性关系:
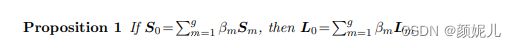
将引理和命题用到目标函数中:
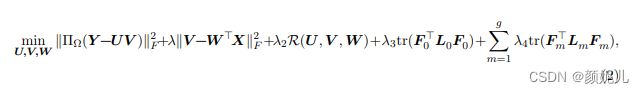
根据引理和命题得到的目标函数:

13:算法伪代码:
- 要说明输入、输出;
- 主要步骤要有注释;
- 长度控制到15~30行;
- 可以引用已有的式子;
- 要进行复杂度分析
模板:
\begin{algorithm}[!htb]
%\textsl{}\setstretch{1.8}
\renewcommand{\algorithmicrequire}{\textbf{Input:}}
\renewcommand{\algorithmicensure}{\textbf{Output:}}
\caption{Multi-label active learning through serial-parallel neural networks}
\label{algorithm: masp}
\begin{algorithmic}[1]
\REQUIRE
data matrix $\mathbf{X}$,
label matrix $\mathbf{Y}$ for query,
query budget $Q$,
cold-start query budget $P$,
number of representative instances $R$,
instance batch size $B_i$,
label batch size $B_l$
\ENSURE
queried instance-label pairs $\mathbf{Q}$, prediction network $\Theta$.
\STATE Initialize the serial-parallel prediction network;
\STATE $\mathbf{Q} = \emptyset$;\\
// Stage 1. Cold start.
\STATE Compute instance representativeness according to Eq. \eqref{equation: dp-representativeness};
\STATE Select the top-$R$ representative instances to reorganize the training set $\mathbf{X}$;
\STATE Update $\mathbf{Q}$ and $\mathbf{Y}'$ by querying $B_l$ labels for each of the top $\lfloor Q / B_l \rfloor$ representative instances;
\STATE Train the prediction network using $\mathbf{X}$ and $\mathbf{Y}'$;\\
// Stage 2. Main learning process.
\REPEAT
\STATE Compute $\hat{\mathbf{Y}}$ using the prediction network and Eq. \eqref{equation: label-prediction};
\STATE Compute label uncertainty according to Eq. \eqref{equation: label-uncertainty};
\STATE Query top-$B_i$ uncertain instance-label pairs to update $\mathbf{Q}$ and $\mathbf{Y}'$;
\STATE Update the prediction network using $\mathbf{X}$ and $\mathbf{Y}'$;\\
\UNTIL{($|\mathbf{Q}| \geq Q$)}
\end{algorithmic}
\end{algorithm}

14:进行实验比较时,要选择合适的指标,例如在多标签问题中,准确度就不再合适了,基于序的评价指标可以参见老师的博客:基于序的评价指标 (特别针对推荐系统和多标签学习),对应的代码我放在了评价指标代码,其它类型的评价指标选择可以参加同类型论文中选择的指标。
15:算法效果的比较通常采取表格和图片的形式展现。在表格中,可以通过加粗、斜体或用圆圈标记的形式来突出效果较好的算法。但同一结果不应在表格和图中同时出现,这样会显得冗余。
16:数据集一般选择12至20个公开数据集,并且数据集的类型覆盖范围越广越好。但有些时候,我们的算法效果并不是在所有的数据集上都有很好的效果,我们可以直接指出自己算法在哪些数据集的效果不理想。
17:除了和别的算法进行外部比较外,我们也需要对自己的算法进行内部比较,例如改变某个参数或某个方案,对我们算法的影响。
18:在和别的算法进行比较时,我们也要尽可能的调出其它算法的最好效果进行比较。
19:总结部分写5局话就差不多了,同时要避免与摘要重复。进一步工作可以列3~5条。
20:使用Latex提供的bib文件进行参考文献管理,模板:
%期刊
@ARTICLE{MinZhang2020Frequent,
author = {Fan Min and Zhi-Heng Zhang and Wen-Jie Zhai and Rong-Ping Shen},
title = {Frequent pattern discovery with tri-partition alphabets},
journal = {Information Sciences},
year = {2020},
volume = {507},
number = {1},
pages = {715--732},
doi = {10.1016/j.ins.2018.04.013}
}
%会议
@INPROCEEDINGS{MinCai2007Dynamic,
author = {Fan Min and Hong-Bin Cai and Qi-He Liu and Zhong-Jian Bai},
title = {Dynamic discretization: a combination approach},
booktitle = {ICMLC},
year = {2007},
pages = {3672--3677}
}
用的时候就把这个模板拿来改改就可以了,不然容易挨骂。
21:引用中的名字要有意义,这样也可以避免面不同参考文献命名冲突。
22:可以通过花括号强制控制控制论文题目中的大写字母;特殊字符需要通过转移符才能正常显示。
24:图注可以相当长,要尽可能地把图片阐述清楚,且要注意,当引用图片时,要保持图片编号一致,作主语时,用Figure。
25:表格常被用于字符说明、数据集介绍、算法比较等,常用三线表格来表示,如:

表格模板:
\begin{table}[h]\caption{Dataset information}\label{table: datasets}
\centering
\setlength{\tabcolsep}{12pt}
\begin{tabular*}{12cm}{@{\extracolsep{\fill}}lrrlll}
\hline
Dataset & $|\mathbf{U}|$ & $|\mathbf{C}|$ & Area & $rt$ & $qi$\\
\hline
Seeds & 210 & 8 & Life & 0.19 & 0.1\\
Thyroid & 215 & 6 & Life & 0.25 & 0.1\\
Heart & 270 & 14 & Life & 0.05 & 0.1\\
Spiral & 312 & 3 & Synthetic & 0.3 & 0.1\\
Ionosphere & 350 & 35 & Physical & 0.04 & 0.1\\
R15 & 600 & 3 & Synthetic & 0.2 & 0.1\\
USps\_2\_6 & 2,200 & 257 & Image & 0.2 & 0.1\\
Waveform & 5,000 & 22 & Physical & 0.1 & 0.1\\
Credit & 5,987 & 66 & Financial & 0.35 & 0.1\\
Twonorm & 7,400 & 21 & Synthetic & 0.3 & 0.1 \\
\hline
\end{tabular*}
\end{table}
Latex表格相关内容可以参见:Latex tabular和tabular* 注意表格样式参数命令
26:要实现在Abstract之前分页,需要在最后一个作者地址结束花括号之前加上\newpage,例:
\address[swpu1]{School of Computer Science, Southwest Petroleum University, Chengdu 610500, China}
\address[swpu2]{Institute for Artificial Intelligence, Southwest Petroleum University, Chengdu 610500, China\newpage}
\cortext[cor1]{Corresponding author at: School of Computer Science, Southwest Petroleum University, Chengdu 610500, China. Tel.: +86 135 4068 5200.}
\begin{abstract}
设置单栏模式:
\documentclass[authoryear,review]{elsarticle}
设置双栏模式:
\documentclass[final,5p,times,authoryear,twocolumn]{elsarticle}
27:会议论文与期刊论文的区别:会议论文相对精简一些,为了节约版面,一般没有章节组织描述、相关工作描述较少、实验也要少一些、不讨论进一步的工作,而且参考的文献一般是20篇左右。
28:算法比较中的Mean Rank值表示了各个算法在数据集上的效果,一般自己的算法在1点几左右可以说比较好,2点几算一般。
29:回复审稿意见时,态度要端正,直接回答审稿人的问题,同时还要表达自己的谢意。
30:实验效果不好:设计一个模型一般都要经历三个阶段:从特征选择到模型训练再到预测。可以从各个阶段下手,找替换方案。比如在训练阶段,可以考虑给网络增加正则项,或者是改变网络结构等方式;在预测阶段,可以考虑采用均值或是最值来代表结果。如果算法效果和其它算法差距不大,可以考虑调参来优化结果。然后,针对对数据集来说要广撒网,说不定能网到几个效果不错的数据集。