视觉伺服研究学习——2021年10月
一、基础学习课程
深度学习
计算机视觉
机器学习
约定:
黄色高亮表示关键词,不认识的知识点;
绿色下划线:重要的思想观点,精髓的理解。
二、论文学习
1、室内动态视觉SLAM算法研究 硕士学位论文
鲁棒性:鲁棒是Robust的音译,也就是健壮和强壮的意思。 它也是在异常和危险情况下系统生存的能力。 比如说,计算机软件在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃,就是该软件的鲁棒性。 所谓“鲁棒性”,也是指控制系统在一定(结构,大小)的参数摄动下,维持其它某些性能的特性。
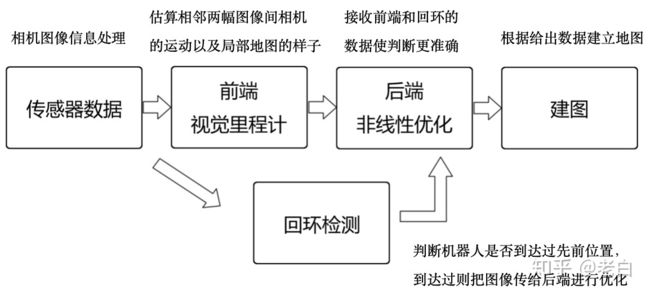
视觉里程计:当你进入陌生的屋子,你能够知道自己在屋子中的位置,知道周围环境是什么样的。视觉SLAM是机器人利用相机作为眼睛,从而具备与你相同的能力,能够对所在位置进行定位,对周围环境进行建模。视觉SLAM分为前端和后端,视觉里程计是前端,负责从图像中实时捕捉信息。后续还有回环检测和后端优化来使模型更加精确。RGB-D相机,向周围发射结构光根据结构光的变形来确定物体深度。TOF相机,向周围物体发射激光,根据激光反弹时间确定物体深度。(深度即相对于相机的距离)
视觉里程计按照是否使用特征点可以分为直接法和特征点法,直接法使用原始光度误差最小约束来估计,而特征点法基于特征点匹配进行估计,直接法可以构建更加稠密的地图,但是特征点法的精度更高且鲁棒性更好,因此多数视觉 SLAM 采用特征点法,本文也主要聚焦在特征点法的视觉里程计。特征点法的视觉里程计主要由特征点处理和运动估计两部分组成,其中特征点处理主要完成的是特征点的提取和匹配,运动估计则是利用特征点匹配关系估计前后帧的相机运动。
2、机器人视觉伺服跟踪系统的研究 硕士学位论文-张作楠-2012
摘要:智能机器人的视觉伺服是利用视觉传感器得到的图像作为反馈信息来构造机器人
的位置闭环控制,即利用视觉传感器来间接检测机器人当前位姿或者其相对于期望目标
图像的当前特征,在此基础上实现机器人的定位控制或者轨迹跟踪。图像采集卡:图像采集卡(Image Capture Card),又称图像捕捉卡,是一种可以获取数字化视频图像信息,并将其存储和播放出来的硬件设备。很多图像采集卡能在捕捉视频信息的同时获得伴音,使音频部分和视频部分在数字化时同步保存、同步播放。
阈值分割法:是一种基于区域的图像分割技术,原理是把图像像素点分为若干类。图像阈值化分割是一种传统的最常用的图像分割方法,因其实现简单、计算量小、性能较稳定而成为图像分割中最基本和应用最广泛的分割技术。它特别适用于目标和背景占据不同灰度级范围的图像。它不仅可以极大的压缩数据量,而且也大大简化了分析和处理步骤,因此在很多情况下,是进行图像分析、特征提取与模式识别之前的必要的图像预处理过程。图像阈值化的目的是要按照灰度级,对像素集合进行一个划分,得到的每个子集形成一个与现实景物相对应的区域,各个区域内部具有一致的属性,而相邻区域不具有这种一致属性。这样的划分可以通过从灰度级出发选取一个或多个阈值来实现。
- 雅可比矩阵:

3、智能机械臂视觉系统的目标检测与定位方法研究
硕士论文-庞博-2016年 -精读
(1)、论文总结
摘要:
1、根据课题研究需要,对目标检测与定位方法进行了综述,并对机械臂视觉
系统的基本原理和关键技术进行了简要介绍。
2、提出了一种基于单模板的多目标检测方法。由于传统的目标检测算法只能
检测单目标,多目标的检测方法需要较长的离线时间对模板或特征进行学习,大
多数算法在保证准确率的同时无法兼顾效率,本文提出了一种基于 NCC 算法与
NMS 方法相结合的多目标检测方法,具有准确率高、实时性强等特点,对噪声、
光照变化具有一定的鲁棒性。
3、提出了一种基于 FFT 计算的旋转不变 HOG 特征的多目标检测方法。传统
模板匹配方法仅适用于目标与模板图像存在轻微角度旋转或不存在旋转的场景,
在存在旋转角度的场景里需要利用特征对目标进行检测。本文在 Liu 提出的基于极
坐标傅里叶分析框架的旋转不变 HOG 特征的基础上进行改进,提出了一种 108 维
的傅里叶空间下的旋转不变 HOG 特征,并基于 FFT 方法进行加速,结合 SVM 分
类器对目标进行检测,得到了良好的检测效果。
4、提出了一种基于边缘信息的多目标检测方法。实际工程项目中,有时需要
对不同多目标进行检测,基于图像匹配和单分类器的目标检测方法将不再适用。
本文针对具体应用,对微软研究院提出的 Edge Boxes 算法进行改进,加入形状约
束并利用 NMS 方法对冗余目标位置进行剔除,合理设置算法涉及的各个参数,可
以得到良好的检测效果。
5、本文利用固连双像机模拟机械臂进行模拟实验,该实验由两部分构成:手
眼标定实验和位姿测量实验。手眼标定实验使用 TSAI 的手眼标定方法对机械臂手
眼系统进行标定,位姿测量实验利用 PNP 算法和双目交会相结合对场景中目标物
体进行位姿测量。实验结果表明 TSAI 手眼标定方法和 PNP 算法结合双目交会的
位姿测量方法适用于机械臂抓取目标物体的实际任务,并具有较高的精度,可以广泛应用到机械臂视觉系统之中。目标检测是通过计算机视觉算法在图像中寻找需要的目标并确定其位置,是
机器人领域的重要研究方向。主流方法大致可分为两类:图像匹配方法和基于分
类器的目标检测方法主流的图像匹配方法主要指的是前两类方法——基于图像灰度和图像特征的匹配方法。
Haar 小波特征(Harr-like features):
哈尔特征(英语:Haar-like features)是用于物体识别的一种数字图像特征。它们因为与哈尔小波转换极为相似而得名,是第一种即时的人脸检测运算。
历史上,直接使用图像的强度(就是图像每一个像素点的RGB值)使得特征的计算强度很大。帕帕乔治奥等人提出可以使用基于哈尔小波的特征而不是图像强度[1] 。维奥拉和琼斯[2]进而提出了哈尔特征。哈尔特征使用检测窗口中指定位置的相邻矩形,计算每一个矩形的像素和并取其差值。然后用这些差值来对图像的子区域进行分类。
例如,当前有一个人脸图像集合。通过观察可以发现,眼睛的颜色要比两颊的深。因此,用于人脸检测的哈尔特征是分别放置在眼睛和脸颊的两个相邻矩形。这些矩形的位置则通过类似于人脸图像的外接矩形的检测窗口进行定义。
在维奥拉-琼斯目标检测框架的检测阶段,一个与目标物体同样尺寸的检测窗口将在输入图像上滑动,在图像的每一个子区域都计算一个哈尔特征。然后这个差值会与一个预先计算好的阈值进行比较,将目标和非目标区分开来。因为这样的一个哈尔特征是一个弱分类器(它的检测正确率仅仅比随机猜测强一点点),为了达到一个可信的判断,就需要一大群这样的特征。在维奥拉-琼斯目标检测框架中,就会将这些哈尔特征组合成一个级联分类器,最终形成一个强分类群。
哈尔特征最主要的优势是它的计算非常快速。使用一个称为积分图的结构,任意尺寸的哈尔特征可以在常数时间内进行计算。
局部二值特征(Local Binary Pattern,LBP):是机器视觉领域中用于分类的一种特征,于1994年被提出[1][2]。局部二值模式在纹理分类问题上是一个非常强大的特征;如果局部二值模式特征与方向梯度直方图结合,则可以在一些集合上十分有效的提升检测效果[3]。局部二值模式是一个简单但非常有效的纹理运算符。它将各个像素与其附近的像素进行比较,并把结果保存为二进制数。由于其辨别力强大和计算简单,局部二值模式纹理算子已经在不同的场景下得到应用。LBP最重要的属性是对诸如光照变化等造成的灰度变化的强健性。它的另外一个重要特性是它的计算简单,这使得它可以对图像进行实时分析。
摄像机标定(Camera calibration)是指确定摄像机成像几何参数(称为内参数)的过程和方法。
摄像机标定:是从多幅二维图像恢复场景三维几何结构必不可少的步骤,是计算机视觉的重要研究内容。由于摄像机制造厂家提供的出场参数一般来说不能满足应用精度的需求,所以在具体应用中需要对使用的摄像机进行标定。摄像机标定可以分为传统标定和自标定两大类。传统标定是指利用结构已知的高精度的标定块进行标定的方法。自标定是指不需要标定块、仅仅利用多幅图像之间几何基元(如点、线等)之间的对应关系进行标定的方法。自标定理论本质上利用的是射影空间的绝对二次曲线(或绝对二次曲面)在图像上的像与摄像机运动无关、仅与内参数有关的事实。摄像机标定一般是指对针孔成像模型下成像参数的确定过程。在精度要求很高的应用场合,需要考虑摄像机的非线性畸变参数,畸变包括径向畸变和切向畸变,一般来说,径向畸变需要首先考虑。
位姿估计的经典算法——PNP算法:相机姿态估计(一)--PnP
归一化互相关匹配(NCC) :NCC是一种基于统计学计算两组样本数据相关性的算法,其取值范围为[-1, 1]之间,而对图像来说,每个像素点都可以看出是RGB数值,这样整幅图像就可以看成是一个样本数据的集合,如果它有一个子集与另外一个样本数据相互匹配则它的ncc值为1,表示相关性很高,如果是-1则表示完全不相关。
图像噪声是指存在于图像数据中的不必要的或多余的干扰信息。 噪声的存在严重影响了遥感图像的质量,因此在图像增强处理和分类处理之前,必须予以纠正。 图像中各种妨碍人们对其信息接受的因素即可称为图像噪声。 噪声在理论上可以定义为“不可预测,只能用概率统计方法来认识的随机误差”。
图像变换:
图像变换
最小二乘曲面拟合:
图像金字塔:
图像金字塔是图像中多尺度表达的一种,最主要用于图像的分割,是一种以多分辨率来解释图像的有效但概念简单的结构。
图像金字塔最初用于机器视觉和图像压缩,一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。
金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似。
我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
高斯金字塔:图像金字塔
拉普拉斯金字塔
旋转不变性:只要对特征定义了方向,然后在同一个方向上进行特征描述就可以实现旋转不变性。
尺度不变性:为了实现尺度不变性,需要给特征加上尺度因子。在进行特征描述的时候,将尺度统一就可以实现尺度不变性了。
所谓的旋转不变性和尺度不变性的原理,就是我们在描述一个特征之前,将两张图像都变换到同一个方向和同一个尺度上,然后再在这个统一标准上来描述这个特征。同样的,如果在描述一个特征之前,将图像变换到同一个仿射尺度或者投影尺度上,那么就可以实现仿射不变性和投影不变性。
基于ROS的机械臂臂障运动规划及仿真 硕士论文-熊超-2018年-泛读
刚体(rigid body)是指在运动中和受到力的作用后,形状和大小不变,而且内部各点的相对位置不变的物体。绝对刚体实际上是不存在的,只是一种理想模型,因为任何物体在受力作用后,都或多或少地变形,如果变形的程度相对于物体本身几何尺寸来说极为微小,在研究物体运动时变形就可以忽略不计。把许多固体视为刚体,所得到的结果在工程上一般已有足够的准确度。但要研究应力和应变,则须考虑变形。由于变形一般总是微小的,所以可先将物体当作刚体,用理论力学的方法求得加给它的各未知力,然后再用变形体力学,包括材料力学、弹性力学、塑性力学等的理论和方法进行研究。
刚体在空间的位置,必须根据刚体中任一点的空间位置和刚体绕该点转动时的位置(见刚体一般运动)来确定,所以刚体在空间有六个自由度。
在很多情况下,固体在受力和运动过程中变形很小,基本上保持原来的大小和形状不变。对此,人们提出了刚体这一理想模型。就是在任何情况下形状和大小都不发生变化的物体,其特点是:在运动过程中,刚体的所有质元之间的距离始终保持不变。因此,构成刚体的质元只能以非常受限制的方式彼此相对运动。而且,作用在刚体各个部分之间的内力,在刚体的整体运动中不起作用
机器人视觉伺服控制研究进展与挑战 杨月全—郑 州 大 学 学 报—2018-精读
摘要:针对机器人视觉伺服研究,分别从基于位置的视觉伺服、基于图像的视觉伺服、混合视觉伺服等对视觉伺服的研究进展进行了回顾. 从雅可比在线估计法、雅可比自适应估计法、深度独立雅可比矩阵估计法等多方面详细分析了无标定视觉伺服. 在此基础上,就视觉伺服的实时性、可靠性、多传感器融合、多任务控制、基于离散时间域及混杂系统的控制器等,对机器人视觉伺服控制所面临的挑战及进一步研究进行了分析与展望.
机器人视觉伺服研究分类:
(1)基于位置的视觉伺服
(2)基于图像的视觉伺服
(3)混合视觉伺服等对视觉伺服
传统方法:
示教再现方式(精度很高,但缺乏灵活性)
加入视觉后:“看后走“ 静态边走边看。
视觉系统分类:
根据摄像机个数不同,可分为单目视觉系统、双目视觉系统和多目视觉系统等
根据摄像机的安装方式,可分为手眼视觉系统( eye-in-hand) 和场景视觉系统( eye-to-hand) 等.
根据输出信号的形式,可分为基于动力学的视觉伺服和基于运动学的视觉伺服.
根据摄像机参数的需求情况,可分为基于标定的视觉伺服和基于无标定的视觉伺服.
基于位置的视觉伺服:
标定模板的标定方法:
像机标定包括像机内参标定与像机外参标定,主要有直接线性变换、Tsai 两步法[24]、张正平面标定法[25]、平面圆标定法[26]、平行圆标定法[27]
自标定方法[33]研究主要有直接求解 Kruppa 方程法[34]、分层逐步标定法[35 - 36]、绝对二次曲面自标定[37]
基于图像的视觉伺服:
基于 CiteSpace 的计算机视觉领域研究热点与前沿分析 张福俊-软件导刊-2020年-精读
摘要:以 Web of Science 收录的文献题录作为数据样本,基于文献计量学方法并利用CiteSpace 工具对 1990-2019 年计算机视觉领域的文献进行可视化分析,从时空层面揭示计算机视觉领域在不同国家(地区)、机构的发展程度;从共引文献层面把握计算机视觉发展脉络;从关键词和突变词角度探测计算机视觉的热点前沿。研究结果显示,从全球范围看,美国对计算机视觉的研究起步较早且一直处于领先地位,中国近年来发展迅速且在总体发文量、高校研究力量层面进步明显,英国、法国、日本、加拿大、瑞士等国近年来发展态势也较突出;马尔视觉计算理论、Canny 边缘检测算法、张氏标定法、YOLO 算法等许多经典算法对计算机视觉领域的发展具有里程碑式的意义;模型、分类、图像分割、追踪、识别等方向是计算机视觉领域的热点话题;深度学习、卷积神经网络、压缩感知、机器学习是计算机视觉领域近 10 年的前沿研究方向。
基于多视图几何的视觉伺服控制控制 张凯祥-博士论文-2019年-泛读
基于计算机视觉的测距技术研究 姜映舟 -硕士论文-2019-泛读
摄像机标定:
摄像机标定方法分类 :传统标定法、自标定法、主动视觉标定法
传统标定法:优点是精度高,适用于多种摄像机模型,缺点;对标定物的加工精度要求高,算法较为复杂,未考虑到摄像头的畸变等因素。
自标定法:一种不依赖于标定物的方法产生了,这种方法十分简单,只需拍下场景下的两幅图像,利用摄像机存在的内部约束关系即可实现标定,鲁棒性高。自标定法可以说是实现精确与便捷的平衡,简化了标定流程,降低了使用门槛,这种优点使自标定法适用于大多数不需要绝对精准标定的场合,可以大大提高工作效率
主动视觉标定法:传统标定法需要借助标定物,操作不便,虽然自标定法不需要借助标定物,但是精度不能满足要求较高的场合,所以一种改进的基于主动视觉的标定法被发明出来基本实现思路为,将摄像机放置在一个可移动的装置上,然后调整装置位置,做位移运动,相机可以执行指定的操作,获取多个图像,并使用这些特殊动作来计算相机的内部参数。 该方法的优点在于可以获得线性解,鲁棒性高。缺点在于虽然该标定方法不需要标定物,但是对实验环境要求高,实验设备昂贵,需要知道旋转平移矩阵,多向运动增加了标定的复杂性。
张正友标定法:此方法结合了传统与自标定两种方法的优点。对于传统标定法需要高精度标定物而言,标定所需的普通二维棋盘只需通过打印即可获得,同时鲁棒性好的优点得到保留,与自标定法同样便捷简单的操作方式相同,对棋盘进行简单的移动即可获得比自标定法更高的标定精度

基于视觉的机械臂伺服系统研究 张家鑫-硕士论文-2015年-泛读
摘要(部分):本文旨在构建端点闭环(ECL: Endpoint.Close.Loop)系统,其原理就是在
工作空间内,设定摄像机并对采集到的目标图像进行处理,引导机器人的机械手臂来追踪服务目标的定位服务操作。(1)研究机器人关节连杆关系、自由度、位姿描述法等运动学基础知识。
关键:手眼(Eye-to-hand)架构、D -H 法
基于双目视觉的人形机器人物体定位与抓取 姚晓莉-兰州工业学院学报-2020年-泛读
摘要:以人形机器人在非结构化的环境中识别、目标定位与实物抓取为基础,使用仿人机器NAO,进行双目视觉模块扩展,对机器人手臂进行运动学建模、双目视觉标定、视觉识别与定位、视觉伺服控制等问题分析,并通过一系列实验验证了 NAO 机器人可以准确有效地完成目标物体识别、定位与抓取任务.对服务型机器人的应用与深度开发具有参考意义.
10月29日:
1、基于成像尺寸变化的单目视觉测距方法研究 向召利,马宝成-第 41 卷 第 2 期 兵 器 装 备 工 程 学 报-2020年-泛读
摘要:: 提出了一种基于特征尺寸成像变化规律的单目视觉测距算法,采用了单目相机和加速度计的测距方案,通过建立相机 - 目标距离与目标特征尺寸成像的关系,利用目标特征尺寸成像相对变化量的统计特性及特征尺寸与相机 - 目标距离的比值关系对距离输出进行估计并逐步修正,有效提高了单目测距精度。测距试验结果表明: 即使在没有固定参照物的情况下,该方法测距精度依然优于传统单目测距方法。
关键词: 单目; 测距; 特征尺寸; 统计特性
提出问题:双目和多目视觉测距的精度相对较高,但其仍存在一些问题: 一是需要精确的配准,耗时的配准过程对实时视觉导航来说具有不可忽略的影响; 二是要求基线和摄像机光轴严格地处于同一平面上,这使得摄像机的架设及测量平台生产制造的难度极大。单目深度提取方法具有操作简单和成本低等优点,但是传统单目测距方法存在以下缺陷: 需要固定参照物、精度较低、无法适应远距离测量场合等。文献[12]采用人工标记法建立地图,利用单目相机采集图片分析对相机进行定位。文献[13]利用单目摄像机进行了视觉导航研究,该方法亦可应用在已知环境下移动机器人的目标识别及抓取。近年来,国内有学者提出一种基于单摄像机镜像的双目视觉系统,该方法试图融合单目与双目,该方法试图融合单目与双目视觉测距的优点,然而存在以下问题: 允许的图像视差减小了一半,本来应是受镜头畸变影响较小的图像中央区域反而变得不可利用。
解决:出了一种基于特征尺寸成像变化规律的单目视觉测距算法。该算法不需要固定参照物,且测距精度优于传统测距方法。
具体实现:1、利用小孔成像原理求出测距公式,

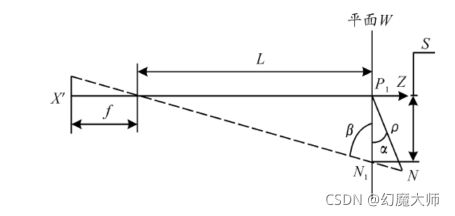
2、重复使用测距公式来求取最优解。
误差分析:
(1)在公式:
在这个公式中简化到公式8要求L>>p;
(2)公式(9)为统计学所得,具有误差波动;
图像预处理采用的是:Matlab
特征点采用Harris 角点,用Harris 算法检测
本文中的测距理论表明,若目标角点密集,即使近距离仍可检测到足够多的角点,测距精度依然可以保证。由此采用了具有尺度不变性的 surf 角点检测算法,
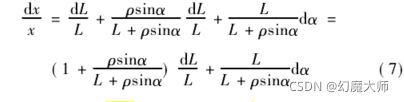

结论:用了单目相机和加速度计的测距方案,通过建立相机-目标距离与目标特征尺寸成像的关系,利用目标特征尺寸成像相对变化量的统计特性及特征尺寸与相机 - 目标距离的比值关系,对距离输出进行估计并逐步修正。利用 harris角点检测法和 surf 角点检测法分别验证了测距算法。测距试验表明: 在不需要固定参照物的情况下,测距精度优于传统测距精度。基于 harris 角点检测的测距精度受距离限制较大,但实时性较好; 基于 surf 角点检测的测距精度基本不受距离影响,但是实时性较差。
三、顶会:
CVPR, ICCV, ECCV