chatglm+langchain+互联网,你可以将大模型接入网络了
最近发现一个好的项目,可以直接将 大模型接入 互联网,笔者这么极客的人,肯定不会错过,使用了一下,哈哈
先来看看界面,使用streamlit包构建的页面
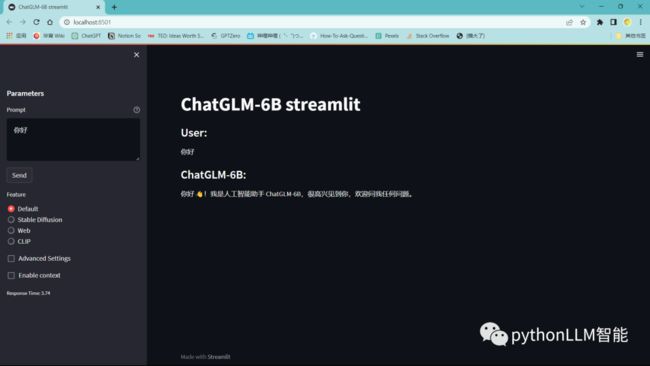
目前支持,纯llm聊天,还有sd插件生成图片,然后就是接入互联网web
sd使用的是stable diffusion模型,当然你也可以换成别的hf上有
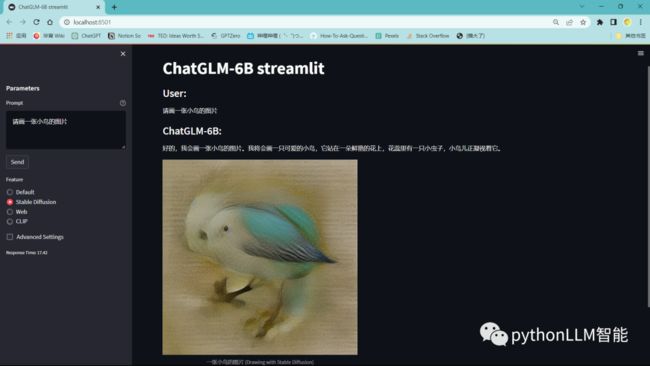
这个不是我们主要介绍的,我们只要看下边这个

来看看目前支持哪些 网站吧
['知乎专栏','知乎回复','百科','微信公众号','新闻','B站专栏','CSDN','GitHub','All(Preview)']
当然这个也可以自己添加一些网站,但是要编写,爬取和解析的过程
类似这样:
def search_zhihu_que(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.44",
}
r = requests.get(url, headers=headers)
html = r.text
soup = BeautifulSoup(html, 'html.parser')
item_list = soup.find_all(class_='List-item')
relist = []
for items in item_list:
item_prelist = items.find(class_ = "RichText ztext CopyrightRichText-richText css-1g0fqss")
item_title = re.sub(r'(<[^>]+>|\s)','',str(item_prelist))
relist.append(item_title)
return relist再来讲一讲,项目是使用web的流程
1、用户输入query
2、基于用户query和你选择的网站比如【知乎专栏】 去bing搜索相关结果,
解析第一页的所有相关问题和对应链接
3、然后根据2中数据对应的链接去爬取内容
4、将内容送给llm去总结答案
5、返回给用户项目是怎样调用bing联网的呢
没错是爬虫惯用的 selenium
def search_web(keyword):
driver = webdriver.Chrome("C:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe")
driver.get(quote("https://cn.bing.com/search?q="+str(keyword),safe='/:?=.'))
for i in range(0, 20000, 350):
time.sleep(0.1)
driver.execute_script('window.scrollTo(0, %s)' % i)
html = driver.execute_script("return document.documentElement.outerHTML")
soup = BeautifulSoup(html, 'html.parser')
item_list = soup.find_all(class_='b_algo')
relist = []
for items in item_list:
item_prelist = items.find('h2')
item_title = re.sub(r'(<[^>]+>|\s)','',str(item_prelist))
href_s = item_prelist.find("a", href=True)
href = href_s["href"]
relist.append([item_title, href])
item_list = soup.find_all(class_ ='ans_nws ans_nws_fdbk')
for items in item_list:
for i in range(1,10):
item_prelist = items.find(class_ = f"nws_cwrp nws_itm_cjk item{i}", url=True, titletext=True)
if item_prelist is not None:
url = item_prelist["url"].replace('\ue000','').replace('\ue001','')
title = item_prelist["titletext"]
relist.append([title, url])
return relist配置webdriver 网上有一大片,无需我来具体说了
安装好依赖包后,启动命令如下:
streamlit run streamlit_new.py然后你就可以 使用 大模型+网络的组合了,哈哈,还等什么,去试试吧
关于部署chatglm不同的可以看这篇国产版chatgpt,可以本地部署了,效果也不错
项目链接:https://github.com/LemonQu-GIT/ChatGLM-6B-Engineering/
下期预告:
下期分享lora微调自己的图片的训练,欢迎关注

往期回顾:
什么情况用Bert模型,什么情况用LLaMA、ChatGLM类大模型,咋选?
基于chatglm、moss+知识库+langchain的问系统的搭建
国产chatgpt可以微调了,手把手教你微调chatglm,文末有福利
国产版chatgpt,可以本地部署了,效果也不错
国产chatgpt:chatGLM基于incontext learning原理微调nlp任务
训练个中文版ChatGPT没那么难:不用A100,开源Alpaca-LoRA+RTX 4090就能搞定
chatgpt免费用了,竟然可以无限coding