学习使用iptables
原文:https://linuxgeeks.github.io/2017/03/10/094107-%E5%AD%A6%E4%B9%A0%E4%BD%BF%E7%94%A8iptables/
基础知识
防火墙
工作于主机或网络边缘,对于进出的报文根据事先定义的规则做检查,对被匹配到的报文作出相应处理的组件
iptables
linux 的包过滤功能,即 linux 防火墙,它由 netfilter 和 iptables 两个组件组成。真正实现防火墙功能的是 netfilter,它是一个 Linux 内核模块,工作于 Kernel space 做实际的包过滤。
Netfilter 的官方站点 http://www.netfilter.org ,此站点的 FAQ 是开始学习 iptables 和 Netfilter 的好地方。
四表五链
netfilter 使用表(Tables)和 链(Chains)来组织网络包的处理规则(Rules)。按照从高到低的优先级,它默认定义了以下表和链:
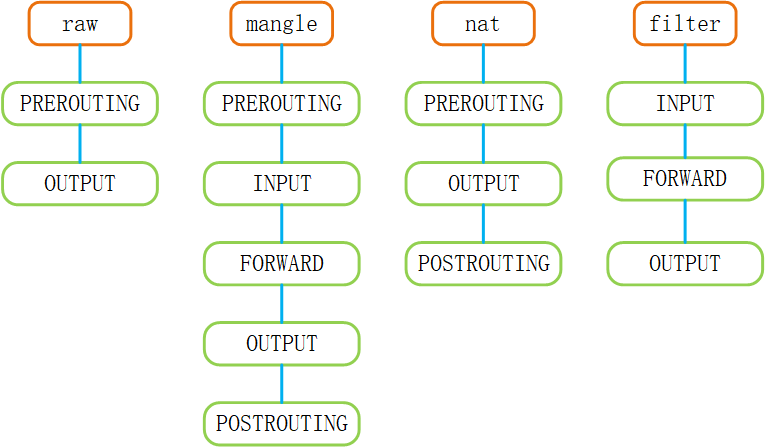
防火墙规则的匹配顺序
因为 iptables 是利用数据包过滤的机制, 所以它会分析数据包的表头数据,将表头数据与定义的规则做匹配,根据匹配结果来决定该数据包是否可以进入主机或者是被丢弃。 也就是说如果数据包能被防火墙规则匹配到就进行相应的动作(Target),否则就继续进行下一条规则的匹配,直到有一条规则能匹配到为止,而重点在于规则的匹配顺序。
假设我们在一台主机已经事先定义好了 10 条防火墙规则,那么当互联网中来了一个数据包想要进入这台主机时, 防火墙是如何分析和匹配这个数据包的呢?
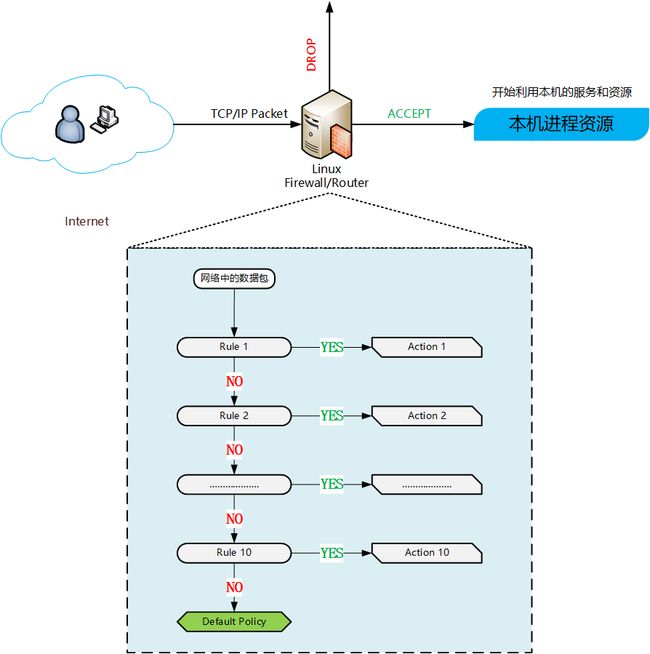
当数据包要进入到主机之前,会先经由 NetFilter 进行检查,也就是 iptables 规则。 检查通过则接受 (ACCEPT) 进入本机取得资源,如果检查不通过,则可能予以丢弃 (DROP) 。
上图主要是为了说明 规则是有顺序的,当数据包被 Rule 1 做匹配时, 如果数据包能被它匹配到,就进行 Action 1 的动作,而不会再被后续的 Rule 2, Rule 3…. 等做匹配了。
而如果这个数据包并没有被 Rule 1 匹配到,那就会开始进行 Rule 2 的匹配,同理数据包就会被一个一个规则做匹配,直到有一条规则能匹配到为止。 如果所有的规则都无法匹配到这个数据包,此时就会交给默认策略( Policy) 来决定数据包的去向。 所以一旦定义的规则顺序排列错误,那就会产生很严重的后果。
比如我们有一台 Linux 服务器提供 Web 服务,那么就要针对 port 80 来启用通过的规则,但是后来发现有一个来源为 192.168.100.100 的 IP 总是恶意地尝试入侵 Web 服务器,所以这时候应该编写规则将这个 IP 拒绝,其他将请求 Web 服务的数据包通过, 最后把所有的不是请求 Web 服务的数据包都给丢弃。就这三个规则而言,应该如何设定匹配顺序呢?
- Rule 1 先把来自 192.168.100.100 的 IP 执行丢弃动作 DROP
- Rule 2 再让请求 Web 服务的数据包通过
- Rule 3 将所有的数据包丢弃
这样的排列顺序就能符合我们的需求,一旦你没有搞清楚将顺序排错了,变成:
- Rule 1 先让请求 Web 服务的数据包通过
- Rule 2 再把来自 192.168.100.100 的 IP 执行丢弃动作 DROP
- Rule 3 将所有的数据包丢弃
此时那个 192.168.100.100 将可以正常请求 Web 服务,因为它会被定义的第一条规则匹配到并且让它通过,一旦有一条规则匹配了,就不会再去进行第二条规则的匹配。
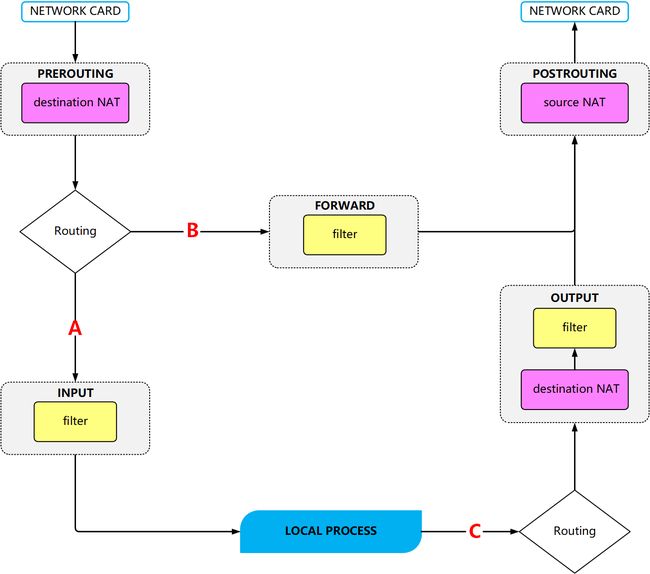
数据包的处理过程
暂时不考虑由哪个表处理,在只看链处理过程的情况下,数据包一般是这样来处理的
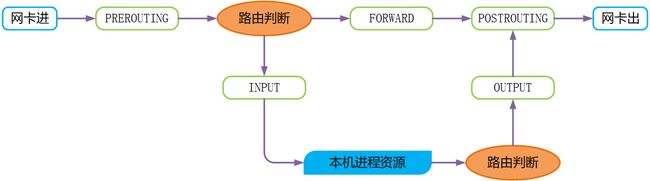
其中路由判断是判断数据包的目标,也就是判断 Destination = localhost ??
而实际上的处理过程比较复杂,数据包要经过多个 table 来处理。
对于 Web 服务器来说,要想让客户端对它发送 web 请求,就得处理 filter 的 INPUT 链; 对于用作局域网路由器的 Linux 来说,就得要分析 nat 的各个链以及 filter 的 FORWARD 链才行。
总而言之,各个表以及链之间是有关联的:
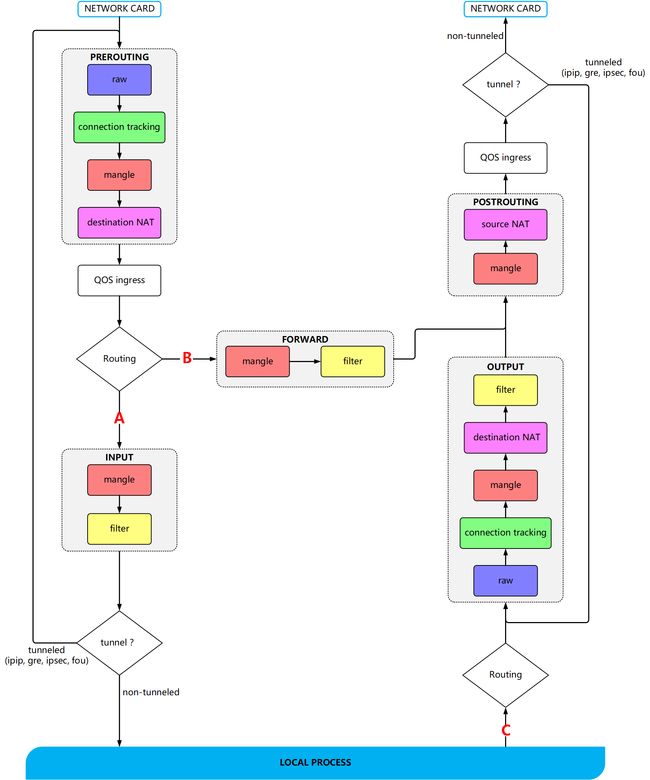
上面的图示很复杂,不过基本上 iptables 可以控制三种数据包的流向:
-
数据包进入 Linux 主机使用资源 (路径 A),在路由判断后已经确定是向 Linux 主机发送请求的数据包,比如客户端向 web 服务器端发送的请求,主要会经过 filter 表的 INPUT 链来进行处理;
-
数据包的目的地不是本机,而是经过本机做转发,没有使用本机的资源,向其后端主机流动 (路径 B): 在路由判断之前进行数据包表头的修订作业后,发现到数据包主要是要经过防火墙而去后端,此时就会经过路径 B 来跑动。 主要经过的链是 nat 表的 PREROUTING, filter 表的 FORWARD 以及 nat表 的 POSTROUTING。
-
数据包由本机发送出去 (路径 C): 例如服务器端要响应客户端的请求,或者是本机作为客户端向其他服务器主动发送的数据包,都是经过路径 C 来处理的。先是经过路由判断, 决定了输出的路径后,再由 filter 表的 OUTPUT 链来处理,当然最终还会经过 nat 的 POSTROUTING 链。
事实上,不建议使用 raw 和 mangle 做包的过滤,因为他们是用来做高级操作的。在不考虑搭建隧道的情况下,将上面图简化后,那就容易看的多了:
iptables命令
iptables 命令用来编写规则,规则就是指向标,对不同的连接和数据包做过滤,或者允许它们去向什么地方。
它的语法格式如下:
复制
1 |
iptables [-t table] command CHAIN [match] [target/jump] |
[-t table] 用来指定要操作的表。一般情况下不是必须要指定使用的表,因为 iptables 不指定 table 就默认使用 filter 表来执行所有的命令。
command 告诉程序该做什么,比如插入一条规则还是追加一条规则,或者是删除一条规则。
CHAIN 说明了要操作哪一条链
match 来根据包的特点来匹配数据包,其中会细致地描述包的某个特点,比如来源 IP 地址,网络接口,端口,协议类型等,以使这个包区别于其它所有的包。
target/jump 说明了对 match 到的数据包做什么操作,或者告诉数据包它应该去往何处。若数据包符合所有的 match,内核就用 target 来处理它,或者说把包发往 target。比如我们可以让内核把包发送到当前表中的其他链(可能是自定义链),或者只是丢弃这个包而没有什么处理,或者向发送者返回某个特殊的应答信息。非常重要的一点是 target 指令必须在最后。
iptables 虽然不是服务但在红帽的 5 和 6 版本系统上有服务脚本 /etc/init.d/iptables,服务脚本的主要作用在于生效保存的规则,装载及移除相关内核模块:
复制
1 2 3 4 5 6 |
iptable_nat iptable_filter iptable_mangle iptable_raw ip_nat ip_conntrack |
在红帽 7 上 ip_nat 换为了 nf_nat , ip_conntrack 换为了 nf_conntrack,并且它使用 firewalld.service 服务来处理数据包而没有 iptables.service,也没有服务脚本
复制
1 2 3 4 5 6 7 |
[root@m1 ~]# systemctl status firewalld.service iptables.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
Unit iptables.service could not be found.
[root@m1 ~]#
|
如果想要使用 iptables.service ,通过 yum 直接安装即可
复制
1 |
yum install iptables-services |
table
raw
raw 表优先级最高,它支持一个特殊的 target,即 TRACE ,使用内核记录下每条匹配该包的对应 iptables 规则信息。利用这个 target ,可以实现对 iptables 规则的跟踪调试。
复制
1 |
iptables -t raw -A OUTPUT -p icmp -j TRACE |
使用 raw 表添加了 iptables 规则后,将不经过连接跟踪模块,一般是为了不让 iptables 做数据包连接追踪来达到提高性能的目的。比如一台访问量比较高的 web 服务器,可以让 80 端口不再经过 iptables 做数据包的链接跟踪处理,以提高用户的访问速度。
在 raw 表的规则处理完后,将跳过 nat 表和 nf_conntrack 处理,即不再做地址转换和数据包的链接跟踪处理。
复制
1 |
iptables -t raw -I PREROUTING -p tcp --dport 80 -j ACCEPT |
mangle
在 mangle 表中可以进行高级路由信息数据包的修改。不建议在这个表里做任何过滤性的操作,不管是 DNAT,SNAT 或 MASQUERADE。
nat
Network Address Translation 简称 nat ,在 nat 表中主要用来实现网络地址转换,它处理源、目标 IP 和端口的转换,与本机资源无关。
filter
filter 表用来匹配并过滤数据包,我们就是在这里根据包的内容对包做 DROP 或 ACCEPT 的。当然也可以预先在其他地方做些过滤,但是 filter 表才是设计用来做过滤的,所以说用它做过滤最合适不过了。
command
使用 -L 或 --list 列出指定链中所有的规则,默认列出 filter 表中所有链的内容。.
复制
1 |
iptables -L |
结合 -L 使用的还有几个附属选项,-n 或 --numeric 以数字形式显示地址和端口号,不对其进行解析。
复制
1 |
iptables -nL |
-v 或 --verbose 显示链及规则详细信息。
复制
1 |
iptables -vL |
--line-numbers 显示规则的序号
复制
1 |
iptables -L --line-numbers |
最常用的情况是把这几个选项结合起来,使得其屏幕输出显得更人性化
复制
1 2 3 4 5 |
iptables -vnL --line-numbers iptables -vnL INPUT --line-numbers iptables -t nat -vnL iptables -t nat -vnL PREROUTING iptables -t nat -vnL PREROUTING --line-numbers |
-x 或 --exact 显示计数器的精确值而不是近似值
复制
1 |
iptables -vnL INPUT -x |
使用 -P 或 --policy 设置指定链的默认策略,如果将默认策略设置为 DROP 时,请事先将自己信任的数据放行,比如 TCP 协议的 22 号端口,即 ssh 。在列出规则时,每一个链上都有一个 policy 的信息,它后面第一个字段就是默认的策略
复制
1 2 3 |
iptables -P INPUT ACCEPT iptables -P OUTPUT ACCEPT iptables -P FORWARD ACCEPT |
使用 -I 或 --insert 在指定链中插入一条新的规则,默认在链的开头插入
复制
1 2 3 |
iptables -t filter -I INPUT -p tcp --dport 22 -j ACCEPT iptables -t filter -I INPUT -p tcp --dport 22 # 不写 -j target 将会交给默认策略处理 iptables -t filter -I INPUT 5 -p tcp --dport 22 # 将规则插入到第五条 |
使用 -A 或 --append 在指定链的末尾处追加一条新的规则
复制
1 |
iptables -t filter -A INPUT -p tcp --dport 22 -j ACCEPT |
使用 -D 或 --delete 删除指定链中的某条规则,可以按照内容确定要删除的规则
复制
1 |
iptables -t filter -D INPUT -p tcp --dport 22 -j ACCEPT |
还可以根据规则的序号删除,规则删除后将重新进行编号,这一点一定要注意
复制
1 2 |
iptables -t filter -vnL INPUT --line-numbers iptables -t filter -D INPUT 3 |
使用 -R 或 --replace 修改、替换指定链中的一条规则,按规则序号或内容确定
复制
1 |
iptables -t filter -R INPUT 2 -p icmp -j ACCEPT |
使用 -F 或 --flush 清空指定链中的所有规则,默认清空表中所有链的内容
复制
1 2 3 4 |
iptables -t mangle -F # 清空 mangle 表中所有链中的规则 iptables -t filter -F INPUT # 清空 filter 表中 INPUT 链中的所有规则 |
使用 -N 或 --new-chain 新建一条用户自己定义的规则链
复制
1 2 3 4 5 6 7 8 |
iptables -t filter -N DOCKER # 在 filter 表中新建一个名为 DOCKER 的自定义链 iptables -t filter -I DOCKER -j ACCEPT # 在自定义的链 DOCKER 中添加对应匹配条件的处理规则 iptables -t filter -I FORWARD -o docker0 -j DOCKER # 在 FORWARD 中添加规则,用来匹配符合条件的数据包,并将其交给自定义链处理 |
使用 -X 或 --delete-chain 删除指定表中用户自定义的规则链,如果自定义链被其他链中的规则引用则无法删除,需要提前将有引用的规则删除,并清空自定义链中的规则
复制
1 2 3 4 |
iptables -X DOCKER iptables -D FORWARD -o docker0 -j DOCKER iptables -F DOCKER iptables -X DOCKER |
使用 -E 或 --rename-chain 重命名自定义链
复制
1 2 |
iptables -N 'test-chain' iptables -E 'test-chain' 'TEST-CHAIN' |
使用 -Z 或 --zero 将指定链中的所有规则的包字节计数器归零,不指定链则将所有链中的计数器置零
复制
1 2 |
iptables -Z iptables -Z INPUT |
使用 -V 或 --version 查看 iptables 命令工具的版本信息
复制
1 |
iptables -V |
使用 -h 或 --help 查看命令帮助信息
复制
1 |
iptables -h |
chain
说到链还是得把简化的处理流程图再拿过来:
默认链
- PREROUTING:进入 netfilter 后的数据包在进入路由判断前执行的规则
- INPUT:路由判断后,目的地是本机,要进入本机内部获取本地服务资源
- FORWARD:路由判断后目的地不是本机,经过本机做转发的数据包而执行的规则。与本机没有关联。
- OUTPUT:由本机产生,需向外发的数据包执行的规则
- POSTROUTING:路由判断后发送到网卡接口前,数据包准备离开 netfilter 时执行的规则
自定义链
自定义链必须在默认链调用后才能发挥作用,如果没有被自定义链中的任何规则匹配,还应该有返回机制。用户可以删除自定义的空链,但不可以删除默认链。
计数器
每一条规则都有两个内置的计数器,在 pkts 一列将会记录被规则被匹配到的报文个数,bytes 一列将会记录被匹配的报文大小之和
复制
1 2 3 4 |
[root@study ~]# iptables -vnL INPUT Chain INPUT (policy ACCEPT 1608 packets, 176K bytes) pkts bytes target prot opt in out source destination [root@study ~]# |
match
匹配模式分为通用匹配和扩展匹配
通用匹配
通用匹配适用于所有的规则,无需依赖模块,自己本身就能完成检查匹配。
| 匹配参数 | 说明 |
|---|---|
| ! | 使用叹号对条件取反 |
-p,--protocol |
指定协议(tcp,udp,icmp等),可使用all来指定所有协议 |
-s,--src,--source |
指定数据包源地址,可使用IP地址、网络地址、主机名 |
-d,--dst,--destination |
指定目的地址 |
-i,--in-interface |
指定数据报文流入接口,用于PREROUTING、INPUT、FORWARD |
-o,--out-interface |
指定数据报文流出接口,用于OUTPUT、POSTROUTING、FORWARD |
使用 -i 或 -o 可以使用 + 做通配,比如 -i eth+ 指的是从 eth 网卡进入的数据包。
扩展匹配
扩展匹配,需要依赖模块来完成检查匹配。扩展匹配比较特殊,其中有些专门针对不同的协议,还有一些针对的是状态(state),所有者(owner),访问的频率限制(limit)等。你可以通过 man iptables-extensions 查看相关的帮助。
扩展匹配又分为了隐式扩展和显式扩展
隐式扩展
隐式扩展,不用特别指明由那个模块进行,当使用 -p {tcp|udp|icmp} 中的一种时,可以直接使用扩展专用选项
| 扩展条件 | 扩展选项 | 说明 |
|---|---|---|
-p tcp,--protocol tcp |
--sport,--source-port |
来源端口,可以是连续的,例如 1024:65535 |
--dport,--destination-port |
目的端口 | |
--tcp-flags |
tcp 标志位 | |
--syn |
第一次握手 | |
-p udp,--protocol udp |
--sport,--source-port |
来源端口 |
--dport,--destination-port |
目的端口 | |
-p icmp,--protocol icmp |
--icmp-type |
icmp 类型 |
--tcp-flags mask comp 用于匹配 TCP 标志位。其中只检查 mask 指定的 TCP 的标志位(逗号分开的标志位列表),comp 表示此列表出现在 mask 中,且必须为 1。如果没有出现在 mask 中,而 comp 中出现的,必须为 0
匹配 TCP 三次握手的第一次,即匹配四个 TCP 标志位(SYN,FIN,ACK,RST),其中 SYN 为 1,其他为 0
复制
1 2 3 |
iptables -t nat -I PREROUTING -p tcp --tcp-flags SYN,FIN,ACK,RST SYN -j ACCEPT # 等价于 iptables -t nat -I PREROUTING -p tcp --syn -j ACCEPT |
再比如匹配四个 TCP 标志位(SYN,FIN,ACK,RST),其中 SYN 和 ACK 为 1,其他为 0
复制
1 |
iptables -t nat -I PREROUTING -p tcp --tcp-flags SYN,FIN,ACK,RST SYN,ACK -j ACCEPT |
--icmp-type 用来匹配 ICMP 报文类型,可以使报文类型代码。其中 8 等同于 echo-request, 0 等同于 echo-reply。
复制
1 2 3 4 5 6 7 |
# 允许本机能 ping 其他主机 iptables -A OUTPUT -p icmp --icmp-type echo-request -j ACCEPT iptables -A INPUT -p icmp --icmp-type echo-reply -j ACCEPT # ----------------------------------------------- # 允许其他主机能 ping 本机 iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT iptables -A OUTPUT -p icmp --icmp-type 0 -j ACCEPT |
代码的摘要,具体可以参考 rfc文档 以及 网络博客
复制
1 2 3 4 5 6 7 8 9 10 11 |
0 Echo Reply 3 Destination Unreachable 4 Source Quench 5 Redirect 8 Echo 11 Time Exceeded 12 Parameter Problem 13 Timestamp 14 Timestamp Reply 15 Information Request 16 Information Reply |
显式扩展
显式扩展必须使用 -m 或 --match 选项指明是由哪个模块进行的扩展,此功能可以使用额外的匹配机制
-m state:状态扩展,结合 nf_conntrack 模块追踪回话的状态
--state匹配连接的状态- NEW 新连接发起的请求
- ESTABLISHED 已经建立的连接(即:对于新请求的响应)
- INVALID 非法连接请求
- RELATED 相关连的连接(由命令发起,例如 ftp )
复制
1 2 3 4 |
iptables -t filter -I INPUT -p tcp --dport 22 -m state --state NEW -j ACCEPT # 将与本机新建立 ssh 连接的数据包放行 iptables -t filter -I INPUT -p tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT # 状态为 NEW 或 ESTABLISHED 的 ssh 连接都放行 |
-m multiport:离散的多端口扩展
--source-ports,--sports指定多个源端口--destination-ports,--dports指定多个目的端口--ports源和目的端口
复制
1 2 |
iptables -t filter -I INPUT -p tcp -m multiport --dports 21,22,80 -j ACCEPT # 将协议为 TCP 目标端口为 21,22,80 的数据包放行 |
-m iprange:匹配IP范围。
--src-range匹配源 IP 范围--dst-range匹配目的 IP 范围
复制
1 2 |
iptables -t filter -I INPUT -m iprange --src-range 192.168.1.100-192.168.1.200 -j ACCEPT # 将来源IP范围是 192.168.1.100-192.168.1.20 的数据包放行 |
-m connlimit:连接数限定。
--connlimit-above n,匹配连接数达到 n,一般进行取反使用
复制
1 2 |
iptables -A INPUT -d 192.168.2.2 -p tcp --dport 80 -m connlimt !--connlimt-above 5 -j ACCEPT # 连接数未达到 5 个则放行,否则按默认规则处理(一般默认规则是丢弃) |
-m limit:令牌桶过滤器,不控制最大上限。
--limit n[/second|/minute|/hour|/day]用来在单位时间内最多允许 n 个数据包,3/minute表示每分钟最多 3 个--limit-burst来匹配峰值,即匹配蜂拥而至的连接数有多大,默认为 5
复制
1 2 3 |
iptables -I INPUT -d 192.168.2.2 -p icmp --icmp-type 8 -m limit --limit 5/minute --limit-burst 6 -j ACCEPT iptables -I INPUT -d 192.168.2.2 -p icmp --icmp-type 8 -j DROP # 目标为本机,协议为 icmp,限定每分钟最多可以连接5个(1/12s),一批最高峰值为6个,即前6个速度比较快,后面的按照 5/minute 作回应 |
-m string:匹配请求的报文中的字符串,字符匹配检查高效算法:kmp, bm。
--algo {kmp|bm}指定算--string "STRING"指定普通字符串--hex-string "HEX_STRING", 指定编码成16进制格式的字符串
复制
1 2 3 4 |
iptables -I OUTPUT -s 192.168.2.2 -m string --algo kmp --string "H7N9" -j REJECT # 源地址为 192.168.2.2,并且报文中匹配到 H7N9 则丢弃 iptables -I FORWARD -p tcp -m string --string "qq.com" --algo bm -j DROP iptables -I FORWARD -p udp -m string --string "qq.com" --algo bm -j DROP |
-m time:基于时间做访问控制,在有些限制时间段访问网络的情况下十分有用
--datestart YYYY[-MM][-DD[Thh[:mm[:ss]]]]起始日期--datestop YYYY[-MM][-DD[Thh[:mm[:ss]]]]终止日期--timestart hh:mm[:ss]起始时间--timestop hh:mm[:ss]终止时间--weekdays Sa[,Su]一周中的哪些天
复制
1 2 |
iptables -I INPUT -d 172.16.100.7 -p tcp --dport 80 -m time --timestart 08:20 --timestop 18:40 --weekdays Mon,Tue,Thu,Fri -j REJECT # 周一、二、四、五的 8:20 到 18:40 禁止其他主机访问本机(172.16.100.7)的80端口 |
-m mac:基于包的 MAC 源地址做访问控制,它也可以用叹号 ! 取反。因为 MAC addresses 只用于 Ethernet 类型的网络,所以只能用于 Ethernet 接口。而且它只能在 PREROUTING,FORWARD 和 INPUT 链里使用。
--mac-source指定源 MAC 地址,格式只能是XX:XX:XX:XX:XX:XX,
复制
1 |
iptables -A FORWARD -m mac --mac-source 00:00:00:00:00:01 -j DROP |
在局域网中如果有人在下载比较大的文件,会占用极大的带宽而影响到了其他人的网络访问,这时候我们在防火墙上针对这个来源的 IP 做 limit 或者直接 DROP 就好了,但是如果这个人发现自己被封网了,就自己指定了静态地址并且换了另外一个 IP ,这时候就需要针对 MAC 地址做限制了,限制了 MAC 来源之后,不管怎么换 IP 地址都无济于事。
-m comment:对规则做说明、注释
--comment 'string'指定注释为string,注释最长 256 个字符
复制
1 |
iptables -A INPUT -s 192.168.1.0/24 -p tcp --dport 80 -j ACCEPT -m comment --comment "This is my local Lan" |
添加了注释的规则,即便是在很久以后回头查看规则的时候你就能很直观地知道这个规则是用来做什么的
复制
1 2 3 4 5 |
[root@m2 ~]# iptables -vnL INPUT
Chain INPUT (policy ACCEPT 34 packets, 3072 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * * 192.168.1.0/24 0.0.0.0/0 tcp dpt:80 /* This is my local Lan */
[root@m2 ~]#
|
Target
target 指的是由规则指定的操作,对规则匹配到的包做什么样的动作
ACCEPT
使用 -j ACCEPT 放行,一旦数据包满足了指定的匹配条件就允许数据包通过,并且不会再去匹配当前链中的其他规则或同一个表内的其他规则,但它还要通过其他表中的链,而且在那儿可能会被 DROP 也说不准。
放行 TCP 协议目标端口是 22 的数据包
复制
1 2 3 |
iptables -t filter -I INPUT -p tcp --destination-port 22 -j ACCEPT # 等价于 iptables -I INPUT -p tcp --dport 22 -j ACCEPT |
放行本机到本机的连接
复制
1 2 |
iptables -A INPUT -i lo -j ACCEPT iptables -A OUTPUT -o lo -j ACCEPT |
DROP
使用 -j DROP 丢弃,不做任何回应。在某些情况下,这个 target 会引起意外的结果,因为它不会向发送者返回任何信息,也不会向路由器返回信息,这就可能会使连接的另一方的 sockets 因苦等回音而亡。解决这个问题的较好的办法是使用 REJECT
复制
1 |
iptables -I INPUT -p tcp --dport 22 -j DROP |
很多情况下我们并不期望所有的来源都能访问某些服务器,只允许一个或多个 IP ,一个或多个网段来访问。比如,在局域网中有一个 Web 服务器为 192.168.100.100,只允许 192.168.1.0/24 来访问,其他的拒绝。要实现这样的功能,在 Web 服务器上有两种做法,我们假设两种情况下的默认策略都是 ACCEPT 。
一种是先允许信任的地址段,最后再拒绝所有的。也就是说来自 192.168.1.0/24 匹配到第一条规则,否则就被第二条规则匹配到并丢弃
复制
1 2 |
iptables -t filter -A INPUT -p tcp -s 192.168.1.0/24 --dport 80 -j ACCEPT iptables -t filter -A INPUT -p tcp --dport 80 -j DROP |
另一种则把不是我们信任的地址段直接丢弃,如果是信任的地址段就不会被这个规则匹配到,然后交给默认规则处理。看上去这种方法更好,一条就搞定了。
复制
1 |
iptables -t filter -A INPUT -p tcp ! -s 192.168.1.0/24 --dport 80 -j DROP |
现在由于业务有了新的变动,需要再加入一个信任的地址段 192.168.2.0/24,于是你又按照第二种方法加入了一条规则
复制
1 |
iptables -t filter -A INPUT -p tcp ! -s 192.168.2.0/24 --dport 80 -j DROP |
看上去把来源不是 192.168.1.0/24 内的包丢弃,然后再把来源不是 192.168.2.0/24 内的包丢弃就可以了,但是最后测试的时候你发现 Web 服务器好像谁都不能访问了。我们来分析一下原因:
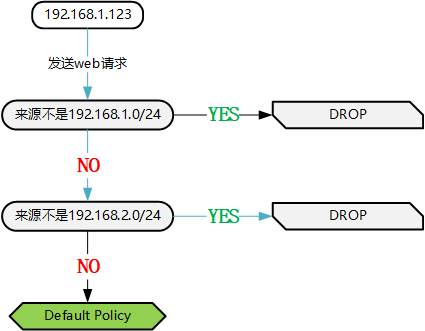
当来源是 192.168.1.123 发起的请求时,第一条规则没有被匹配,继续向下走让第二条做匹配,匹配成功然后被丢弃,也就是上图中蓝色箭头所指向的方向
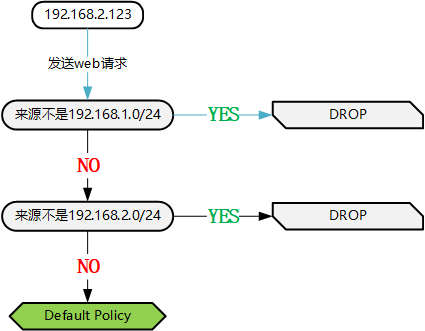
当来源是 192.168.2.123 发起的请求时,第一条规则匹配成功然后被丢弃,也就是上图中蓝色箭头所指向的方向
这样一来,不管谁来请求都被 DROP 掉了。所以应当使用第一种先允许再拒绝的方法
复制
1 2 3 |
iptables -t filter -A INPUT -p tcp -s 192.168.1.0/24 --dport 80 -j ACCEPT iptables -t filter -A INPUT -p tcp -s 192.168.2.0/24 --dport 80 -j ACCEPT iptables -t filter -A INPUT -p tcp --dport 80 -j DROP |
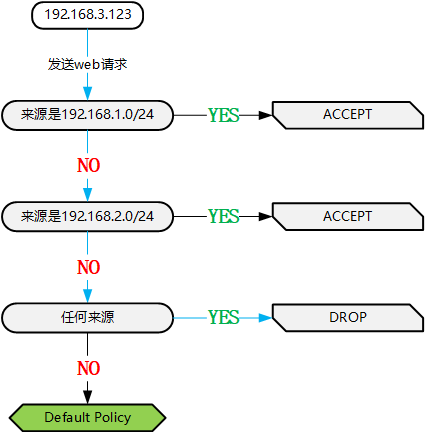
当来源是 192.168.3.123 发起的请求时,第一条规则没有匹配到,然后交给第二条规则,也没有匹配到,再交给第三条规则,匹配成功然后被丢弃,也就是上图中蓝色箭头所指向的方向
REJECT
使用 -j REJECT 拒绝数据包通过,并且向发送者返回错误信息。这个 target 只能用在 filter表中 INPUT、FORWARD、OUTPU和它们的子链里,而且包含 REJECT 的链也只能被它们调用,否则不能发挥作用。它只有一个选项 --reject-with,是用来控制返回的错误信息的种类的。可用的信息类型有:
- icmp-net-unreachable
- icmp-host-unreachable
- icmp-port-unreachable
- icmp-proto-unreachable
- icmp-net-prohibited
- icmp-host-prohibited 。
其中缺省的是 icmp-port-unreachable。
复制
1 |
iptables -I INPUT -p icmp -j REJECT --reject-with icmp-port-unreachable |
另外一个类型是 tcp-reset,只能用于TCP协议。 它的作用是告诉 REJECT 返回一个 TCP RST 包(这个包以文雅的方式关闭TCP连接,正如 iptables 的 man page 中说的,tcpreset 主要用来阻止身份识别探针(即113/tcp,当向被破坏的邮件主机发送邮件时,探针常被用到,否则它不会接受你的信)
复制
1 |
iptables -I INPUT -p tcp --sport 113 -j REJECT --reject-with tcp-reset |
SNAT
这个 target 是用来做来源IP地址转换的,就是重写包的源IP地址。SNAT 只能用在 nat 表的 POSTROUTING 链里。只要会话连接中的的第一个符合条件的包被 SNAT 了,那么这个连接的其他所有的包都会自动地被 SNAT,而且这个规则还会应用于这个连接所在流的所有数据包。
局域网中的主机想要通过防火墙访问互联网时,就需要用到它。先在内核里打开 ip 转发功能,然后再写一个 SNAT 规则,就可以把所有从本地网络出去的包的源地址改为外网地址了。如果不这样做而是直接转发本地网的包的话,互联网中的服务器发现是个内网 IP 发送过来的请求,就不知道往哪儿发送响应了,因为内网属于私有专用网络,不能在互联网上直接使用的。
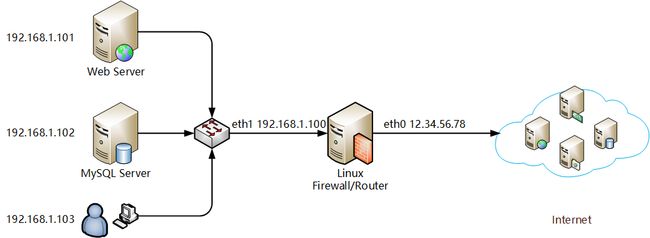
在这里 SNAT 的作用就是让所有从局域网发出去的的包看起来都是从防火墙发出的。
复制
1 2 3 |
echo 1 > /proc/sys/net/ipv4/ip_forward # 临时开启转发 iptables -t nat -I POSTROUTING -o eth0 -s 192.168.1.0/24 -j SNAT --to 12.34.56.78 |
要永久开启转发需要编辑 /etc/sysctl.conf,并配置 net.ipv4.ip_forward = 1,再执行 sysctl -p 即可
如果一个网卡上有多个连续的 IP 还可以对一个范围内的 IP 做 SNAT,以达到负载均衡的效果,每个会话流被随机分配一个 IP,但对于同一个会话,在会话期间使用的是同一个 IP 。
复制
1 |
iptables -t nat -I POSTROUTING -o eth0 -s 192.168.1.0/24 -j SNAT --to 12.34.56.78-12.34.56.80 |
在指定 -p tcp 或 -p udp 的前提下在 SNAT 的时候还可以指定源端口的范围
复制
1 |
iptables -t nat -I POSTROUTING -p tcp -o eth0 -s 192.168.1.0/24 -j SNAT --to 12.34.56.78-12.34.56.80:1024-32000 |
这样的话包的源端口就被限制在 1024-32000了。注意,如果可能的话 iptables 总是想尽可能避免任何的端口的变更,也就是说,它总是尽力使用建立连接时所用的端口。
但是如果两台主机使用了相同的源端口,iptables 将会把他们的其中之一映射到另外的一个端口。如果没有指定端口范围, 所有的在 512 以内的源端口会被映射到 512 以内的另一个端口,512 和 1023 之间的将会被映射到 1024 内的另一个端口,其他的将会被映射到大于或等于于 1024 的另一个端口,即同范围映射。这种映射和目的端口无关,因此,如果客户端想要发送请求到防火墙外的 HTTP 服务器,它是不会被映射到 FTP 所用的端口的。
MASQUERADE
这个 target 和 SNAT 的作用是一样的,但是它可以自动获得可用的 IP 而不是像 SNAT 那样需要指定 --to-source。
MASQUERADE 是被专门设计用于那些动态获取 IP 地址的连接的,比如拨号上网、DHCP连接等,这些情况下 SNAT 就会有很大的局限性。如果有固定的 IP 地址的话,最好还是用SNAT,因为 MASQUERADE 在获取可用 IP 的时候会带来额外的资源消耗。
另外,当网卡停用时 MASQUERADE 不会记住任何连接,而 SNAT 是会将连接跟踪的数据保留下来一段时间,并且 SNAT 会占用很多链接追踪的内存资源。
所以当 IP 地址是动态获取而不固定时,使用 MASQUERADE,有固定的 IP 地址时最好用 SNAT。
还要注意 MASQUERADE 和 SNAT 一样,只能用于 nat 表的 POSTROUTING 链。它也可以指定源端口或范围,如果是指定单个端口用 --to-ports 1025,指定端口范围用 --to-1024-3000
复制
1 2 |
iptables -t nat -I POSTROUTING -o eth0 -s 192.168.1.0/24 -j MASQUERADE # 不管现在 eth0上获得了怎样的动态 IP,使用 MASQUERADE 都会自动读取网卡上可用 IP 然后做 SNAT 出去,这样就实现了很好的动态 SNAT 地址转换 |
DNAT
这个 target 是用来做目标 IP 地址转换的,就是重写包的目的 IP 地址。如果一个包被匹配了,那么和它属于同一个流的所有的包都会被自动转换,然后就可以被路由到正确的主机或网络。目的地址也可以是一个范围,这样的话 DNAT会为每一个流随机分配一个地址。因此可以用这个 target 做某种类型的负载均衡。为了便于理解,下面阐述为映射。
注意,DNAT 必须在 POSTROUTING 之前进行,因为交给 POSTROUTING 的时候目标地址就已经确定了,此时做 DNAT 已经为时已晚。并且 DNAT 只能用在 nat 表的 PREROUTING 和 OUTPUT 链中,或者是被这两条链调用的链里。
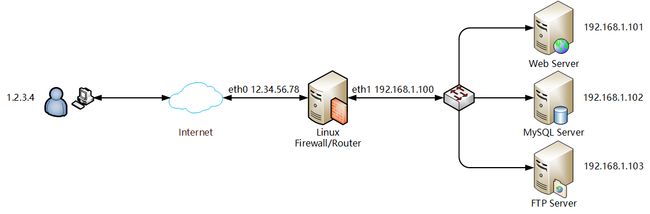
如图所示,如果你的 Web 、MySQL、FTP 服务器在局域网内部,而且没有外网 IP 地址,那就可以使用这个 target 让防火墙把所有到它自己的端口的分别映射到局域网内部的各个主机上。
复制
1 2 3 |
iptables -t nat -I PREROUTING 1 -p tcp -d 12.34.56.78 --dport 80 -j DNAT --to 192.168.1.101:80 iptables -t nat -I PREROUTING 2 -p tcp -d 12.34.56.78 --dport 3306 -j DNAT --to 192.168.1.102:3306 iptables -t nat -I PREROUTING 3 -p tcp -d 12.34.56.78 --dport 21 -j DNAT --to 192.168.1.103:21 |
在默认情况下,很多服务器的 SSH 服务都监听在 22 号端口,如果是 ssh 到局域网的一台服务器查看配置,执行一些维护命令该怎么办呢?
第一个想到的就是按照刚才的方式再做 22 端口的映射
复制
1 2 3 |
iptables -t nat -I PREROUTING 1 -p tcp -d 12.34.56.78 --dport 22 -j DNAT --to 192.168.1.101:22 iptables -t nat -I PREROUTING 2 -p tcp -d 12.34.56.78 --dport 22 -j DNAT --to 192.168.1.102:22 iptables -t nat -I PREROUTING 3 -p tcp -d 12.34.56.78 --dport 22 -j DNAT --to 192.168.1.103:22 |
根据匹配规则的顺序,结果可想而知,最后只映射到了局域网其中一台机器上。当再次 ssh 连接 Firewall 时发现连接的却是其他机器,这是因为到它的 ssh 连接被 DNAT 到了局域网内部的主机,这显然是不切合实际的。要解决这个问题,除了修改 SSH 服务的端口号,还可以在 Firewall 上映射不同端口到不同机器的 22 端口
复制
1 2 3 4 5 6 |
iptables -t nat -I PREROUTING 1 -p tcp -d 12.34.56.78 --dport 1231 -j DNAT --to 192.168.1.101:22 # 1231 端口映射为 Web Server 的 22 端口 iptables -t nat -I PREROUTING 2 -p tcp -d 12.34.56.78 --dport 1232 -j DNAT --to 192.168.1.102:22 # 1232 端口映射为 MySQL Server 的 22 端口 iptables -t nat -I PREROUTING 3 -p tcp -d 12.34.56.78 --dport 1233 -j DNAT --to 192.168.1.103:22 # 1233 端口映射为 FTP Server 的 22 端口 |
由此一来,想要 ssh 连接局域网内部多个主机只需要指定对应的端口号就可以了。
对于访问量比较高的 Web 服务器,可以通过 Squid 做缓存来提高访问效率。通常会把客户端发送的资源请求映射到 Squid 缓存服务器上,如果没有现有的缓存则回源站服务器请求。

复制
1 2 |
iptables -t nat -I PREROUTING 1 -p tcp -d 12.34.56.78 --dport 80 -j DNAT --to 192.168.1.106:3128 iptables -t nat -I PREROUTING 2 -p tcp -d 12.34.56.78 --dport 443 -j DNAT --to 192.168.1.106:3128 |
在规则越来越多的时候,要匹配的规则就会越来越多,处理速度就会随之越来越慢,所以规则的精简是十分重要的,上面的规则可以使用 multiport 简化为一条:
复制
1 |
iptables -t nat -I PREROUTING 1 -p tcp -d 12.34.56.78 -m multiport --dports 80,443 -j DNAT --to 192.168.1.106:3128 |
现在,我们已经把所有从互联网来的到防火墙的 1232 端口去的包都映射到在局域网内部的 MySQL 服务器的 22 端口上,并且在这之前为了能让内网访问外网我们还做了 SNAT。如果在外网机器上试验一下,一切正常。但是再从内网机器里试验一下,却完全不能用,这其实是路由的问题。下面我们来好好分析这个问题。

- 包从 User1 发起,他的外网是 1.2.3.4 ,向 12.34.56.78 的 1232 端口发送请求
- 包到达防火墙,然后被防火墙做 DNAT,目标变成了向 192.168.1.102 的 22 端口发送请求
- 防火墙转发这个包,而且包会经过很多其他的链检验及处理
- 包离开防火墙走并到达 192.168.102,即 MySQL 服务器
- 此时 MySQL 服务器看到的来源没有变化,还是 1.2.3.4
- MySQL 服务器试图进行数据包的响应,此时变成了 MySQL 作为源,User1 作为目标进行响应
- MySQL 服务器在路由数据库中看到他要响应的目标是 1.2.3.4 ,这属于来自外网的一个IP(scope global),因此经过默认网关,即防火墙做出响应。一般情况下,防火墙就是内网服务器的缺省网关。
- 防火墙再对返回包做 SNAT,这样 User1 看到的就是防火墙回复了之前的请求。
那么,从局域网内部发起的请求时如何处理的呢?
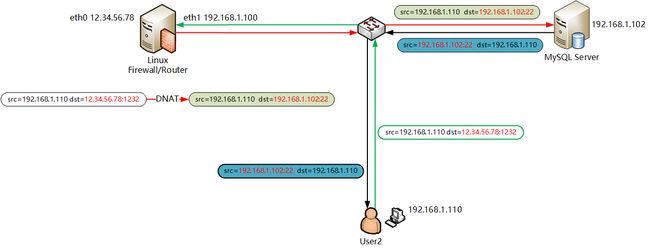
- 包从 User2 发起,他的地址为局域网的 192.168.1.110,向 12.34.56.78 的 1232 端口发送请求,上图绿色箭头
- 包到达防火墙,然后被防火墙做 DNAT,目标变成了向 192.168.1.102 的 22 端口发送请求
- 防火墙转发这个包,而且还会经过其他的处理。
- 包离开防火墙走并到达 192.168.102,即 MySQL 服务器,上图红色箭头
- 此时 MySQL 服务器看到的来源没有变化,还是 192.168.1.110
- MySQL 服务器试图进行数据包的响应,此时变成了 MySQL 作为源,User2 作为目标进行响应
- MySQL 服务器试图响应这个包,但是它在路由数据库中看到包是来自同一个网络的 192.168.1.110 ,也就是 User2,这属于直连网络(scope link)不需要防火墙转发 。因此 MySQL 服务器会把响应的包直接发送给 User2 。上图黑色箭头
- 响应的包的确到达了 User2,但它会很困惑,因为他是把请求发送给了防火墙,结果防火墙没有响应自己,却莫名其妙收到了一个其他机器的包。这样肯定没有办法建立连接,但 User2 会等待防火墙的响应,最终超过指定的时间会话被关闭(Connection timed out)。
这就是 IP 传输包的特点,只根据目的地的不同改变目的地址,但不因传输过程中要经过很多路由器而随着路由器改变其源地址,除非你单独进行源地址的改变。其实这一步的处理和对外来包的处理是一样的,只不过内网包的问题就在于此。
针对这个问题有个简单的解决办法,因为这些包都要进入防火墙,而且它们都去往需要做 DNAT 才能到达的那个地址,所以我们只要对做了 DNAT 的这些包再做 SNAT 操作即可。
复制
1 2 |
iptables -t nat -I PREROUTING 1 -p tcp -d 12.34.56.78 --dport 1232 -j DNAT --to 192.168.1.102:22 iptables -t nat -I POSTROUTING 1 -p tcp -d 192.168.1.102 --dport 22 -j SNAT --to 192.168.1.100 |
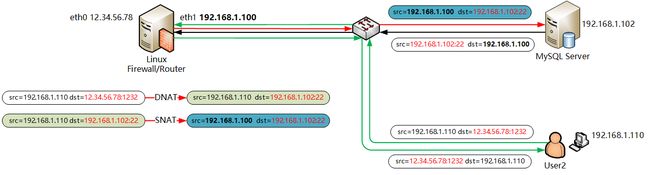
对照规则和上面的流程图你应该很容易就搞清楚是到底如何工作的了。
REDIRECT
这个 target 把要转发的包的目的地址改写为我们自己机器的 IP 和端口,这个在局域网中相当于做了透明代理,客户机根本不知道有代理的存在,并且可以正常上网。
REDIRECT 只能用在 nat 表的 PREROUTING、OUTPUT 链和被它们调用的自定义链里。它只有一个选项 --to ,其完整格式是 --to-ports
在使用 -p tcp 或 -p udp 的前提下,有三种指定端口的方式:
1、不使用这个选项,目的端口不会被改变
2、指定一个端口,用 --to-ports 8080
3、指定端口范围,用 --to-ports 8080-8090
别人都使用 80 端口提供 Web 服务,如果你想要把 8080 映射到自己的 80 而不是直接 80 对外提供 Web 服务,用 REDIRECT 就能完美地解决这个问题,本机生成的包都会被映射到 127.0.0.1
复制
1 |
iptables -t nat -I PREROUTING -p tcp --dport 8080 -j REDIRECT --to 80 |
RETURN
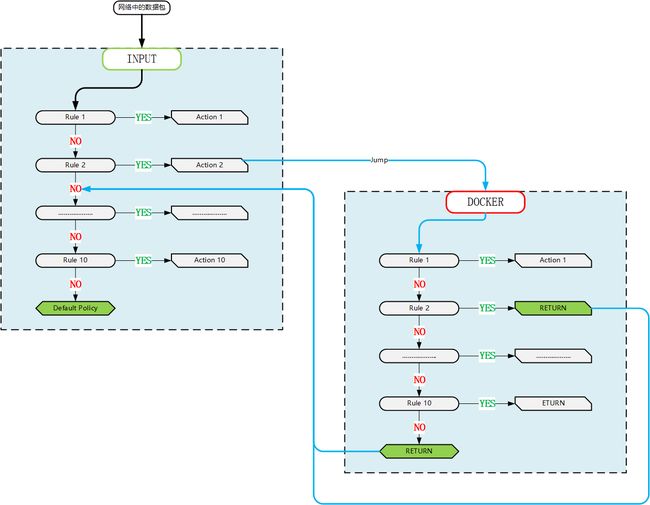
它使包返回上一层,顺序是:子链 => 父链 => 默认策略。具体地说,就是若包在子链中遇到了 RETURN,则返回父链的下一条规则继续进行匹配,若是在父链(或称主链,比如INPUT)中遇到了RETURN,就要被缺省的策略(一般是ACCEPT或DROP)操作了。
举个例子说明一下,假设一个包进入了 INPUT 链,匹配了某条规则并且 target 为 -j DOCKER ,然后数据包进入了子链 DOCKER 。在子链中又匹配了某条规则,恰巧 target 为 -j RETURN,那包就返回父链 INPUT 链并继续进行下一条规则的匹配。如果在 INPUT链里又遇到了 -j RETURN,那这个包就要被缺省的策略(一般是ACCEPT 或 DROP)处理了。
TOS
TOS 是用来设置 IP 头中的 Type of Service 字段的。这个字段长一个字节,可以控制包的路由情况。它也是 iproute2 及其子系统可以直接使用的字段之一。值得注意的是,如果你有几个独立的防火墙和路由器,而且还想在他们之间利用包的头部来传递路由信息,TOS 是唯一的办法。
-p 选项除了可以指定 tcp 或 udp 还可以使用协议号来代替协议,比如:
复制
1 2 3 |
iptables -I INPUT -p 6 -j ACCEPT # 等价于 iptables -I INPUT -p tcp -j ACCEPT |
不同的协议都有各自的协议号,具体可以参照本篇文章末尾的表格
TOS 只能在 mangle 表内使用,要想设置 TOS 的值,值的形式可以是名字或者使相应的数值(十进制或16进制的)。一般情况下,建议使用名字而不使用数值形式,因为以后这些数值可能会有所改变, 而名字一般是固定的。TOS 字段有 8 个二进制位,所以可能的值是 0-255(十进制)或 0x00-0xFF(16进制)。
复制
1 2 3 |
iptables -t mangle -I PREROUTING -p 135 -m tos ! --tos 0 -j TOS --set-tos=0 iptables -t mangle -I PREROUTING -p 47 -m tos ! --tos 0 -j TOS --set-tos=0 iptables -t mangle -A PREROUTING -p tcp --dport 22 -j TOS --set-tos 0x10 |
如前所述,最好使用预定义的值:
1、Minimize-Delay 16 (0x10),要求找一条路径使延时最小,一些标准服务如 telnet、SSH、FTP- control 就需要这个选项。
2、Maximize-Throughput 8 (0x08),要求找一条路径能使吞吐量最大,标准服务 FTP-data 能用到这个。
3、Maximize-Reliability4 (0x04),要求找一条路径能使可靠性最高,使用它的有 BOOTP 和 TFTP。
4、Minimize-Cost 2 (0x02),要求找一条路径能使费用最低,一般情况下使用这个选项的是一些视频音频流协议,如RTSP(Real Time Stream Control Protocol)。
5、Normal-Service 0 (0x00),一般服务,没有什么特殊要求。这个值也是大部分包的缺省值。
完整的列表可以通过命令 iptables -j TOS -h 得到
复制
1 2 3 4 5 6 7 8 9 10 11 |
TOS target vlibxtables.so.10 options:
--set-tos value[/mask] Set Type of Service/Priority field to value
(Zero out bits in mask and XOR value into TOS)
--set-tos symbol Set TOS field (IPv4 only) by symbol
(this zeroes the 4-bit Precedence part!)
Accepted symbolic names for value are:
(0x10) 16 Minimize-Delay
(0x08) 8 Maximize-Throughput
(0x04) 4 Maximize-Reliability
(0x02) 2 Minimize-Cost
(0x00) 0 Normal-Service
|
TTL
TTL 可以修改 IP 头中 Time To Live 字段的值。它有很大的作用,我们可以把所有外出包的 Time To Live 值都改为一样的,比如 64,这是 Linux 的默认值。
有些 ISP 不允许我们共享连接(他们可以通过 TTL 的值来区分是不是有多个机器使用同一个连接),如果我们把 TTL 都改为一样的值,他们就不能再根据 TTL 来判断了。
TTL 只能在 mangle 表内使用,它有 3 个选项
复制
1 2 3 4 |
TTL target options --ttl-set value Set TTL to |
--ttl-set 用来设置 TTL 的值。
这个值不要太大也不要太小,大约 64 就很好。值太大会影响网络,而且有点不道德,为什么这样说呢?如果有些路由器的配置不太正确,包的 TTL 又非常大,那它们就会在这些路由器之间往返很多次,值越大,占用的带宽越多。这个 target 就可以被用来限制包能走多远,一个比较恰当的距离是刚好能到达 DNS 服务器的距离。
复制
1 |
iptables -t mangle -A PREROUTING -i eth0 -j TTL --ttl-set 64 |
--ttl-dec 设定 TTL要被减掉的值
复制
1 |
iptables -t mangle -I PREROUTING -i eth1 -j TTL --ttl-dec 3 |
假设一个进来的包的 TTL 是 53,那么当它离开我们这台机子时,TTL 就变为 49 了。为什么不是 50 呢? 因为经过我们这台机器,TTL 本身就要减 1,还要被 iptables 的 TTL 再减 3,当然总共就是减去 4 了。
使用这个 target 可以限制“使用我们的服务的用户” 离我们有多远。比如用户总是使用比较近的 DNS,那我们就可以对我们的 DNS 服务器发出的包进行几个 --ttl-dec。意思也就是,我们只想让距离 DNS 服务器近一些的用户访问我们的服务,当然用 --set-ttl 控制会更方便。
--ttl-inc 设定 TTL 要被增加的值
复制
1 |
iptables -t mangle -A PREROUTING -i eth0 -j TTL --ttl-inc 4 |
假设一个进来的包的 TTL 是 53,那么当它离开我们这台机子时,TTL 应是多少呢?答案是 53+4-1=56,原因同 --ttl-dec。
在防火墙上没有操作 TTL 之前,从局域网的机器使用 traceroute 做路由追踪可以看到经过了防火墙(网关)
复制
1 2 3 4 5 6 7 8 9 10 11 |
traceroute to 182.61.200.7 (182.61.200.7), 30 hops max, 60 byte packets 1 192.168.1.101 0.237 ms 0.224 ms 0.440 ms 2 192.168.127.2 0.403 ms 0.364 ms 0.310 ms 3 * * * 4 * * * 5 * * * 6 * * * 7 * * * 8 * * * 9 * * * 10 * * * |
使用 --ttl-inc 这个选项可以使我们的防火墙更加隐蔽,而不被 traceroute 发现, 方法就是设置 --ttl-inc 1 。原因很简单,数据包每经过一个路由器,TTL 就要自动减 1,但在我们的防火墙里这个 1 又被补上了,也就是说 TTL 的值没变,那么 traceroute 就会认为我们的防火墙是不存在的。
复制
1 2 3 4 5 6 7 8 9 10 11 |
traceroute to 182.61.200.7 (182.61.200.7), 30 hops max, 60 byte packets 1 * * * 2 * * * 3 * * * 4 * * * 5 * * * 6 * * * 7 * * * 8 * * * 9 * * * 10 * * * |
实际上使用三个选项中的任意一个,只要修改了 TTL 的值就可以不被 traceroute 追踪到。
MARK
为数据包做 mark 标记,这个值只能在 mangle 表里使用。因为 mark 比较特殊,它不是包本身的一部分,而是在包穿越计算机的过程中由内核分配的和它相关联的一个字段。它可以和本地的高级路由功能联用,以使不同的包能使用不同的策略路由,队列要求等等。
复制
1 2 3 4 5 |
iptables -t mangle -I PREROUTING -p tcp -s 10.0.0.0/8 -d 31.13.95.48 --dport 80 -j MARK --set-mark 2
# 对相应符合条件的数据包进行标记
ip rule add fwmark 2 lookup 12 prio 997
# 对标记的数据包做策略路由
|
TCPMSS
在 ip foward 的时候内核会检查 mss 和 mtu 值来决定是否分片,而 mss 和 tcp 连接有关。为达到最佳的传输效能 TCP 在建立连接时会协商 MSS(最大分段长度,一般为1460字节)值,即 MTU(最大传输单元,不超过1500字节)减去 IP 数据包包头 20 字节和 TCP 数据包头 20 字节,取最小的 MSS 值为本次连接的最大 MSS 值。一般 tcp 通信中一些数据包不允许分片,所以需要在发送的时候,直接发送一个比较小的数据报文,不然就会被网络处理的时候丢弃掉。在 ADSL 拨号环境中由于 PPP 包头占用 8 字节,MTU 为 1492 字节,MSS 为 1452 字节,如果不能正确设置会导致网络不正常。
iptables 中 TCPMSS 就是用来调整 TCP 数据包中 MSS 的数值的,配合使用的有两个选项
复制
1 2 3 |
TCPMSS target mutually-exclusive options: --set-mss value explicitly set MSS option to specified value --clamp-mss-to-pmtu automatically clamp MSS value to (path_MTU - 20) |
--set-mss value 将设置手动指定的 MSS 值
复制
1 2 3 4 |
iptables -t mangle -I PREROUTING -i pppoe-wan -p tcp --tcp-flags SYN,FIN,ACK,RST SYN -j TCPMSS --set-mss 1360 # 从 pppoe-wan 进来,握手信号的包 iptables -t mangle -I POSTROUTING -o pppoe-wan -p tcp --tcp-flags SYN,FIN,ACK,RST SYN,ACK -j TCPMSS --set-mss 1360 # 从 pppoe-wan 出去,响应握手信号的包 |
--clamp-mss-to-pmtu 将根据 MTU 自动调整 MSS,它只能用在 FORWARD, OUTPUT 和 POSTROUTING 链
复制
1 |
iptables -t mangle -I POSTROUTING -o pppoe-wan -p tcp --tcp-flags SYN,FIN,ACK,RST SYN -j TCPMSS --clamp-mss-to-pmtu |
如果想匹配指定的 MSS 范围的包,并且把它的 MSS 值改为特定的,则需要依赖于显示扩展的 tcpmss 模块
复制
1 2 |
iptables -t mangle -I PREROUTING -i ppp+ -p tcp --syn -m tcpmss --mss 1400:1500 -j TCPMSS --set-mss 1360 iptables -t mangle -I POSTROUTING -o ppp+ -p tcp --tcp-flags SYN,FIN,ACK,RST -m tcpmss --mss 1400:1500 -j TCPMSS --set-mss 1360 |
LOG
这个 target 是专门用来记录包的有关信息的。这些信息可能是非法的,那就可以用来除错。LOG 会返回包的有关细节,如 IP 头的大部分和其他有趣的信息。这个功能是通过内核的日志工具完成的,一般是 rsyslogd。返回的信息可用 dmesg 阅读,或者可以直接查看 rsyslogd 的日志文件,也可以用其他的什么程序来看。
LOG 对调试规则有很大的帮助,你可以看到包去了哪里、经过了什么规则的处理,什么样的规则处理什么样的包,等等。当你在生产服务器上调试一个不敢保证 100% 正常的规则集时,用 LOG 代替 DROP 是比较好的,有详细的信息可看,错误就容易定位解决了。
LOG 有5个选项,你可以用它们指定需要的信息类型或针对不同的信息设定一 些值以便在记录中使用。
复制
1 2 3 4 5 6 |
LOG target options: --log-level level Level of logging (numeric or see syslog.conf) --log-prefix prefix Prefix log messages with this prefix. --log-tcp-sequence Log TCP sequence numbers. --log-tcp-options Log TCP options. --log-ip-options Log IP options. |
--log-level 告诉 iptables 和 rsyslog 使用哪个记录等级。记录等级的详细信息可以查看文件 /etc/rsyslog.conf,一般来说有以下几种,它们的级别依次是:debug,info,notice,warning,warn,err,error,crit,alert, emerg,panic。其中,error 和 err、warn 和 warning、panic 和 emerg 分别是同义词,也就是说作用完全一样的。这三种级别的信息量太大,所以不太建议使用。信息级别说明了被记录信息所反映的问题的严重程度。所有信息都是通过内核的功能被记录的。
先在文件 /etc/rsyslog.conf 里设置 kern.=info /var/log/iptables,然后再让所有关于 iptables 的 LOG 信息使用级别 info,就可以把所有的信息存入文件 /var/log/iptables 内。其中也可能会有其他的信息,它们是内核中使用 info 这个等级的其他部分产生的。如果你不想这样做,那么所有日志默认在 /var/log/messages 文件中记录,然后将数据包传递给下一条规则。
复制
1 2 |
iptables -I INPUT -p ICMP -j LOG --log-level info iptables -I INPUT -p ICMP -j LOG --log-level notice |
在其他机器做 ping 测试后,回来查看 tail /var/log/messages 你将看到相关的日志信息。
--log-prefix 告诉 iptables 在记录的信息之前加上指定的前缀。这样用 grep 或其他工具就容易追踪特定的问题,而且也方便从不同的规则输出。前缀最多能有 29 个英文字符,这已经是包括空白字符和其他特殊符号的总长度了。
复制
1 |
iptables -I INPUT -p ICMP -j LOG --log-level info --log-prefix "INPUT icmp packets: " |
--log-tcp-sequence 把包的 TCP 序列号和其他日志信息一起记录下来。TCP 序列号可以唯一标识一个包,在重组时也是用它来确定每个分组在包里的位置。注意,这个选项可能会带来危险, 因为这些记录被未授权的用户看到的话,可能会使他们更容易地破坏系统。其实任何 iptables 的输出信息都增加了这种危险,“言多必失”,“沉默是金”。
复制
1 |
iptables -A INPUT -p tcp -j LOG --log-tcp-sequence |
--log-tcp-options 记录 TCP 包头中的字段大小不变的选项。这对一些除错是很有价值的,通过它提供的信息,可以知道哪里可能出错,或者哪里已经出了错。
复制
1 |
iptables -A FORWARD -p tcp -j LOG --log-tcp-options |
--log-ip-options 记录IP包头中的字段大小不变的选项。这对一些除错是很有价值的,还可以用来跟踪特定地址的包。
复制
1 |
iptables -A FORWARD -p tcp -j LOG --log-ip-options |
连接跟踪机制 conntrack
在 iptables 里,包是和被跟踪连接的四种不同状态有关的。它们是 NEW,ESTABLISHED,RELATED 和 INVALID 。使用 --state 匹配操作,就能很容易地控制 “谁或什么能发起新的会话”。 所有在内核中由 Netfilter 的特定框架做的连接跟踪称作 conntrack(connection tracking)。
除了本机产生的包由 OUTPUT 链处理外,所有连接跟踪都是在 PREROUTING 链里进行处理的,也就是说 iptables 会在 PREROUTING 链里重新计算所有的状态。如果我们发送一个初始包出去,状态就会在 OUTPUT 链里被设置为 NEW,当我们收到回应的包时,状态就会在 PREROUTING 链里被设置为 ESTABLISHED。如果第一个包不是本机产生的,那就会在 PREROUTING 链里被设置为 NEW 状态。
nf_conntrack
nf_conntrack 是 Linux 内核 NAT 的模块,实时记录当前主机上 client 和 server 彼此建立的连接关系,且可以追踪某个连接和其他某个连接处于何种状态,既可以追踪 TCP 协议,也可以追踪 UDP 协议和 ICMP 协议。
默认的 timeout 是 432000秒(五天)。每个 nf_conntrack 记录约会占用 292 Bytes 的内存,所以系统所能记录的nf_conntrack 也是有限的,如果超过了这个限度,就会出现内核级错误 nf_conntrack: table full, dropping packet,其结果就是无法再有任何的网络连接了。另外,在使用 iptables 命令查看 nat 表时,由于内核模块的依赖关系,将会自动激活 nf_conntrack 模块,如果在访问量非常繁忙的服务器上执行此操作将会导致大量请求被丢弃。这时候就需要修改它能记录的最大值了。你也可以在 /proc/sys/net/nf_conntrack_max 里查看、设置,也可以编辑文件 /etc/sysctl.conf 来实现。
conntrack记录
在 /proc/net/nf_conntrack 中记录了当前被跟踪的连接
复制
1 2 |
ipv4 2 tcp 6 300 SYN_SENT src=192.168.127.1 dst=192.168.127.131 sport=3069 dport=22 \ [UNREPLIED] src=192.168.127.131 dst=192.168.127.1 sport=22 dport=3069 [ASSURED] mark=0 zone=0 use=2 |
通过这个文件就可以知道某个特定的连接处于什么状态。首先显示的是协议,这里是 tcp,接着是十进制的 6 即 tcp 的协议类型代码。之后的 300 是这条 conntrack 记录的生存时间,它会有规律地被消耗,直到收到这个连接的更多的包。那时这个值就被设为当时那个状态的缺省值。接下来的是这个连接在当前时间点的状态。上面的例子说明这个包处在 SYN_SENT 状态,这个值是 iptables 显示的,以便我们好理解,而内部用的值稍有不同。SYN_SENT 说明我们正在观察的这个连接只在一个方向发送了一 TCP SYN 包。再下面是源地址、目的地址、源端口和目的端口。其中有个特殊的词 UNREPLIED,说明这个连接还没有收到任何回应。最后是希望接收的应答包的信息,他们的地址和端口和前面是相反的。
连接跟踪记录的信息依据 IP 所包含的协议不同而不同,所有相应的值都是在头文件中定义的,即
复制
1 |
/usr/include/linux/netfilter/nf_conntrack*.h |
当一个连接在两个方向上都有传输时,conntrack 记录就删除 [UNREPLIED] 标志,然后重置。在末尾有 [ASSURED] 的记录说明两个方向已没有流量。这样的记录是确定的,在连接跟踪表满时,是不会被删除的, 没有 [ASSURED] 的记录就要被删除。连接跟踪表能容纳多少记录是被一个变量控制的,它可由内核中的 ip- sysctl 函数设置。默认值取决于你的内存大小,128MB 可以包含 8192 条目录,256MB 是 16376 条。所以,需要合理调整 nf_conntrack_max 的值。
数据包在用户空间的状态
NEW 说明这个包是我们看到的第一个包。意思就是这是 conntrack 模块看到的某个连接第一个包,它即将被匹配了。比如我们看到一个 SYN 包,是我们所留意的连接的第一个包,就要匹配它。第一个包也可能不是 SYN 包,但它仍会被认为是 NEW 状态。
ESTABLISHED 已经注意到两个方向上的数据传输,而且会继续匹配这个连接的包。只要发送请求并收到响应,连接就是 ESTABLISHED 的了。一个连接要从 NEW 变 为 ESTABLISHED,只需要接到响应包即可,不管这个包是发往防火墙的,还是要由防火墙转发的。ICMP 的错误和重定向等信息包也被看作是 ESTABLISHED,只要它们是发出请求后得到的响应。
RELATED 当一个连接和某个已处于 ESTABLISHED 状态的连接有关系时,就被认为是 RELATED 的了。换句话说,一个连接要想是 RELATED 的,首先要有一个 ESTABLISHED 的连接。这个 ESTABLISHED 连接再产生一个主连接之外的连接,这个新的连接就是 RELATED 的了,当然前提是 conntrack 模块要能理解 RELATED。ftp 就是个很好的例子,FTP-data 连接就是和 FTP-control 有 RELATED 的。注意,大部分还有一些 UDP 协议都依赖这个机制。这些协议是很复杂的,它们把连接信息放在数据包里,并且要求这些信息能被正确理解。
INVALID 说明数据包不能被识别属于哪个连接或没有任何状态。有几个原因可以产生这种情况,比如,内存溢出,收到不知属于哪个连接的 ICMP 错误信息。一般这种状态的数据包都最好 DROP 。
这些状态可以一起使用,以便匹配数据包。这可以使我们的防火墙非常强壮和有效。以前我们经常打开 1024 以上的所有端口来放行应答的数据。现在有了状态机制就不需再这样了。因为我们可以只开放那些有应答数据的端口,其他的都可以关闭,这样就安全多了。
对于本机 SSH 服务的 22 号端口,就可以通过状态机制处理了。
复制
1 2 3 4 |
iptables -I INPUT -d 192.168.2.133 -p tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT # 将目的地为本机,目的端口 22,状态为新请求或者已建立的连接放行 iptables -A OUTPUT -s 192.168.2.133 -m state --state ESTABLISED -j ACCEPT # 将本机发出去的,状态为已建立的连接放行 |
对于 FTP 连接的规则,需要事先装载 nf_conntrack_ftp 和 nf_nat_ftp 模块
复制
1 2 3 4 |
modprobe nf_conntrack_ftp modprobe nf_nat_ftp iptables -A INPUT -d 192.168.2.133 -p tcp -m state --state ESTABLISHED,RELATED -j ACCEPT iptables -I OUTPUT -s 192.168.2.133 -m state --state ESTABLISHED,RELATED -j ACCEPT |
规则的保存和恢复
iptables 提供了两个工具来处理大规则集: iptables-save 和 iptables-restore,iptables-save 用来把规则集保存到一个特殊格式的文本文件里,而 iptables-restore 是用来把这个文件重新装入内核空间的。
处理效率
使用 iptables-save 和 iptables-restore 的一个最重要的原因是,它们能提高装载、保存规则的速度。
iptables-save 运行一次就可以把整个规则集从内核里提取出来,并保存到文件里,而 iptables-restore 是每次将规则装入一个表。使用脚本更改规则的问题是,改动每个规则都要调用 iptables 命令,而每一次调用 iptables,它首先要把 Netfilter 内核空间中的整个规则集都提取出来, 然后再插入或追加,或做其他的改动,最后再把新的规则集从它的内存空间插入到内核空间中。相对于一次操作一个表而言,这会花费很多时间。
iptables-restore的不足
iptables-restore 最大的缺点就是不能替代所有的脚本来设置规则,也就是不能用来做复杂的规则集。最常见的情况就是,一个动态获取 IP 的主机,使用脚本就可以很方便地得到这个 IP,用 iptables-restore 却是无法实现的。
有一个笨办法是先装入 iptables-restore 文件,再运行一个特定的脚本把动态的规则载入。虽然可行,但是 iptables-restore 并不适合于使用动态 IP 的场合,如果你想在配置文件里使用选项来实现不同的要求,iptables-restore 也不适用。
iptables-save
iptables-save 用来把当前的规则存入一个文件里以备 iptables-restore 使用。它的使用很简单,只有两个参数:
复制
1 |
iptables-save [-c] [-t table] |
使用 -c 保存包和字节计数器的值,这可以使我们在重启防火墙后不丢失对包和字节的统计。默认情况下是不保存的计数器的数值的。
使用 -t 指定要保存的表,默认是保存所有的表。
复制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:17 2002 *filter :INPUT ACCEPT [404:19766] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [530:43376] COMMIT # Completed on Wed Apr 24 10:19:17 2002 # Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:17 2002 *mangle :PREROUTING ACCEPT [451:22060] :INPUT ACCEPT [451:22060] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [594:47151] :POSTROUTING ACCEPT [594:47151] COMMIT # Completed on Wed Apr 24 10:19:17 2002 # Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:17 2002 *nat :PREROUTING ACCEPT [0:0] :POSTROUTING ACCEPT [3:450] :OUTPUT ACCEPT [3:450] COMMIT # Completed on Wed Apr 24 10:19:17 2002 |
上面的输出格式中 # 后面的是注释,表都以 * 开始。每个表都包含链和规则,链的详细说明是 COMMIT 结束,在 iptables-restore 的时候遇到它就说明此时要把规则装入内核了。
默认情况下命令的执行结果会输出到屏幕,想要保存到文件,直接输出重定向即可:
复制
1 |
iptables-save -c > /etc/iptables.save |
iptables-restore
iptables-restore 用来载入由 iptables-save 保存的规则集。它不能直接读取文件,只能通过标准输入重定向载入规则。
复制
1 |
iptables-restore [-c] [-n] |
使用 -c 要求载入包和字节计数器,如果你用 iptables-save 保存了计数器,现在想重新装入,就必须用这个参数。它的长选项格式是 --counters。
使用 -n 告诉 iptables-restore 不要覆盖已有的表或表内的规则。默认情况是清除所有已存在的规则。它的长选项格式是 --noflush。如果使用了这个选项,你的规则就很有可能出现很多重复,所以不太建议使用。
复制
1 |
iptables-restore -c < /etc/iptables.save |
这样规则集应该正确地装入内核并正常工作了。如果有问题,就要开始排错了。
iptables.service
如果你用的是红帽 7 系列的系统,并且安装了 iptables-services,那么 /etc/sysconfig/iptables 就作为了 iptables.service 规则存放的文件, /etc/sysconfig/iptables-config 作为 iptables.service 的服务配置文件 。你可以使用 /usr/libexec/iptables/iptables.init save 保存规则。
编写规则抵御常见攻击
SYN FLOOD
方法一,限制请求速度
复制
1 2 3 4 5 6 7 |
iptables -N SYN_FLOOD # 自定义链 SYN_FLOOD iptables -A INPUT -p tcp --syn -j SYN_FLOOD # 对第一次握手 SYN 包进行 jump ,跳转到自定义链 iptables -A SYN_FLOOD -m limit --limit 1/s --limit-burst 4 -j RETURN iptables -A SYN_FLOOD -j DROP # 限定每秒最多可以连接1个,一批最高峰值为4个,即前4个速度比较快,后面的按照1/s返回主链进行回应。否则将丢弃 |
方法二,限制单个IP最大连接数,也可以用于限制访问量过大的IP
复制
1 2 |
iptables -A INPUT -i eth0 -p tcp --syn -m connlimit --connlimit-above 15 -j DROP # 限定单个 IP 连接,超过15个就丢弃 |
Dos
复制
1 2 3 4 5 6 |
iptables -I INPUT 1 -p tcp -m multiport --dport 22 -m connlimit --connlimit-above 5 -j DROP # 单个 IP 最多 5 个会话 iptables -I INPUT 2 -p tcp --dport 22 -m state --state NEW -m recent --set --name SSH # 只要是新的连接请求,就把它加入到 SSH 列表中,此处需要使用 recent 模块 iptables -I INPUT 3 -p tcp --dport 22 -m state --state NEW -m recent --update --seconds 300 --hitcount 3 --name SSH -j DROP # 5分钟(300s)内尝试次数达到3次,就拒绝为 SSH 列表中的这个 IP 提供服务。被限制5分钟后即可恢复访问。 |
反弹木马
复制
1 2 |
iptables -A OUTPUT -m state --state NEW -j DROP # 防止本机向外发送连接请求(如果本机有类似 DNS 请求的数据则据具体情况而待) |
ping攻击
复制
1 2 |
iptables -A INPUT -p icmp --icmp-type echo-request -m limit --limit 1/m -j ACCEPT # 限制连接速率 |
防火墙脚本
清除规则脚本
复制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
#!/usr/bin/env bash
:<<:
------------------------------------------------
FileName : flush-iptables-rules.sh
Author : Silence
Version : 0.0.1
Description :
------------------------------------------------
:
# Check if iptable module is loaded
PROC_iptables_NAMES=/proc/net/ip_tables_names
[ ! -e "$PROC_iptables_NAMES" ] && exit 0
# Get active tables
NF_TABLES=$(cat "$PROC_iptables_NAMES" 2>/dev/null)
# Check if firewall is configured (has tables)
[ -z "$NF_TABLES" ] && exit 1
# only usable for root
if [ $EUID != 0 ]; then
echo -n $"iptables: Only usable by root."; exit 4
fi
if [ ! -x /sbin/iptables ]; then
echo $"iptables: /sbin/iptables does not exist.";
exit 5
fi
# Flush firewall rules and delete chains.
echo -n $"iptables: Flushing firewall rules: "
# For all tables
for i in $NF_TABLES; do
# Flush firewall rules.
iptables -t $i -F;
# Delete firewall chains.
iptables -t $i -X;
# Set counter to zero.
iptables -t $i -Z;
# Set policy for configured tables.
policy=ACCEPT
echo -n "$i "
case "$i" in
raw)
for chain in PREROUTING OUTPUT;do
iptables -t $i -P ${chain} $policy
done
unset chain
;;
filter)
for chain in INPUT OUTPUT FORWARD;do
iptables -t $i -P ${chain} $policy
done
unset chain
;;
nat)
for chain in PREROUTING POSTROUTING OUTPUT;do
iptables -t $i -P ${chain} $policy
done
unset chain
;;
mangle)
for chain in PREROUTING POSTROUTING INPUT OUTPUT FORWARD;do
iptables -t $i -P ${chain} $policy
done
unset chain
;;
security)
: Ignore the security table
;;
*)
: Do nothing
;;
esac
done
echo
|
TCP/IP协议号
https://www.frozentux.net/iptables-tutorial/cn/other/protocols.txt
| 协议号 | 协议类型 | 说明 |
|---|---|---|
| 0 | HOPOPT | IPv6 逐跳选项 |
| 1 | ICMP | Internet 控制消息 |
| 2 | IGMP | Internet 组管理 |
| 3 | GGP | 网关对网关 |
| 4 | IP | IP 中的 IP(封装) |
| 5 | ST | 流 |
| 6 | TCP | 传输控制 |
| 7 | CBT | CBT |
| 8 | EGP | 外部网关协议 |
| 9 | IGP | 任何专用内部网关 (Cisco 将其用于 IGRP) |
| 10 | BBN-RCC-MON | BBN RCC 监视 |
| 11 | NVP-II | 网络语音协议 |
| 12 | PUP | PUP |
| 13 | ARGUS | ARGUS |
| 14 | EMCON | EMCON |
| 15 | XNET | 跨网调试器 |
| 16 | CHAOS | Chaos |
| 17 | UDP | 用户数据报 |
| 18 | MUX | 多路复用 |
| 19 | DCN-MEAS | DCN 测量子系统 |
| 20 | HMP | 主机监视 |
| 21 | PRM | 数据包无线测量 |
| 22 | XNS-IDP | XEROX NS IDP |
| 23 | TRUNK-1 | 第 1 主干 |
| 24 | TRUNK-2 | 第 2 主干 |
| 25 | LEAF-1 | 第 1 叶 |
| 26 | LEAF-2 | 第 2 叶 |
| 27 | RDP | 可靠数据协议 |
| 28 | IRTP | Internet 可靠事务 |
| 29 | ISO-TP4 | ISO 传输协议第 4 类 |
| 30 | NETBLT | 批量数据传输协议 |
| 31 | MFE-NSP | MFE 网络服务协议 |
| 32 | MERIT-INP | MERIT 节点间协议 |
| 33 | SEP | 顺序交换协议 |
| 34 | 3PC | 第三方连接协议 |
| 35 | IDPR | 域间策略路由协议 |
| 36 | XTP | XTP |
| 37 | DDP | 数据报传送协议 |
| 38 | IDPR-CMTP | IDPR 控制消息传输协议 |
| 39 | TP++ | TP++ 传输协议 |
| 40 | IL | IL 传输协议 |
| 41 | IPv6 | Ipv6 |
| 42 | SDRP | 源要求路由协议 |
| 43 | IPv6-Route | IPv6 的路由标头 |
| 44 | IPv6-Frag | IPv6 的片断标头 |
| 45 | IDRP | 域间路由协议 |
| 46 | RSVP | 保留协议 |
| 47 | GRE | 通用路由封装 |
| 48 | MHRP | 移动主机路由协议 |
| 49 | BNA | BNA |
| 50 | ESP | IPv6 的封装安全负载 |
| 51 | AH | IPv6 的身份验证标头 |
| 52 | I-NLSP | 集成网络层安全性 TUBA |
| 53 | SWIPE | 采用加密的 IP |
| 54 | NARP | NBMA 地址解析协议 |
| 55 | MOBILE | IP 移动性 |
| 56 | TLSP | 传输层安全协议 使用 Kryptonet 密钥管理 |
| 57 | SKIP | SKIP |
| 58 | IPv6-ICMP | 用于 IPv6 的 ICMP |
| 59 | IPv6-NoNxt | 用于 IPv6 的无下一个标头 |
| 60 | IPv6-Opts | IPv6 的目标选项 |
| 61 | 任意主机内部协议 | |
| 62 | CFTP | CFTP |
| 63 | 任意本地网络 | |
| 64 | SAT-EXPAK | SATNET 与后台 EXPAK |
| 65 | KRYPTOLAN | Kryptolan |
| 66 | RVD MIT | 远程虚拟磁盘协议 |
| 67 | IPPC | Internet Pluribus 数据包核心 |
| 68 | 任意分布式文件系统 | |
| 69 | SAT-MON | SATNET 监视 |
| 70 | VISA | VISA 协议 |
| 71 | IPCV | Internet 数据包核心工具 |
| 72 | CPNX | 计算机协议网络管理 |
| 73 | CPHB | 计算机协议检测信号 |
| 74 | WSN | 王安电脑网络 |
| 75 | PVP | 数据包视频协议 |
| 76 | BR-SAT-MON | 后台 SATNET 监视 |
| 77 | SUN-ND | SUN ND PROTOCOL-Temporary |
| 78 | WB-MON | WIDEBAND 监视 |
| 79 | WB-EXPAK | WIDEBAND EXPAK |
| 80 | ISO-IP | ISO Internet 协议 |
| 81 | VMTP | VMTP |
| 82 | SECURE-VMTP | SECURE-VMTP |
| 83 | VINES | VINES |
| 84 | TTP | TTP |
| 85 | NSFNET-IGP | NSFNET-IGP |
| 86 | DGP | 异类网关协议 |
| 87 | TCF | TCF |
| 88 | EIGRP | EIGRP |
| 89 | OSPFIGP | OSPFIGP |
| 90 | Sprite-RPC | Sprite RPC 协议 |
| 91 | LARP | 轨迹地址解析协议 |
| 92 | MTP | 多播传输协议 |
| 93 | AX.25 | AX.25 帧 |
| 94 | IPIP | IP 中的 IP 封装协议 |
| 95 | MICP | 移动互联控制协议 |
| 96 | SCC-SP | 信号通讯安全协议 |
| 97 | ETHERIP | IP 中的以太网封装 |
| 98 | ENCAP | 封装标头 |
| 99 | 任意专用加密方案 | |
| 100 | GMTP | GMTP |
| 101 | IFMP | Ipsilon 流量管理协议 |
| 102 | PNNI | IP 上的 PNNI |
| 103 | PIM | 独立于协议的多播 |
| 104 | ARIS | ARIS |
| 105 | SCPS | SCPS |
| 106 | QNX | QNX |
| 107 | A/N | 活动网络 |
| 108 | IPComp | IP 负载压缩协议 |
| 109 | SNP | Sitara 网络协议 |
| 110 | Compaq-Peer | Compaq 对等协议 |
| 111 | IPX-in-IP | IP 中的 IPX |
| 112 | VRRP | 虚拟路由器冗余协议 |
| 113 | PGM | PGM 可靠传输协议 |
| 114 | 任意 0 跳协议 | |
| 115 | L2TP | 第二层隧道协议 |
| 116 | DDX D-II | 数据交换 (DDX) |
| 117 | IATP | 交互式代理传输协议 |
| 118 | STP | 计划传输协议 |
| 119 | SRP | SpectraLink 无线协议 |
| 120 | UTI | UTI |
| 121 | SMP | 简单邮件协议 |
| 122 | SM | SM |
| 123 | PTP | 性能透明协议 |
| 124 | ISIS | over IPv4 |
| 125 | FIRE | |
| 126 | CRTP | Combat 无线传输协议 |
| 127 | CRUDP | Combat 无线用户数据报 |
| 128 | SSCOPMCE | |
| 129 | IPLT | |
| 130 | SPS | 安全数据包防护 |
| 131 | PIPE | IP 中的专用 IP 封装 |
| 132 | SCTP | 流控制传输协议 |
| 133 | FC | 光纤通道 |
| 134-254 | 未分配 | |
| 255 | 保留 |
参考链接:
https://www.linuxtopia.org/Linux_Firewall_iptables/
https://www.frozentux.net/iptables-tutorial/cn/iptables-tutorial-cn-1.1.19.html
http://cn.linux.vbird.org/linux_server/0250simple_firewall_3.php