性能测试——JMeter基础(一)
1.性能测试基本概念
1.1 RT -Response time
请求响应时间
从客户端发出请求到得到响应的整个时间
一般包括网络响应时间+server的响应时间。
用户接受准则:
例如2-5-10原则,即按照正常用户体验,如果用户能够在2秒内得到响应,会感觉速度很快,如果2-5秒得到响应,用户感觉系统的响应速度还不多,在5-10秒之内得到响应时,用户会感觉系统的响应速度慢,但是可以接受,超过10秒后还没有响应,用户就会感觉不能够接受。
不同行业不同业务可接受的响应时间是不同的,一般情况,对于在线实时交易:
- 互联网企业:500毫秒以下,例如淘宝业务10毫秒左右。
- 金融企业:1秒以下为佳,部分复杂业务3秒以下。
- 保险企业:3秒以下为佳。
- 制造业:5秒以下为佳。
- 阿里云规范
1.2 系统处理能力-吞吐量
系统处理能力是指系统在利用系统硬件平台和软件平台进行信息处理的能力。系统处理能力通过系统每秒钟能够处理的交易数量来评价,交易有两种理解:
一是业务人员角度的一笔业务过程;
二是系统角度的一次交易申请和响应过程。
前者称为业务交易过程,后者称为事务。两种交易指标都可以评价应用系统的处理能力。一般的建议与系统交易日志保持一致,以便于统计业务量或者交易量。系统处理能力指标是技术测试活动中重要指标。
要么完全成功,要么完全失败
事务:原子性,一致性,隔离性,持久性
1.1.1 简称
一般情况下,用以下几个指标来度量:
- HPS(Hits Per Second) :每秒点击次数,单位是次/秒。
- QPS(Query per Second):系统每秒处理查询次数,单位是次/秒。
- TPS(Transaction per Second):系统每秒处理事务数,单位是笔/秒。
- 下订单:
- 生成订单
- 减库存
- 通知后台订单状态
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么TPS=QPS=HPS,
一般情况下用TPS来衡量整个业务流程,用QPS来衡量接口查询次数,用HPS来表示对服务器点击请求。
每秒钟处理完的事务次数,一般TPS是对整个系统来讲的。一个应用系统1s能完成多少事务处理,一个事务在分布式处理中,可能会对应多个请求,对于衡量单个接口服务的处理能力,用QPS比较多。
吞吐量
1.3 并发用户数量
常见的错误理解:
使用系统的全部用户数量(注册用户)
使用系统的全部在线用户数量
正确理解:
并发用户数指在同一时刻内,打开系统并进行业务操作的用户数量,并发用户数对于长连接(数据库连接时长连接,web请求时短连接)系统来说最大并发用户数即是系统的并发接入能力。对于短连接系统而言最大并发用户数并不等于系统的并发接入能力,而是与系统架构、系统处理能力等各种情况相关
1.1.3 简称
Virtual User: VU 虚拟用户
1.1.4 标准
一般情况下,性能测试是将系统处理能力容量测出来,而不是测试并发用户数,除了服务器长连接可能影响并发用户数外,系统处理能力不完全受并发用户数影响,可以用最小的用户数将系统处理能力容量测试出来,也可以用更多的用户将系统处理能力容量测试出来。
系统在线值时间段用峰户数量的8%-12%,一般取值10%
1.4 错误率
1.1.5 定义及解释
错误率指系统在负载情况下,失败交易的概率。错误率=(失败交易数/交易总数)*100%。
稳定性较好的系统,其错误率应该由超时引起,即为超时率。
连接超时 设置超时时间10s
响应超时 设置超时时间10s
1.1.6 标准
不同系统对错误率的要求不同,但一般不超出千分之六,即成功率不低于99.4%
1.5 CPU
中央处理器是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。CPU Load: 系统正在干活的多少的度量,队列长度。系统平均负载。
CPU指标主要指的CPU利用率,包括用户态(user)、系统态(sys)、等待态(wait)、空闲态(idle)。CPU 利用率要低于业界警戒值范围之内,即小于或者等于75%;CPU sys%小于或者等于30%, CPU wait%小于或者等于5%。单核CPU也需遵循上述指标要求。
1.6 Memory
内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。
现代的操作系统为了最大利用内存,在内存中存放了缓存,因此内存利用率100%并不代表内存有瓶颈,衡量系统内有没有瓶颈主要靠SWAP(与虚拟内存交换)交换空间利用率,一般情况下,SWAP交换空间利用率要低于70%,太多的交换将会引起系统性能低下。
Swap解释:
当物理内存接近崩溃时,将物理内存中最近一段时间最少频率使用到的页框移出物理内存,放进该存储空间,这段存储空间我们称之为交换空间(Swap)
1.7 磁盘吞吐量
磁盘吞吐量是指在无磁盘故障的情况下单位时间内通过磁盘的数据量。
磁盘指标主要有每秒读写多少兆,磁盘繁忙率,磁盘队列数,平均服务时间,平均等待时间,空间利用率。其中磁盘繁忙率是直接反映磁盘是否有瓶颈的的重要依据,一般情况下,磁盘繁忙率要低于70%
1.8 网络吞吐量
网络吞吐量是指在无网络故障的情况下单位时间内通过的网络的数据数量。单位为Byte/s。网络吞吐量指标用于衡量系统对于网络设备或链路传输能力的需求。当网络吞吐量指标接近网络设备或链路最大传输能力时,则需要考虑升级网络设备。
网络吞吐量指标主要有每秒有多少兆流量进出,一般情况下不能超过设备或链路最大传输能力的70%
2. 并发计算方式
在做性能测试的时候,传统方式都是用并发用户数来衡量系统的性能,觉得系统能支撑的并发用户数越多,系统的性能就越好;同时对TPS不是非常理解,也根本不知道它们之间的关系,因此非常有必要进行解释。因为TPS模式(吞吐量模式)是一种更好的方式衡量服务端系统的能力。
并发用户=TPS(吞吐量)*RT(响应时间)
第一个公式:根据在线用户的峰值计算并发量
第二个公式:根据pv数量,计算并发量
PV(访问量):即Page View, 即页面浏览量或点击量,用户每次刷新即被计算一次。
假设:pv数是1000w
80~20原则:根据统计学原理,采用80~20原则计算并发用户数。
TPS=每秒钟的请求数量=1000w*80%/(18*3600*20%)=616/s
设置并发?经验值(经验因子3-5)
并发数量VU=TPS*经验因子=616*5=3080
3. 性能测试基本流程
性能测试需求:
- 最终用户体验,例如2-5-10原则,即按照正常用户体验,如果用户能够在2秒内得到响应,会感觉速度很快,如果2-5秒得到响应,用户感觉系统的响应速度还不多,在5-10秒之内得到响应时,用户会感觉系统的响应速度慢,但是可以接受,超过10秒后还没有响应,用户就会感觉不能够接受。
- 技术需求, cpu,内存,网络吞吐量,磁盘吞吐量
- 性能测试步骤:

4. Jmeter安装配置及目录结构
4.1 Windows下Jmeter下载安装
登录 http://jmeter.apache.org/download_jmeter.cgi ,根据自己平台,下载对应文件



4.2 设置环境变量

安装JDK,配置环境变量
将下载Jmeter文件解压,打开/bin/jmeter.bat

4.3 Jmeter的目录结构
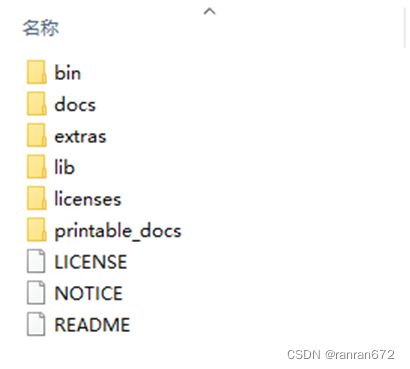
/bin 目录(常用文件介绍)
examples:目录下包含Jmeter使用实例
ApacheJMeter.jar:JMeter源码包
jmeter.bat:windows下启动文件
jmeter.sh:Linux下启动文件
jmeter.log:Jmeter运行日志文件
jmeter.properties:Jmeter配置文件
jmeter-server.bat:windows下启动负载生成器服务文件
jmeter-server:Linux下启动负载生成器文件
/docs目录——Jmeter帮助文档
/extras目录——提供了对Ant的支持文件,可也用于持续集成
/lib目录——存放Jmeter依赖的jar包,同时安装插件也放于此目录
/licenses目录——软件许可文件,不用管
/printable_docs目录——Jmeter用户手册
5. Jmeter入门
5.1 修改语言
Options-->choose Language-->Chinese
永久生效
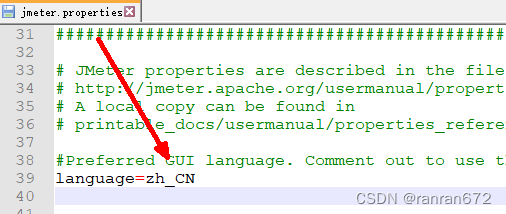
在jmeter\bin目录中打开jmeter.properties配置文件,修改language=zh_CN
5.2 创建测试计划,添加线程组
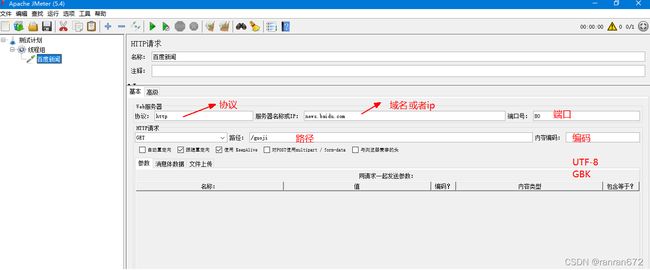
5.3 添加sampler设置http请求
5.4 添加结果树
线程组--右击--添加监听器-查看结果树
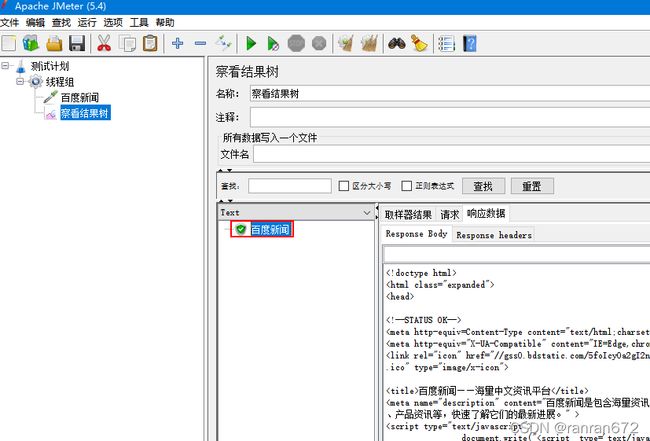
5.5 查看结果
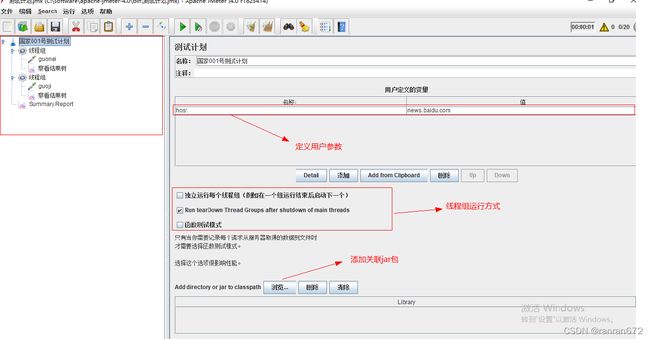
6. 测试计划
7. 线程组
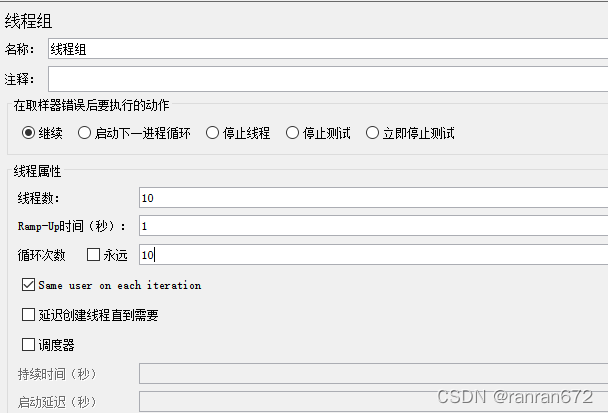
Delay Thread creation until needed
延迟创建线程,直到该线程开始采样,即之后的任何线程组延迟和加速时间为线程本身。这样可以支持更多的线程,但不会有太多是同时处于活动状态。
持续时间(秒):测试计划持续多长时间,会覆盖结束时间。
启动延迟(秒):测试计划延迟多长时间启动,会覆盖启动时间。
8. Samlper --HTTP请求

请求方式
请求路径
请求ip
请求协议
请求编码
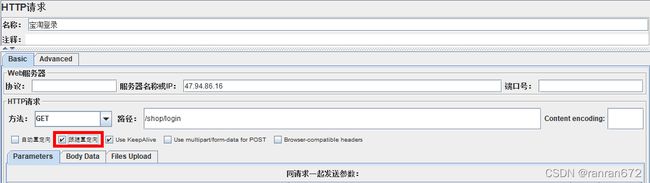
重定向之前的和之后的请求都会在结果树中显示出来
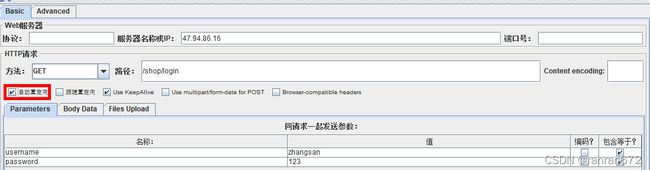
自动重定向,只会显示重定向之后的地址。

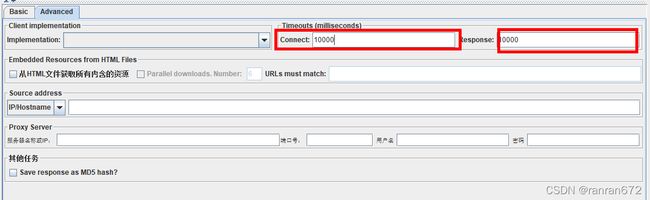
9. 结果收集
9.1 查看结果树

9.2 表格查看结果
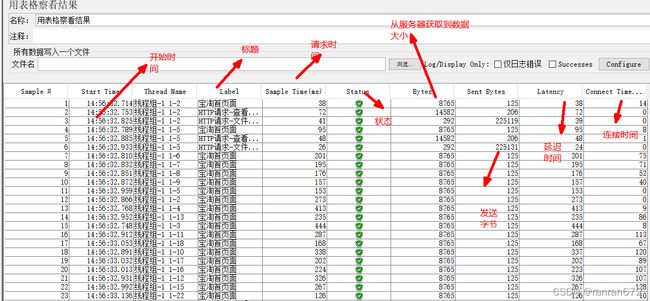
偏离表示服务器响应时间变化、离散程度测量值的大小,或者,换句话说,就是数据的分布。
9.3 聚合报告
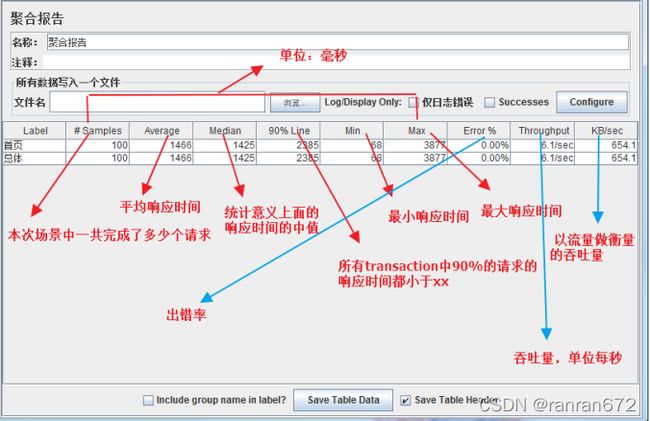
平均时间
90%时间
error率
吞吐量
KB/s
10. Jmeter参数化
10.1 使用CSV配置原件
配置元件(Config Element)维护Sampler需要的配置信息,并根据实际的需要会修改请求的内容。我们主要在参数化中用到CSV Data Set Config

10.2 使用随机函数助手
生成随机字符串

生成随机数字
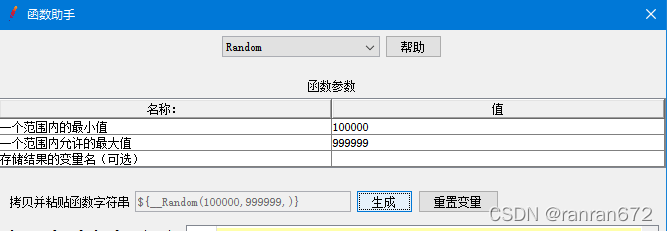
参数引用
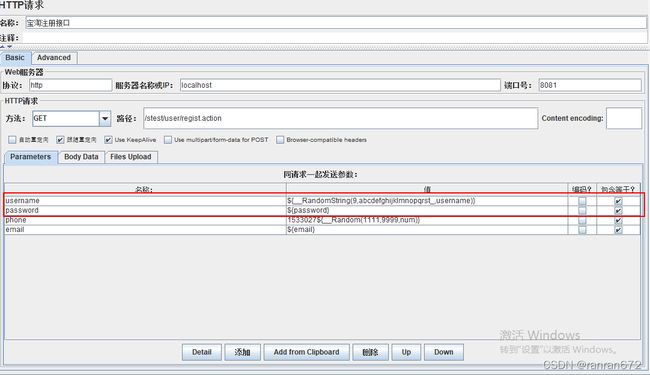
11. Jmeter断言--检查点
断言(Assertions)可以用来判断请求响应的结果是否如用户所期望的。它可以用来隔离问题域,即在确保功能正确的前提下执行压力测试。这个限制对于有效的测试是非常有用的。
设置断言,可以设置响应内容监听或者响应头断言。

12. Jmeter定时器
Jmeter定时器,可以模拟用户思考时间。可以使用固定定时器,高斯随机定时器。
也可以模拟集合点,用户数量达到某一个并发量所有线程一并执行。
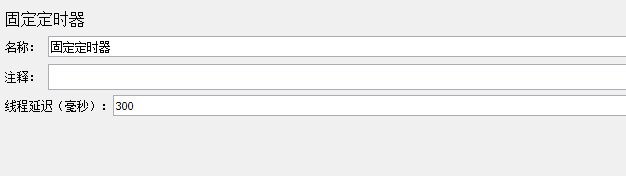
12.1 固定定时器
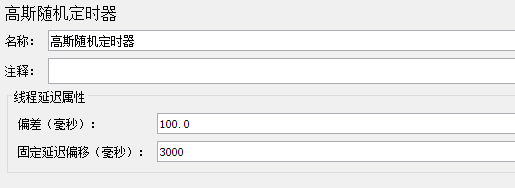
12.2 高斯随机定时器
12.3 同步定时器--集合点
13. Jmeter配置原件
13.1 HTTP Cookie管理器
配置元件---->HTTP Cookie管理器
默认保存cookie信息
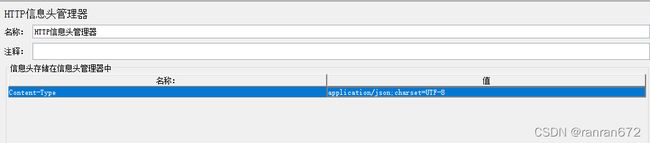
13.2 HTTP信息头管理器
配置元件----->HTTP信息头管理器,如果需要,就以键值对形式添加上。
常用头示例:Content-Type------application/json;charset=UTF-8
13.3 HTTP 请求默认值
配置元件-------HTTP请求头默认值
可以设置http请求的默认值,在单个的请求中不需要再设置其他内容
14. Jmeter逻辑控制器
14.1 简单控制器
作用:这是Jmeter里最简单的一个控制器,它可以让我们组织我们的采样器和其它的逻辑控制器(分组功能),提供一个块的结构和控制,并不具有任何的逻辑控制或运行时的功能。
14.2 循环控制器
在之前基础上再去循环,线程10,迭代1,一共十次,放到循环控制器可以多次x请求,用于在某一组中对哪些请求循环执行

14.3 事务控制器
在线程组下创建事务控制器,对于一个事务,包含多个接口,为了统计整体性能数据,可以添加事务控制器。

14.4 仅一次控制器
设置某一个接口对于一个线程,仅执行一次。

15. Jmeter关联--后置处理器
存在接口依赖问题,需要从某一个接口中提取参数,放置到某个接口中时,需要添加后置处理器,提取参数。
后置处理器---正则表达式提取器
后置处理器---json提取器
15.1 正则表达式提取
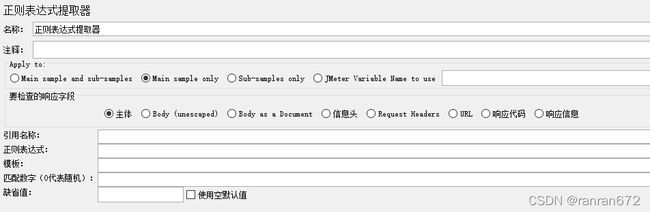
要检查的响应字段,提取时,
要提取的变量在响应实体中---->主体
要提取的变量在响应头中 ----->信息头
要提取的变量在URL中 ----->URL
- 引用名称:自己定义的变量名称,后续请求将要引用到的变量名,如填写的是:user_id,后面的引用方式是${user_id}
- 正则表达式:提取内容的正则表达式,
- () 括起来的部分就是需要提取的,对于你要提的内容需要用小括号括起来
- . 点号表示匹配任何一个字符
- + 一次或多次
- ? 在找到第一个匹配项后停止
- 模板:用$$引用起来,如果在正则表达式中有多个正则表达式(多个括号括起来),则可以是$2$,$3$等等,表示解析到的第几个值给user_id。例如:$1$表示匹配到的第一个值$1$
- 匹配数字:0代表随机取值,-1代表所有值,此时提取结果是一个数组,其余正整数代表第几个匹配的内容提取出来。如果匹配数字选择的是-1,还可以通过${user_id_1}的方式来取第1个匹配的内容,${user_id_2}来取第2个匹配的内容。
- 缺省值:正则匹配失败时,取的值
15.2 Json提取器
只适用于响应结果是json的数据

Names of created variablebugs 定义变量名称
Json Path expressions json表达式
Match No 0 代表随机 1 代表 第一个 -1代表所有
15.3 使用debug Sampler获取参数的名称
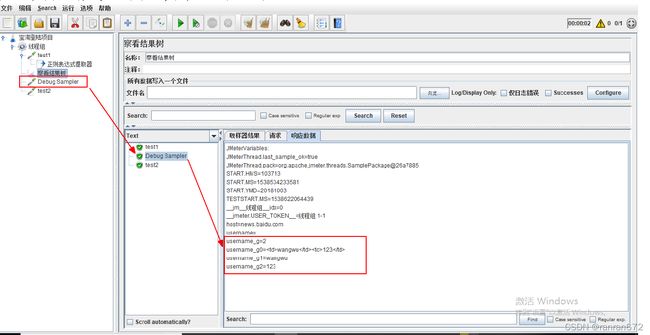
15.4 参数化获取参数内容

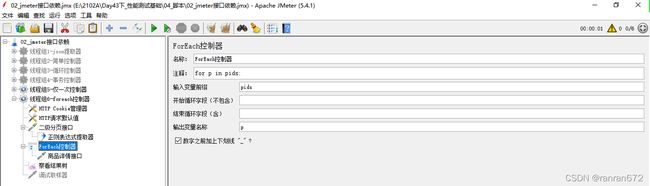
15.5 foreach控制器