TiDB-学习笔记
编写这个笔记,希望能记录下学习TiDB时候的知识点。
目录
参考文章
第一章
1.事务
1.1 SQL-92标准:
1.2 事务的隔离级别
2.在TiDB学习 SQL 语句
查看表的结构
select的基本用法
投射-无过滤查询
过滤-使用where
排序
控制查询返回的记录数
Like的转义字符
子查询的优势
使用子查询,还是JOIN?
IN和EXISTS
WITH子句
2.X 小技巧
3.TiDB的error code&SQL state汇总
第二章-认识TiDB
如何使用TiUP
认识TiDB Dashboard
认识TiDB Grafana
第三章
高级功能
placeMent Rules in SQL
第四章
1.数据库和字符集
2.字符集和排序规则
第N章
TiDB升级的内容
6.5
6.0
5.0
第四章
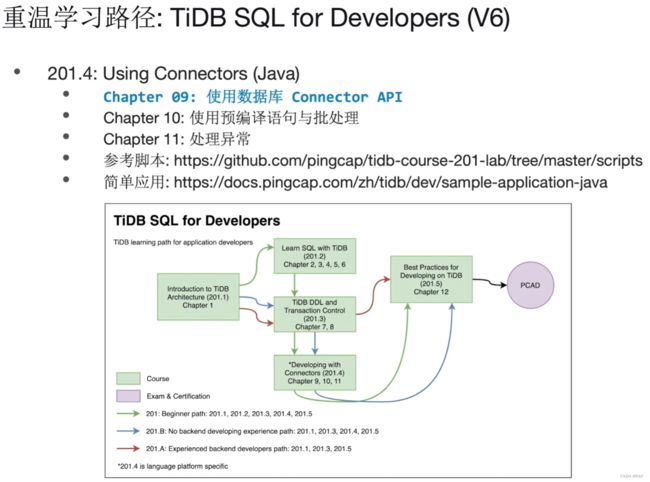
1.使用数据库ConnectorAPI(JAVA)【入门级】
Chapter 09:使用数据库Connector API
Chapter 10:使用预编译语句和批处理
Chapter 11:异常处理
2.使用数据库ConnectorAPI(JAVA)【入门级】
参考文章
| 目的 | 链接&详细 |
|---|---|
| TiDB Books | TiDB 6.x in Action | TiDB Books 【6.0版】 Introduction · TiDB in Action 【4.0版】 |
第一章
1.事务
事务的特性(ACID)
atomicity原子性、consistency一致性、isolation隔离性、durability持久性
1.1 SQL-92标准:
Dirty read脏读、Nonrepeatable read不可重复读、Phantom read幻读
| Dirty read脏读 | Nonrepeatable read不可重复读 | Phantom read幻读 |
|---|---|---|
| 即A读B的未提交/uncommit的数据。 | A读到B的已提交/commit的数据。导致A第一次和第二次读的内容不一致。 | 与不可重复读的区别在于“更新” |
| 脏读:读到其他事务还没有提交的数据。 | 不可重复读:对某数据进行读取,发现两次读取的结果不同,也就是说没有读到相同的内容。这是因为有其他事务对这个数据同时进行了修改或删除。 | 幻读:事务A根据条件查询得到N条数据,但此时事务B更改或者增加M条符合事务A查询条件的数据,这样当事务A再次进行查询的时候发现会有N+M条数据,产生了幻读。 |
1.2 事务的隔离级别
事务的隔离级别
SQL-92标准的四种级别:读未提交、读已提交、可重复读、可串行化
| 隔离级别 | 解释 |
|---|---|
| 读未提交 | 允许读到未提交的数据,这种情况下查询是不会使用锁的,可能会产生脏读、不可重复读、幻读等情况 |
| 读已提交 | 只能读到已经提交的内容,可以避免脏读,属于 RDBMS 中常见的默认隔离级别(比如说 Oracle 和 SQL Server),但如果想要避免不可重复读或者幻读,就需要我们在 SQL 查询的时候编写带加锁的 SQL 语句(我会在进阶篇里讲加锁)。 |
| 可重复读 | 保证一个事务在相同查询条件下两次查询得到的数据结果是一致的,可以避免脏读和不可重复读,但无法避免幻读。MySQL 默认的隔离级别就是可重复读。 |
| 可串行化 | 将事务进行串行化,也就是在一个队列中按照顺序执行,可串行化是最高级别的隔离等级,可以解决事务读 |
2.在TiDB学习 SQL 语句
官网的课程是【在 TiDB 上学习 SQL 语句 [TiDB v6.x](201.2)】
| 目的 | 命令 |
|---|---|
查看表的结构 |
DESC |
select的基本用法 |
clause 分句 从句
|
投射-无过滤查询 |
select col1,distinct col2 from table
|
过滤-使用where |
|
排序 |
select name,ring_systems from table order by 2;表示根据列号,即第二列ring_system升序排列。 |
控制查询返回的记录数 |
分页
limit 0,3 从第0行开始取3行。
可见分页挺好用,但效率不高。还是要全表取9行,再拿第9行。 |
Like的转义字符 |
escape '#' 就是让 # 成为了转义符号
|
子查询的优势 |
子查询的效果也可以通过join实现。
子查询一般在from、where 后面。但是ANY() 是什么鬼语法糖吗?
董菲老师说:现在的优化器一般都会将子查询优化为 join。 |
使用子查询,还是JOIN? |
董菲老师说:现在的优化器一般都会将子查询优化为 join。
|
IN和EXISTS |
in() 是先把子查询拿出来成为结果集,再去外层找。exists() 是外层逐步查一条,再使用子查询找。 参考文章:sql中的in与not in,exists与not exists的区别_Mr_John_Liang的博客-CSDN博客 |
WITH子句 |
针对有复杂逻辑的SQL的语句,WITH 可以大幅减少临时表的数量,提升SQL代码的可读性和可维护性。
Oracle有这个语法糖,DB2没有,个人印象。 |















2.X 小技巧
| 目的 | |
|---|---|
| 小技巧 |
(1) \G 的效果
(4)paper less -S |
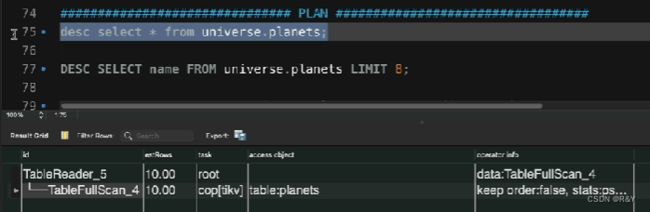
| 查看执行计划 | 口诀:从上往下,靠右先执行。 desc 不会真正执行。
|
| keyset seeker 优化分页 |
...就是索引。 就是先创建索引,然后order by 索引字段,然后自己找到分页后关键点的值,通过where 大于小于找到,写在where 中 题外话:索引不是寄生在表上,而是拷贝出来单独存储。就是用空间换时间。查索引小表再找大表。
如下就是解决分页消耗大的办法。
|





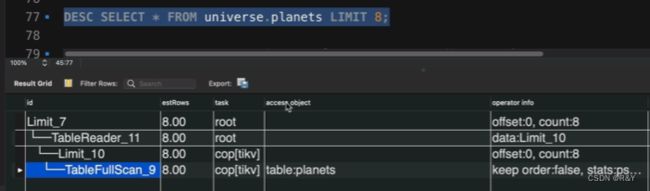



3.TiDB的error code&SQL state汇总
| Error Code 错误码 | |
| TiDB 兼容 MySQL 的错误码,在大多数情况下,返回和 MySQL 一样的错误码。 关于 MySQL 的错误码列表,详见 [MySQL 5.7 Error Message Reference]。 还有一些 TiDB 特有的错误码: 有一部分错误码属于内部错误,正常情况下 TiDB 会自行处理不会直接返回给用户,故没有在此列出。 如果您遇到了这里没有列出的错误码,请向 PingCAP 工程师或通过官方论坛寻求帮助。 |
|
| Error Number: 8001 | 请求使用的内存超过 TiDB 内存使用的阈值限制。出现这种错误,可以通过调整系统变量 tidb_mem_quota_query 来增大单个 SQL 使用的内存上限。 |
| Error Number: 8002 | 带有 SELECT FOR UPDATE 语句的事务,在遇到写入冲突时,为保证一致性无法进行重试,事务将进行回滚并返回该错误。出现这种错误,应用程序可以安全地重新执行整个事务。 |
| Error Number: 8003 | ADMIN CHECK TABLE 命令在遇到行数据跟索引不一致的时候返回该错误,在检查表中数据是否有损坏时常出现。出现该错误时,请向 PingCAP 工程师或通过官方论坛寻求帮助。 |
| Error Number: 8004 | 单个事务过大,原因及解决方法请参考这里 |
| Error Number: 8005 完整的报错信息为 ERROR 8005 (HY000) : Write Conflict, txnStartTS is stale。 事务在 TiDB 中遇到了写入冲突。可以检查 tidb_disable_txn_auto_retry 是否为 on。如是,将其设置为 off;如已经是 off,将 tidb_retry_limit 调大到不再发生该错误。 Error Number: 8018 当执行重新载入插件时,如果之前插件没有载入过,则会出现该错误。出现该错误,进行插件首次载入即可。 Error Number: 8019 重新载入的插件版本与之前的插件版本不一致,无法重新载入插件并报告该错误。可重新载入插件,确保插件的版本与之前载入的插件版本一致。 Error Number: 8020 当表被加锁时,如果对该表执行写入操作,将出现该错误。请将表解锁后,再进行尝试写入。 Error Number: 8021 当向 TiKV 读取的 key 不存在时将出现该错误,该错误用于内部使用,对外表现为读到的结果为空。 Error Number: 8022 事务提交失败,已经回滚,应用程序可以安全的重新执行整个事务。 Error Number: 8023 在事务内,写入事务缓存时,设置了空值,将返回该错误。这是一个内部使用的错误,将由内部进行处理,不会返回给应用程序。 Error Number: 8024 非法的事务。当事务执行时,发现没有获取事务的 ID (Start Timestamp),代表正在执行的事务是一个非法的事务,将返回该错误。通常情况下不会出现该问题,当发生时,请向 PingCAP 工程师或通过官方论坛寻求帮助。 Error Number: 8025 写入的单条键值对过大。TiDB 默认支持最大 6MB 的单个键值对,超过该限制可适当调整 txn-entry-size-limit 配置项以放宽限制。 Error Number: 8026 使用了没有实现的接口函数。该错误仅用于数据库内部,应用程序不会收到这个错误。 Error Number: 8027 表结构版本过期。TiDB 采用在线变更表结构的方法。当 TiDB server 表结构版本落后于整个系统的时,执行 SQL 将遇到该错误。遇到该错误,请检查该 TiDB server 与 PD leader 之间的网络。 Error Number: 8028 TiDB 没有表锁(在 MySQL 中称为元数据锁,在其他数据库中可能称为意向锁)。当事务执行时,TiDB 表结构发生了变化是无法被事务感知到的。因此,TiDB 在事务提交时,会对事务涉及表的结构进行检查。如果事务执行中表结构发生了变化,则事务将提交失败,并返回该错误。遇到该错误,应用程序可以安全地重新执行整个事务。 Error Number: 8029 当数据库内部进行数值转换发生错误时,将会出现该错误,该错误仅在内部使用,对外部应用将转换为具体类型的错误。 Error Number: 8030 将值转变为带符号正整数时发生了越界,将结果显示为负数。多在告警信息里出现。 Error Number: 8031 将负数转变为无符号数时,将负数转变为了正数。多在告警信息里出现。 Error Number: 8032 使用了非法的 year 格式。year 只允许 1 位、2 位和 4 位数。 Error Number: 8033 使用了非法的 year 值。year 的合法范围是 (1901, 2155)。 Error Number: 8037 week 函数中使用了非法的 mode 格式。mode 必须是一位数字,范围 [0, 7]。 Error Number: 8038 字段无法获取到默认值。一般作为内部错误使用,转换成其他具体错误类型后,返回给应用程序。 Error Number: 8040 尝试进行不支持的操作,比如在 View 和 Sequence 上进行 lock table。 Error Number: 8047 设置了不支持的系统变量值,通常在用户设置了数据库不支持的变量值后的告警信息里出现。 Error Number: 8048 设置了不支持的隔离级别,如果是使用第三方工具或框架等无法修改代码进行适配的情况,可以考虑通过 tidb_skip_isolation_level_check 来绕过这一检查。 set @@tidb_skip_isolation_level_check = 1; Error Number: 8050 设置了不支持的权限类型,遇到该错误请参考 TiDB 权限说明进行调整。 Error Number: 8051 TiDB 在解析客户端发送的 Exec 参数列表时遇到了未知的数据类型。如果遇到这个错误,请检查客户端是否正常,如果客户端正常请向 PingCAP 工程师或通过官方论坛寻求帮助。 Error Number: 8052 来自客户端的数据包的序列号错误。如果遇到这个错误,请检查客户端是否正常,如果客户端正常请向 PingCAP 工程师或通过官方论坛寻求帮助。 Error Number: 8055 当前快照过旧,数据可能已经被 GC。可以调大 tidb_gc_life_time 的值来避免该问题。从 TiDB v4.0.8 版本起,TiDB 会自动为长时间运行的事务保留数据,一般不会遇到该错误。 有关 GC 的介绍和配置可以参考 GC 机制简介和 GC 配置文档。 Error Number: 8059 自动随机量可用次数用尽无法进行分配。当前没有恢复这类错误的方法。建议在使用 auto random 功能时使用 bigint 以获取最大的可分配次数,并尽量避免手动给 auto random 列赋值。相关的介绍和使用建议可以参考 auto random 功能文档。 Error Number: 8060 非法的自增列偏移量。请检查 auto_increment_increment 和 auto_increment_offset 的取值是否符合要求。 Error Number: 8061 不支持的 SQL Hint。请参考 Optimizer Hints 检查和修正 SQL Hint。 Error Number: 8062 SQL Hint 中使用了非法的 token,与 Hint 的保留字冲突。请参考 Optimizer Hints 检查和修正 SQL Hint。 Error Number: 8063 SQL Hint 中限制内存使用量超过系统设置的上限,设置被忽略。请参考 Optimizer Hints 检查和修正 SQL Hint。 Error Number: 8064 解析 SQL Hint 失败。请参考 Optimizer Hints 检查和修正 SQL Hint。 Error Number: 8065 SQL Hint 中使用了非法的整数。请参考 Optimizer Hints 检查和修正 SQL Hint。 Error Number: 8066 JSON_OBJECTAGG 函数的第二个参数是非法参数。 Error Number: 8101 插件 ID 格式错误,正确的格式是 [name]-[version] 并且 name 和 version 中不能带有 '-'。 Error Number: 8102 无法读取插件定义信息。请检查插件相关的配置。 Error Number: 8103 插件名称错误,请检查插件的配置。 Error Number: 8104 插件版本不匹配,请检查插件的配置。 Error Number: 8105 插件被重复载入。 Error Number: 8106 插件定义的系统变量名称没有以插件名作为开头,请联系插件的开发者进行修复。 Error Number: 8107 载入的插件未指定版本或指定的版本过低,请检查插件的配置。 Error Number: 8108 不支持的执行计划类型。该错误为内部处理的错误,如果遇到该报错请向 PingCAP 工程师或通过官方论坛寻求帮助。 Error Number: 8109 analyze 索引时找不到指定的索引。 Error Number: 8110 不能进行笛卡尔积运算,需要将配置文件里的 cross-join 设置为 true。 Error Number: 8111 execute 语句执行时找不到对应的 prepare 语句。 Error Number: 8112 execute 语句的参数个数与 prepare 语句不符合。 Error Number: 8113 execute 语句涉及的表结构在 prepare 语句执行后发生了变化。 Error Number: 8115 不支持 prepare 多行语句。 Error Number: 8116 不支持 prepare DDL 语句。 Error Number: 8120 获取不到事务的 start tso,请检查 PD Server 状态/监控/日志以及 TiDB Server 与 PD Server 之间的网络。 Error Number: 8121 权限检查失败,请检查数据库的权限配置。 Error Number: 8122 指定了通配符,但是找不到对应的表名。 Error Number: 8123 带聚合函数的 SQL 中返回非聚合的列,违反了 only_full_group_by 模式。请修改 SQL 或者考虑关闭 only_full_group_by 模式。 Error Number: 8129 TiDB 尚不支持键长度 >= 65536 的 JSON 对象。 Error Number: 8130 完整的报错信息为 ERROR 8130 (HY000): client has multi-statement capability disabled。 从早期版本的 TiDB 升级后,可能会出现该问题。为了减少 SQL 注入攻击的影响,TiDB 目前默认不允许在同一 COM_QUERY 调用中执行多个查询。 可通过系统变量 tidb_multi_statement_mode 控制是否在同一 COM_QUERY 调用中执行多个查询。 Error Number: 8138 事务试图写入的行值有误,请参考数据索引不一致报错。 Error Number: 8139 事务试图写入的行和索引的 handle 值不一致,请参考数据索引不一致报错。 Error Number: 8140 事务试图写入的行和索引的值不一致,请参考数据索引不一致报错。 Error Number: 8141 事务写入时,对 key 的存在性断言报错,请参考数据索引不一致报错。 Error Number: 8143 非事务 DML 语句的一个 batch 报错,语句中止,请参考非事务 DML 语句 Error Number: 8200 尚不支持的 DDL 语法。请参考与 MySQL DDL 的兼容性。 Error Number: 8214 DDL 操作被 admin cancel 操作终止。 Error Number: 8215 Admin Repair 表失败,如果遇到该报错请向 PingCAP 工程师或通过官方论坛寻求帮助。 Error Number: 8216 自动随机列使用的方法不正确,请参考 auto random 功能文档进行修改。 Error Number: 8223 检测出数据与索引不一致的错误,如果遇到该报错请向 PingCAP 工程师或通过官方论坛寻求帮助。 Error Number: 8224 找不到 DDL job,请检查 restore 操作指定的 job id 是否存在。 Error Number: 8225 DDL 已经完成,无法被取消。 Error Number: 8226 DDL 几乎要完成了,无法被取消。 Error Number: 8227 创建 Sequence 时使用了不支持的选项,支持的选项的列表可以参考 Sequence 使用文档。 |
|
| Error Number: 8228 | 在 Sequence 上使用 setval 时指定了不支持的类型,该函数的示例可以在 Sequence 使用文档中找到。 |
| Error Number: 8229 事务超过存活时间,遇到该问题可以提交或者回滚当前事务,开启一个新事务。 Error Number: 8230 TiDB 目前不支持在新添加的列上使用 Sequence 作为默认值,如果尝试进行这类操作会返回该错误。 Error Number: 9001 完整的报错信息为 ERROR 9001 (HY000) : PD Server Timeout。 请求 PD 超时,请检查 PD Server 状态/监控/日志以及 TiDB Server 与 PD Server 之间的网络。 Error Number: 9002 完整的报错信息为 ERROR 9002 (HY000) : TiKV Server Timeout。 请求 TiKV 超时,请检查 TiKV Server 状态/监控/日志以及 TiDB Server 与 TiKV Server 之间的网络。 Error Number: 9003 完整的报错信息为 ERROR 9003 (HY000) : TiKV Server is Busy。 TiKV 操作繁忙,一般出现在数据库负载比较高时,请检查 TiKV Server 状态/监控/日志。 Error Number: 9004 完整的报错信息为 ERROR 9004 (HY000) : Resolve Lock Timeout。 清理锁超时,当数据库上承载的业务存在大量的事务冲突时,会遇到这种错误,请检查业务代码是否有锁争用。 Error Number: 9005 完整的报错信息为 ERROR 9005 (HY000) : Region is unavailable。 访问的 Region 不可用,某个 Raft Group 不可用,如副本数目不足,出现在 TiKV 比较繁忙或者是 TiKV 节点停机的时候,请检查 TiKV Server 状态/监控/日志。 Error Number: 9006 完整的报错信息为 ERROR 9006 (HY000) : GC life time is shorter than transaction duration。 GC Life Time 间隔时间过短,长事务本应读到的数据可能被清理了。你可以使用如下命令修改 tidb_gc_life_time 的值: SET GLOBAL tidb_gc_life_time = '30m'; 其中 30m 代表仅清理 30 分钟前的数据,这可能会额外占用一定的存储空间。 Error Number: 9007 完整的报错信息为 ERROR 9007 (HY000) : Write Conflict。 事务在 TiKV 中遇到了写入冲突。可以检查 tidb_disable_txn_auto_retry 是否为 on。如是,将其设置为 off;如已经是 off,将 tidb_retry_limit 调大到不再发生该错误。 Error Number: 9008 同时向 TiKV 发送的请求过多,超过了限制。请调大 tidb_store_limit 或将其设置为 0 来取消对请求流量的限制。 Error Number: 9010 TiKV 无法处理这条 raft log,请检查 TiKV Server 状态/监控/日志。 Error Number: 9012 请求 TiFlash 超时。请检查 TiFlash Server 状态/监控/日志以及 TiDB Server 与 TiFlash Server 之间的网络。 Error Number: 9013 TiFlash 操作繁忙。该错误一般出现在数据库负载比较高时。请检查 TiFlash Server 的状态/监控/日志。 MySQL 原生报错汇总 完整的报错信息为 ERROR 2013 (HY000): Lost connection to MySQL server during query。 排查方法如下: log 中是否有 panic 完整的报错信息为 ERROR 1105 (HY000): other error: unknown error Wire Error(InvalidEnumValue(4004)) 这类问题一般是 TiDB 和 TiKV 版本不匹配,在升级过程尽量一起升级,避免版本 mismatch。 Error Number: 1148 (42000) 完整的报错信息为 ERROR 1148 (42000): the used command is not allowed with this TiDB version。 这个问题是因为在执行 LOAD DATA LOCAL 语句的时候,MySQL 客户端不允许执行此语句(即 local_infile 选项为 0)。解决方法是在启动 MySQL 客户端时,用 --local-infile=1 选项。具体启动指令类似:mysql --local-infile=1 -u root -h 127.0.0.1 -P 4000。有些 MySQL 客户端需要设置而有些不需要设置,原因是不同版本的 MySQL 客户端对 local-infile 的默认值不同。 |
|
| Error Number: 9001 (HY000) | 完整的报错信息为 ERROR 9001 (HY000): PD server timeout start timestamp may fall behind safe point 这个报错一般是 TiDB 访问 PD 出了问题,TiDB 后台有个 worker 会不断地从 PD 查询 safepoint,如果超过 100s 查不成功就会报这个错。一般是因为 PD 磁盘操作过忙、反应过慢,或者 TiDB 和 PD 之间的网络有问题。TiDB 常见错误码请参考错误码与故障诊断。 TiDB 日志中的报错信息:EOF 当客户端或者 proxy 断开连接时,TiDB 不会立刻察觉连接已断开,而是等到开始往连接返回数据时,才发现连接已断开,此时日志会打印 EOF 错误。 |
ererr
| SQL state | |
ererro
第二章-认识TiDB
TiDB 是通过 2PC (两阶段提交协议)来保证事务的原子性( ACID 的 A );通过 raft 协议来保证多副本数据的一致性( ACID 中的 C );通过乐观锁加 MVCC 来实现可重复读的事务隔离级别( ACID 中 I )。
这意味着 TiDB 每一次事务的成本是比 MySQL 要高很多,特别是有事务冲突的时候(乐观锁的原因),所以性能是需要验证的关键点。
事务的特性(ACID)
atomicity原子性、consistency一致性、isolation隔离性、durability持久性
如何使用TiUP
| 目的 | |
|---|---|
| 检查当前集群的健康状况 | 为避免升级过程中出现未定义行为或其他故障,建议在升级前对集群当前的 region 健康状态进行检查。 对集群当前的 region 健康状态进行检查,此操作可通过 check 子命令完成。 执行结束后,最后会输出 region status 检查结果。
|
| 不停机升级 | 不停机升级 |

认识TiDB Dashboard
| 目的 | 详情 |
|---|---|
 |
|
认识TiDB Grafana
| 目的 | 详细 |
|---|---|
第三章
高级功能
| 目的 | 具体实现 |
|---|---|
placeMent Rules in SQL |
【版本】:tidb 6.0 之后 "placeMent Rules in SQL"功能的实现,三个步骤: (1)在PD中为TiKV打标签
(2)创建placement policy
(3)在建表的使用,指定placement policy
|



第四章
1.数据库和字符集
创建 Schema/Database
语法:
CREATE DATABSAE [IF NOT EXISTS] database_name [options];
CREATE SCHEMA [IF NOT EXISTS] schema_name [options];
删除数据库:DROP DATABASE [IF EXISTS] database_name;
小心这是一个无法撤消的操作tidb> show variables like 'lower_case_%'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | lower_case_file_system | 1 | | lower_case_table_names | 2 | +------------------------+-------+
数据库名建议按照业务、产品线或者其它指标进行区分,一般不要超过 20 个字符。
目前 TiDB 只支持将 lower-case-table-names 值设为 2,即按照大小写来保存表名,按照小写来比较(不区分大小写)。
CREATE DATABASE 用于创建数据库,并可以指定数据库的默认属性(如数据库默认字符集、排序规则)。CREATE SCHEMA 和 CREATE DATABASE 操作效果一样。
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name [create_specification] ...
create_specification: [DEFAULT] CHARACTER SET [=] charset_name | [DEFAULT] COLLATE [=] collation_name
当创建已存在的数据库且不指定使用 IF NOT EXISTS 时会报错。
create_specification 选项用于指定数据库具体的 CHARACTER SET 和 COLLATE。目前 TiDB 只支持部分的字符集和排序规则,它们会在后续的内容中讲解。
2.字符集和排序规则
SHOW CHARACTER SET: 列出支持的字符集SHOW COLLATION: 列出支持的排序规则- e.g:
CREATE DATABASE universe DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
数据库名建议按照业务、产品线或者其它指标进行区分,一般不要超过 20 个字符。
目前 TiDB 只支持将 lower-case-table-names 值设为 2,即按照大小写来保存表名,按照小写来比较(不区分大小写)。
CREATE DATABASE 用于创建数据库,并可以指定数据库的默认属性(如数据库默认字符集、排序规则)。CREATE SCHEMA 和 CREATE DATABASE 操作效果一样。
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification] ...
create_specification:
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
当创建已存在的数据库且不指定使用 IF NOT EXISTS 时会报错。
create_specification 选项用于指定数据库具体的 CHARACTER SET 和 COLLATE。目前 TiDB 只支持部分的字符集和排序规则,它们会在后续的内容中讲解。
字符集和排序规则
SHOW CHARACTER SET: 列出支持的字符集
SHOW COLLATION: 列出支持的排序规则
e.g:
CREATE DATABASE universe DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
tidb> SHOW COLLATION;
+--------------------+---------+------+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------+---------+------+---------+----------+---------+
| ascii_bin | ascii | 65 | Yes | Yes | 1 |
| binary | binary | 63 | Yes | Yes | 1 |
| gbk_bin | gbk | 87 | | Yes | 1 |
| gbk_chinese_ci | gbk | 28 | Yes | Yes | 1 |
| latin1_bin | latin1 | 47 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | Yes | Yes | 1 |
| utf8_general_ci | utf8 | 33 | | Yes | 1 |
| utf8_unicode_ci | utf8 | 192 | | Yes | 1 |
| utf8mb4_bin | utf8mb4 | 46 | Yes | Yes | 1 |
| utf8mb4_general_ci | utf8mb4 | 45 | | Yes | 1 |
| utf8mb4_unicode_ci | utf8mb4 | 224 | | Yes | 1 |
+--------------------+---------+------+---------+----------+---------+
11 rows in set (0.00 sec)字符集 (character set) 是符号与编码的集合。
TiDB 中的默认字符集是 utf8mb4,与 MySQL 8.0 及更高版本中的默认字符集匹配。
排序规则 (collation) 是在字符集中比较字符以及字符排序顺序的规则。
COLLATE 子句
tidb> select * from test.c1 order by name;
+------+
| name |
+------+
| A |
| B |
| C |
| a |
| b |
| c |
+------+
tidb> select * from test.c1 order by name collate utf8mb4_unicode_ci;
+------+
| name |
+------+
| A |
| a |
| B |
| b |
| C |
| c |
+------+
以下示例取自官方文档:
https://docs.pingcap.com/zh/tidb/v6.0/character-set-and-collation:
观察在排序规则为 utf8mb4_bin 和 utf8mb4_general_ci 情况下两个不同的结果:
tidb> SET NAMES utf8mb4 COLLATE utf8mb4_bin;
tidb> SELECT 'A' = 'a';
+-----------+
| 'A' = 'a' |
+-----------+
| 0 |
+-----------+
tidb> SET NAMES utf8mb4 COLLATE utf8mb4_general_ci;
tidb> SELECT 'A' = 'a';
+-----------+
| 'A' = 'a' |
+-----------+
| 1 |
+-----------+第N章
TiDB升级的内容
| 版本 | 内容 |
|---|---|
6.5 |
官方更新说明:TiDB 6.5 LTS 发版 (qq.com) 集群闪回 有时候,用户会希望整个集群快速恢复到之前的某个时间点。 在新版本中,TiDB 就提供了这个能力,它支持用简单一条命令向 GC 时间内的任意时间点进行全集群闪回,就像下面这样。 完整的大事务自动拆分支持 TiDB 完整支持了针对插入和修改的大事务拆分。在以往版本中,TiDB 用户经常要面对的一个问题就是,一些大规模的数据变更维护操作,例如过期数据删除,大范围数据修订,或者根据查询结果回写数据等操作,会遇到超过 TiDB 单条事务上限的问题,这是由于 TiDB 单一事务需要由单一 TiDB Server 作为提交方而带来的限制,这时候用户往往不得不手动想办法拆小事务以绕过该限制。但在实际使用中,上述类型的数据变更未必真的需要作为单一事务确保原子性,例如数据淘汰和数据修订,只要最终执行完成,哪怕事务被拆开多次执行也并不会影响使用。 在 TiDB 6.5 中,提供了将大事务自动拆分的能力,例如按照 t1.id 以 10000 条为大小分批数据更新,可以简单使用如下语句完成: 高性能全局单调递增 AUTO_INCREMENT 列 在过往版本中,TiDB 主要依赖 BR 进行静态的备份恢复,而在 6.2 之后的新版中,TiDB 提供了 PITR 能力,使得数据库可以更灵活地恢复到任意时间点。 TiDB PITR(Point-in-Time Recovery)是结合了 BR 和变更捕获(Change Data Capture)两种能力的灾备特性。以往 BR 的静态灾备只能将数据恢复到备份的时间点,如果要更提供针对更新和更多时间点的恢复,则相应需要提高备份频率。这不但会加重备份对在线业务的负担,也需要更多存储成本。使用 PITR 则可以摆脱这个烦恼,用户无需不断进行全量备份,而是可经由一个全量备份结合增量共同完成针对任意时间点的数据恢复。 在 6.5 版本中,TiCDC 的吞吐能力取得了数倍的提升。DM 正式发布了在数据迁移过程中的增量数据持续校验功能。 |
6.0 |
1.placeMent Rules in SQL
|
5.0 |

第四章
1.使用数据库ConnectorAPI(JAVA)【入门级】
| 目的 | 详细 |
| 课程内容 | 使用 Connector/J [TiDB v6.1](201.4) (pingcap.com) 课程:201.4 学习成果:通过使用 Java 的数据库连接器接口,连接到 TiDB 数据库,并通过使用 Java 以编程的形式执行 SQL 对 TiDB 数据库进行查询与修改数据 |
| 路线 |
|
Chapter 09:使用数据库Connector API |
|
| connector/J |
实例:
脚本 xxxxx-01-show.sh (1)脚本编译java类
(2)DemoJdbcConnection类 的内容
(3)脚本的执行结果
(4)DemoJdbcExecuteUpdate类 的内容 (5)DemoJdbcExecuteQuery类 的内容
这类有两个方法
脚本的执行结果 |
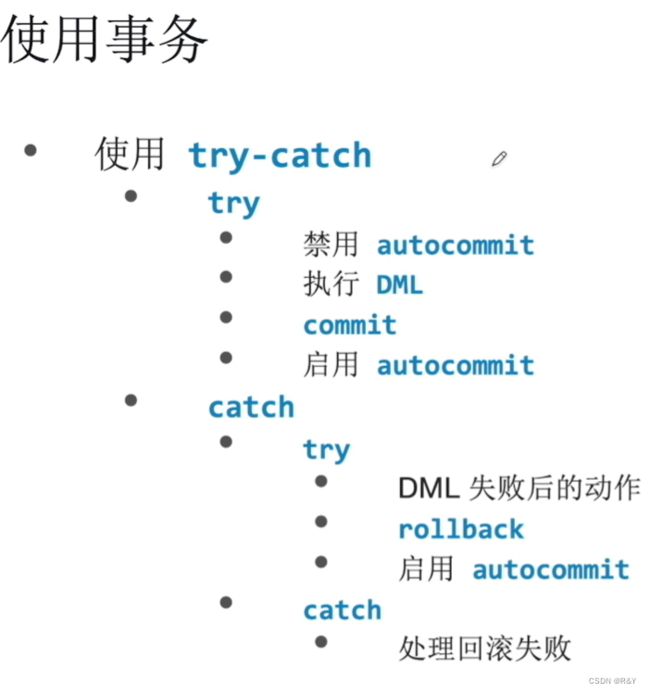
| 事务 |
|
| 连接池 |
因为连接数据库,需要创建session,而且还需要做user的身份认证......所以是高代价操作。 反复连接和关闭数据库,就为了一条SQL,其实是蛮浪费的时间和资源。 |
| 处理SQL中特殊字符 |
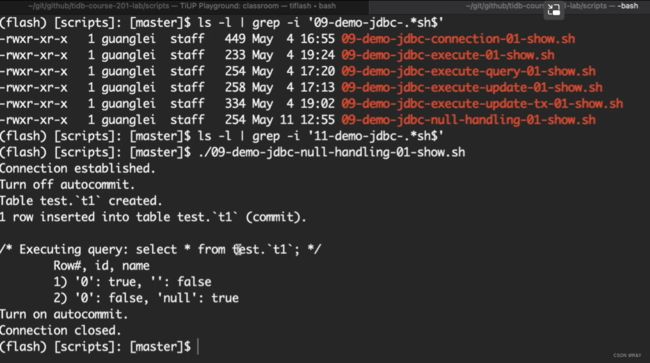
占位符(问号 ?)
wasNull() 脚本执行编译类后的结果,如下
|
Chapter 10:使用预编译语句和批处理 |
|
| 目标 |
|
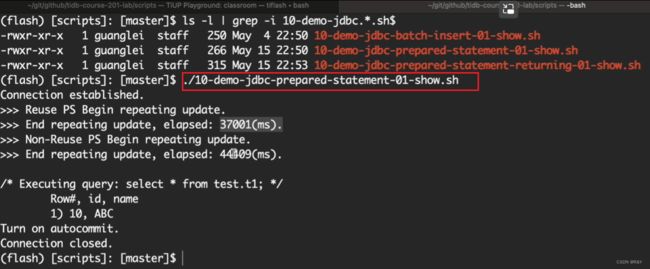
| prepared statement | 确定不是存储过程?
示例:
|
| java的 prepared statement |
上面是C语言版本,下面才是java版本
上述都是client端,所以需要在server端打开参数。 实例:
cachePreStmts=true。在客户端缓存statement,如果语句可以重用,则节省时间。
60~75行,比50~58行的性能要低。不需要执行一次update就close()。且代码前面也开启cachePreStmts=true。 脚本执行结果如下:
在java中将结果赋予常量“RETURN_GENERATED_KEYS” 实例:
脚本执行结果:
|
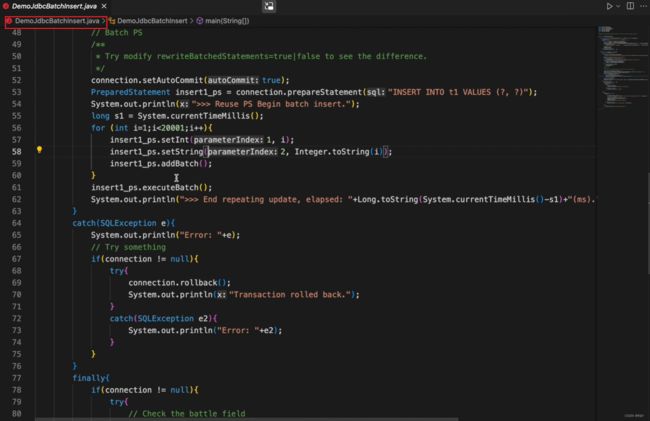
| 使用批处理 | 一次性插入多行。OLAP场景记得要打开参数rewriteBatchStatements = true。
实例:
脚本执行结果如下:
|
Chapter 11:异常处理 |
|
| 目的 |  |
| 查看SQL模式 |
默认情况下TiDB是处于严格模式 strict mode
|
| 严格模式 和其它SQL模式 |
默认情况下TiDB是处于严格模式 strict mode
|
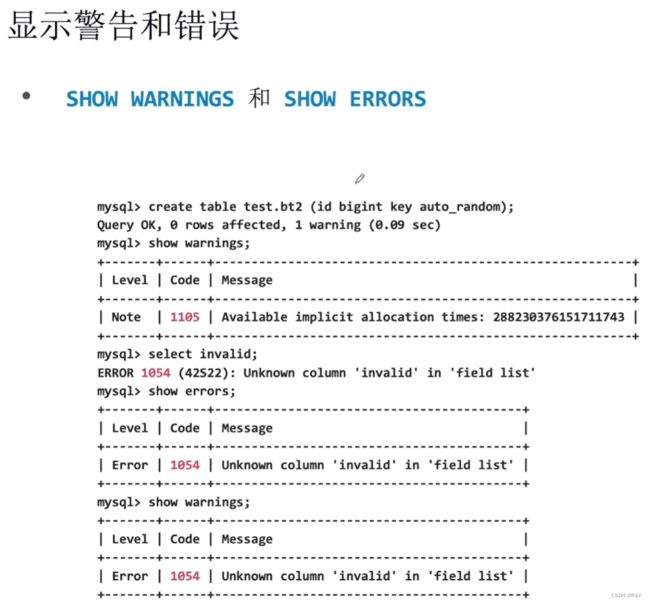
| 显示告警和错误 |
|
| 解释错误消息 |
|
| 实战 |
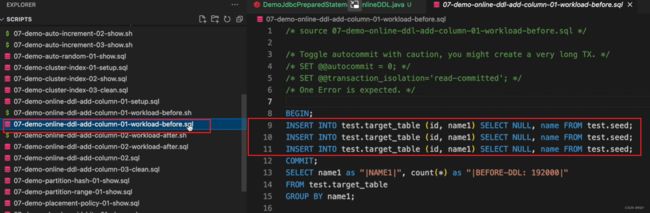
目的就是通过java类实现上面的脚本中三条insert语句。
如果出错,且TiDB的error code是 8028
|