BI-SQL丨XML

XML
SQL Server中,存在一种特殊类型的数据,就是XML数据类型。
可能看到这里,小伙伴都会产生疑惑,XML不是Web语言么?为什么在SQL Server里面也会有XML数据类型?
这个就要从SQL Server的应用开始说起了,众所周知,SQL作为计算机的通用语言之一,在各个领域都存在广泛的应用,也有着各式各样的开发规范要求,但是并不是所有的场景下,开发者都会遵循相关的规范。
这就导致,不同的开发者之间因为开发习惯不同,导致接口之间的对接,存在很大的问题。
例如:小A开发了总部的数仓,某张表一共16个字段;小B开发了分部的数仓,因为分部的业务特色,导致小B开发的某张表多余16个字段;这种情况下,小A和小B之间接口的对接,就会出现很大的差异性。
为了解决这一现状,SQL Server引入了XML类型的字段,这样不需要针对表结构进行更改,可以将差异化类型的数据,存储在XML类型的字段中。
使用实例
例子1:使用query和value查询XML数据。
创建一张表,包含XML类型的数据。
代码如下:
CREATE TABLE XML_TEST1
(
XMLID INT PRIMARY KEY,
XMLVALUE XML NOT NULL
)
GO
;
INSERT INTO XML_TEST1
(XMLID,XMLVALUE)
VALUES
(1, N'白茶 黑茶 '),
(2, N'红茶 '),
(3, N'19 '),
(4, N'18 '),
(5, N'tea ');
我们来看一下数据结果:
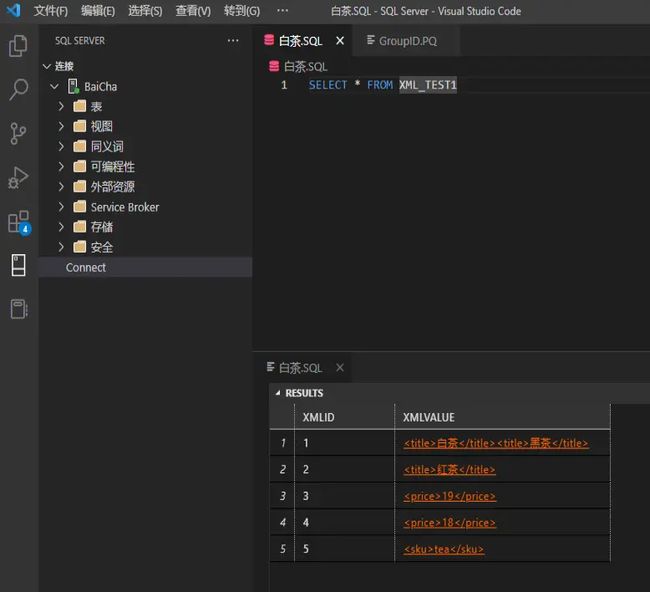
针对XML的数据类型,SQL Server是有专门的查询关键字的,分别是query查询和value查询。
query查询返回的是原始的数据格式,而value查询可以从XML中提取相应的值。
query查询示例:
SELECT XMLVALUE.query('/title') FROM XML_TEST1
结果如下:
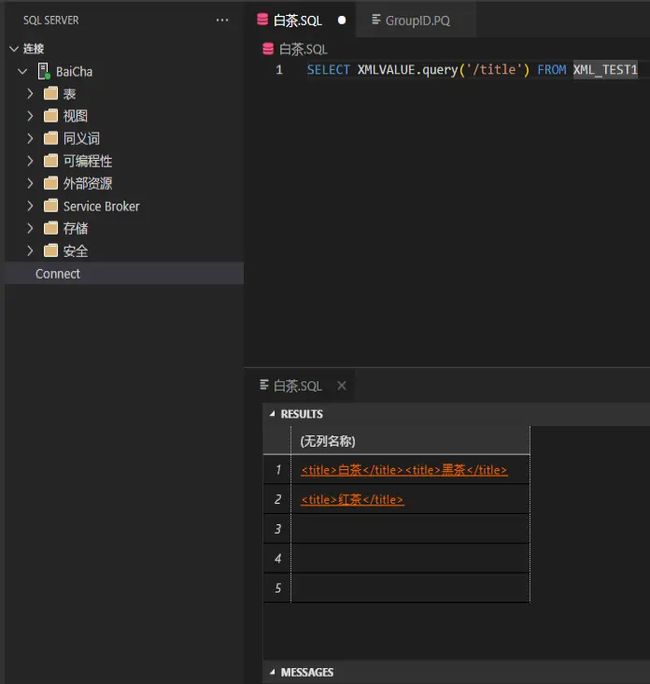
注:
query内的字段,为查询条件,即获取XML中数据标签。
value查询示例:
SELECT XML_TEST1.XMLVALUE.value('(/title)[1]', 'nvarchar(max)') AS A1,
结果如下:
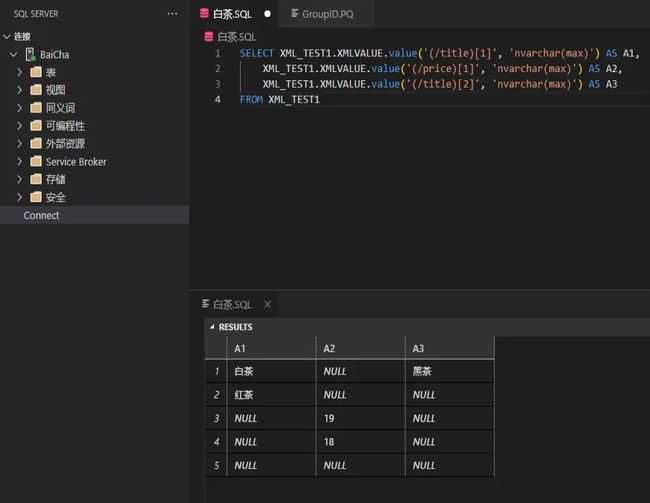
注:
1.同query查询一样,value第一参数里面的字段,也是查询条件;
2.value查询条件里面的[1],代表获取数据的位置;
例子2:使用nodes查询XML数据。
创建一张表,包含XML类型的数据。
代码如下:
CREATE TABLE XML_TEST2
(
XMLID INT PRIMARY KEY,
XMLVALUE XML NOT NULL
)
GO
;
INSERT INTO XML_TEST2
(XMLID,XMLVALUE)
VALUES
(1, N'白茶 黑茶 红茶 '),
(2, N'黄茶 '),
(3, N'蓝茶 '),
(4, N'绿茶 ');
我们来看一下数据结果:
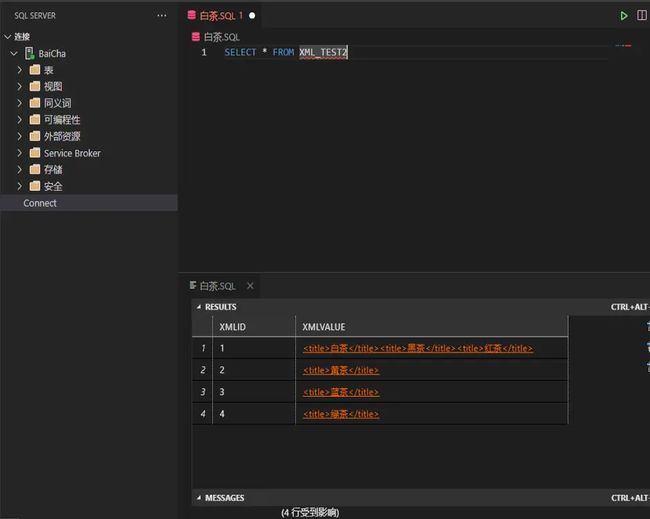
nodes通常会返回XML数据类型中,符合条件的多个节点数据组合成的多行一列的结果表。
这句话很抽象,我们点击上面的查询结果的第一行,结果如下:
可以看到,实际上在结果的第一行,是存在多行数据的,而nodes的作用通常是将一行中多行的数据,拆分出来。
说到这里,就需要提到另外两种形式的APPLY了。
CROSS APPLY与OUTER APPLY
语法:
{cross|outer} apply
APPLY运算的步骤:
1.A1:把右表表达式()应用到左表( )输入的行;
2.A2:添加外部行;
3.使用APPLY先计算左输入,然后为左输入中的每一行计算一次右输入。
CROSS APPLY和OUTER APPLY,都会执行A1,进行左右表匹配,而只有OUTER APPLY会执行A2。
简而言之:
如果左表匹配到右表,有空积时,CROSS APPLY空积会被过滤;
反之,OUTER APPLY返回的结果包含空积。
为什么这里会提到这两个APPLY,因为nodes通常会和这两个APPLY搭配使用。
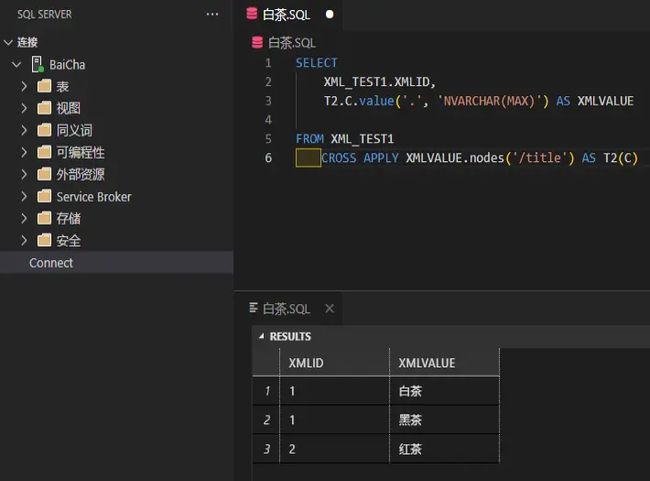
CROSS APPLY查询示例:
SELECT
XML_TEST1.XMLID,
T2.C.value('.', 'NVARCHAR(MAX)') AS XMLVALUE
FROM XML_TEST1
CROSS APPLY XMLVALUE.nodes('/title') AS T2(C)
结果如下:
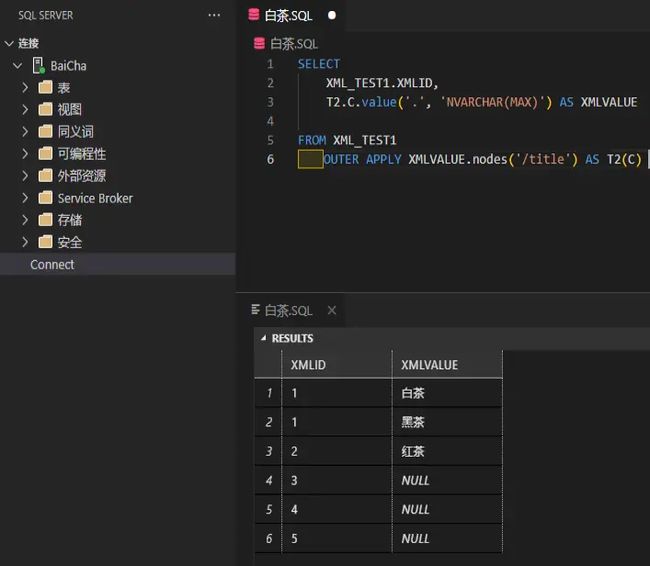
OUTER APPLY查询示例:
SELECT
XML_TEST1.XMLID,
T2.C.value('.', 'NVARCHAR(MAX)') AS XMLVALUE
FROM XML_TEST1
OUTER APPLY XMLVALUE.nodes('/title') AS T2(C)
结果如下:
从结果上,相信小伙伴也能看出差异,这里白茶给大家解释一下:
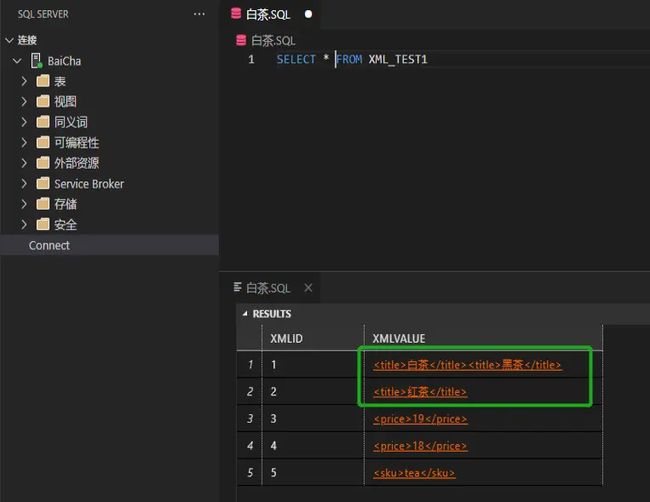
在XML_TEST1中,一共有5行数据,只有2行,有title标签,而title标签的2行数据,可以拆分出来白茶、黑茶、红茶共计3行数据。
CROSS APPLY会过滤掉空积,因为左右表有3行数据不匹配,所以返回匹配上的3行数据。
OUTER APPLY不过滤空积,原表有5行数据,拆分之后数据总数为6行,所以返回6行数据。
例子3:利用XML的语法,针对某个分隔符进行拆分。
创建一张数据表。
CREATE TABLE XML_TEST3
(
XMLID INT PRIMARY KEY,
XMLVALUE NVARCHAR(200) NOT NULL
)
GO
;
INSERT INTO XML_TEST3
(XMLID,XMLVALUE)
VALUES
(1, N'白茶,黑茶,红茶'),
(2, N'黄茶,紫茶'),
(3, N'蓝茶'),
(4, N'绿茶');
我们来看一下结果:
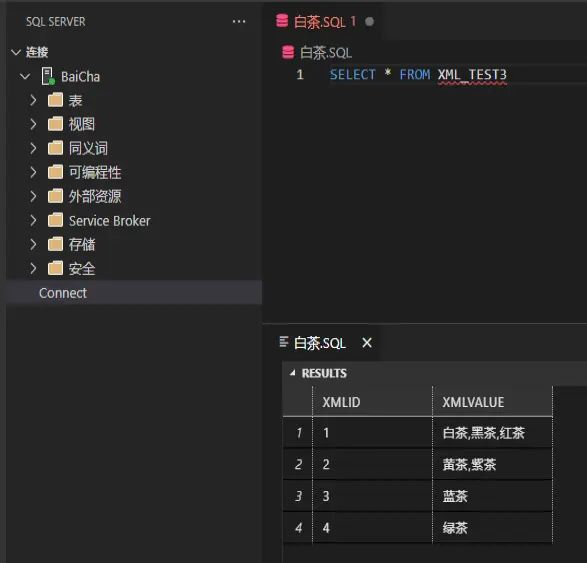
我们现在,要针对XMLVALUE字段,对分隔符“,”进行拆分。
SELECT
ReplaceTable.XMLID,
T2.C.value('.', 'NVARCHAR(MAX)') AS XMLVALUE
FROM
(SELECT XMLID,
CAST(''+REPLACE(XMLVALUE,',',' ')+' ' AS XML) AS XMLVALUE
FROM XML_TEST3) AS ReplaceTable
OUTER APPLY ReplaceTable.XMLVALUE.nodes('/TEA') AS T2(C)
结果如下:
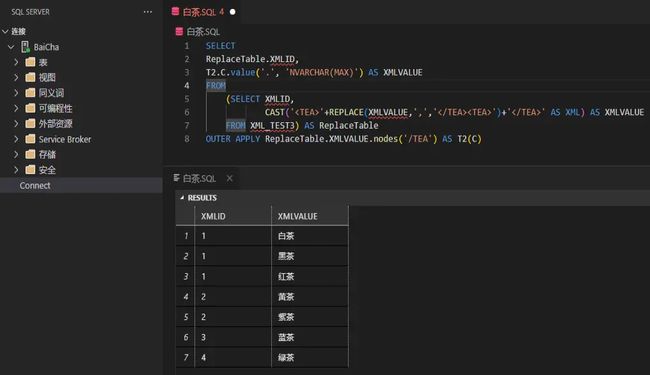
解释一下:
1.使用CAST函数,将原本的分隔符替换为一个固定的XML标签,并且将其转化为XML数据格式;
2.使用XML中的nodes函数,将转化后的XML数据类型字段进行行拆分,生成一张多行一列的结果表;
3.OUTER APPLY将转化后事实表,与nodes生成的结果表,进行左右关联;
4.使用XML中的value函数,将转化后的XML数据类型字段中的值提取出来。
![]()

这里是白茶,一个PowerBI的初学者。
