初识Redis
目录
1.Redis是什么
2.Redis VS MySQL
2.1各自优点:
2.2各自缺点:
2.3 二者的不同
2.4二者结合使用
3.Redis的特性
3.1 In-memory data structures
3.2 Programmability 可编程性
3.3 Extensibility 可扩展性
3.4 Persistence 持久化
3.5 Clustering 群集
3.6 High availability 高可用性
3.7 访问速度快(补充)
4.应用场景
4.1 Real-time data store 实时数据存储
4.2 Caching & session storage 缓存和会话存储
4.3 Streaming & messaging 消息队列
1.Redis是什么
官方解释:
The open source, in-memory data store used by millions of developers as a database, cache, streaming engine, and message broker.
译文:
被数百万开发人员用作数据库、缓存、流媒体引擎和消息代理的开源内存数据存储。
听上去很高大尚的样子,那Redis到底是什么呢?我们将修饰词去掉,再来看这句话:开源内存数据存储。这样看的话,就好理解多了,Redis其实就是在内存中存储数据。
那听到这里,大家可能又会很疑惑,我们平时定义的变量不也是在内存中存储数据吗?这样理解完全没有问题,所以Redis是在分布式系统中才会发挥到它的作用,而在单机程序中,确实是通过变量存储是更优的选择~
那为什么说在分布式系统中才会发挥它的作用呢,首先需要了解什么是分布式系统:分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。简单来说就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。
所以分布式系统会涉及到多个进程,而进程是具有隔离性的,每个进程的内存空间都是被隔开的,想要访问其他进程的变量,是有一定难度的。而Redis就是对这种的需求进行一系列封装,而通过网实现进程间通信,不仅可以实现进程间通信,还能实现跨主机的进程间通信。所以Redis就是通过以网络为基础,能够将其自己的内存变量分享给别的(主机的)进程使用。
因此,我们总结一下,Redis是一个在内存中存储数据的中间件,用于作为数据库,用于作为数据库缓存,在分布式系统中能够大展拳脚~
2.Redis VS MySQL
2.1各自优点:
- Redis:访问速度快,比MySQL要快3到4个数量级
- MySQL:存储空间大(存储在硬盘上)
2.2各自缺点:
- Redis:存储空间有限(存储在内存中)
- MySQL:访问速度慢
2.3 二者的不同
- MySQL:主要是通过“表”的方式来存储组织数据的-->关系型数据库
- Redis:主要是通过“键值对”的方式来存储组织数据的-->非关系型数据库
2.4二者结合使用
在多数的系统中,数据都会遵循一个规律:二八定律。就是说百分之八十的情况都是要经常使用那百分之二十的数据。因此我们可以将百分之二十的数据存储在内存(Redis)中,其他的数据都存储在硬盘中~这里的Redis其实也就是被当做缓存来使用了~
- 优点:二者结合使用,可以达到又快存储空间又大
- 缺点:提升了系统的复杂程度
3.Redis的特性
这里根据官网来看:
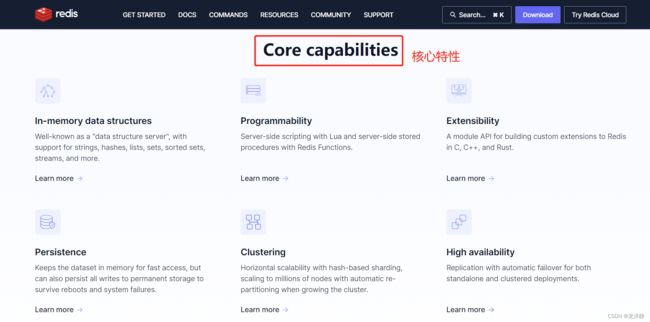
3.1 In-memory data structures
通过一系列的数据结构,在内存中存储数据。
例如支持字符串,散列、列表、集、排序集、流等。
也就是说,他的键值对中,key都是string,value可以是以上这些数据结构
3.2 Programmability 可编程性
针对Redis的操作,可以是直接通过简单的交互式命令进行操作,也可以是通过一些脚本的方式(使用Lua编写),批量执行一些操作(可以带有一些逻辑)
3.3 Extensibility 可扩展性
我们可以在Redis原有的功能之上,进行扩展。可以通过C, C++, and Rust这几种语言进行编写Redis的扩展(本质上就是一个动态链接库 Windows-dll Linux-.so)
3.4 Persistence 持久化
将数据集保存在内存中以便快速访问,但也可以将所有写入永久存储以在重新启动和系统故障时幸存下来。
也就是说,Redis会把数据存储在硬盘上(备份),以内存为主,硬盘为辅。
3.5 Clustering 群集
通俗来说就是,一个Redis能存储的数据是有限的,那我们可以引入多个主机,部署多个Redis节点,每个Redis存储数据的一部分。这个特性在我们使用Redis时,简单配置一下就可以用了,后面的文章详谈~
3.6 High availability 高可用性
Redis支持“主从”结构,从节点相当于是主节点的备份。当主节点挂了时,从节点会自动上前代替主节点~ 从而保证了可用性
3.7 访问速度快(补充)
- Redis数据存储在内存中,因此比访问硬盘要快
- Redis核心功能都是比较简单的操作内存的数据结构(例如MySQL中要插入一条数据,他可能要考虑外键约束等,所以做的事情相对多,整体就会比Redis要慢一些)
- 从网络角度,Redis使用了IO多路复用的方式(epoll)【多路复用:使用一个线程管理多个socket】
- Redis使用的是单线程模型(高版本的也引入了多线程,但只是在网络IO这里使用了多线程,核心业务逻辑依然是单线程),减少了不必要的线程之间的竞争开销
- Redis是使用C语言开发的(并不是一个特别好的理由,反例:MySQL也是C语言开发的)
4.应用场景
结合官网来看:

4.1 Real-time data store 实时数据存储
将Redis作为数据库来使用,支持构建数据用于需要低延迟和高吞吐量的情况。
在多数情况下,数据存储有点考虑的是存储空间大,少数场景是快
4.2 Caching & session storage 缓存和会话存储
为了同时追求大和快,所以我们会将Redis和MySQL结合使用,Redis充当缓存,上述2.4已经说过了~
会话缓存,我们先来看如果不进行会话缓存,那么在分布式系统中会出现什么状况呢?

不使用Redis进行会话缓存之前,所有会话都是存储在应用服务器上的,那么在分布式系统中,又是引入了多台应用服务器,当用户第一次登陆时,分配到第一台,就只有第一台有该用户的信息,第二次进行访问时,由于负载均衡器的处理(尽可能让请求均匀分配到各个服务器),就会分配给第二台,第二台有没有这个用户session,因此会让用户重新登陆,那一次两次还好,那三次四次呢?会让用户的体验感很差!!!
怎么解决这个?有两个办法:
方法一:想办法让负载均衡器把同一个用户的需求始终分配到同一个机器上,例如使用userID进行取模,0为第一台机器,1为第二台,2为第三台等~
方法二:使用Redis,将会话数据拿出来,放在一个单独的机器上~
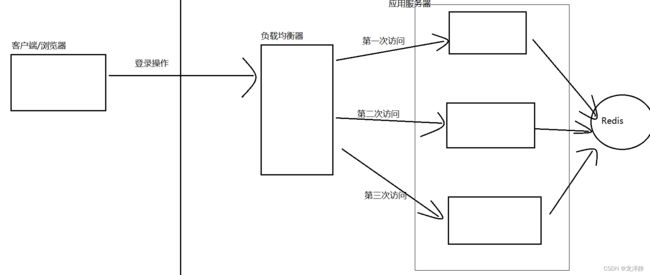
每次应用服务器存储session信息,和获取session信息,都从Redis中获取,就可以解决上述问题了,注意这里的Redis也可以是Redis集群~
所以方法二是更优解的,即使应用程序重启了,会话是不丢失的
那么为什么在4.2中要将这两个场景写在一起的,因为在这里,Redis中的数据是可以丢失的~
4.3 Streaming & messaging 消息队列
对于分布式系统。服务器和服务器之间,有时也需要用到生产者消费者模型(解耦合、削峰填谷)。
实际工作中,使用Redis的消息队列的功能相对来说还是比较少的,消息队列更多的还是使用RabbitMQ、Kafka等~
好啦,本期先到这里咯~下期见!!!