java面试题/认证答辩 ---数据库相关
- 对数据库掌握层次的定义
熟悉:掌握基本sql语法,能对接数据库进行简单功能开发
掌握:能独立设计应用的数据库表,掌握基本sql优化技巧
精通:掌握事务隔离级别,锁,分库分表设计等概念和技术,能进行大数据量应用的数据库设计
综合应用:综合使用数据库技术,独立完成大数据量下大型产品或项目的数据库设计和调优
参考: https://segmentfault.com/a/1190000022635983
https://blog.csdn.net/zanpengfei/article/details/123505051
https://juejin.cn/post/6958426991980724261
数据库底层基础:
mysql底层存储结构是B+树,
b+树的非叶子节点不会存储数据,至存储索引值,数据都存储在叶子节点上
B+的特点
1 B+树的叶子节点连起来是一条双向链表,目的是为了解决范围查找。
2 非叶子节点不存数据,只存索引,空间利用更高效。
3 数据的个数和节点一样多,换句话说,非叶子节点存的是其子树的最大或最小值。
数据库优化:
https://segmentfault.com/a/1190000013672421
https://segmentfault.com/a/1190000013746118
https://segmentfault.com/a/1190000013781544
影响MySql的性能
1 服务器硬件( 磁盘io/CPU频率)
2 服务器系统(系统参数优化)
3 存储引擎(Mysql5.5及之后默认存储引擎是InnoDB)
MyIsAm: 不支持事务,表级锁
InnoDB: 支持事务(ACID),行级锁
4 数据库参数配置
5 数据库表结构设计和sql语句
数据库的优化顺序
① 数据库结构设计和SQL语句
② 数据库存储引擎的选择和参数配置
③ 系统选择及优化
④ 硬件升级
- 数据库结构优化方法
① 范式化 参考: https://blog.csdn.net/xy3233/article/details/86314329
第一范式: 原子性 (列不能分割,一个列中不能有多个属性)
第二范式: 消除部分依赖 (非主属性依赖主键全部,不是依赖主键的一部分)
第三范式: 消除依赖传递 (非主属性是直接依赖于主键,还是依赖非主键列)
数据库 只需满足第三范式(3NF)就行了
范式化的优点: 减少冗余数据, 数据表体积小,更新可以更快
范式化的缺点: 查询需要多表关联(会导致性能降低)
反范式化的优点: 减少表关联,可以优化索引
反范式化的缺点: 数据冗余,维护不方便
- 为字段选取合适的类型
数据字段类型:
数值型: 整数 小数
字符串类型:
时间类型:
字符串类型:
CHAR 类型用于定长字符串,并且必须在圆括号内用一个大小修饰符来定义。这个大小修饰符的范围从 0-255。比指定长度大的值将被截短,而比指定长度小的值将会用空格作填补。
VARCHAR的长度是可变的,
如果长度确定就用 char 因为CHAR类型由于本身定长的特性使其性能要高于 VARCHAR
合理的选择数据类型:
① 选择合理范围内最小的
② 选择相对简单的数据类型(数字类型比字符串简单)
③ 列属性尽量为NOT NULL(因为MYSQL对NULL字段索引优化不佳,增加更多的计算难度,同时在保存与处理NULL类形时,也会做更多的工作, 对于可能没值的数据,可以使用0 或者空字符串作为默认值)
- sql的索引优化
索引两种主要的数据结构 B-tree 和hash
B-tree索引优点: 加快查询速度,更适合范围查找
hash索引的优点: 适合精确查找
Mysql中常见的索引:
普通索引:最基本的索引,没有任何限制
唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
主键索引:它 是一种特殊的唯一索引,不允许有空值。
全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
索引的优化策略:
① 索引列上不能使用表达式和函数
② 使用选择性高的列作为索引(性别,区别性太低 就不适合做索引)
③ 宽度小的列优先
④ 尽量使用索引 is null, is not null, 不等于(!=或者<>), or 无法使用索引
⑤ like百分号要写在右边
⑥ 避免使用select *
慢sql分析 参考: https://blog.csdn.net/qq_40884473/article/details/89455740
查看慢查询日志状态 show variables like '%slow_query_log%';
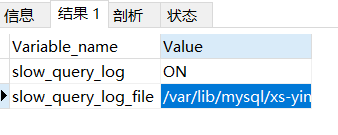
开启慢查询日志 set global slow_query_log=1(当前数据库有效 重启消失)
永久配置 在my.cnf中配置
slow_query_log = 1
slow_query_log_file = /tmp/mysql_slow.log
慢查询日志位置 show variables like ‘%slow_query_log_file%’;
慢查询时间参数 show variables like ‘long_query_time%’;(默认查询时间超过10秒的会被记录)
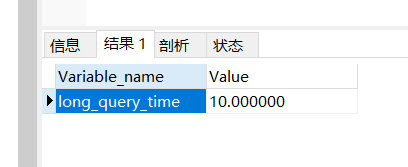 使用 set global long_query_time=4 设置新的查询时间(需要重新连接才能看到, 或使用 show global variables like ‘long_query_time’
使用 set global long_query_time=4 设置新的查询时间(需要重新连接才能看到, 或使用 show global variables like ‘long_query_time’
查看记录存储方式 show variables like ‘%log_output%’;(默认FILE)
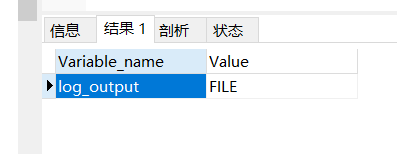
set global log_output=‘TABLE’; (设置 日志信息写入到mysql.slow_log表中,比较耗资源)
查看(最好断开重新连接再测试)
制造一个慢查询: select sleep(5)
查看慢查询 select * from mysql.slow_log
查询时间 和 sql

可以使用 explain 进行分析
参考: https://cloud.tencent.com/developer/article/1093229
需要重点关注type、rows、filtered、extra。
① id列 select 的序列号,有几个 select 就有几个id
② select_type列: 查询类型
simple:简单查询
primary:复杂查询中最外层的 select
subquery:包含在 select 中的子查询(不在 from 子句中)
derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表
union:在 union 中的第二个和随后的 select
union result:从 union 临时表检索结果的 selec
③ table 查询哪个表
④ type列(索引类型)
最优到最差分别为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
⑤ possible_keys列 显示查询可能使用哪些索引来查找
⑥ key列 这一列显示mysql实际采用哪个索引来优化对该表的访问。如果没有使用索引,则该列是 NULL。
⑦ key_len 显示了mysql在索引里使用的字节数(如果索引市int 就是4 如果索引是bigint key_len就是8)
⑧ ref 列显示了在key列记录的索引中,表查找值所用到的列或常量
⑨ rows列 mysql估计要读取并检测的行数,注意这个不是结果集里的行数
⑩ filtered 符合条件的百分比
⑪ Extra列 额外信息
distinct: 一旦mysql找到了与行相联合匹配的行,就不再搜索了
Using index:这发生在对表的请求列都是同一索引的部分的时候,返回的列数据只使用了索引中的信息,而没有再去访问表中的行记录。
Using where:mysql服务器将在存储引擎检索行后再进行过滤。就是先读取整行数据,再按 where 条件进行检查,符合就留下,不符合就丢弃。
Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
Using filesort:mysql 会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。
数据库事务隔离级别 锁:
参考: https://www.cnblogs.com/kexinxin/p/11620345.html
事务ACID属性:
1、原子性(atomicity):全部成功,全部回滚失败。银行存取款。
2、一致性(consistent):银行转账的总金额不变。
3、隔离性(isolation)
4、持久性(DURABILITY):从数据库的角度的持久性,磁盘损坏就不行了
隔离性等级:
未提交读(READ UNCOMMITED) 脏读,两个事务之间互相可见;-- 存在脏读、不可重复读、幻读的问题
已提交读(READ COMMITED)符合隔离性的基本概念,一个事务进行时,其它已提交的事物对于该事务是可见的,即可以获取其它事务提交的数据(不可重复读)。-- 解决脏读的问题,存在不可重复读、幻读的问题。
可重复读(REPEATABLE READ) InnoDB的默认隔离等级。事务进行时,其它所有事务对其不可见,即多次执行读,得到的结果是一样的! -- mysql 默认级别,解决脏读、不可重复读的问题,存在幻读的问题。使用 MVCC(多版本并发控制,提高并发,不加锁)机制 实现可重复读。But,MySQL在可重复读级别已经解决幻读,插不进数据,有间隙锁。
可串行化(SERIALIZABLE) 在读取的每一行数据上都加锁,会造成大量的锁超时和锁征用,严格数据一致性且没有并发是可使用。 -- 解决脏读、不可重复读、幻读,可保证事务安全,但完全串行执行,性能最低。
锁分类 大概
按锁的粒度划分:表级锁、行级锁
按锁级别划分:共享锁、排它锁
按使用方式划分:乐观锁、悲观锁