Hugging Face实战(NLP实战/Transformer实战/预训练模型/分词器/模型微调/模型自动选择/PyTorch版本/代码逐行解析)下篇之模型训练
模型训练的流程代码是不是特别特别多啊?有的童鞋看过Bert那个源码写的特别特别详细,参数贼多,运行一个模型百八十个参数的。
Transformer对NLP的理解是一个大道至简的感觉,Hugging Face的老板接受采访的时候讲过他想给算法人提供一个非常简单实用的模板,因为NLP本身做的就是一个非常简单的事情。但是由于一些开源项目的门槛过高,所以大家用起来特别麻烦。Hugging Face的老板只用了30个做兼职的人就把NLP的江山打下来了,微软、谷歌、openAI、Facebook真的直接哭死。
有任何问题欢迎在下面留言
本篇文章的代码运行界面演示结果均在notebook中进行
本篇文章配套的代码资源已经上传
本文章是下篇的内容,主要解析模型训练,上篇内容解析如何进行模型调用:
Hugging Face实战(NLP实战/Transformer实战/预训练模型/分词器/模型微调/模型自动选择/PyTorch版本/代码逐行解析)上篇之模型调用_会害羞的杨卓越的博客-CSDN博客
目录
1、数据集与模型
1.1背景
1.2 数据集构建
1.3 HuggingFace官网的数据集
2、处理数据
2.1 单条数据处理
2.2 对所有数据进行处理
2.3数据封装
3 模型训练
3.1模型参数
3.2模型导入
3.3模型训练
4 模型测试
4.1模型测试
4.2训练评估函数
1、数据集与模型
- 这些数据集都可以直接用:点我直达数据集链接
- 咱们今天玩这个(GLUE):点我直达GLUE数据集
1.1背景
Hugging Face不仅仅是Transformer,你点开可以看到非常重要的四个大模块。
首先是提供了Transformers本身的工具包源码

首先是tokenizers,一个高效的分词器,对文本数据进行预处理,你别管是用什么语言做的,用就完了。实际上最核心的东西就是tokenizers,对于我们来说是一个开箱即用的过程,但是开发出这个工具确实需要特别大的成本和代价。

然后是数据集,你别一个模型一个数据集了,全部用统一格式的数据集吧。实际上人家在下一盘大棋,不仅给你提供API,还要提供数据集,统一了数据格式,以后真竞争不过它。与此同时想想,国内还在天天“遥遥领先!遥遥领先!遥遥领先!”

如果你用非常高端的GPU来训练,提供一个加速包让你更够有更高的效率去训练,帮你发挥出高端设备的能力。

1.2 数据集构建
首先是dataset这个安装包,真的很简单,直接pip install就行了:
pip install datasetsglue数据集是NLP中Hello World级别的数据集,但是它却包含来各大经典任务,执行下面的代码后,就会进行下载:
import warnings
warnings.filterwarnings("ignore")
from datasets import load_dataset#https://github.com/huggingface/datasets
raw_datasets = load_dataset("glue", "mrpc")
raw_datasets执行后的提示:
Using the latest cached version of the module from C:\Users\Administrator\.cache\huggingface\modules\datasets_modules\datasets\glue\dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad (last modified on Sun May 1 15:59:37 2022) since it couldn't be found locally at glue., or remotely on the Hugging Face Hub.
Reusing dataset glue (C:\Users\Administrator\.cache\huggingface\datasets\glue\mrpc\1.0.0\dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad)所以梯子,该整还是得整,代码执行后的输出:
A Jupyter Widget
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})解释一下上面的数据,看看公开数据集到底长啥样子
train:( train: Dataset、validation: Dataset、test: Dataset)这三个分别表示训练、验证、测试集,很简单不用讲
sentence1 & sentence2:分别是两个句子
label:表示的是标签,标签意义是这两个句子之间有没有相关性
idx:这个样本的索引,然后后面的
num_rows:表示在训练集中一共有3668行数据,每行数据都包含了两个句子和一个标签,一个索引
选择训练集的第100号样本,打印出来看看,代码:
raw_train_dataset = raw_datasets["train"]
raw_train_dataset[100]打印:
{'idx': 114,
'label': 0,
'sentence1': 'The Nasdaq composite index inched up 1.28 , or 0.1 percent , to 1,766.60 , following a weekly win of 3.7 percent .',
'sentence2': 'The technology-laced Nasdaq Composite Index .IXIC was off 24.44 points , or 1.39 percent , at 1,739.87 .'}idx索引不用去管,label为0,是二分类的,然后是两个句子,这就是一个实际的数据集,公开数据集。
1.3 HuggingFace官网的数据集
在官网的datasets中搜索glue,打开后可以看到很多数据集,其中的mrpc就是刚刚加载的数据集

可以看到很多预览的东西,后续可以自己慢慢去看。
2、处理数据
2.1 单条数据处理
使用AutoTokenizer来处理数据
from transformers import AutoTokenizer
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)从Transformer中导入AutoTokenizer,将一个经典模型读进来,现成的分词器去分这两句话:
inputs = tokenizer("This is the first sentence.", "This is the second one.")
inputs打印结果:
{'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
这个分词器有没有什么不一样呢?
input_ids 和attention_mask之前提到过,这个token_type_ids呢?
现在的输入是两句话,但是即便你输入的是两句话,也会将你的两句话合为一体(你仔细观察input_ids 就知道了)。但是为什么是会将两句话合成一句话呢?是跟你选择得模型有关的!
但是我怎么知道怎么选模型呢?
你再看看Hugging Face的官网,点开Models,在左边可以根据任务类型进行选择分类,然后在右边选择模型

你们真是赶上好时候了,保姆级教程直接给你了。在三四年前,你做一个NLP任务,跑通一个模型贼费劲,该一个源码真给你干吐血来。
说回前面的token_type_ids,0就表示的第一句话,1表示第二句话。
把ID解码出来看看,代码:
tokenizer.convert_ids_to_tokens(inputs["input_ids"])打印结果:
['[CLS]', 'this', 'is', 'the', 'first', 'sentence', '.', '[SEP]',
'this', 'is', 'the', 'second', 'one', '.', '[SEP]']2.2 对所有数据进行处理
当我们对数据进行预处理的时候,两种方法做,一种是使用pandas工具包,清洗一遍数据。第二种就是官方强烈推荐的map方法去做的所有的数据预处理。
我们的任务有两句话,是要一起做一个tokenizer。先定义一个函数:
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)在执行map这个函数的时候,会对每一个样本都执行这个函数的操作,数据集的所有数据都会映射为向量:
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets提示:
Loading cached processed dataset at C:\Users\Administrator\.cache\huggingface\datasets\glue\mrpc\1.0.0\dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad\cache-fcf7d43fefa50575.arrow
Loading cached processed dataset at C:\Users\Administrator\.cache\huggingface\datasets\glue\mrpc\1.0.0\dacbe3125aa31d7f70367a07a8a9e72a5a0bfeb5fc42e75c9db75b96da6053ad\cache-6c207e4b2226e7c9.arrow打印结果:
A Jupyter Widget
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 1725
})
})map函数有一个好处就是指定batched=True,分布式的东西自己研究多麻烦。
看一下上面的输出,映射完后有什么,看看前面我们有几个字段:
features: ['sentence1', 'sentence2', 'label', 'idx']映射完之后有几个字段:
features: ['sentence1', 'sentence2', 'label', 'idx', 'input_ids', 'token_type_ids', 'attention_mask']多了后面几个,都是tokenizer生成的。当我们有了tokenizer生成的input_ids、token_type_ids、attention_mask前面的还需要吗?
前面的我们都不需要了,都需要删掉,后面会讲怎么删掉哈。
2.3数据封装
在NLP中怎么做数据的DataLoader呢?还是调用PyTorch的DataLoader包吗?不是的!
我们的数据已经做来分词处理,但是还没有进行封装,是不能进入模型处理的。
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)这里为什么会有一个withPadding呢?在数据打包的时候保证64个样本数据长度都是一致的
将结果打印一下:
tokenized_datasets["train"][0]notebook打印结果:
{'attention_mask': [1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'idx': 0,
'input_ids': [101, 2572, 3217, 5831, 5496, 2010, 2567, 1010, 3183, 2002, 2170, 1000, 1996, 7409, 1000, 1010, 1997, 9969, 4487, 23809, 3436, 2010, 3350, 1012, 102, 7727, 2000, 2032, 2004, 2069, 1000, 1996, 7409, 1000, 1010, 2572, 3217, 5831, 5496, 2010, 2567, 1997, 9969, 4487, 23809, 3436, 2010, 3350, 1012, 102],
'label': 1,
'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}将数据取出来看看呗:
samples = tokenized_datasets["train"][:8]#取到所有的列
samples = {k: v for k, v in samples.items() if k not in ["idx", "sentence1", "sentence2"]}#不需要这些列
[len(x) for x in samples["input_ids"]]#每一个样本的长度第一行:取出数据集,取训练集,取前八个样本,sample即为训练集的前八个样本
第二行:一个列表推导式,将["idx", "sentence1", "sentence2"]这三个列过滤掉,剩下的做成字典,k为列名,v为列值
第三行:依次打印出每个样本的长度
打印结果:
[50, 59, 47, 67, 59, 50, 62, 32]
8个样本长度都不同?在我们任务中样本长度必须得相同啊。
经过data_collator处理之后,所有的样本长度都是固定的,再用k:v的形式打印一下
batch = data_collator(samples)
{k: v.shape for k, v in batch.items()}打印结果:
{'attention_mask': torch.Size([8, 67]),
'input_ids': torch.Size([8, 67]),
'labels': torch.Size([8]),
'token_type_ids': torch.Size([8, 67])}结果就是按照最大值取,全是8*67了
3 模型训练
咱玩一个东西,要带着问题去玩儿,有的人特别擅长做笔记,拿本拿笔记下来?能把所有参数都记下来,真没什么卵用。什么叫学习,多查,多练,遇到问题了,然后要去解决一个问题的一个过程,这才叫学习。
3.1模型参数
先打开这个API文档:
API文档,实际用的时候一定对应着来
API文档就是说明书,你得认真的看,有你想知道的一切答案
首先第一步,从Transformers中导进来训练参数
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")设置好后再打印出来看看:
print(training_args )
TrainingArguments(
_n_gpu=0,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
bf16=False,
bf16_full_eval=False,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
debug=[],
deepspeed=None,
disable_tqdm=False,
do_eval=False,
do_predict=False,
do_train=False,
eval_accumulation_steps=None,
eval_steps=None,
evaluation_strategy=IntervalStrategy.NO,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
greater_is_better=None,
group_by_length=False,
half_precision_backend=auto,
hub_model_id=None,
hub_strategy=HubStrategy.EVERY_SAVE,
hub_token=,
ignore_data_skip=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=5e-05,
length_column_name=length,
load_best_model_at_end=False,
local_rank=-1,
log_level=-1,
log_level_replica=-1,
log_on_each_node=True,
logging_dir=test-trainer\runs\May26_10-08-48_WIN-BM410VRSBIO,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=500,
logging_strategy=IntervalStrategy.STEPS,
lr_scheduler_type=SchedulerType.LINEAR,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=None,
mp_parameters=,
no_cuda=False,
num_train_epochs=3.0,
optim=OptimizerNames.ADAMW_HF,
output_dir=test-trainer,
overwrite_output_dir=False,
past_index=-1,
per_device_eval_batch_size=8,
per_device_train_batch_size=8,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=,
remove_unused_columns=True,
report_to=['tensorboard', 'wandb'],
resume_from_checkpoint=None,
run_name=test-trainer,
save_on_each_node=False,
save_steps=500,
save_strategy=IntervalStrategy.STEPS,
save_total_limit=None,
seed=42,
sharded_ddp=[],
skip_memory_metrics=True,
tf32=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_legacy_prediction_loop=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,
xpu_backend=None,
) 我的天哪,这么多参数,这些参数都能改吗?
你都能改,要训练模型的时候,这些参数都要指定的
就算你背下来了,你还是要忘,就是要边查边用
比如说我要指定batch怎么指定呢?指定epochs怎么指定呢?
你打开API文档,看看人家API文档做的多漂亮。
鼠标停在第一个参数上:
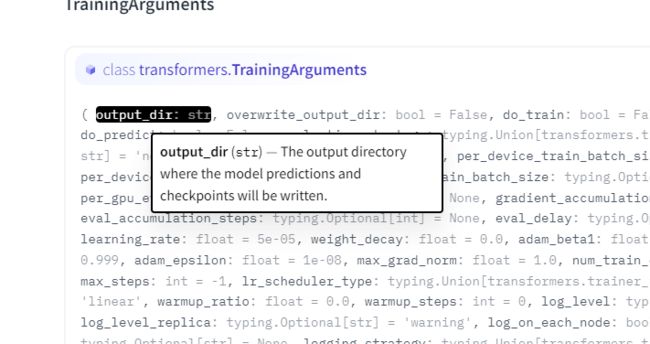
第一个就是输出路径,自己读一遍,模型保存的位置对不对?后面的也是这样一个一个看的。
前面我们打印出来的都是默认的参数
3.2模型导入
接下来导一下模型:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)模型有一些提示:
Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertForSequenceClassification: ['cls.predictions.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.decoder.weight', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight', 'cls.predictions.transform.LayerNorm.bias']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.首先确定你任务是什么,比如对序列进行分类,就导入AutoModelForSequenceClassification,选择模型checkpoint,num_labels=2是什么意思?我们要改输出层,输出层不用预训练模型了,输出层自己训练。
所以上面的提示告诉你,很多分类层的权重参数没有指定到,就是分类的输出层被自己初始化了,无法加载预训练模型了,当然了正合我们意。
3.3模型训练
模型咋训练?哎呀,太简单了,真的嗷嗷简单:
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)无论训练什么都把Trainer导进来,看看参数
- model:我们在上面已经定义了
- training_args:配置参数,前面打印过,现在全是默认的,但是可以改,后续再教怎么改
- train_dataset:训练集,自己指定,根据前面定义的字典
- eval_dataset:验证集,自己指定,根据前面定义的字典
- data_collator:这是前面提到的batch
- tokenizer:前面也定义了
不懂没关系,再次点开前面提到的API,搜一下Trainer,要等个几秒钟才会出现:

不懂就去API里面查:
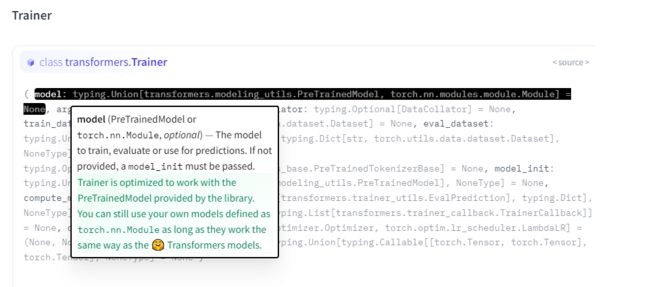
看看人家这在线API做的,多招人稀罕啊,鼠标放上面就有解释了。
指定好参数,直接.train一下就开始训练了:
trainer.train()训练过程中会给你打印出损失:

再看 training_args参数中,有一个叫logging_steps=500,就是说500次打印一次损失
还会告诉你一些已经指定的参数:
The following columns in the training set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence2, idx, sentence1.
***** Running training *****
Num examples = 3668
Num Epochs = 3
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 1377其实这个任务CPU也能跑,但是比较慢,但是最好还是有GPU这个东西哈。
跑完之后还有提示:
Saving model checkpoint to test-trainer\checkpoint-500
Configuration saved in test-trainer\checkpoint-500\config.json
Model weights saved in test-trainer\checkpoint-500\pytorch_model.bin
tokenizer config file saved in test-trainer\checkpoint-500\tokenizer_config.json
Special tokens file saved in test-trainer\checkpoint-500\special_tokens_map.json
Saving model checkpoint to test-trainer\checkpoint-1000
Configuration saved in test-trainer\checkpoint-1000\config.json
Model weights saved in test-trainer\checkpoint-1000\pytorch_model.bin
tokenizer config file saved in test-trainer\checkpoint-1000\tokenizer_config.json
Special tokens file saved in test-trainer\checkpoint-1000\special_tokens_map.json
Training completed. Do not forget to share your model on huggingface.co/models =)就是你的模型都保存在哪儿了,训练完成后,就可以得到模型了:
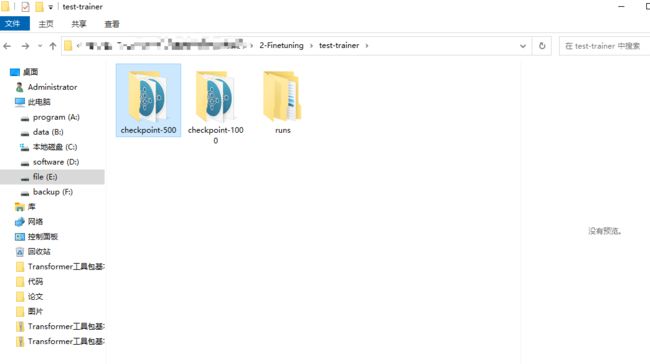
这分别是500打印一次损失的结果,1000打印一次损失的结果,点进去看,pytorch_model.bin这个文件,就是你训练的模型

这就是一个训练过程
4 模型测试
4.1模型测试
模型训练好了,用验证集进行一下验证:
predictions = trainer.predict(tokenized_datasets["validation"])
print(predictions.predictions.shape, predictions.label_ids.shape)打印的结果:(408, 2) (408,),当然这是打印的维度
前面给到的都是损失值,能不能给出具体的评估呢?datasets 模块专门提供了评估子模块load_metric
from datasets import load_metric
metric = load_metric("glue", "mrpc")
metric.compute(predictions=preds, references=predictions.label_ids)打印结果:
A Jupyter Widget
{'accuracy': 0.8186274509803921, 'f1': 0.8754208754208753}在评估的参数中,只需要传入两个值,一个是predictions,一个是references,预测和标签嘛
4.2训练评估函数
我们在训练过程中能不能指定评估参数呢,那就需要将它封装成一个函数了:
def compute_metrics(eval_preds):
metric = load_metric("glue", "mrpc")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)逐行解释:
- 首先函数名字无所谓
- 还是加载默认的方法
- 输入参数只有一个值,但是在这个函数中需要做一个解开操作logits, labels = eval_preds
- labels 是真实的标签,logits是一个中间结果不是实际预测结果,将logits中最大的取出来(模型中预测的最大概率)
- 然后再把预测和标签传进去返回
最后在训练参数中将上面的函数指定进去:
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)compute_metrics=compute_metrics,这是一个固定的写法
再训练看一下:
trainer.train()这回打印的指标就变多了:

这就完了,源码点我直达。
这就完了,这简直就是,简单TM给简单开门,简单到家了