今天在OpenHatch上找到一个涉及到很多Python知识点的问题,这个问题写着适于中级水平的Python程序员自测,需求是编写一个带评分功能的英文填字图版游戏,我尝试用2.7版本的Python对其进行了编码。
详细需求:
practice breaking down a problem and solving it in Python from scratch
practice command line argument parsing
practice reading from files
practice working with dictionaries and for loops
翻译作中文如下:
题中给了一个叫做sowpods.txt文件,这个文件中每一行是一个大写单词
用户输入一个单词,通过运行程序显示这个单词中的字母能组成的新单词(小写)
对于单词中的字母,题目对每个字母给到一个数字分数,根据单词中的字母得到的分数进行降序排序
sowpods.txt文件示意图:
项目链接:
http://webcache.googleusercontent.com/search?q=cache:xcsq7ruu3NoJ:wiki.openhatch.org/Scrabble_challenge+&cd=9&hl=zh-CN&ct=clnk&gl=cn
如果你可以不看我的答案独立解出这个问题,相信你已经是个不错的Python程序员了。
如果你有疑问,以下是我的详细的思考编码过程,也许你可以参考一下。
既然定义为中级水平,这个题目还是涉及到几个知识点的,我把我代码中涉及到的Python知识点罗列了出来,如下:
1.文件操作
2.函数的使用
3.列表解析的应用
4.Python的collections库中Counter类的巧妙应用
5.sys.argv取到用户输入的参数(个人选择,用argparse库效果类似)
...
构思过程:
用面向函数的思想对这个问题进行了解答。
程序分为5个函数:
1.main函数负责接受用户参数,调用其他函数,和对结果进行排序(你也可以把接受函数和对结果排序独立为两个新函数);
2.get_word_list函数负责把sowpods中的单词放到一个list中;
3.get_valid_words函数筛选有效单词并将其放在list中返回;
4.lower_valid_words函数负责把get_valid_words函数变为小写(若你仔细做了这个题目,请在留言中回答这个函数的好处);
5.get_scores函数负责计算每个单词的分数,并将结果存放在一个dict中。
这个题目的难点在于get_valid_words函数的编写,最初我的思路是把用户输入的单词和
sowpods中单词的比较,说的具体一点,当我输入helo时,程序输出的结果是不可以出现hello的,因为输入单词中l的个数为1,而hello中l的个数为2,在首次编码时,用list对用户输入单词进行了存储比较,每当找到一个单词后就把list中的对应的字母移走,写出来的代码像这样:
def get_valid_words(words, rack):
valid_words = []
for word in words:
rack_list = list(rack)
found = True
for c in word:
if c in rack_list:
rack_list.remove(c)
else:
found = False
break
if found:
valid_words.append(word)
return valid_words
后来我想到collections中Counter可以进行加减运算,可以大大简化我的代码,而且提高代码可读性,更改后的代码像下面这样:
def get_valid_words(word_list, rack):
c = Counter(rack)
return [word for word in word_list if not (Counter(word) - c)]
参考资料链接:
https://pymotw.com/2/collections/counter.html
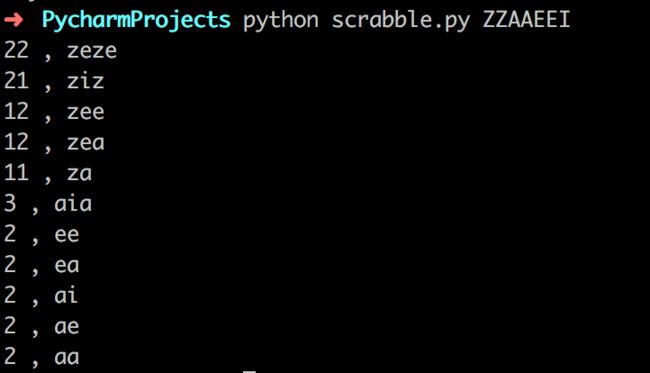
遗憾的是,我对更改后的代码进行运行测试,对于相同的用户输入单词ZZAAEEI ,第一种函数运行需要1.2s,而后一种写法需要5.4s,这个问题我没有细究,有空我会看看Counter的源码。
下面我贴出每个函数:
1.main函数
def main():
if len(sys.argv) != 2:
raise SystemExit('Usage: scrabble_change.py RACK')
rack = sys.argv[1]
word_list = get_word_list('sowpods.txt')
valid_words = get_valid_words(word_list, rack.upper())
valid_words = lower_valid_words(valid_words)
d = get_scores(valid_words)
for val, key in sorted(zip(d.values(), d.keys()), reverse=True):
print(val, key)
2.get_word_list函数
def get_word_list(file_name):
word_list = []
with open(file_name) as f:
for line in f:
word_list.append(line.strip())
return word_list
3.get_valid_words函数
def get_valid_words(word_list, rack):
c = Counter(rack)
return [word for word in word_list if not (Counter(word) - c)]
4.lower_valid_words函数
def lower_valid_words(words):
return [word.lower() for word in words]
5.get_scores函数
def get_scores(words):
d = {}
for word in words:
d[word] = sum(scores[c] for c in word)
return d
以下是全部代码,供参考:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from __future__ import print_function
import sys
from collections import Counter
scores = {"a": 1, "c": 3, "b": 3, "e": 1, "d": 2, "g": 2,
"f": 4, "i": 1, "h": 4, "k": 5, "j": 8, "m": 3,
"l": 1, "o": 1, "n": 1, "q": 10, "p": 3, "s": 1,
"r": 1, "u": 1, "t": 1, "w": 4, "v": 4, "y": 4,
"x": 8, "z": 10}
def get_word_list(file_name):
word_list = []
with open(file_name) as f:
for line in f:
word_list.append(line.strip())
return word_list
def get_valid_words(word_list, rack):
c = Counter(rack)
return [word for word in word_list if not (Counter(word) - c)]
def lower_valid_words(words):
return [word.lower() for word in words]
def get_scores(words):
d = {}
for word in words:
d[word] = sum(scores[c] for c in word)
return d
def main():
if len(sys.argv) != 2:
raise SystemExit('Usage: scrabble_change.py RACK')
rack = sys.argv[1]
word_list = get_word_list('sowpods.txt')
valid_words = get_valid_words(word_list, rack.upper())
valid_words = lower_valid_words(valid_words)
d = get_scores(valid_words)
for val, key in sorted(zip(d.values(), d.keys()), reverse=True):
print(val, key)
if __name__ == '__main__':
main()
运行效果图:
总结:
除了上面指出的知识点,本程序函数的命名也符合<代码整洁之道>的规范,本程序遵守PEP8规范,若有错误,请大家勘正。
欢迎各位指出这个程序可以改进的地方!