【C++进阶之路】模拟实现string类
文章目录
- 前言
- 一、String类
-
- ①要点说明
- ②私有成员
- ③构造函数
-
- 1.构造
- 2.拷贝构造
- ④析构函数
- ⑤c_str
- ⑤size
- ⑥[]
-
- 1 .读写
- 1.只读
- ⑦reserve
- ⑧push_back
- ⑨append
- ⑩+=
-
- 1.字符串
- 2.字符
- ⑪insert
-
- 1.插入字符
- 2.插入字符串
- ⑫earse
- ⑬find
-
- 1.字符
- 2.字符串
- ⑭substr
- ⑮resize
- ⑯clear
- ⑰>
- ⑱ ==
- ⑲>=
- ⑳swap与 =
-
- swap
- 赋值的传统写法
- 较现代写法
- 现代写法
- ㉑迭代器
-
- begin
- end
- ㉒<<
- ㉓>>
- 源码
- 总结
前言
本文所属专栏——【C++进阶之路】
上一篇,我们讲解了string类接口的基本使用,今天我们就实战从底层实现自己的string类,当然实现所有的接口难度很大,我们今天主要实现的常用的接口~
一、String类
①要点说明
- 1.为了
不与库里面的string冲突,我们需要命名空间对自己实现的类进行封装 - 2.这里我们实现的框架是按照
顺序表的数据结构进行实现的。 - 3.为了理解,下面的接口是分开讲解的,最后我会给出源码。
②私有成员
这里顺便把框架给出~
namespace my_string
{
class string
{
public:
//迭代器——begin和end要用
typedef char* iterator;
typedef const char* const_iterator;
private:
char* _str;
size_t _size;
size_t _capacity;
static size_t npos;
};
size_t string::npos = -1;
}
前3个私有成员或许都明白,那最后一个成员我们就要额外介绍一下,由于是size_t类型,vs在64位平台下是8字节,32位平台下是4字节,且由于是无符号的只会大于等于0,又因为是static修饰的,所以不走初始化列表初始化,由于这里只是声明,所以只能在类外进行定义,在定义时只需声明类域和变量类型即可,存储类(static)不必在写。所以就是上述的写法。有啥用呢?在接下来的insert接口中我们会用到。
③构造函数
我们这里需要跟库里面大致看齐,所以这里说一下库里参数的概念,_size和_capacity指的是有效字符,不包含字符串的最后一个\0,所以这里初始化时,会多开一个字节的空间用于存放\0,但_capacity和_size相同。
1.构造
string(const char* str = "")
{
int len = strlen(str);
_str = new char[len + 1];
memcpy(_str, str,len + 1);
_size = len;
_capacity = len;//_capacity存的是多少个有效字符
}
2.拷贝构造
第一,这里涉及到深拷贝和浅拷贝。第二,这里涉及向谁(\0和_size)看齐的问题。我们先来解决第一个问题。
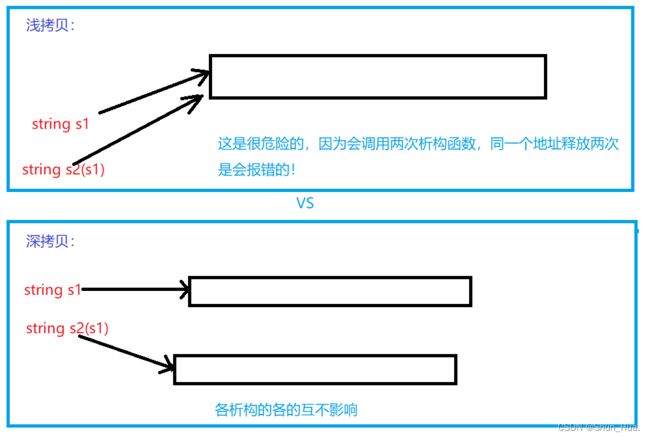
- 浅拷贝,管理的是同一块空间,会析构两次十分危险,因此会直接报错。
当只进行只读时我们深拷贝出来的空间会造成一定程度上的空间消耗,但当我们浅拷贝时又会面临上面的问题。
那有没有什么办法解决这个问题呢?到还真有一个写时拷贝技术和引用计数。
这里我只简单的介绍一下原理,并不深入介绍,有兴趣自行了解~
先说下好处:在进行只读时我们进行的是浅拷贝,在修改时我们才进行深拷贝。
再说原理:

再来解决第二个问题,这就又涉及到库的实现,直接说库是咋实现的吧,举个例子:

也就是说库里面拷贝构造,不按照到第一个\0为止,而是最后一个,这咋解决呢?其实很简单,按照_size进行拷贝即可,用到的函数为memcpy。
string(const string& str)
{
_str = new char[str._size + 1];
memcpy(_str, str._str, str._size + 1);
_size = str._size;
_capacity = str._capacity;
}
④析构函数
~string()
{
delete[]_str;
_str = nullptr;
_size = _capacity = 0;
}
⑤c_str
const char* c_str() const
{
return _str;
}
后面的const有两个作用:
- 使 *this不可被修改
- const修饰string和string都可调用此函数
⑤size
由于_size成员是私有的,因此我们在使用时需要通过公有函数进行访问。
size_t size() const
{
return _size;
}
- const作用同上
⑥[]
1 .读写
- 注意:需要检查位置是否越界。
char& operator[](size_t pos)
{
//判断pos位置是否越界
assert(pos < _size);
return _str[pos];
}
1.只读
const char& operator[](size_t pos) const
{
//判断pos位置是否越界
assert(pos < _size);
return _str[pos];
}
⑦reserve
- 只有当n大于容量时我们才进行扩容。
void reserve(size_t n = 0)
{
if (n > _capacity)
{
char* tmp = new char[n+1];
memcpy(tmp, _str, _size+1);
delete[]_str;
_str = tmp;
_capacity = n;
}
}
⑧push_back
考虑三个问题:
- 是否需要扩容
- 扩容时字符串是否为空
- 尾插之后要补\0
void push_back(char c)
{
//考虑扩容
if (_size == _capacity)
{
//有可能是空字符串
size_t new_capacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(new_capacity);
}
_str[_size++] = c;
//注意这里一定要给'\0'
_str[_size] = '\0';
}
⑨append
- 由于是插入的是一个字符串,这里我们的扩容的条件是一个范围
void append(const char* str)
{
int len = strlen(str);
if (len + _size >= _capacity)
{
reserve(len + _size);
}
memcpy(_str + _size, str, len + 1);
//strcpy会将\0拷贝过去,但是这里我们是memcpy,所以要多拷贝一个。
_size += len;
}
⑩+=
复用上面的⑧和⑨。
1.字符串
string& operator += (const char* str)
{
append(str);
return *this;
}
2.字符
string& operator += (char c)
{
push_back(c);
return *this;
}
⑪insert
主要逻辑:
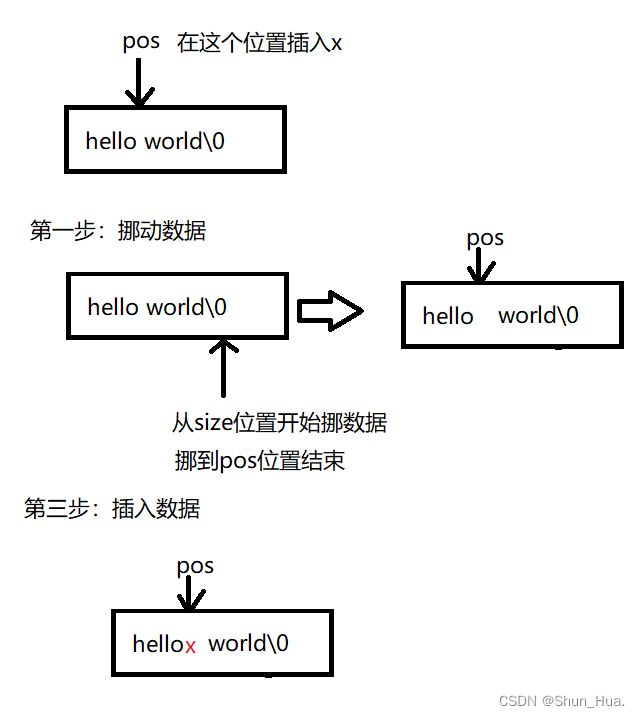
这里需要考虑pos(size_t)位置如果为0,由于这里是从前往后挪,我们要对下标不断做减法,而判断的条件必然是下标大于等于pos继续,当下标再一减,就会变成很大的数,所以这里要不把数据类型都强转成整形,要不就设置npos用来判断是否越界,这里我们取后者。
注意:
- 要检查pos位置的合法性
- 看是否需要扩容
1.插入字符
string& insert(size_t pos, size_t n, char c)
{
//看pos位置是否合法
assert(pos < _size);
//看是否要扩容
reserve(n + _size);
//将pos位置的数据进行移动
//npos是为了防止i--越界访问,因为size_t的范围是大于等于0的,
//当pos为0,如果不设置npos会出现死循环
for (size_t i = _size; i >= pos&& i!= npos; i--)
{
_str[i + n] = _str[i] ;
}
//将位置插入字符c
for (int i = pos; i < pos + n; i++)
{
_str[i] = c;
}
_size += n;
return *this;
}
2.插入字符串
string& insert(size_t pos, const char* str)
{
assert(pos < _size);
int len = strlen(str);
reserve(len + _size);
for (size_t i = _size; i >= pos&&i != npos; i--)
{
_str[i + len] = _str[i];
}
//将字符串拷贝过去,当然这里\0就不用拷过去了。
memcpy(_str + pos, str, len);
_size += len;
return *this;
}
⑫earse
主要逻辑:

注意事项:
- pos位置的合法性
- len和pos+len是否大于_size
string& earse(size_t pos = 0, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size )
{
_str[pos] = '\0';
_size = pos;
}
else
{
for (size_t i = pos + len; i <= _size; i++)
{
_str[i - len] = _str[i];
}
_size -= len;
}
return *this;
}
⑬find
- 失败返回npos
1.字符
size_t find(char c, size_t pos = 0) const
{
assert(pos < _size);
int begin = 0;
while (begin < _size && _str[begin] != c)
{
begin++;
}
if (begin == _size)
{
return npos;
}
else
{
return begin;
}
}
2.字符串
- 有兴趣可自行了解KMP和BMP算法。
这里我直接用库里的strstr,失败会返回空指针。
size_t find(const char* str, size_t pos = 0)
{
assert(pos < _size);
char* ret = strstr(_str + pos,str);
if (ret == nullptr)
{
return -1;
}
else
{
return ret - _str;
}
}
⑭substr
注意事项:
- pos位置的合法性
- 字符串区间的合法性
主要逻辑:
- 找到起始和结束区间
string substr(size_t pos = 0, size_t len = npos)
{
assert(pos < _size);
size_t begin = pos;
size_t end = pos + len;
if (len == npos|| pos + len >= _size)
{
end = _size;
}
string tmp;
for (size_t i = begin; i < end; i++)
{
tmp += _str[i];
}
return tmp;
}
⑮resize
void resize(size_t n, char c = '\0')
{
if (n > _size)
{
reserve(n);
memset(_str + _size, c, n - _size);
}
_str[n] = '\0';
_size = n;
}
⑯clear
void clear()
{
_str[0] = '\0';
_size = 0;
}
⑰>
主要逻辑:

bool operator>(const string& s)
{
//先比较size
size_t less = _size > s._size ? s._size : _size;
int ret = memcmp(_str, s._str, less);
if (ret == 0)
{
return _size > s._size;
}
return ret > 0;
}
⑱ ==
bool operator==(const string& s)
{
//size_t less = _size > s.size() ? s.size() : _size;
//int ret = memcmp(_str, s.c_str(), less);
//if (ret == 0)
//{
// return _size == s.size();
//}
return _size == s._size &&
memcmp(_str, s._str, _size);
}
至于< ,<= ,>= != 都可进行复用,这里就复用个>=。
⑲>=
bool operator>=(const string& s)
{
return *this > s || *this == s;
}
⑳swap与 =
这两个有很大的关系,这里放到一块讲。
swap
void swap(string& str)
{
std::swap(_str, str._str);
std::swap(_size, str._size);
std::swap(_capacity, str._capacity);
//说明:不能进行对象的交换,因为swap里也有赋值,成递归调用了。
}
赋值的传统写法
string& operator=(const string& str)
{
//传统写法
//前提是自己不能拷贝自己
if (this != &str)
{
delete[]_str;
_str = new char[str._capacity + 1];
memcpy(_str, str._str, _size + 1);
_capacity = str._capacity;
_size = str._size;
}
return *this;
}
较现代写法
- 让临时变量,帮我们去析构。
string& operator=(const string& str)
{
string tmp(str);
swap(tmp);
return *this;
}
现代写法
- 直接拷贝构造临时变量。
- 让临时变量去析构
string& operator=(string tmp)
{
swap(tmp);
return *this;
}
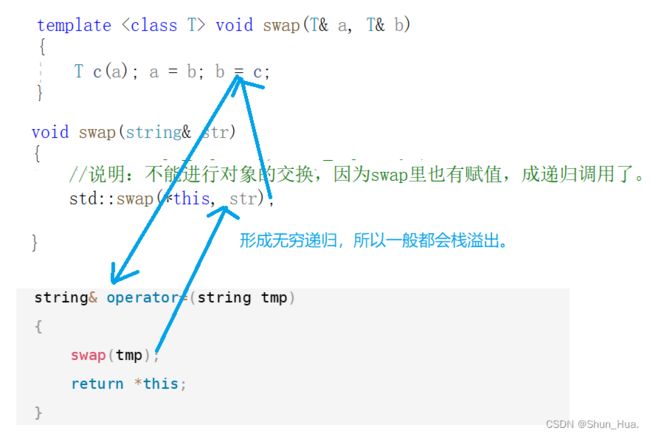
错误示例:
void swap(string& str)
{
std::swap(*this, str);
//说明:不能进行对象的交换,因为swap里也有赋值,成递归调用了。
}
string& operator=(string tmp)
{
swap(tmp);
return *this;
}
图解:
㉑迭代器
begin
iterator begin()
{
return _str;
}
const_iterator begin() const
{
return _str;
}
end
iterator end()
{
return _str + _size;
}
const_iterator end()const
{
return _str + _size;
}
㉒<<
这里需要说明两点:
- 流插入必须用引用当参数,因为拷贝库里面会强制delete进行释放,无法返回。
- 范围for的底层原理本质上就是迭代器。
ostream& operator<<(ostream& out, const string& s)
// 这里必须加const防止被修改
{
for (auto c : s)
{
cout << c;
}
return out;
}
㉓>>
注意:
-
输入即覆盖,所以我们需要对输入的string进行清空
-
为了与库对齐,我们这里的空格和\n是跳过的,即输入: “空格”"空格"hello最后会将hello输入进去。
-
这里我们设置了一个相当于扩大了容量,就好比你原来拿一个勺子喝水,现在要拿一个碗进行喝水,在碗满了或者没水之后,再放入string里面。
istream& operator>>(istream& in, string& s)
{
//先清除s内部的内容
s.clear();
//清除空格和\n
char ch = in.get();
while (ch == ' ' || ch == '\n')
{
ch = in.get();
}
//输入字符
//由于+=要不断的进行开空间,我们可以设置一个buf将容量放大,
//当这个buf满了,就在加上,这样节约了空间
char buf[128];
int i = 0;
while (ch != ' ' && ch != '\n')
{
buf[i++] = ch;
if (i == 127)
{
buf[i] = '\0';
s += buf;
i = 0;
}
ch = in.get();
}
//这里buf也可能会有数据
if (i != 0)
{
buf[i] = '\0';
s += buf;
}
return in;
}
源码
namespace my_string
{
class string
{
public:
//迭代器
typedef char* iterator;
typedef const char* const_iterator;
iterator begin()
{
return _str;
}
const_iterator begin() const
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator end()const
{
return _str + _size;
}
//用字符串进行构造
string(const char* str = "")
{
int len = strlen(str);
_str = new char[len + 1];
memcpy(_str, str,len + 1);
_size = len;
_capacity = len;//_capacity存的是多少个有效字符
}
//拷贝构造
string(const string& str)
{
//在类域里面对象可访问其成员,不管是由谁进行调用
_str = new char[str._size + 1];
memcpy(_str, str._str, str._size + 1);
_size = str._size;
_capacity = str._capacity;
}
//析构函数
~string()
{
delete[]_str;
_str = nullptr;
_size = _capacity = 0;
}
//返回C字符串类型
const char* c_str() const
//写const的原因为——不管const或非const都可使用此成员函数
{
return _str;
}
//返回有效字符的大小
size_t size() const//const理由同上
{
return _size;
}
//运算符重载下标引用操作符
//返回值得引用,读和写都可行
char& operator[](size_t pos)
{
//判断pos位置是否越界
assert(pos < _size);
return _str[pos];
}
//只读版本
const char& operator[](size_t pos) const
{
//判断pos位置是否越界
assert(pos < _size);
return _str[pos];
}
//扩容,参数n是想要扩到多大
void reserve(size_t n = 0)
{
if (n > _capacity)
{
char* tmp = new char[n+1];
memcpy(tmp, _str, _size+1);
delete[]_str;
_str = tmp;
_capacity = n;
}
}
//尾插
void push_back(char c)
{
//考虑扩容
if (_size == _capacity)
{
//有可能是空字符串
size_t new_capacity = _capacity == 0 ? \
4 : _capacity * 2;
reserve(new_capacity);
}
_str[_size++] = c;
//注意这里一定要给'\0'
_str[_size] = '\0';
}
//追加字符串
void append(const char* str)
{
int len = strlen(str);
if (len + _size >= _capacity)
{
reserve(len + _size);
}
memcpy(_str + _size, str, len + 1);
_size += len;
}
//运算符重载+=
string& operator += (const char* str)
{
append(str);
return *this;
}
string& operator += (char c)
{
push_back(c);
return *this;
}
string& insert(size_t pos, size_t n, char c)
{
//看pos位置是否合法
assert(pos < _size);
//看是否要扩容
reserve(n + _size);
//将pos位置的数据进行移动
//npos是为了防止i--越界访问,因为size_t的范围是大于等于0的,
//当pos为0,如果不设置npos会出现死循环
for (size_t i = _size; i >= pos&& i!= npos; i--)
{
_str[i + n] = _str[i] ;
}
//将位置插入字符c
for (int i = pos; i < pos + n; i++)
{
_str[i] = c;
}
_size += n;
return *this;
}
string& insert(size_t pos, const char* str)
{
assert(pos < _size);
int len = strlen(str);
reserve(len + _size);
for (size_t i = _size; i >= pos&&i != npos; i--)
{
_str[i + len] = _str[i];
}
//将字符串拷贝过去
memcpy(_str + pos, str, len);
_size += len;
return *this;
}
string& earse(size_t pos = 0, size_t len = npos)
{
assert(pos < _size);
if (len == npos || pos + len >= _size )
{
_str[pos] = '\0';
_size = pos;
}
else
{
for (size_t i = pos + len; i <= _size; i++)
{
_str[i - len] = _str[i];
}
_size -= len;
}
return *this;
}
//查找字符串的函数
size_t find(char c, size_t pos = 0) const
{
assert(pos < _size);
int begin = 0;
while (begin < _size && _str[begin] != c)
{
begin++;
}
if (begin == _size)
{
return npos;
}
else
{
return begin;
}
}
size_t find(const char* str, size_t pos = 0)
{
assert(pos < _size);
char* ret = strstr(_str + pos,str);
if (ret == nullptr)
{
return -1;
}
else
{
return ret - _str;
}
}
string substr(size_t pos = 0, size_t len = npos)
{
assert(pos < _size);
size_t begin = pos;
size_t end = pos + len;
if (len == npos|| pos + len >= _size)
{
end = _size;
}
string tmp;
for (size_t i = begin; i < end; i++)
{
tmp += _str[i];
}
return tmp;
}
//调整size
//void resize(size_t n)
//{
// if (n > _size)
// {
// reserve(n);
// }
// _str[n] = '\0';
// _size = n;
//}
void resize(size_t n, char c = '\0')
{
if (n > _size)
{
reserve(n);
memset(_str + _size, c, n - _size);
}
_str[n] = '\0';
_size = n;
}
void clear()
{
_str[0] = '\0';
_size = 0;
}
//比较大小
bool operator>(const string& s)
{
//先比较size
size_t less = _size > s._size ? s._size : _size;
int ret = memcmp(_str, s._str, less);
if (ret == 0)
{
return _size > s._size;
}
return ret > 0;
}
bool operator==(const string& s)
{
//size_t less = _size > s.size() ? s.size() : _size;
//int ret = memcmp(_str, s.c_str(), less);
//if (ret == 0)
//{
// return _size == s.size();
//}
return _size == s._size &&
memcmp(_str, s._str, _size);
}
bool operator>=(const string& s)
{
return *this > s || *this == s;
}
bool operator<(const string& s)
{
return !(*this >= s);
}
bool operator<=(const string& s)
{
return !(*this > s);
}
void swap(string& str)
{
std::swap(_str, str._str);
std::swap(_size, str._size);
std::swap(_capacity, str._capacity);
//说明:不能进行对象的交换,因为swap里也有赋值,成递归调用了。
/*std::swap(*this, str);*/
}
string& operator=(const string& str)
{
//现代写法
//string tmp(str);
//swap(tmp);
//传统写法
//前提是自己不能拷贝自己
if (this != &str)
{
delete[]_str;
_str = new char[str._capacity + 1];
memcpy(_str, str._str, _size + 1);
_capacity = str._capacity;
_size = str._size;
}
return *this;
}
// 库里的swap
//template void swap(T& a, T& b)
//{
// T c(a); a = b; b = c;
//}
//最优现代写法
string& operator=(string tmp)
{
swap(tmp);
return *this;
}
private:
char* _str;
size_t _size;
size_t _capacity;
static size_t npos;
//const static size_t npos = -1;
//这是可行的。当做特殊语法记住即可。
};
size_t string::npos = -1;
//注意流插入和流提取不能进行拷贝,因为实现是强制设置为引用,
//拷贝会直接delete
ostream& operator<<(ostream& out, const string& s)
{
//for (size_t begin = 0; begin < s.size(); begin++)
//{
// out << s[begin];
//}
for (auto c : s)
{
cout << c;
}
return out;
}
istream& operator>>(istream& in, string& s)
{
//先清除s内部的内容
s.clear();
//清除空格和\n
char ch = in.get();
while (ch == ' ' || ch == '\n')
{
ch = in.get();
}
//输入字符
//由于+=要不断的进行开空间,我们可以设置一个buf将容量放大,
//当这个buf满了,就在加上,这样节约了空间
char buf[128];
int i = 0;
while (ch != ' ' && ch != '\n')
{
buf[i++] = ch;
if (i == 127)
{
buf[i] = '\0';
s += buf;
i = 0;
}
ch = in.get();
}
//这里buf也可能会有数据
if (i != 0)
{
buf[i] = '\0';
s += buf;
}
return in;
}
}
总结
今天的分享就到这里了,如果觉得文章不错,点个赞鼓励一下吧!我们下篇文章再见!