人脸识别学习
目录
1、人脸识别如何做到一次学习
2、Siamese 网络(Siamese network)
3、Triplet 损失(Triplet 损失)
4、人脸验证与二分类
5、什么是神经风格迁移?(What is neural style transfer?)
6、什么是深度卷积网络
8、代价函数
1、人脸识别如何做到一次学习
(1)、数据收集:收集包含多个人脸图像的数据集,每个人脸图像都有对应的标签或身份信息。
(2)、图像预处理:对数据集中的每个人脸图像进行预处理,包括图像对齐、去噪、亮度/对比度
调整等。目的是使得每个人脸图像都具有相似的规范化特征
(3)、 特征提取:使用人脸识别算法(如PCA、LDA、DeepFace等)从每个人脸图像中提取人
脸的特征向量。这些特征向量通常是低维度的数值表示,用于表示每个人脸的唯一特征
(4)、特征存储:将每个人脸的特征向量与对应的标签或身份信息一起存储在数据库中,以便后
续的人脸识别任务中使用
(5)、人脸识别:在进行人脸识别时,首先对待识别的人脸图像进行预处理,然后提取其特征向
量。接下来,与数据库中存储的人脸特征向量进行比对,使用相似度度量方法(如欧氏距离、余弦
相似度等)计算待识别人脸与数据库中人脸的相似度。根据相似度,可以判断待识别人脸的身份。
2、Siamese 网络(Siamese network)
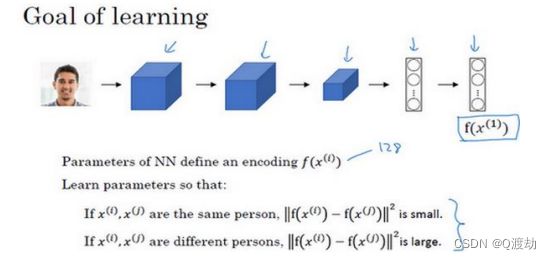
(1)、如果给定输入图像 (), 这个网络会输出 ()的 128 维的编码
(2)、学习参数,使得如果两个图片 ()和 () 是同一个人,那么得到的两个编码的距离就小
(3)、如果 ()和 ()是不同的人,那么它们之间的编码距离大一点
(4)、改变这个网络所有层的参数,会得到不同的编码结果,使用反向传播来改变这些所有的参
数,以确保满足这些条件
3、Triplet 损失(Triplet 损失)
(1)、Triplet loss 是一种用于训练深度学习模型的损失函数,主要应用于人脸识别、图像检索等
问题中。它的目标是将同一类别的样本尽可能地拉近,不同类别的样本尽可能地推远
(2)、Triplet loss 的输入是一个三元组 (a, p, n),其中 a 表示锚点样本,p 表示正样本(同一类
别的样本),n 表示负样本(不同类别的样本)
(3)、Triplet loss 的计算方式是通过计算锚点样本与正样本之间的距离和锚点样本与负样本之间
的距离的差值,然后将差值与一个预先设定的边界值进行比较。 如果差值小于边界值,表示模型
在将同一类别的样本拉近;如果差值大于边界值,表示模型在将不同类别的样本推远。因此,
Triplet loss 的目标就是最小化同一类别样本之间的距离和最大化不同类别样本之间的距离。
(4)、Triplet loss 的公式可以表示为: L(a, p, n) = max(0, d(a, p) - d(a, n) + margin) 其中,d(a,
p) 表示锚点样本与正样本之间的距离,d(a, n) 表示锚点样本与负样本之间的距离,margin 是一个
边界值。 通过使用 Triplet loss,可以使模型学习到更加具有区分度的特征表示,从而提高模型在
人脸识别、图像检索等任务中的性能。(来源于做FaceNet系统的论文)
4、人脸验证与二分类

(1)、另一个训练神经网络的方法是选取一对神经网络,选取 Siamese 网络,使其同时计算这
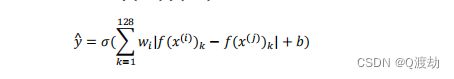
(2)、|( () ) − ( () )|对这两个编码取元素差的绝对值,把这128个元素当作特征,然后把
他们放入逻辑回归中,最后的逻辑回归可以增加参数和,就像普通的逻辑回归一样。将在这
128 个单元上训练合适的权重,用来预测两张图片是否是一个人,这是一个很合理的方法来学习预
测 0 或者 1,即是否是同一个人
5、什么是神经风格迁移?(What is neural style transfer?)
(1)、神经风格迁移(Neural Style Transfer)是一种利用神经网络将一张图像的风格应用到另一
张图像上的技术。它结合了深度学习和计算机视觉的技术,可以生成具有新颖艺术风格的图像
(2)、 神经风格迁移的基本思想是将一张图像的内容与另一张图像的风格进行分离,并将风格应
用到内容图像上。这个过程是通过预训练的卷积神经网络(通常使用VGG网络)来实现的
(3)、 神经风格迁移主要包括以下步骤
- 定义一个损失函数,包括内容损失和风格损失。内容损失是通过比较内容图像与生成图像在卷积神经网络的某一层的特征表示;而风格损失是通过比较风格图像与生成图像在多个卷积神经网络的不同层的特征表示
- 初始化生成图像,可以是一张随机噪声图像或者与内容图像相同的图像
- 使用反向传播算法来最小化损失函数,以更新生成图像的像素值。通过迭代优化,使得生成图像的内容与内容图像相似,并且风格与风格图像相似
- 反复迭代上述步骤,直到生成的图像达到预期的效果
6、什么是深度卷积网络
(1)、深度卷积神经网络(Deep Convolutional Neural Network,DCNN)是一种用于图像识别
和计算机视觉任务的深度学习模型。它能够自动学习图像中的特征,并将其用于分类、检测和分割
等任务
(2)、在训练过程中,深度卷积网络通过多层的卷积层、池化层和全连接层来逐步提取和组合图
像的特征。具体而言,深度卷积网络通过卷积层中的卷积操作来提取输入图像的低级特征,然后通
过多个卷积层和池化层的堆叠,逐渐提取更高级的特征。最后,通过全连接层将这些特征组合起
来,并输出最终的分类结果
(3)、深度卷积网络通过反向传播算法来训练网络参数,使得网络能够自动学习图像中的特征和
模式。训练过程中,网络通过最小化损失函数来调整权重和偏置,使得网络的输出与真实标签尽可
能接近。通过大量的训练样本和多次的迭代优化,深度卷积网络可以学习到更复杂、更抽象的特
征,并具备更强的图像识别能力
8、代价函数
(1)、() = content(, ) + style(, ),用两个超参数和来来确定内容代价和风格代价,
两者之间的权重用两个超参数来确定。第一部分被称作内容代价,这是一个关于内容图片和生成图
片的函数,它是用来度量生成图片的内容与内容图片的内容有多相似。关于和的函数,用来
度量图片的风格和图片的风格的相似度
(2)、算法的运行是这样的,对于代价函数(),为了生成一个新图像。接下来要做的是随