shell脚本
shell变量
shell内置命令
shell运算符和执行运算命令
流程控制语句
shell函数
shell重定向
常用工具 cut sed awk sort
常见面试题
1、脚本编写格式
首行设置解析器类型:#!/bin/bash 或者 #!/bin/sh
单行注释:
# 注释内容多行注释:
:<2、执行脚本
绝对路径、相对路径(./shell.sh 使用较多)、sh shell.sh、bash shell.sh、. shell.sh、source shell.sh
【注:】
2.1、路径执行需要获取文件执行权限,后者像sh shell.sh原理是将shell.sh名称作为入参让sh进程执行 不获取权限就可以调用
2.2、bash用来创建子shell
2.3、. shell.sh、source shell.sh:shell进程直接把shell.sh的信息拿出来执行,其它四种是shell开启一个父shell进程,然后再开启一个子shell进程把shell.sh的信息拿出来执行 是一种父子嵌套shell,这有可能会导致父shell的变量作用域影响不到子shell


3、变量
3.1、系统变量
如$HOME $SHELL $PWD $PATH etc。使用试例如下:

3.2、自定义变量
定义变量:变量名=变量值(前后不可有空格)
撤销变量:unset 变量名
声明静态变量:readonly 但不可撤销
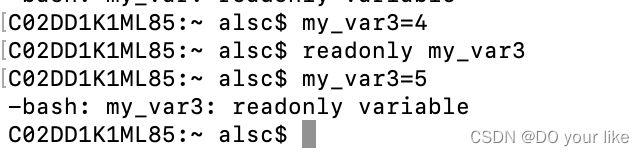
3.3、自定义变量规则
可以使用字母数字下划线,不可以数字开头,环境变量名推荐系统、自定义全局大写
=两侧不可空格,如果变量值中有空格,可以用 " " 或者 ' ' 括起来
bash中变量默认全部是字符串 无法直接数值运算 需要用运算符运算 后面会描述
3.4、set、env
查询shell中变量:set(系统变量、自定义变量)、env(系统变量)
直接用可以查询全部

通过grep 查询匹配到的部分
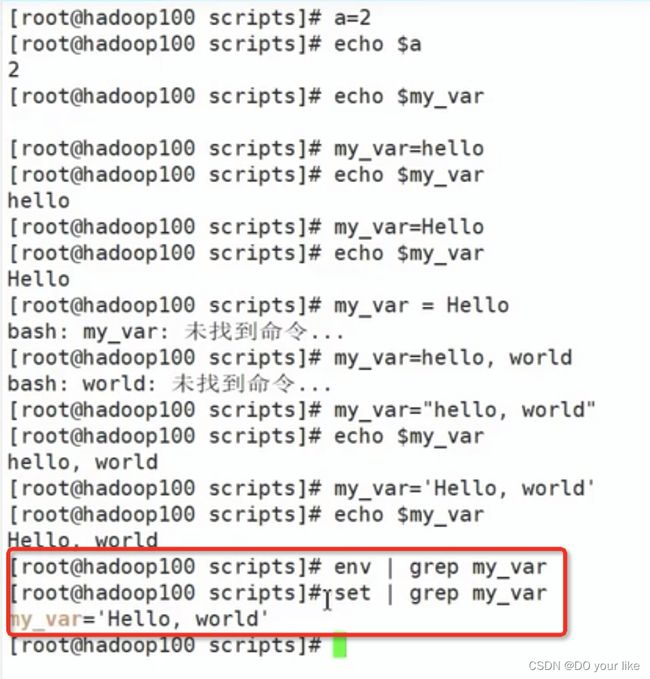
将当前shell的变量声明为全局可以作用到子/孙shell,但这个全局祖/父shell无法感知,也就是全局只能向下兼容
使用:export 变量名称

3.5、特殊符号
3.5.1、$n:用来表示不同位置传入的变量,n表示数字,$1表示传入的第一个变量,$2表示第二个变量,但是$0特殊,表示脚本名称(带路径)

3.5.2、$#:参数个数的统计变量,常用于循环判断数量是否正确以及加强脚本健壮性

3.5.3、$* & $@:都表示所有的参数,前者逻辑是把所有的参数作为一个整体,后者逻辑是区分每一个参数,可以用来参数遍历。前者像字符串,后者像数组

3.5.4、$?:最后一次命令的执行状态,如果0则执行成功,如果非0则执行失败

4、运算
shell编程是底层编程 并不能像高级编程那样可以解析赋值操作,你需要一些运算表达式来执行预算和赋值
运算:$[n1*n2]、$((n1*n2))、expr n1 \* n2(注意expr运算时,参数n1 n2之间要空格),推荐使用$[n1*n2]、$((n1*n2))

赋值:$[n1*n2]、$((n1*n2))可以直接赋值,但是expr要特殊处理下,可以嵌套进 $( ) 或者 ` `后再赋值

5、条件判断
简单来说就是通过表达式来判断真假
5.1、判断语法(condition是表达式的简写,要注意空格!!!)
test condition,然后$?可以返回0表示成功

[ condition ],然后$?可以返回0表示成功([、condition、]之间要空格)

【注:】[ ] 也可以用来判断参数是否为空,例如d=,判断是否为空[ ! -n "$d" ],返回0表示正确为空,之所以用" "嵌套$d是可以避免空参报错

5.2、常用判断条件

测试用例
 关系判断
关系判断 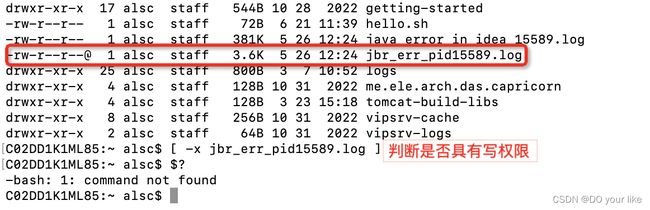 判断权限
判断权限 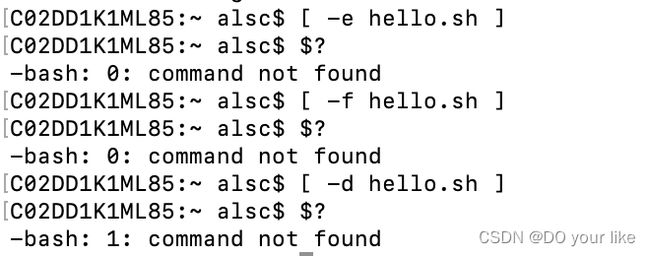 判断文件信息
判断文件信息
5.3、多条件判断
这个环节就是使用 && 或者 || ,如果要与判断使用&&,或判断使用||,例如[ conditon1] && [ condition2 ]、[ conditon1] || [ condition2 ],如果要合在一个[ ]也可以,格式:[ condition1 -a condition2 ]、[ condition1 -o condition2 ](-a是and,-o是or)
6、流程控制
6.1、if else
if [ condition ]
then
code
elif [ condition ]
then
code
else
code
fi6.2、case
case $变量名 in
"value1")
code
;; //相当于Java的break
"value1")
code
;;
*) //相当于Java的default
code
;;
esac6.3、for循环
可以对数值、字符串、变量、目录、路径等实现遍历操作。好文推荐
6.3.1、for(*;*;*)
for(i=n;i 

6.3.2、用seq按序获取min到max之间的所有数字
for i in $(seq min max)
do
code;
done 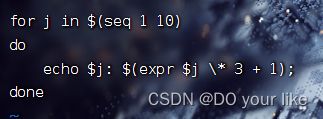

6.3.3、用{min..max}按序获取min和max之间的所有数字
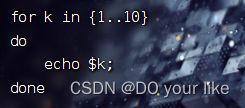

6.3.4、用awk按序获取min和max之间的所有数字
#!/bin/bash
awk 'BEGIN{for(i=1; i<=10; i++) print i}'
6.3.5、遍历文件
----------------文件路径-----------------
for file in /Volumes/work/*;
do
echo $file is file path \! ;
done
-----------------文件名称-----------------
for i in $(ls /Volumes/work)
do
echo $i is file name \! ;
done
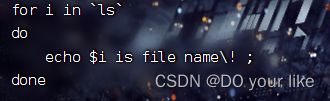
或者
for i in `ls` //当前脚本所在目录
do
echo $i is file name \!;
done

6.3.6、遍历字符串、参数
-------------------设置固定参数个数-------------------
#!/bin/bash
for i in f1 f2 f3 ;
do
echo $i is appoint ;
done
-------------------设置动态参数个数:数组、$*或者$@-------------------
list="rootfs usr data data2"
for i in $list;
do
echo $i is appoint ;
done
或者
for i in $* 或者"$*" //$*遍历每个参数,"$*"将参数作为整体,只能遍历一次,'$*'无效操作
do
echo $i is input chart\! ;
done
或者
for i in $@ 或者 "$@"
do
echo $i is input chart\! ;
done操作实例
# 编辑脚本
[root@localhost ~]#vim hello.sh
#!/bin/bash
------------------数组------------------
list="rootfs usr data data2"
for i in $list;
do
echo $i is appoint ;
done
------------------$*------------------
for i in $*
do
echo $i is input chart\! ;
done
------------------"$*"------------------
for i in "$*"
do
echo $i is input chart\! ;
done
------------------'$*'------------------
for i in '$*'
do
echo $i is input chart\! ;
done
------------------$@------------------
for i in $@
do
echo $i is input chart\!
done
------------------"$@"------------------
for i in "$@"
do
echo $i is input chart\!
done
# 配置参数 执行如下
[root@localhost ~]# . hello.sh 1 2 3
------------------数组------------------
rootfs is appoint
usr is appoint
data is appoint
data2 is appoint
------------------$*------------------
1 is input chart!
2 is input chart!
3 is input chart!
------------------"$*"------------------
1 2 3 is input chart!
------------------'$*'------------------
$* is input chart!
------------------$@------------------
1 is input chart!
2 is input chart!
3 is input chart!
------------------"$@"------------------
1 is input chart!
2 is input chart!
3 is input chart!
6.4、while循环
while [ conditon ]
do
code
done操作实例:引入 let 声明变量
------------------while循环------------------
# 编辑脚本
[root@localhost ~]# vi hello.sh
#!/bin/bash
------------------传统unary operator------------------
i=1
sum=0
while [ $i -le 100 ]
do
sum=$[$sum+$i]
i=$[$i+1]
done
echo $sum
------------------新unary operator------------------
i=1
sum=0
while [ $i -le 100 ]
do
let sum+=i
let i++
done
echo $sum
# 执行脚本
[root@localhost ~]# . hello.sh
------------------传统unary operator------------------
5050
------------------新unary operator------------------
50507、read控制台输入
格式:read (options) (variables)
options表示选项,如下表所示;
variables表示用来存储数据的变量,可以有一个,也可以有多个。
options和variables都是可选的,如果没有提供变量名,那么读取的数据将存放到环境变量 REPLY 中。
①options:
-p:指定读取值时的提示符;
-t:指定读取值时等待的时间(秒)如果-t 不加表示一直等待
②variables
变量:指定读取值的变量名
例如:read -t 10 -p "请输入账户:" name
操作实例:
# 脚本编辑
#!/bin/bash
-------------------read控制台输入-----------------
read -t 10 -p "please input your name: " name
if [ -z "$name" ] #未输入任何值
then
echo "timeout"
else
echo "welcome,$name"
fi
# 执行脚本
[root@localhost ~]# . hello.sh
please input your name: bom # 正常输入
welcome,bom
[root@localhost ~]# . hello.sh # 超时输入
please input your name: timeout
8、函数
8.1、系统函数([]表示可有可无,不代表shell编辑格式)
8.1.1、basename:basename [string / pathname] [suffix],可以根据suffix删除掉string或者pathname中对应的suffix
操作实例
C02DD1K1ML85:~ alsc$ basename /Users/alsc/hello.sh .sh
hello
C02DD1K1ML85:~ alsc$ basename /Users/alsc/hello.sh
hello.sh
C02DD1K1ML85:~ alsc$ basename /Users/alsc
alsc8.1.2、dirname:dirname [pathname],可以返回指定路径文件的绝对路径
操作实例
C02DD1K1ML85:~ alsc$ dirname /Users/alsc/hello.sh
/Users/alsc
C02DD1K1ML85:~ alsc$ dirname ./hello.sh
.
C02DD1K1ML85:~ alsc$ dirname ../alsc/hello.sh
../alsc8.2、自定义函数([]表示可有可无,不代表shell编辑格式)
[function] funname[()]
{
action;
[return int;]
}
【注:】
1.先声明函数再调用函数,shell是逐行解析,不想高级语言预先编译后再解析
2.返回值:返回值只能通过$?获取,如果没有return,则$?返回函数内最后一个命令的执行状态,return值的范围是0-255,因此如果算数运算的结果很大则无法被准确返回,下面实例会演示
3.定义函数时不用声明入参格式
操作实例
--------------------编辑脚本-------------------
C02DD1K1ML85:~ alsc$ vi fun.sh
#!/bin/bash
function add(){
sum=$[$1+$2]
echo "相加结果:$sum"
return sum
}
read -p "请输入第一个参数:" a
read -p "请输入第二个参数:" b
add $a $b
--------------------执行脚本-------------------
C02DD1K1ML85:~ alsc$ . fun.sh
请输入第一个参数:156
请输入第二个参数:234
相加结果:390
134 # 运算结果超出0-255范围,只能显示134,因此要注意return和$?结合使用时最好用来查看状态操作,下面展现优化后的函数
--------------------优化后的脚本-------------------
C02DD1K1ML85:~ alsc$ vi fun.sh
#!/bin/bash
function add(){
sum=$[$1+$2]
echo "$sum" # 注意此处在下面的sum=$(add $a $b)操作中不会打印 而是赋值给外部变量
}
read -p "请输入第一个参数:" a
read -p "请输入第二个参数:" b
sum=$(add $a $b) # 利用echo打印出运算结果 然后把值赋给变量
echo sum
--------------------执行脚本-------------------
C02DD1K1ML85:~ alsc$ . fun.sh
请输入第一个参数:156
请输入第二个参数:234
3909、正则表达式,应用点有查询、匹配、替换和分割,灵活使用
9.1、^:例如^a 匹配以a开头的所有内容
9.2、$:例如a$ 匹配以a结尾的所有内容
9.3、^a$:精准匹配为a的内容
9.4、^$:匹配的是空内容,即以空开头,以空结尾
9.5、.:匹配任意一个字符,有几个.就代表匹配几个字符,例如a.可以表示aa、ab、a1 etc.
9.6、*:不单独使用,和前一个字符联合使用,例如ro*t,则表示匹配r和t之间有>=0个o的内容,即rt、rot、root、roooot,etc.(扩展:*表示0、1或多次;?表示0或1次;+表示1或多次)
9.7、.*:匹配任意内容,即.是任意字符,*是0或多个任意字符
9.8、^a.*bash$:匹配以a开头、以hash结尾、中间是任意值的内容
9.9、[]:匹配某个范围内的一个字符
9.9.1、[6,8]:匹配6或者8
9.9.2、[0-9]:匹配一个0-9内的字符
9.9.3、[0-9]*:匹配任意长度的数字字符串
9.9.4、[a-z]:匹配一个小写a-z内的字符
9.9.5、[A-Z]:匹配一个大写a-z内的字符
9.9.5、[a-z]*:匹配任意长度的英文字符串
9.9.5、[a-z,0-9]*:匹配任意长度的英文数字字符串
9.9.6、[^0-9]:任意一个非数字字符
9.10、\:转义符
9.11、{}:和 []、转义符合用。\{n\} 表示匹配n个字符;\{n,\}:表示匹配至少n个字符;\{n,m\}:表示匹配n-m个字符。比如手机号匹配 [1][3-8][0-9]\\{9\\} ,日期匹配 [0-9]\\{4\\}-[0-9]\\{2\\}-[0-9]\\{2\\},IP匹配 [0-9]\\{1,3\\}\\.[0-9]\\{1,3\\}\\.[0-9]\\{1,3\\}\\.[0-9]\\{1,3\\}
操作实例
# 编辑文本
[C02DD1K1ML85:~ alsc]$ vim test.txt
flahgakhgkahgkakghkhgkahkghakghk
[1]
zz13838654225
flahgakhgkahgkakghkhgkahkghakghk
shell.sh
# grep匹配到的部分会在“abcdefgnn77abcdeft660099”高亮展示
[C02DD1K1ML85:~ alsc]$ echo “abcdefgnn77abcdeft660099” | grep n*[0-9]*
“abcdefgnn77abcdeft660099”
# grep匹配到各行中带有.的文本信息,这里.做下转义
[C02DD1K1ML85:~ alsc]$ cat test.txt | grep .*[\.].*
shell.sh
# grep匹配到各行中带有手机号的文本信息,这里{}做下转义
[C02DD1K1ML85:~ alsc]$ cat test.txt | grep 1[3-9][0-9]\\{9\\}
zz13838654225
10、文本处理
10.1、cut:字符串提取命令
-f 列号:提取第几列,最低是1不是0!!!
-d 分隔符:按照指定分隔符分割列
----------------------编辑文本---------------------
[C02DD1K1ML85:alsc-packs-goods-center alsc$ vim excel.txt
ID Name Gender Mark
1 Ford M 85
2 White M 60
3 Clyde M 70
----------------------提取文本信息,按列具体提取---------------------
[C02DD1K1ML85:alsc-packs-goods-center alsc$ cut [-d " "] -f 2 excel.txt
Name
Ford
White
Clyde
----------------------提取文本信息,通过","按列范围提取---------------------
[C02DD1K1ML85:alsc-packs-goods-center alsc$ cut [-d " "] -f 2,4 student.txt
Name Mark
Ford 85
White 60
Clyde 70
----------------------提取文本信息,通过"-"按列范围提取---------------------
C02DD1K1ML85:~ alsc$ cut -f 1- eccel.txt
ID Name Gender Mark
1 Ford M 85
2 White M 60
3 Clyde M 70
C02DD1K1ML85:~ alsc$ cut -f -4 eccel.txt
ID Name Gender Mark
1 Ford M 85
2 White M 60
3 Clyde M 70
C02DD1K1ML85:~ alsc$ cut -f 3-4 eccel.txt
Gender Mark
M 85
M 60
M 70
C02DD1K1ML85:~ alsc$ cut -f -1 eccel.txt
ID
1
2
3
----------------------提取、切割文本信息---------------------
# 案例1 分割字符串中的手机号
[C02DD1K1ML85:~ alsc]$ vim test.txt
zz13838654225
[C02DD1K1ML85:~ alsc]$ cat test.txt | grep 1[3-9][0-9]\\{9\\} | cut -d "z" -f 3
13838654225
# 案例2 分割ifconfig信息
[C02DD1K1ML85:~ alsc]$ ifconfig en1
en1: flags=8963 mtu 1500
options=460
ether 56:b4:92:68:27:44
media: autoselect
status: inactive
[C02DD1K1ML85:~ alsc]$ ifconfig en1 | grep status
status: inactive
[C02DD1K1ML85:~ alsc]$ ifconfig en1 | grep status | cut -d ":" -f 2
inactive 10.2、awk:强大的文本分析工具,逐行读入文件,以空格为默认分隔符将每行切开,切开的部分再进行分割处理
awk [参数] '/pattern1/ {action1} pattern2/ {action2}...' filename
-F:指定文件分隔符
-V:赋值一个用户定义变量
-------------------- -F用来设置符号 可以分割符合pattern的文本 -------------------
[C02DD1K1ML85:~ alsc]$ cat /etc/passwd | grep "^root" | cut -d ":" -f 1
root
[C02DD1K1ML85:~ alsc]$ cat /etc/passwd | awk -F ":" '/^root/ {print $1","$2}'
root,*
[C02DD1K1ML85:~ alsc]$ cat /etc/passwd | awk -F ":" '/^root/ {print $1}'
root
[C02DD1K1ML85:~ alsc]$ cat /etc/passwd | grep "^root" | cut -d ":" -f 1,2
root:*
-------------------- -v用来初始化变量 可以在代码块中使用 -------------------
[C02DD1K1ML85:~ alsc]$ cat /etc/passwd | awk -F ":" '{print $3}'
278
279
280
281
283
284
440
[C02DD1K1ML85:~ alsc]$ cat /etc/passwd | awk -v i=1 -F ":" '{print $3+i}'
279
280
281
282
284
285
441awk内置命令
FILENAME:文件名 # 格式:awk {print FILENAME} path/filename 否则代码块打印FILENAME失效
NR:行数
NF:列数
-------------------------对文件/etc/passwd执行内置命令-----------------------
C02DD1K1ML85:etc alsc$ awk '{print "文件名:"FILENAME"&&行数:"NR"&&列数:"NF}' /etc/passwd
文件名:/etc/passwd&&行数:1&&列数:1
文件名:/etc/passwd&&行数:2&&列数:3
文件名:/etc/passwd&&行数:3&&列数:1
文件名:/etc/passwd&&行数:4&&列数:14
文件名:/etc/passwd&&行数:5&&列数:12
文件名:/etc/passwd&&行数:6&&列数:310.3、sed
10.4、sort